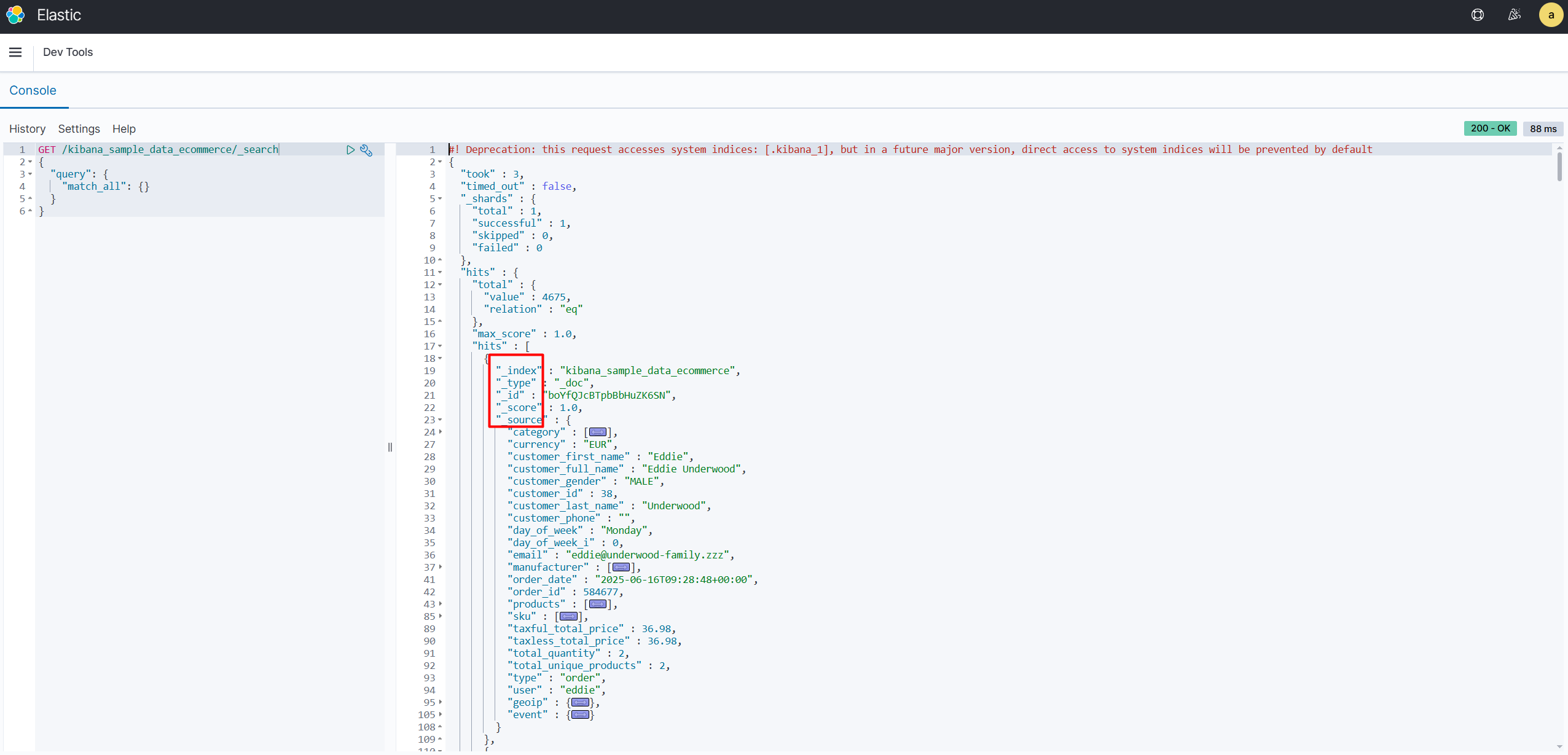
Spring Boot + Elasticsearch + HBase 构建海量数据搜索系统
📖 目录
- 1. 系统需求分析
- 2. 系统架构设计
- 3. Elasticsearch 与 HBase 集成方案
- 4. Spring Boot 项目实现
- 5. 大规模搜索系统最佳实践
项目概述
本文档提供了基于 Spring Boot、Elasticsearch 和 HBase 构建海量数据搜索系统的完整解决方案。从需求分析、架构设计、技术集成到具体实现和最佳实践,全面覆盖了系统开发的各个环节。
主要特点
- 高性能:利用 Elasticsearch 的全文检索能力和 HBase 的海量数据存储能力
- 高可用:通过集群部署和数据副本机制保障系统可用性
- 高扩展性:支持水平扩展,应对数据量和请求量的增长
- 实时性:支持近实时的数据索引和查询
- 一致性:提供数据同步和一致性保障机制
适用场景
- 电子商务平台商品搜索
- 日志分析系统
- 社交媒体内容检索
- 金融交易数据分析
- 其他需要海量数据存储和实时搜索的场景
如何使用本文档
- 从系统需求分析开始,了解系统的目标和需求
- 参考系统架构设计了解整体架构和组件关系
- 深入Elasticsearch 与 HBase 集成方案学习两者的集成原理
- 通过Spring Boot 项目实现获取具体的代码实现指导
- 参考大规模搜索系统最佳实践了解部署和优化建议
技术栈
- Spring Boot: 2.7.x / 3.x
- Elasticsearch: 7.17.x / 8.x
- HBase: 2.4.x
- Kafka: 3.x (用于数据同步)
- Redis: 6.x (可选,用于缓存)
- Zookeeper: 3.7.x
核心功能
- 全文检索与结构化查询
- 海量数据存储与管理
- 实时数据同步与一致性保障
- 高性能查询与结果合并
- 系统监控与运维支持
后续建议
- 根据实际业务需求调整系统架构和配置
- 进行性能测试和压力测试,验证系统在实际负载下的表现
- 建立完善的监控和告警机制,确保系统稳定运行
- 定期优化索引和查询,提升系统性能
结语
本解决方案提供了构建海量数据搜索系统的理论基础和实践指导,可作为系统设计和开发的参考。在实际应用中,应根据具体业务场景和技术环境进行适当调整和优化。
海量数据搜索系统需求分析
1. 应用场景分析
海量数据搜索系统在多个领域有广泛应用,主要包括以下典型场景:
1.1 电子商务平台
电商平台需要对海量商品数据进行实时搜索,包括商品名称、描述、属性、价格等多维度信息。用户搜索行为具有高并发、低延迟的特点,且需要支持复杂的筛选、排序和个性化推荐功能。
1.2 日志分析系统
企业级应用产生的日志数据量巨大,需要对这些数据进行实时采集、存储和分析。运维人员需要快速定位异常日志,分析系统性能瓶颈,监控业务指标波动等。
1.3 社交媒体内容检索
社交平台需要对用户生成的文本、图片、视频等多媒体内容进行索引和检索,支持按时间、热度、相关性等多种方式排序,并能够实现实时的内容推送。
1.4 金融交易数据分析
金融机构需要对交易数据进行实时监控和历史查询,用于风险控制、反欺诈分析、交易模式识别等,要求系统具备高可靠性和数据一致性。
2. 数据规模与性能需求
2.1 数据规模
- 数据总量:TB 级至 PB 级,且持续增长
- 单表记录数:十亿级别
- 单条记录大小:从 KB 到 MB 不等,取决于具体业务
- 数据增长速度:每日新增数据量可达 GB 至 TB 级别
2.2 性能需求
- 查询响应时间:
- 简单查询:≤ 100ms
- 复杂查询:≤ 1s
- 聚合分析:≤ 3s
- 系统吞吐量:
- 峰值 QPS:1000+
- 日均查询量:百万级
- 写入性能:
- 批量写入:≥ 10000 条/秒
- 实时写入:≥ 1000 条/秒
- 数据同步延迟:≤ 5s(从数据写入到可被搜索)
3. 查询类型与实时性要求
3.1 查询类型
- 全文检索:支持对文本字段的模糊匹配、分词搜索、同义词扩展等
- 结构化查询:支持对数值、日期、枚举等字段的精确匹配、范围查询
- 地理位置查询:支持基于经纬度的距离计算、区域筛选
- 复合查询:支持多条件组合查询,如布尔查询、嵌套查询等
- 聚合分析:支持分组统计、指标计算、直方图分析等
- 相关性排序:支持基于 TF-IDF、BM25 等算法的相关性评分
3.2 实时性要求
- 数据写入实时性:新增或修改的数据需在秒级内可被检索
- 查询结果实时性:查询结果需反映最新的数据状态,允许秒级延迟
- 实时分析能力:支持对流式数据的实时聚合分析
- 热点数据更新:高频访问的热点数据需保持更高的实时性
4. 系统扩展性与可用性需求
4.1 扩展性需求
- 水平扩展:支持通过增加节点线性提升系统容量和性能
- 动态扩容:支持在不停机的情况下进行集群扩容
- 数据分片:支持基于业务规则的数据分片策略
- 多租户支持:支持多业务线或多客户的数据隔离
4.2 可用性需求
- 高可用性:系统整体可用性 ≥ 99.9%
- 容灾能力:支持跨机房、跨区域的数据备份和故障转移
- 无单点故障:关键组件需具备冗余设计
- 平滑升级:支持不停机的系统升级和维护
4.3 安全性需求
- 数据安全:支持数据加密存储和传输
- 访问控制:支持细粒度的权限管理和访问控制
- 操作审计:记录关键操作日志,支持安全审计
- 数据隔离:确保不同租户间的数据严格隔离
5. 系统集成与接口需求
5.1 集成需求
- 数据源集成:支持从多种数据源(关系型数据库、消息队列、文件系统等)导入数据
- 第三方系统集成:提供标准接口与其他业务系统集成
- 监控系统集成:支持与 Prometheus、Grafana 等监控工具集成
5.2 接口需求
- RESTful API:提供标准的 HTTP/JSON 接口
- 批量操作接口:支持批量查询、写入和更新操作
- 异步接口:支持长时间运行的查询任务异步执行
- SDK 支持:提供多语言的客户端 SDK
6. 运维与监控需求
6.1 运维需求
- 部署自动化:支持容器化部署和自动化运维
- 配置管理:支持集中化的配置管理和动态配置更新
- 备份恢复:支持定期数据备份和快速恢复
- 资源隔离:支持计算资源和存储资源的隔离管理
6.2 监控需求
- 系统监控:监控集群节点状态、资源使用率等
- 性能监控:监控查询延迟、吞吐量、错误率等指标
- 业务监控:支持自定义业务指标的监控和告警
- 日志分析:集中收集和分析系统运行日志
7. 总结
基于以上需求分析,我们需要设计一个基于 Spring Boot、Elasticsearch 和 HBase 的海量数据搜索系统,该系统应具备高性能、高可用、高扩展性的特点,能够满足各类应用场景下的海量数据存储和实时搜索需求。系统架构设计将充分考虑这些需求,合理划分职责,优化数据流转,确保系统整体性能和可靠性。
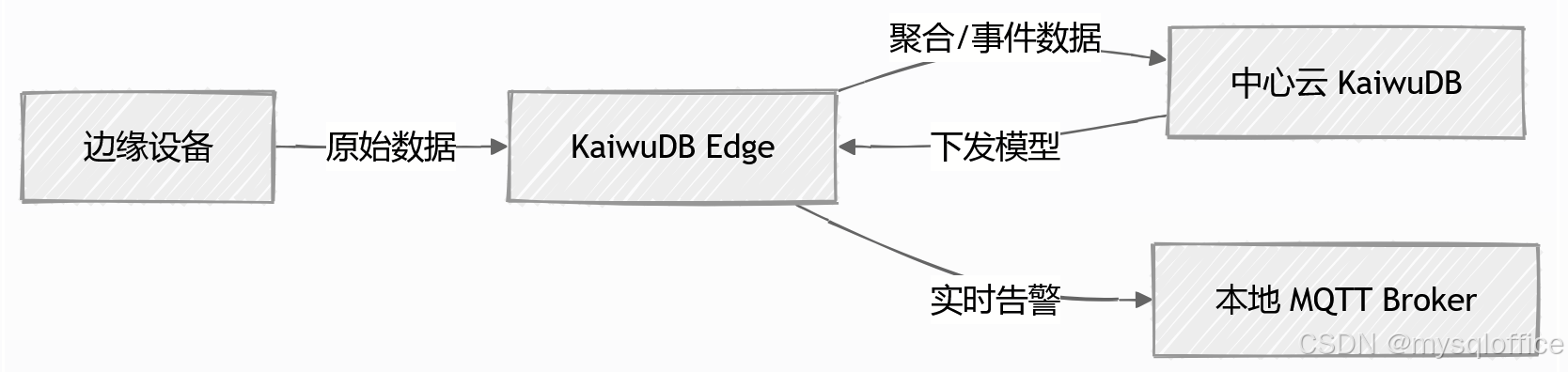
海量数据搜索系统架构设计
1. 整体架构设计
基于Spring Boot、Elasticsearch和HBase构建的海量数据搜索系统采用分层架构设计,充分发挥各组件的优势,实现高性能、高可用、高扩展性的数据存储与检索服务。
1.1 架构图
+--------------------------------------------------------------------------------------------------+
| 客户端应用层 |
| +----------------------------+ +----------------------------+ +----------------------------+ |
| | Web 应用 | | 移动应用 | | 第三方系统 | |
| +----------------------------+ +----------------------------+ +----------------------------+ |
+--------------------------------------------------------------------------------------------------+
|
| HTTP/HTTPS
v
+--------------------------------------------------------------------------------------------------+
| API 网关层 |
| +----------------------------+ +----------------------------+ +----------------------------+ |
| | 认证授权 | | 限流熔断 | | 请求路由 | |
| +----------------------------+ +----------------------------+ +----------------------------+ |
+--------------------------------------------------------------------------------------------------+
|
| REST API
v
+--------------------------------------------------------------------------------------------------+
| Spring Boot 应用层 |
| +--------------------------------------------------------------------------------------------+ |
| | Controller 层 | |
| | +----------------------------+ +----------------------------+ +-------------------------+| |
| | | 查询控制器 | | 索引控制器 | | 管理控制器 || |
| | +----------------------------+ +----------------------------+ +-------------------------+| |
| +--------------------------------------------------------------------------------------------+ |
| | |
| +--------------------------------------------------------------------------------------------+ |
| | Service 层 | |
| | +----------------------------+ +----------------------------+ +-------------------------+| |
| | | 搜索服务 | | 索引服务 | | 数据同步服务 || |
| | +----------------------------+ +----------------------------+ +-------------------------+| |
| +--------------------------------------------------------------------------------------------+ |
| | |
| +--------------------------------------------------------------------------------------------+ |
| | Repository/DAO 层 | |
| | +----------------------------+ +----------------------------+ +-------------------------+| |
| | | Elasticsearch Repository | | HBase Repository | | Cache Repository || |
| | +----------------------------+ +----------------------------+ +-------------------------+| |
| +--------------------------------------------------------------------------------------------+ |
+--------------------------------------------------------------------------------------------------+
| | |
v v v
+---------------------------+ +----------------------------------+ +------------------+
| | | | | |
| Elasticsearch 集群 |<-->| 数据同步层 |<-->| HBase 集群 |
| (索引存储与检索引擎) | | (CDC/MQ/定时任务/实时同步) | | (海量数据存储) |
| | | | | |
+---------------------------+ +----------------------------------+ +------------------+
|
v
+--------------------------------------------------------------------------------------------------+
| 监控与运维层 |
| +----------------------------+ +----------------------------+ +----------------------------+ |
| | 性能监控 | | 日志收集 | | 告警系统 | |
| +----------------------------+ +----------------------------+ +----------------------------+ |
+--------------------------------------------------------------------------------------------------+
2. 核心组件职责
2.1 Spring Boot 应用层
作为系统的核心业务逻辑层,负责处理客户端请求、协调各组件交互、实现业务功能。
2.1.1 Controller 层
- 查询控制器:提供搜索API接口,处理各类查询请求
- 索引控制器:提供索引管理API,处理索引创建、更新、删除等操作
- 管理控制器:提供系统管理API,处理配置管理、状态监控等功能
2.1.2 Service 层
- 搜索服务:实现各类搜索逻辑,包括全文检索、结构化查询、聚合分析等
- 索引服务:实现索引管理逻辑,包括索引创建、更新、优化等
- 数据同步服务:实现HBase与Elasticsearch之间的数据同步逻辑
2.1.3 Repository/DAO 层
- Elasticsearch Repository:封装对Elasticsearch的操作,提供索引和查询功能
- HBase Repository:封装对HBase的操作,提供数据存储和读取功能
- Cache Repository:封装对缓存的操作,提供热点数据缓存功能
2.2 Elasticsearch 集群
作为系统的搜索引擎,负责提供高性能的全文检索和实时分析能力。
- 索引存储:存储结构化和非结构化数据的索引
- 全文检索:提供基于倒排索引的全文搜索能力
- 实时分析:提供聚合分析和统计功能
- 高可用机制:通过主从复制、分片和副本机制保障高可用
2.3 HBase 集群
作为系统的海量数据存储层,负责存储原始数据和历史数据。
- 数据存储:基于列族模型存储海量结构化和半结构化数据
- 高吞吐写入:支持高并发、高吞吐的数据写入
- 随机读取:支持基于RowKey的高效随机读取
- 水平扩展:支持通过增加RegionServer实现线性扩展
2.4 数据同步层
负责在Elasticsearch和HBase之间同步数据,保证数据一致性。
- 变更数据捕获(CDC):捕获HBase数据变更并推送到Elasticsearch
- 消息队列:作为数据同步的中间缓冲,提高系统可靠性
- 定时任务:定期执行全量或增量数据同步
- 实时同步:支持近实时的数据同步,满足实时搜索需求
2.5 API 网关层
作为系统的接入层,负责请求路由、认证授权、限流熔断等功能。
- 认证授权:验证客户端身份,控制访问权限
- 限流熔断:防止系统过载,提高系统稳定性
- 请求路由:将请求分发到合适的服务节点
- 协议转换:支持多种协议的客户端接入
2.6 监控与运维层
负责系统监控、日志收集、告警通知等运维功能。
- 性能监控:监控系统各组件的性能指标
- 日志收集:集中收集和分析系统日志
- 告警系统:当系统异常时发出告警通知
- 运维工具:提供系统管理和运维工具
3. 数据流转流程
3.1 数据写入流程
- 客户端通过API网关发送数据写入请求
- Spring Boot应用接收请求并进行参数验证
- 数据首先写入HBase作为主存储
- 写入成功后,通过数据同步层将数据同步到Elasticsearch
- 返回写入结果给客户端
客户端 -> API网关 -> Spring Boot应用 -> HBase
-> 数据同步层 -> Elasticsearch
3.2 数据查询流程
- 客户端通过API网关发送查询请求
- Spring Boot应用接收请求并解析查询条件
- 根据查询类型选择查询路径:
- 全文检索、复杂查询、聚合分析:直接查询Elasticsearch
- 精确查询、主键查询:优先查询HBase
- 混合查询:分别查询Elasticsearch和HBase,合并结果
- 处理查询结果并返回给客户端
客户端 -> API网关 -> Spring Boot应用 -> Elasticsearch -> 结果处理 -> 客户端
-> HBase ->
3.3 数据同步流程
3.3.1 实时同步
- HBase数据变更触发CDC机制
- 变更事件发送到消息队列
- 数据同步服务消费消息队列中的事件
- 将变更应用到Elasticsearch索引
HBase变更 -> CDC -> 消息队列 -> 数据同步服务 -> Elasticsearch
3.3.2 批量同步
- 定时任务触发批量同步作业
- 从HBase读取增量或全量数据
- 对数据进行转换和处理
- 批量写入Elasticsearch
定时触发 -> 批量同步作业 -> 从HBase读取数据 -> 数据转换 -> 批量写入Elasticsearch
4. 技术选型与版本兼容性
4.1 核心组件版本
| 组件 | 推荐版本 | 说明 |
|---|---|---|
| Spring Boot | 2.7.x / 3.x | 提供Web框架、依赖注入、自动配置等功能 |
| Elasticsearch | 7.17.x / 8.x | 提供全文检索和实时分析能力 |
| HBase | 2.4.x | 提供海量数据存储能力 |
| Kafka | 3.x | 作为数据同步的消息队列 |
| Redis | 6.x | 提供缓存支持 |
| Zookeeper | 3.7.x | 为HBase和Kafka提供协调服务 |
4.2 关键依赖库
| 依赖库 | 版本 | 用途 |
|---|---|---|
| spring-boot-starter-web | 与Spring Boot版本一致 | Web应用支持 |
| spring-boot-starter-data-elasticsearch | 与Spring Boot版本一致 | Elasticsearch集成 |
| hbase-client | 与HBase版本一致 | HBase客户端 |
| spring-kafka | 与Spring Boot版本兼容 | Kafka集成 |
| spring-boot-starter-data-redis | 与Spring Boot版本一致 | Redis集成 |
| spring-boot-starter-actuator | 与Spring Boot版本一致 | 应用监控 |
5. 系统扩展性设计
5.1 水平扩展
- 应用层扩展:Spring Boot应用可部署多实例,通过负载均衡分发请求
- Elasticsearch扩展:通过增加节点和调整分片数量实现集群扩展
- HBase扩展:通过增加RegionServer和调整Region分布实现集群扩展
5.2 功能扩展
- 插件化设计:核心功能模块化,支持通过插件方式扩展
- 配置化能力:关键参数可通过配置动态调整,无需修改代码
- API版本控制:支持API版本演进,保障向后兼容性
6. 高可用设计
6.1 无单点故障
- 应用层:多实例部署,任一实例故障不影响整体服务
- Elasticsearch:主从架构,数据分片和副本机制
- HBase:主从架构,Region复制机制
- 消息队列:集群部署,多副本存储
6.2 故障恢复
- 自动故障检测:通过健康检查及时发现故障
- 自动故障转移:故障节点自动下线,请求转发到健康节点
- 数据一致性保障:通过事务机制和幂等设计保障数据一致性
7. 安全设计
7.1 认证与授权
- API认证:基于OAuth2.0/JWT的API认证机制
- 细粒度授权:基于RBAC的权限控制,支持数据级别的访问控制
- 安全通信:全链路HTTPS加密
7.2 数据安全
- 敏感数据加密:对敏感字段进行加密存储
- 数据脱敏:查询结果中的敏感信息自动脱敏
- 审计日志:记录关键操作,支持安全审计
8. 总结
本架构设计基于Spring Boot、Elasticsearch和HBase构建了一个完整的海量数据搜索系统,通过合理的分层设计和组件选择,实现了高性能、高可用、高扩展性的系统目标。架构中明确了各组件的职责和交互关系,设计了完整的数据流转流程,为后续的详细实现提供了清晰的指导。
Elasticsearch 与 HBase 集成方案
1. Elasticsearch 与 HBase 技术特点分析
1.1 Elasticsearch 核心特点
Elasticsearch 是一个分布式、RESTful 风格的搜索和分析引擎,基于 Apache Lucene 构建。其主要特点包括:
1.1.1 优势
- 全文检索能力:基于倒排索引,提供强大的全文检索功能
- 实时性:近实时搜索,数据写入后秒级可查
- 分布式架构:支持水平扩展,可处理 PB 级数据
- 高可用性:通过分片和副本机制保障数据可用性
- 丰富的查询 DSL:支持复杂的查询语法和聚合分析
- Schema-less:灵活的数据模型,支持动态映射
- RESTful API:提供简单易用的 HTTP 接口
1.1.2 局限性
- 存储成本高:索引需要额外存储空间,成本较高
- 更新性能较弱:对文档的更新实际是删除后重建
- 事务支持有限:不支持完整的 ACID 事务
- 深度分页性能差:对大偏移量的分页查询性能较差
- 资源消耗大:内存和 CPU 资源消耗较高
1.2 HBase 核心特点
HBase 是一个分布式、可扩展的 NoSQL 数据库,基于 Google 的 BigTable 模型构建。其主要特点包括:
1.2.1 优势
- 海量数据存储:可存储 PB 级结构化和半结构化数据
- 线性扩展能力:通过增加 RegionServer 实现水平扩展
- 高吞吐写入:优化的写入路径,支持高并发写入
- 强一致性:提供行级别的强一致性保证
- 列族存储模型:灵活的存储模型,适合稀疏数据
- 版本化数据:支持数据多版本存储
- Hadoop 生态集成:与 Hadoop 生态系统紧密集成
1.2.2 局限性
- 不支持复杂查询:只支持基于 RowKey 的查询,不支持全文检索
- 不支持二级索引:原生不支持除 RowKey 外的索引
- 查询灵活性差:查询模式受 RowKey 设计限制
- 聚合能力弱:不支持复杂的聚合操作
- 实时性较差:查询性能受 Region 分布和缓存影响
1.3 两者结合的优势
结合 Elasticsearch 和 HBase 可以互补各自的优缺点,形成一个完整的海量数据存储和检索解决方案:
- 存储与检索分离:HBase 负责海量数据的可靠存储,Elasticsearch 负责高效检索和分析
- 全面的查询能力:结合 HBase 的精确查询和 Elasticsearch 的全文检索、复杂查询能力
- 成本优化:热数据放在 Elasticsearch 中,冷数据存储在 HBase 中,优化存储成本
- 数据完整性:HBase 作为数据主存储,保障数据完整性和一致性
- 查询性能优化:利用 Elasticsearch 的索引能力,提升复杂查询性能
2. 数据模型设计
2.1 HBase 数据模型设计
2.1.1 表设计原则
- RowKey 设计:根据查询模式设计 RowKey,避免热点问题
- 列族设计:相关字段分组到同一列族,减少 I/O 开销
- 版本控制:根据业务需求设置合适的版本数量
- TTL 策略:为不同类型的数据设置合适的生存时间
2.1.2 示例表结构
以电商商品数据为例:
表名:products
RowKey 设计:category_id + brand_id + product_id(复合键)
列族设计:
1. info:基本信息
- name:商品名称
- description:商品描述
- price:价格
- status:状态
2. detail:详细信息
- specifications:规格参数(JSON格式)
- features:特性列表
- materials:材料信息
3. media:媒体信息
- images:图片URL列表
- videos:视频URL列表
4. stats:统计信息
- view_count:浏览次数
- sale_count:销售数量
- rating:评分
2.2 Elasticsearch 索引设计
2.2.1 索引设计原则
- 映射优化:根据字段类型选择合适的映射类型
- 分析器选择:根据语言和业务需求选择合适的分析器
- 分片策略:根据数据量和查询性能需求设置分片数
- 副本策略:根据可用性需求设置副本数
2.2.2 示例索引结构
继续以电商商品数据为例:
{
"settings": {
"number_of_shards": 5,
"number_of_replicas": 1,
"analysis": {
"analyzer": {
"product_analyzer": {
"type": "custom",
"tokenizer": "standard",
"filter": ["lowercase", "synonym", "edge_ngram"]
}
}
}
},
"mappings": {
"properties": {
"product_id": { "type": "keyword" },
"category_id": { "type": "keyword" },
"brand_id": { "type": "keyword" },
"name": {
"type": "text",
"analyzer": "product_analyzer",
"fields": {
"keyword": { "type": "keyword" }
}
},
"description": { "type": "text", "analyzer": "product_analyzer" },
"price": { "type": "double" },
"status": { "type": "keyword" },
"specifications": { "type": "object" },
"features": { "type": "text", "analyzer": "product_analyzer" },
"materials": { "type": "keyword" },
"images": { "type": "keyword" },
"videos": { "type": "keyword" },
"view_count": { "type": "integer" },
"sale_count": { "type": "integer" },
"rating": { "type": "float" },
"created_at": { "type": "date" },
"updated_at": { "type": "date" },
"location": { "type": "geo_point" }
}
}
}
2.3 数据模型映射关系
HBase 和 Elasticsearch 之间的数据模型需要建立清晰的映射关系,以确保数据同步的准确性:
| HBase | Elasticsearch | 映射说明 |
|---|---|---|
| RowKey | product_id, category_id, brand_id | HBase RowKey 拆分为多个字段 |
| info:name | name | 直接映射 |
| info:description | description | 直接映射 |
| info:price | price | 类型转换为 double |
| info:status | status | 直接映射 |
| detail:specifications | specifications | JSON 解析为对象 |
| detail:features | features | 直接映射 |
| detail:materials | materials | 直接映射 |
| media:images | images | 字符串分割为数组 |
| media:videos | videos | 字符串分割为数组 |
| stats:view_count | view_count | 类型转换为 integer |
| stats:sale_count | sale_count | 类型转换为 integer |
| stats:rating | rating | 类型转换为 float |
3. 数据同步机制设计
3.1 同步策略概述
在 HBase 和 Elasticsearch 之间建立高效、可靠的数据同步机制是系统成功的关键。根据业务需求,可以采用以下几种同步策略:
- 实时同步:数据写入 HBase 后立即同步到 Elasticsearch
- 准实时同步:数据写入 HBase 后短时间内(秒级)同步到 Elasticsearch
- 批量同步:定期(分钟或小时级)将 HBase 数据批量同步到 Elasticsearch
- 混合同步:重要数据实时同步,非关键数据批量同步
3.2 实时/准实时同步实现
3.2.1 基于 CDC (Change Data Capture) 的同步
利用 HBase 的 WAL (Write-Ahead Log) 或 Replication 机制捕获数据变更:
+-------------+ +-------------+ +-------------+ +----------------+
| HBase | | CDC 工具 | | 消息队列 | | 同步服务 | +----------------+
| 数据写入 +---->+ (如 Debezium)+---->+ (如 Kafka) +---->+ (Spring Boot) +---->+ Elasticsearch |
+-------------+ +-------------+ +-------------+ +----------------+ +----------------+
实现步骤:
- 配置 CDC 工具监听 HBase 的数据变更
- 将捕获的变更事件发送到消息队列
- 同步服务消费消息队列中的事件
- 将变更应用到 Elasticsearch
代码示例:
// 消费 Kafka 中的 HBase 变更事件
@Service
public class RealTimeSyncService {
@Autowired
private ElasticsearchClient esClient;
@KafkaListener(topics = "hbase-changes", groupId = "es-sync-group")
public void processHBaseChanges(ConsumerRecord<String, String> record) {
try {
// 解析变更事件
ChangeEvent event = objectMapper.readValue(record.value(), ChangeEvent.class);
// 根据操作类型处理
switch (event.getOperationType()) {
case "INSERT":
case "UPDATE":
syncToElasticsearch(event);
break;
case "DELETE":
deleteFromElasticsearch(event);
break;
default:
log.warn("Unknown operation type: {}", event.getOperationType());
}
} catch (Exception e) {
log.error("Error processing HBase change event", e);
// 处理异常,可能的策略:重试、记录失败事件、告警等
}
}
private void syncToElasticsearch(ChangeEvent event) {
// 转换数据格式
Map<String, Object> document = transformToEsDocument(event);
// 写入 Elasticsearch
IndexRequest request = new IndexRequest("products")
.id(event.getRowKey())
.source(document);
esClient.index(request, RequestOptions.DEFAULT);
}
private void deleteFromElasticsearch(ChangeEvent event) {
DeleteRequest request = new DeleteRequest("products", event.getRowKey());
esClient.delete(request, RequestOptions.DEFAULT);
}
private Map<String, Object> transformToEsDocument(ChangeEvent event) {
// 根据映射关系转换 HBase 数据为 Elasticsearch 文档
// ...
}
}
3.2.2 基于 Observer 的同步
利用 HBase 的 Coprocessor 机制在数据写入时触发同步:
+-------------+ +----------------+ +----------------+
| HBase | | Coprocessor | | Elasticsearch |
| 数据写入 +---->+ (Observer) +---->+ |
+-------------+ +----------------+ +----------------+
实现步骤:
- 开发 HBase Observer 类,监听数据变更事件
- 在 Observer 中直接调用 Elasticsearch API 进行同步
- 部署 Observer 到 HBase 集群
代码示例:
public class ElasticsearchSyncObserver extends BaseRegionObserver {
private ElasticsearchClient esClient;
@Override
public void start(CoprocessorEnvironment env) throws IOException {
super.start(env);
// 初始化 Elasticsearch 客户端
this.esClient = createEsClient();
}
@Override
public void postPut(ObserverContext<RegionCoprocessorEnvironment> c, Put put, WALEdit edit, Durability durability) throws IOException {
try {
// 获取表名
TableName tableName = c.getEnvironment().getRegion().getTableDescriptor().getTableName();
// 只处理特定表
if (tableName.equals(TableName.valueOf("products"))) {
// 转换 Put 操作为 Elasticsearch 文档
String rowKey = Bytes.toString(put.getRow());
Map<String, Object> document = convertPutToEsDocument(put);
// 异步写入 Elasticsearch
IndexRequest request = new IndexRequest("products")
.id(rowKey)
.source(document);
esClient.indexAsync(request, RequestOptions.DEFAULT, new ActionListener<IndexResponse>() {
@Override
public void onResponse(IndexResponse indexResponse) {
// 同步成功处理
}
@Override
public void onFailure(Exception e) {
// 同步失败处理,记录日志或发送到死信队列
}
});
}
} catch (Exception e) {
// 记录异常但不影响 HBase 操作
LOG.error("Error syncing to Elasticsearch", e);
}
}
@Override
public void postDelete(ObserverContext<RegionCoprocessorEnvironment> c, Delete delete, WALEdit edit, Durability durability) throws IOException {
// 类似 postPut 实现,处理删除操作
}
private Map<String, Object> convertPutToEsDocument(Put put) {
// 根据映射关系转换 HBase Put 操作为 Elasticsearch 文档
// ...
}
}
3.3 批量同步实现
3.3.1 基于时间戳的增量同步
利用 HBase 的时间戳机制,定期同步增量数据:
+----------------+ +----------------+ +----------------+
| 调度系统 | | 同步作业 | | Elasticsearch |
| (如 Quartz) +---->+ (Spring Batch)+---->+ |
+----------------+ +----------------+ +----------------+
| ^
| |
v |
+----------------+ +----------------+
| 同步元数据 | | HBase |
| (上次同步时间)| | (数据源) |
+----------------+ +----------------+
实现步骤:
- 记录上次同步的时间戳
- 定期触发同步作业
- 从 HBase 读取大于上次同步时间戳的数据
- 批量写入 Elasticsearch
- 更新同步时间戳
代码示例:
@Component
public class BatchSyncJob {
@Autowired
private HBaseTemplate hbaseTemplate;
@Autowired
private ElasticsearchClient esClient;
@Autowired
private SyncMetadataRepository syncMetadataRepository;
@Scheduled(fixedRate = 300000) // 每5分钟执行一次
public void syncIncrementalData() {
try {
// 获取上次同步时间戳
long lastSyncTimestamp = syncMetadataRepository.getLastSyncTimestamp("products");
long currentTimestamp = System.currentTimeMillis();
// 构建 HBase 扫描条件
Scan scan = new Scan();
scan.setTimeRange(lastSyncTimestamp + 1, currentTimestamp);
// 批量读取 HBase 数据
List<Map<String, Object>> documents = new ArrayList<>();
hbaseTemplate.find("products", scan, (Result result, int rowNum) -> {
Map<String, Object> document = convertResultToEsDocument(result);
documents.add(document);
return null;
});
// 批量写入 Elasticsearch
if (!documents.isEmpty()) {
BulkRequest bulkRequest = new BulkRequest();
for (Map<String, Object> document : documents) {
String id = (String) document.get("product_id");
bulkRequest.add(new IndexRequest("products")
.id(id)
.source(document));
}
BulkResponse bulkResponse = esClient.bulk(bulkRequest, RequestOptions.DEFAULT);
if (bulkResponse.hasFailures()) {
// 处理部分失败情况
handlePartialFailures(bulkResponse, documents);
}
}
// 更新同步时间戳
syncMetadataRepository.updateLastSyncTimestamp("products", currentTimestamp);
} catch (Exception e) {
log.error("Error during batch sync", e);
// 处理异常,可能的策略:重试、告警等
}
}
private Map<String, Object> convertResultToEsDocument(Result result) {
// 根据映射关系转换 HBase Result 为 Elasticsearch 文档
// ...
}
private void handlePartialFailures(BulkResponse bulkResponse, List<Map<String, Object>> documents) {
// 处理部分失败的情况,可能的策略:重试、记录失败项、告警等
// ...
}
}
3.3.2 基于全表扫描的全量同步
定期执行全表扫描,确保数据完整性:
实现步骤:
- 定期触发全量同步作业
- 从 HBase 读取全表数据
- 批量写入或更新 Elasticsearch
- 记录同步状态和统计信息
代码示例:
@Component
public class FullSyncJob {
@Autowired
private HBaseTemplate hbaseTemplate;
@Autowired
private ElasticsearchClient esClient;
@Scheduled(cron = "0 0 2 * * ?") // 每天凌晨2点执行
public void syncFullData() {
try {
log.info("Starting full sync from HBase to Elasticsearch");
// 创建新索引(带版本号)
String newIndexName = "products_" + System.currentTimeMillis();
createIndex(newIndexName);
// 全表扫描
Scan scan = new Scan();
AtomicInteger counter = new AtomicInteger(0);
// 分批处理
int batchSize = 1000;
List<Map<String, Object>> batch = new ArrayList<>(batchSize);
hbaseTemplate.find("products", scan, (Result result, int rowNum) -> {
Map<String, Object> document = convertResultToEsDocument(result);
batch.add(document);
// 达到批处理大小,执行批量写入
if (batch.size() >= batchSize) {
bulkIndexDocuments(newIndexName, batch);
counter.addAndGet(batch.size());
batch.clear();
log.info("Synced {} documents", counter.get());
}
return null;
});
// 处理最后一批
if (!batch.isEmpty()) {
bulkIndexDocuments(newIndexName, batch);
counter.addAndGet(batch.size());
}
// 切换别名,完成索引切换
updateIndexAlias("products", newIndexName);
log.info("Full sync completed, total {} documents synced", counter.get());
} catch (Exception e) {
log.error("Error during full sync", e);
// 处理异常,可能的策略:回滚、告警等
}
}
private void createIndex(String indexName) {
// 创建新索引,设置映射等
// ...
}
private void bulkIndexDocuments(String indexName, List<Map<String, Object>> documents) throws IOException {
BulkRequest bulkRequest = new BulkRequest();
for (Map<String, Object> document : documents) {
String id = (String) document.get("product_id");
bulkRequest.add(new IndexRequest(indexName)
.id(id)
.source(document));
}
esClient.bulk(bulkRequest, RequestOptions.DEFAULT);
}
private void updateIndexAlias(String aliasName, String newIndexName) throws IOException {
// 获取当前别名指向的索引
GetAliasesRequest getAliasesRequest = new GetAliasesRequest(aliasName);
GetAliasesResponse getAliasesResponse = esClient.indices().getAlias(getAliasesRequest, RequestOptions.DEFAULT);
Set<String> oldIndices = getAliasesResponse.getAliases().keySet();
// 更新别名
IndicesAliasesRequest aliasesRequest = new IndicesAliasesRequest();
// 添加新索引到别名
aliasesRequest.addAliasAction(
new IndicesAliasesRequest.AliasActions(IndicesAliasesRequest.AliasActions.Type.ADD)
.index(newIndexName)
.alias(aliasName));
// 从别名中移除旧索引
for (String oldIndex : oldIndices) {
aliasesRequest.addAliasAction(
new IndicesAliasesRequest.AliasActions(IndicesAliasesRequest.AliasActions.Type.REMOVE)
.index(oldIndex)
.alias(aliasName));
}
esClient.indices().updateAliases(aliasesRequest, RequestOptions.DEFAULT);
// 可选:删除旧索引
// ...
}
}
3.4 数据一致性保障机制
3.4.1 事务性写入
在写入 HBase 和同步到 Elasticsearch 之间实现事务性保障:
实现方案:
- 两阶段提交:先预提交到 HBase,成功后再同步到 Elasticsearch,最后确认 HBase 提交
- 补偿事务:先写入 HBase,同步到 Elasticsearch 失败时记录失败事件,后续补偿处理
- 最终一致性:接受短暂的不一致,通过定期校验和修复确保最终一致性
代码示例:
@Service
@Transactional
public class TransactionalDataService {
@Autowired
private HBaseTemplate hbaseTemplate;
@Autowired
private ElasticsearchClient esClient;
@Autowired
private FailedSyncRepository failedSyncRepository;
public void saveData(ProductData productData) {
try {
// 1. 写入 HBase
String rowKey = generateRowKey(productData);
Put put = createPut(rowKey, productData);
hbaseTemplate.execute("products", table -> {
table.put(put);
return null;
});
// 2. 同步到 Elasticsearch
try {
Map<String, Object> document = convertToEsDocument(productData);
IndexRequest indexRequest = new IndexRequest("products")
.id(rowKey)
.source(document);
esClient.index(indexRequest, RequestOptions.DEFAULT);
} catch (Exception e) {
// 3. 记录同步失败事件
failedSyncRepository.save(new FailedSyncEvent(
rowKey,
"products",
objectMapper.writeValueAsString(productData),
e.getMessage()
));
// 根据业务需求决定是否抛出异常回滚 HBase 写入
if (productData.isRequireStrictConsistency()) {
throw new RuntimeException("Failed to sync to Elasticsearch", e);
}
}
} catch (Exception e) {
throw new RuntimeException("Error saving data", e);
}
}
// 补偿处理失败的同步事件
@Scheduled(fixedRate = 60000) // 每分钟执行一次
public void processFailedSyncEvents() {
List<FailedSyncEvent> failedEvents = failedSyncRepository.findUnprocessedEvents(100);
for (FailedSyncEvent event : failedEvents) {
try {
// 重新同步到 Elasticsearch
ProductData productData = objectMapper.readValue(event.getData(), ProductData.class);
Map<String, Object> document = convertToEsDocument(productData);
IndexRequest indexRequest = new IndexRequest(event.getIndexName())
.id(event.getRowKey())
.source(document);
esClient.index(indexRequest, RequestOptions.DEFAULT);
// 标记为处理成功
event.setProcessed(true);
event.setProcessTime(new Date());
failedSyncRepository.update(event);
} catch (Exception e) {
// 增加重试次数
event.setRetryCount(event.getRetryCount() + 1);
// 如果超过最大重试次数,标记为需要人工干预
if (event.getRetryCount() >= 5) {
event.setRequireManualIntervention(true);
}
failedSyncRepository.update(event);
}
}
}
}
3.4.2 数据校验与修复
定期执行数据校验,发现并修复不一致:
实现方案:
- 基于时间窗口的增量校验
- 基于采样的全量校验
- 基于哈希值的快速比对
代码示例:
@Component
public class DataConsistencyChecker {
@Autowired
private HBaseTemplate hbaseTemplate;
@Autowired
private ElasticsearchClient esClient;
@Autowired
private InconsistencyRepository inconsistencyRepository;
@Scheduled(cron = "0 0 3 * * ?") // 每天凌晨3点执行
public void checkDataConsistency() {
try {
log.info("Starting data consistency check");
// 1. 采样 HBase 数据
List<String> sampleRowKeys = sampleHBaseRowKeys(1000); // 采样1000条记录
// 2. 检查每个采样记录
List<InconsistencyRecord> inconsistencies = new ArrayList<>();
for (String rowKey : sampleRowKeys) {
// 从 HBase 获取数据
Result hbaseResult = getFromHBase(rowKey);
if (hbaseResult == null || hbaseResult.isEmpty()) {
continue;
}
// 从 Elasticsearch 获取数据
GetResponse esResponse = getFromElasticsearch(rowKey);
// 比较数据
if (!esResponse.isExists()) {
// Elasticsearch 中缺少数据
inconsistencies.add(new InconsistencyRecord(
rowKey,
InconsistencyType.MISSING_IN_ES,
"Record exists in HBase but missing in Elasticsearch"
));
} else {
// 比较内容
Map<String, Object> hbaseData = convertHBaseResultToMap(hbaseResult);
Map<String, Object> esData = esResponse.getSourceAsMap();
if (!compareData(hbaseData, esData)) {
inconsistencies.add(new InconsistencyRecord(
rowKey,
InconsistencyType.DATA_MISMATCH,
"Data mismatch between HBase and Elasticsearch"
));
}
}
}
// 3. 记录不一致
if (!inconsistencies.isEmpty()) {
inconsistencyRepository.saveAll(inconsistencies);
log.warn("Found {} inconsistencies out of {} samples", inconsistencies.size(), sampleRowKeys.size());
} else {
log.info("No inconsistencies found in {} samples", sampleRowKeys.size());
}
// 4. 修复不一致(可选择自动修复或人工确认后修复)
repairInconsistencies();
} catch (Exception e) {
log.error("Error during data consistency check", e);
}
}
private void repairInconsistencies() {
// 获取需要修复的不一致记录
List<InconsistencyRecord> toRepair = inconsistencyRepository.findByStatus(InconsistencyStatus.TO_REPAIR);
for (InconsistencyRecord record : toRepair) {
try {
String rowKey = record.getRowKey();
// 从 HBase 获取最新数据
Result hbaseResult = getFromHBase(rowKey);
if (hbaseResult == null || hbaseResult.isEmpty()) {
// HBase 中已删除,从 Elasticsearch 中也删除
DeleteRequest deleteRequest = new DeleteRequest("products", rowKey);
esClient.delete(deleteRequest, RequestOptions.DEFAULT);
} else {
// 将 HBase 数据同步到 Elasticsearch
Map<String, Object> document = convertHBaseResultToMap(hbaseResult);
IndexRequest indexRequest = new IndexRequest("products")
.id(rowKey)
.source(document);
esClient.index(indexRequest, RequestOptions.DEFAULT);
}
// 更新修复状态
record.setStatus(InconsistencyStatus.REPAIRED);
record.setRepairTime(new Date());
inconsistencyRepository.update(record);
} catch (Exception e) {
log.error("Error repairing inconsistency for rowKey: " + record.getRowKey(), e);
record.setStatus(InconsistencyStatus.REPAIR_FAILED);
record.setErrorMessage(e.getMessage());
inconsistencyRepository.update(record);
}
}
}
// 其他辅助方法...
}
4. 查询路由与结果合并策略
4.1 查询路由策略
根据查询类型和性能需求,将查询请求路由到合适的存储系统:
4.1.1 路由规则
| 查询类型 | 路由目标 | 说明 |
|---|---|---|
| 全文检索 | Elasticsearch | 利用 Elasticsearch 的倒排索引能力 |
| 精确查询(基于主键) | HBase | 直接通过 RowKey 查询 HBase |
| 范围查询 | Elasticsearch | 利用 Elasticsearch 的范围查询能力 |
| 聚合分析 | Elasticsearch | 利用 Elasticsearch 的聚合功能 |
| 复合查询 | Elasticsearch + HBase | 先查 Elasticsearch,再补充 HBase 数据 |
| 高级过滤 | Elasticsearch | 利用 Elasticsearch 的过滤器 |
4.1.2 实现示例
@Service
public class QueryRouterService {
@Autowired
private ElasticsearchRepository esRepository;
@Autowired
private HBaseRepository hbaseRepository;
public SearchResult search(SearchRequest request) {
// 分析查询类型
QueryType queryType = analyzeQueryType(request);
switch (queryType) {
case FULL_TEXT:
case RANGE:
case AGGREGATION:
// 路由到 Elasticsearch
return searchFromElasticsearch(request);
case PRIMARY_KEY:
// 路由到 HBase
return searchFromHBase(request);
case COMPOSITE:
// 复合查询策略
return compositeSearch(request);
default:
throw new UnsupportedOperationException("Unsupported query type");
}
}
private QueryType analyzeQueryType(SearchRequest request) {
// 根据请求参数分析查询类型
if (request.hasFullTextTerms()) {
return QueryType.FULL_TEXT;
} else if (request.hasPrimaryKey()) {
return QueryType.PRIMARY_KEY;
} else if (request.hasRangeConditions()) {
return QueryType.RANGE;
} else if (request.hasAggregations()) {
return QueryType.AGGREGATION;
} else {
return QueryType.COMPOSITE;
}
}
private SearchResult searchFromElasticsearch(SearchRequest request) {
// 构建 Elasticsearch 查询
SearchSourceBuilder sourceBuilder = buildEsQuery(request);
// 执行查询
SearchResponse response = esRepository.search(sourceBuilder);
// 转换结果
return convertEsResponse(response);
}
private SearchResult searchFromHBase(SearchRequest request) {
// 构建 HBase 查询
String rowKey = extractRowKey(request);
// 执行查询
Result result = hbaseRepository.get(rowKey);
// 转换结果
return convertHBaseResult(result);
}
private SearchResult compositeSearch(SearchRequest request) {
// 实现复合查询策略
// ...
}
// 其他辅助方法...
}
4.2 结果合并策略
当需要从多个存储系统获取数据时,需要合理合并查询结果:
4.2.1 合并场景
- 补充字段:Elasticsearch 查询结果中缺少的字段从 HBase 补充
- 结果过滤:Elasticsearch 查询结果通过 HBase 数据进行二次过滤
- 结果排序:合并多个来源的结果并重新排序
- 分页处理:处理跨系统的分页查询
4.2.2 实现示例
@Service
public class ResultMergeService {
@Autowired
private HBaseRepository hbaseRepository;
public SearchResult mergeResults(SearchResult esResult, SearchRequest request) {
// 根据需要补充 HBase 数据
if (request.isRequireFullData()) {
return enrichWithHBaseData(esResult);
}
return esResult;
}
private SearchResult enrichWithHBaseData(SearchResult esResult) {
List<Map<String, Object>> enrichedItems = new ArrayList<>();
for (Map<String, Object> esItem : esResult.getItems()) {
String rowKey = (String) esItem.get("product_id");
// 从 HBase 获取完整数据
Result hbaseResult = hbaseRepository.get(rowKey);
if (hbaseResult != null && !hbaseResult.isEmpty()) {
// 合并 Elasticsearch 和 HBase 数据
Map<String, Object> mergedItem = new HashMap<>(esItem);
Map<String, Object> hbaseData = convertHBaseResultToMap(hbaseResult);
// 补充缺失字段
for (Map.Entry<String, Object> entry : hbaseData.entrySet()) {
if (!mergedItem.containsKey(entry.getKey())) {
mergedItem.put(entry.getKey(), entry.getValue());
}
}
enrichedItems.add(mergedItem);
} else {
// HBase 中不存在,仅使用 Elasticsearch 数据
enrichedItems.add(esItem);
}
}
// 更新结果
esResult.setItems(enrichedItems);
return esResult;
}
private Map<String, Object> convertHBaseResultToMap(Result hbaseResult) {
// 将 HBase Result 转换为 Map
// ...
}
}
4.3 缓存策略
为提高查询性能,可以在不同层次实现缓存:
4.3.1 缓存层次
- 应用层缓存:缓存热点查询结果
- 数据层缓存:缓存频繁访问的数据记录
- 查询层缓存:缓存查询计划和中间结果
4.3.2 实现示例
@Service
public class CachedSearchService {
@Autowired
private QueryRouterService queryRouter;
@Autowired
private CacheManager cacheManager;
public SearchResult search(SearchRequest request) {
// 生成缓存键
String cacheKey = generateCacheKey(request);
// 尝试从缓存获取
Cache cache = cacheManager.getCache("searchResults");
SearchResult cachedResult = cache.get(cacheKey, SearchResult.class);
if (cachedResult != null) {
return cachedResult;
}
// 缓存未命中,执行查询
SearchResult result = queryRouter.search(request);
// 缓存结果(设置适当的过期时间)
cache.put(cacheKey, result);
return result;
}
private String generateCacheKey(SearchRequest request) {
// 根据请求参数生成唯一的缓存键
// ...
}
}
5. 索引优化策略
5.1 Elasticsearch 索引优化
5.1.1 映射优化
- 字段类型选择:根据数据特点选择合适的字段类型
- 分析器配置:根据语言和业务需求配置分析器
- 字段存储策略:合理设置 _source 和 store 属性
5.1.2 分片策略
- 分片数量:根据数据量和节点数确定合理的分片数
- 分片路由:使用自定义路由提高查询效率
- 分片均衡:确保分片在节点间均匀分布
5.1.3 索引别名
使用索引别名实现零停机索引重建:
public void rebuildIndex() {
// 1. 创建新索引
String newIndexName = "products_" + System.currentTimeMillis();
createIndex(newIndexName);
// 2. 重新索引数据
reindexData("products", newIndexName);
// 3. 切换别名
updateAlias("products", newIndexName);
}
private void updateAlias(String aliasName, String newIndexName) {
IndicesAliasesRequest request = new IndicesAliasesRequest();
// 获取当前别名指向的索引
GetAliasesRequest getRequest = new GetAliasesRequest(aliasName);
GetAliasesResponse getResponse = esClient.indices().getAlias(getRequest, RequestOptions.DEFAULT);
// 添加新索引到别名
request.addAliasAction(
new IndicesAliasesRequest.AliasActions(IndicesAliasesRequest.AliasActions.Type.ADD)
.index(newIndexName)
.alias(aliasName));
// 从别名中移除旧索引
for (String oldIndex : getResponse.getAliases().keySet()) {
request.addAliasAction(
new IndicesAliasesRequest.AliasActions(IndicesAliasesRequest.AliasActions.Type.REMOVE)
.index(oldIndex)
.alias(aliasName));
}
esClient.indices().updateAliases(request, RequestOptions.DEFAULT);
}
5.2 HBase 表优化
5.2.1 RowKey 设计
- 避免热点:使用加盐、哈希或时间戳前缀
- 长度控制:保持 RowKey 长度适中
- 复合键设计:根据查询模式设计复合键
5.2.2 列族优化
- 列族数量:控制列族数量,一般不超过 3 个
- 数据分组:相关字段分组到同一列族
- 压缩设置:根据数据特点选择合适的压缩算法
5.2.3 Region 优化
- 预分区:根据数据分布预先创建 Region
- Region 大小:控制 Region 大小,避免过大或过小
- Region 分裂策略:配置合适的分裂策略
public void createPreSplitTable() {
// 创建表描述符
TableDescriptorBuilder tableBuilder = TableDescriptorBuilder.newBuilder(TableName.valueOf("products"));
// 添加列族
ColumnFamilyDescriptorBuilder cfBuilder1 = ColumnFamilyDescriptorBuilder.newBuilder(Bytes.toBytes("info"));
cfBuilder1.setCompressionType(Compression.Algorithm.SNAPPY);
cfBuilder1.setBlocksize(64 * 1024); // 64KB
tableBuilder.setColumnFamily(cfBuilder1.build());
ColumnFamilyDescriptorBuilder cfBuilder2 = ColumnFamilyDescriptorBuilder.newBuilder(Bytes.toBytes("detail"));
cfBuilder2.setCompressionType(Compression.Algorithm.SNAPPY);
tableBuilder.setColumnFamily(cfBuilder2.build());
// 创建预分区键
byte[][] splitKeys = generateSplitKeys();
// 创建表
admin.createTable(tableBuilder.build(), splitKeys);
}
private byte[][] generateSplitKeys() {
// 根据数据分布生成分区键
// ...
}
6. 总结
Elasticsearch 与 HBase 的集成为海量数据搜索系统提供了强大的支持,通过合理的数据模型设计、高效的数据同步机制、智能的查询路由策略和优化的索引设计,可以充分发挥两者的优势,构建高性能、高可用、高扩展性的搜索系统。
在实际实现中,需要根据具体业务需求和数据特点,选择合适的集成方案和优化策略,并通过持续监控和调优,确保系统稳定高效运行。
Spring Boot 项目实现
1. 项目基础结构
采用标准的 Maven 或 Gradle 项目结构,以下是一个典型的 Maven 项目结构示例:
search-system/
├── pom.xml # Maven 配置文件
├── src/
│ ├── main/
│ │ ├── java/
│ │ │ └── com/
│ │ │ └── example/
│ │ │ └── searchsystem/
│ │ │ ├── SearchSystemApplication.java # Spring Boot 启动类
│ │ │ ├── config/ # 配置类目录
│ │ │ │ ├── ElasticsearchConfig.java
│ │ │ │ ├── HBaseConfig.java
│ │ │ │ └── KafkaConfig.java
│ │ │ ├── controller/ # 控制器层
│ │ │ │ ├── SearchController.java
│ │ │ │ └── IndexController.java
│ │ │ ├── service/ # 服务层
│ │ │ │ ├── SearchService.java
│ │ │ │ ├── IndexService.java
│ │ │ │ └── SyncService.java
│ │ │ ├── repository/ # 数据访问层
│ │ │ │ ├── ElasticsearchRepository.java
│ │ │ │ └── HBaseRepository.java
│ │ │ ├── model/ # 数据模型
│ │ │ │ ├── Product.java
│ │ │ │ └── SearchRequest.java
│ │ │ ├── listener/ # 消息监听器
│ │ │ │ └── HBaseChangeListener.java
│ │ │ └── util/ # 工具类
│ │ │ └── RowKeyUtils.java
│ │ └── resources/
│ │ ├── application.yml # Spring Boot 配置文件
│ │ ├── logback-spring.xml # 日志配置文件
│ │ └── hbase-site.xml # HBase 客户端配置文件 (可选)
│ └── test/ # 测试代码目录
│ └── java/
│ └── com/
│ └── example/
│ └── searchsystem/
│ └── ...
└── logs/ # 日志文件目录
2. 关键依赖 (pom.xml)
<dependencies>
<!-- Spring Boot Core -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-actuator</artifactId>
</dependency>
<!-- Elasticsearch -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-elasticsearch</artifactId>
</dependency>
<!-- 或者使用原生 High Level Client -->
<!--
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>elasticsearch-rest-high-level-client</artifactId>
<version>7.17.x</version>
</dependency>
-->
<!-- HBase -->
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-client</artifactId>
<version>2.4.x</version> <!-- 与 HBase 集群版本一致 -->
<exclusions>
<!-- 排除可能冲突的依赖 -->
<exclusion>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
</exclusion>
<exclusion>
<groupId>log4j</groupId>
<artifactId>log4j</artifactId>
</exclusion>
<exclusion>
<groupId>javax.servlet</groupId>
<artifactId>servlet-api</artifactId>
</exclusion>
</exclusions>
</dependency>
<!-- 如果使用 Spring Data HBase (非官方,社区维护) -->
<!--
<dependency>
<groupId>com.github.CCweixiao</groupId>
<artifactId>hbase-sdk-spring-boot-starter</artifactId>
<version>x.x.x</version>
</dependency>
-->
<!-- Kafka (用于数据同步) -->
<dependency>
<groupId>org.springframework.kafka</groupId>
<artifactId>spring-kafka</artifactId>
</dependency>
<!-- Lombok (简化代码) -->
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<optional>true</optional>
</dependency>
<!-- Jackson (JSON 处理) -->
<dependency>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-databind</artifactId>
</dependency>
<!-- Spring Boot Test -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
</dependencies>
3. 配置文件 (application.yml)
server:
port: 8080
spring:
application:
name: search-system
# Elasticsearch 配置
elasticsearch:
rest:
uris: es-node1:9200,es-node2:9200,es-node3:9200 # Elasticsearch 集群地址
username: your_username # 可选,如果启用了安全认证
password: your_password # 可选
connection-timeout: 5s
socket-timeout: 30s
# HBase 配置 (如果使用原生 Client,则在 HBaseConfig 中配置)
hbase:
zookeeper:
quorum: zk-node1:2181,zk-node2:2181,zk-node3:2181 # Zookeeper 地址
property:
clientPort: 2181
# 可以将 hbase-site.xml 放在 classpath 下,会自动加载
# 或者在这里配置更多属性
# properties:
# hbase.client.retries.number: 3
# hbase.client.pause: 100
# Kafka 配置 (用于数据同步)
kafka:
bootstrap-servers: kafka-node1:9092,kafka-node2:9092
consumer:
group-id: es-sync-group
auto-offset-reset: earliest
key-deserializer: org.apache.kafka.common.serialization.StringDeserializer
value-deserializer: org.apache.kafka.common.serialization.StringDeserializer
producer:
key-serializer: org.apache.kafka.common.serialization.StringSerializer
value-serializer: org.apache.kafka.common.serialization.StringSerializer
management:
endpoints:
web:
exposure:
include: health,info,prometheus # 暴露 Actuator 端点
metrics:
tags:
application: ${spring.application.name}
logging:
level:
root: INFO
com.example.searchsystem: DEBUG
file:
name: logs/search-system.log
4. 核心代码示例
4.1 Elasticsearch 配置 (ElasticsearchConfig.java)
如果使用 Spring Data Elasticsearch,大部分配置会自动完成。如果需要更精细的控制或使用原生 High Level Client,可以自定义配置:
package com.example.searchsystem.config;
import org.apache.http.HttpHost;
import org.apache.http.auth.AuthScope;
import org.apache.http.auth.UsernamePasswordCredentials;
import org.apache.http.client.CredentialsProvider;
import org.apache.http.impl.client.BasicCredentialsProvider;
import org.elasticsearch.client.RestClient;
import org.elasticsearch.client.RestClientBuilder;
import org.elasticsearch.client.RestHighLevelClient;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.data.elasticsearch.config.AbstractElasticsearchConfiguration;
import org.springframework.data.elasticsearch.repository.config.EnableElasticsearchRepositories;
import org.springframework.util.StringUtils;
@Configuration
@EnableElasticsearchRepositories(basePackages = "com.example.searchsystem.repository")
public class ElasticsearchConfig extends AbstractElasticsearchConfiguration {
@Value("${spring.elasticsearch.rest.uris}")
private String[] uris;
@Value("${spring.elasticsearch.rest.username:#{null}}")
private String username;
@Value("${spring.elasticsearch.rest.password:#{null}}")
private String password;
@Override
@Bean
public RestHighLevelClient elasticsearchClient() {
HttpHost[] httpHosts = new HttpHost[uris.length];
for (int i = 0; i < uris.length; i++) {
String[] parts = uris[i].split(":");
httpHosts[i] = new HttpHost(parts[0], Integer.parseInt(parts[1]), "http");
}
RestClientBuilder builder = RestClient.builder(httpHosts);
// 配置认证信息
if (StringUtils.hasText(username) && StringUtils.hasText(password)) {
final CredentialsProvider credentialsProvider = new BasicCredentialsProvider();
credentialsProvider.setCredentials(AuthScope.ANY,
new UsernamePasswordCredentials(username, password));
builder.setHttpClientConfigCallback(httpClientBuilder -> httpClientBuilder
.setDefaultCredentialsProvider(credentialsProvider));
}
// 可以设置其他配置,如超时时间等
// builder.setRequestConfigCallback(...);
// builder.setHttpClientConfigCallback(...);
return new RestHighLevelClient(builder);
}
}
4.2 HBase 配置 (HBaseConfig.java)
配置 HBase 连接:
package com.example.searchsystem.config;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.client.Connection;
import org.apache.hadoop.hbase.client.ConnectionFactory;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import java.io.IOException;
@Configuration
public class HBaseConfig {
private static final Logger log = LoggerFactory.getLogger(HBaseConfig.class);
@Value("${spring.hbase.zookeeper.quorum}")
private String zookeeperQuorum;
@Value("${spring.hbase.zookeeper.property.clientPort}")
private String zookeeperClientPort;
@Bean(destroyMethod = "close")
public Connection hbaseConnection() throws IOException {
org.apache.hadoop.conf.Configuration config = HBaseConfiguration.create();
config.set("hbase.zookeeper.quorum", zookeeperQuorum);
config.set("hbase.zookeeper.property.clientPort", zookeeperClientPort);
// 可以设置更多 HBase 客户端参数
// config.set("hbase.client.retries.number", "3");
// config.set("hbase.client.pause", "100");
log.info("Creating HBase connection with Zookeeper quorum: {}", zookeeperQuorum);
Connection connection = ConnectionFactory.createConnection(config);
log.info("HBase connection created successfully.");
// 可以在这里添加一个简单的连接测试
try {
connection.getAdmin().listTableNames();
log.info("HBase connection test successful.");
} catch (IOException e) {
log.error("HBase connection test failed!", e);
// 根据需要决定是否抛出异常或尝试重连
}
return connection;
}
// 如果使用 Spring Data HBase 或类似库,可能需要配置 HBaseTemplate
/*
@Bean
public HBaseTemplate hbaseTemplate(Connection connection) {
// 配置 HBaseTemplate
return new HBaseTemplate(connection.getConfiguration());
}
*/
}
4.3 Elasticsearch Repository (ElasticsearchRepository.java)
使用 Spring Data Elasticsearch 简化操作:
package com.example.searchsystem.repository;
import com.example.searchsystem.model.ProductDocument; // 假设有 ProductDocument 实体
import org.springframework.data.elasticsearch.repository.ElasticsearchRepository;
import org.springframework.stereotype.Repository;
@Repository
public interface ProductElasticsearchRepository extends ElasticsearchRepository<ProductDocument, String> {
// 可以定义自定义查询方法
// List<ProductDocument> findByName(String name);
}
或者使用 RestHighLevelClient 进行原生操作:
package com.example.searchsystem.repository;
import com.example.searchsystem.model.ProductDocument;
import com.fasterxml.jackson.databind.ObjectMapper;
import org.elasticsearch.action.bulk.BulkRequest;
import org.elasticsearch.action.bulk.BulkResponse;
import org.elasticsearch.action.delete.DeleteRequest;
import org.elasticsearch.action.index.IndexRequest;
import org.elasticsearch.action.search.SearchRequest;
import org.elasticsearch.action.search.SearchResponse;
import org.elasticsearch.client.RequestOptions;
import org.elasticsearch.client.RestHighLevelClient;
import org.elasticsearch.common.xcontent.XContentType;
import org.elasticsearch.index.query.QueryBuilders;
import org.elasticsearch.search.builder.SearchSourceBuilder;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Repository;
import java.io.IOException;
import java.util.List;
import java.util.Map;
@Repository
public class ElasticsearchRepository {
private static final Logger log = LoggerFactory.getLogger(ElasticsearchRepository.class);
private static final String INDEX_NAME = "products"; // 索引名
@Autowired
private RestHighLevelClient client;
@Autowired
private ObjectMapper objectMapper;
public void indexDocument(String id, ProductDocument document) throws IOException {
IndexRequest request = new IndexRequest(INDEX_NAME)
.id(id)
.source(objectMapper.writeValueAsString(document), XContentType.JSON);
client.index(request, RequestOptions.DEFAULT);
log.debug("Indexed document with id: {}", id);
}
public void bulkIndexDocuments(List<ProductDocument> documents) throws IOException {
if (documents == null || documents.isEmpty()) {
return;
}
BulkRequest bulkRequest = new BulkRequest();
for (ProductDocument doc : documents) {
bulkRequest.add(new IndexRequest(INDEX_NAME)
.id(doc.getProductId()) // 假设 ProductDocument 有 getId() 方法
.source(objectMapper.writeValueAsString(doc), XContentType.JSON));
}
BulkResponse bulkResponse = client.bulk(bulkRequest, RequestOptions.DEFAULT);
if (bulkResponse.hasFailures()) {
log.warn("Bulk indexing had failures: {}", bulkResponse.buildFailureMessage());
// 处理失败情况
}
log.info("Bulk indexed {} documents", documents.size());
}
public void deleteDocument(String id) throws IOException {
DeleteRequest request = new DeleteRequest(INDEX_NAME, id);
client.delete(request, RequestOptions.DEFAULT);
log.debug("Deleted document with id: {}", id);
}
public SearchResponse search(SearchSourceBuilder sourceBuilder) throws IOException {
SearchRequest searchRequest = new SearchRequest(INDEX_NAME);
searchRequest.source(sourceBuilder);
log.debug("Executing ES search query: {}", sourceBuilder.toString());
return client.search(searchRequest, RequestOptions.DEFAULT);
}
}
4.4 HBase Repository (HBaseRepository.java)
封装 HBase 操作:
package com.example.searchsystem.repository;
import org.apache.hadoop.hbase.TableName;
import org.apache.hadoop.hbase.client.*;
import org.apache.hadoop.hbase.util.Bytes;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Repository;
import java.io.IOException;
import java.util.ArrayList;
import java.util.List;
import java.util.Map;
@Repository
public class HBaseRepository {
private static final Logger log = LoggerFactory.getLogger(HBaseRepository.class);
private static final TableName TABLE_NAME = TableName.valueOf("products"); // 表名
private static final byte[] CF_INFO = Bytes.toBytes("info"); // 列族名
private static final byte[] CF_DETAIL = Bytes.toBytes("detail");
@Autowired
private Connection hbaseConnection;
public void putData(String rowKey, Map<byte[], Map<byte[], byte[]>> data) throws IOException {
try (Table table = hbaseConnection.getTable(TABLE_NAME)) {
Put put = new Put(Bytes.toBytes(rowKey));
for (Map.Entry<byte[], Map<byte[], byte[]>> familyEntry : data.entrySet()) {
byte[] cf = familyEntry.getKey();
for (Map.Entry<byte[], byte[]> qualifierEntry : familyEntry.getValue().entrySet()) {
put.addColumn(cf, qualifierEntry.getKey(), qualifierEntry.getValue());
}
}
table.put(put);
log.debug("Put data for rowKey: {}", rowKey);
} catch (IOException e) {
log.error("Error putting data to HBase for rowKey: {}", rowKey, e);
throw e;
}
}
public Result getData(String rowKey) throws IOException {
try (Table table = hbaseConnection.getTable(TABLE_NAME)) {
Get get = new Get(Bytes.toBytes(rowKey));
// 可以指定获取特定列族或列
// get.addFamily(CF_INFO);
Result result = table.get(get);
log.debug("Get data for rowKey: {}, empty: {}", rowKey, result.isEmpty());
return result;
} catch (IOException e) {
log.error("Error getting data from HBase for rowKey: {}", rowKey, e);
throw e;
}
}
public List<Result> scanData(Scan scan) throws IOException {
List<Result> results = new ArrayList<>();
try (Table table = hbaseConnection.getTable(TABLE_NAME);
ResultScanner scanner = table.getScanner(scan)) {
for (Result result : scanner) {
results.add(result);
}
log.debug("Scan completed, found {} results.", results.size());
return results;
} catch (IOException e) {
log.error("Error scanning data from HBase", e);
throw e;
}
}
public void deleteData(String rowKey) throws IOException {
try (Table table = hbaseConnection.getTable(TABLE_NAME)) {
Delete delete = new Delete(Bytes.toBytes(rowKey));
table.delete(delete);
log.debug("Deleted data for rowKey: {}", rowKey);
} catch (IOException e) {
log.error("Error deleting data from HBase for rowKey: {}", rowKey, e);
throw e;
}
}
}
4.5 服务层 (SearchService.java)
实现搜索逻辑,包含查询路由和结果合并:
package com.example.searchsystem.service;
import com.example.searchsystem.model.ProductDocument;
import com.example.searchsystem.model.SearchRequest;
import com.example.searchsystem.model.SearchResult;
import com.example.searchsystem.repository.ElasticsearchRepository;
import com.example.searchsystem.repository.HBaseRepository;
import com.fasterxml.jackson.databind.ObjectMapper;
import org.apache.hadoop.hbase.Cell;
import org.apache.hadoop.hbase.CellUtil;
import org.apache.hadoop.hbase.client.Result;
import org.apache.hadoop.hbase.util.Bytes;
import org.elasticsearch.action.search.SearchResponse;
import org.elasticsearch.search.SearchHit;
import org.elasticsearch.search.builder.SearchSourceBuilder;
import org.elasticsearch.index.query.QueryBuilders;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;
import java.io.IOException;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
@Service
public class SearchService {
private static final Logger log = LoggerFactory.getLogger(SearchService.class);
@Autowired
private ElasticsearchRepository esRepository;
@Autowired
private HBaseRepository hbaseRepository;
@Autowired
private ObjectMapper objectMapper;
public SearchResult search(SearchRequest request) {
try {
// 1. 构建 Elasticsearch 查询
SearchSourceBuilder sourceBuilder = buildEsQuery(request);
// 2. 执行 Elasticsearch 查询
SearchResponse esResponse = esRepository.search(sourceBuilder);
// 3. 解析 Elasticsearch 结果
List<ProductDocument> esResults = parseEsResponse(esResponse);
// 4. (可选) 根据需要从 HBase 补充数据
if (request.isFetchFullDataFromHBase()) {
esResults = enrichWithHBaseData(esResults);
}
// 5. 封装最终结果
return buildFinalResult(esResponse, esResults);
} catch (IOException e) {
log.error("Error during search operation", e);
// 返回错误信息或抛出自定义异常
return SearchResult.error("Search failed due to internal error.");
}
}
private SearchSourceBuilder buildEsQuery(SearchRequest request) {
SearchSourceBuilder sourceBuilder = new SearchSourceBuilder();
// 根据 SearchRequest 构建查询条件、分页、排序、高亮、聚合等
if (request.getKeyword() != null && !request.getKeyword().isEmpty()) {
sourceBuilder.query(QueryBuilders.multiMatchQuery(request.getKeyword(), "name", "description", "features"));
}
sourceBuilder.from(request.getFrom());
sourceBuilder.size(request.getSize());
// ... 其他查询条件
return sourceBuilder;
}
private List<ProductDocument> parseEsResponse(SearchResponse response) {
List<ProductDocument> results = new ArrayList<>();
if (response.getHits() == null || response.getHits().getHits() == null) {
return results;
}
for (SearchHit hit : response.getHits().getHits()) {
try {
ProductDocument doc = objectMapper.readValue(hit.getSourceAsString(), ProductDocument.class);
doc.setProductId(hit.getId()); // 设置 ID
// 处理高亮等
results.add(doc);
} catch (IOException e) {
log.warn("Failed to parse document from ES hit: {}", hit.getId(), e);
}
}
return results;
}
private List<ProductDocument> enrichWithHBaseData(List<ProductDocument> esResults) throws IOException {
List<ProductDocument> enrichedResults = new ArrayList<>();
for (ProductDocument esDoc : esResults) {
Result hbaseResult = hbaseRepository.getData(esDoc.getProductId());
if (hbaseResult != null && !hbaseResult.isEmpty()) {
// 合并数据,以 HBase 数据为准或补充 ES 缺失字段
ProductDocument enrichedDoc = mergeData(esDoc, hbaseResult);
enrichedResults.add(enrichedDoc);
} else {
// HBase 中无数据,可能数据不一致或已被删除
log.warn("Data for product ID {} found in ES but not in HBase.", esDoc.getProductId());
enrichedResults.add(esDoc); // 或者根据策略决定是否保留
}
}
return enrichedResults;
}
private ProductDocument mergeData(ProductDocument esDoc, Result hbaseResult) {
// 实现合并逻辑,例如补充 HBase 中的 'detail' 列族数据
Map<String, String> details = new HashMap<>();
for (Cell cell : hbaseResult.getFamilyMap(Bytes.toBytes("detail")).values()) {
details.put(Bytes.toString(CellUtil.cloneQualifier(cell)), Bytes.toString(CellUtil.cloneValue(cell)));
}
// esDoc.setDetails(details); // 假设 ProductDocument 有 setDetails 方法
return esDoc;
}
private SearchResult buildFinalResult(SearchResponse esResponse, List<ProductDocument> items) {
SearchResult finalResult = new SearchResult();
finalResult.setTotalHits(esResponse.getHits().getTotalHits().value);
finalResult.setItems(items);
// 设置聚合结果、分页信息等
// finalResult.setAggregations(...);
return finalResult;
}
}
4.6 控制器层 (SearchController.java)
提供 RESTful API 接口:
package com.example.searchsystem.controller;
import com.example.searchsystem.model.SearchRequest;
import com.example.searchsystem.model.SearchResult;
import com.example.searchsystem.service.SearchService;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.http.ResponseEntity;
import org.springframework.web.bind.annotation.*;
@RestController
@RequestMapping("/api/search")
public class SearchController {
@Autowired
private SearchService searchService;
@PostMapping
public ResponseEntity<SearchResult> searchProducts(@RequestBody SearchRequest request) {
// 参数校验
if (request == null || (request.getKeyword() == null || request.getKeyword().trim().isEmpty())) {
// 简单的校验,实际应更完善
return ResponseEntity.badRequest().body(SearchResult.error("Invalid search request"));
}
SearchResult result = searchService.search(request);
return ResponseEntity.ok(result);
}
// 可以添加其他搜索相关的端点,如建议、聚合分析等
}
4.7 数据同步服务 (SyncService.java / HBaseChangeListener.java)
参考 elasticsearch_hbase_integration.md 中关于数据同步的代码示例,实现基于 Kafka 消息队列或 HBase Coprocessor 的数据同步逻辑。
5. 总结
以上提供了 Spring Boot 项目的基础结构、关键配置和核心代码示例,涵盖了与 Elasticsearch 和 HBase 的集成。开发者可以基于此框架,根据具体业务需求进行扩展和完善,例如添加更复杂的查询逻辑、实现更健壮的数据同步机制、引入缓存策略、完善监控和告警等。
大规模搜索系统最佳实践
构建和运维一个基于 Spring Boot、Elasticsearch 和 HBase 的大规模搜索系统需要遵循一系列最佳实践,以确保系统的高性能、高可用、高扩展性和易维护性。
1. 大规模部署建议
1.1 硬件选型与资源规划
- Elasticsearch 节点:
- 内存:推荐 64GB 或更高,JVM 堆内存建议设置为物理内存的一半,但不超过 30.5GB (避免指针压缩失效)。剩余内存留给操作系统文件缓存 (Lucene 使用)。
- CPU:多核 CPU (如 16 核或 32 核),高主频对查询性能有益。
- 存储:使用高性能 SSD (NVMe SSD 最佳),保证足够的 IOPS 和低延迟。根据数据量和副本数规划存储容量,预留 30% 以上的空闲空间。
- 网络:万兆以太网 (10GbE) 或更高,保证节点间通信和数据传输效率。
- HBase 节点 (RegionServer):
- 内存:推荐 64GB 或更高,JVM 堆内存根据 BlockCache 和 MemStore 配置,通常分配较大内存给 BlockCache。
- CPU:多核 CPU,对写入和 Compaction 友好。
- 存储:使用大容量 HDD 或 SSD (根据成本和性能需求选择),HDFS 通常部署在 HDD 上。确保 HDFS 集群的可靠性和性能。
- 网络:万兆以太网 (10GbE) 或更高。
- Spring Boot 应用节点:
- 内存:根据应用复杂度和并发量决定,通常 8GB 或 16GB 起步。
- CPU:根据请求处理逻辑和并发量决定,通常 4 核或 8 核起步。
- 网络:千兆或万兆以太网。
- 资源隔离:
- 物理隔离或使用容器化技术 (如 Kubernetes) 进行资源隔离,避免组件间资源争抢。
- Elasticsearch 和 HBase 最好部署在不同的物理机或 K8s Node 上。
1.2 集群规模与拓扑
- Elasticsearch 集群:
- 主节点 (Master):至少 3 个专用的主节点,不处理数据和查询请求,保证集群稳定性。
- 数据节点 (Data):根据数据量、副本数和查询负载确定数量。建议区分热、温、冷数据节点,优化成本和性能。
- 协调节点 (Coordinating):可选,用于分发查询请求,减轻数据节点负担。
- 分片与副本:合理规划分片数量 (避免过多或过少),副本数量至少为 1 (保证高可用)。主分片和副本分片应分布在不同可用区或机架。
- HBase 集群:
- HMaster:至少 2 个 HMaster 实现高可用。
- RegionServer:根据数据量和读写负载确定数量。确保 Region 在 RegionServer 间均匀分布。
- Zookeeper:独立的 Zookeeper 集群,至少 3 或 5 个节点。
- Spring Boot 应用:
- 部署多个实例,通过负载均衡器 (如 Nginx, HAProxy, K8s Service) 分发流量,实现高可用和水平扩展。
- 网络拓扑:
- 确保 Elasticsearch、HBase、Zookeeper、Kafka 和 Spring Boot 应用之间的网络低延迟、高带宽。
- 考虑跨可用区部署,提高容灾能力。
1.3 部署自动化
- 基础设施即代码 (IaC):使用 Terraform, Ansible, Chef, Puppet 等工具自动化基础设施的创建和配置。
- 容器化部署:使用 Docker 和 Kubernetes (K8s) 进行部署,简化管理、提高资源利用率和弹性伸缩能力。
- CI/CD:建立持续集成和持续部署流水线,自动化构建、测试和部署流程。
2. 性能优化策略
2.1 Elasticsearch 性能优化
- 索引设计:
- 映射优化:精确定义字段类型,禁用不需要索引的字段 (
enabled: false),对 keyword 字段禁用doc_values(如果仅用于过滤且不需要聚合排序)。 - 分片策略:避免单个分片过大 (建议 < 50GB),根据查询并发和数据量调整分片数。使用基于时间的索引 (如按天、按月) 管理时序数据。
- 路由优化:对于特定查询模式,使用自定义路由将相关文档路由到同一分片。
- 映射优化:精确定义字段类型,禁用不需要索引的字段 (
- 查询优化:
- 避免
select *:只查询需要的字段 (_source过滤)。 - 使用 Filter Context:对于精确匹配、范围查询等非评分场景,使用
filter子句,利用缓存。 - 避免深度分页:使用
search_after或 Scroll API 进行深度分页。 - 优化聚合查询:减少聚合基数,使用
terminate_after限制扫描文档数,考虑预计算或使用 Rollup。 - 减少 Shard 请求:优化查询路由,减少跨分片查询。
- 避免
- 写入优化:
- 批量写入 (Bulk API):使用 Bulk API 提高写入吞吐量,合理设置批次大小 (如 5-15MB)。
- 调整 Refresh Interval:适当延长
refresh_interval(如 30s 或更长),减少 Segment 生成频率,但会牺牲部分实时性。 - 调整 Translog 设置:
translog.durability设置为async可以提高写入性能,但可能丢失少量数据。 - 禁用 Swap:确保 Elasticsearch 节点的 Swap 已禁用。
- 优化 Segment Merging:调整合并策略和线程数。
- JVM 调优:
- 合理设置堆内存大小。
- 选择合适的垃圾回收器 (如 G1GC)。
- 监控 GC 活动,调整相关参数。
2.2 HBase 性能优化
- RowKey 设计:
- 避免热点:加盐、哈希、反转、时间戳后缀等策略。
- 长度适中:过长增加存储和索引开销。
- 查询友好:根据主要查询模式设计。
- 列族设计:
- 数量精简:列族数量不宜过多。
- 数据局部性:将经常一起访问的列放在同一列族。
- BlockSize:根据访问模式调整 BlockSize。
- 压缩:启用压缩 (如 Snappy, LZO, Gzip) 减少存储空间和 I/O。
- Bloom Filter:为 Get/Scan 操作启用 Bloom Filter (ROW 或 ROWCOL)。
- 读写优化:
- 批量读写:使用
Table.get(List<Get>)和Table.put(List<Put>)。 - 缓存利用:合理配置 BlockCache (LRUBlockCache, SlabCache, BucketCache)。
- Scan 优化:设置
setCaching调整 RPC 次数,使用 Filter 减少传输数据量,指定列族或列。 - 客户端 Buffer:调整
hbase.client.write.buffer大小。
- 批量读写:使用
- Compaction 优化:
- 调整 Compaction 策略和触发阈值。
- 配置 Compaction 线程数。
- 监控 Compaction 状态,避免积压。
- Region 管理:
- 预分区:建表时根据 RowKey 分布预分区。
- Region 大小:控制 Region 大小在合理范围 (如 10-50GB)。
- 负载均衡:确保 Region 在 RegionServer 间均匀分布。
2.3 Spring Boot 应用层优化
- 异步处理:对于耗时操作 (如复杂查询、数据同步),使用异步处理 (
@Async,CompletableFuture) 避免阻塞主线程。 - 连接池:合理配置 Elasticsearch 和 HBase 的客户端连接池大小。
- 缓存策略:
- 应用级缓存:使用 Caffeine, Redis 等缓存热点查询结果、配置信息等。
- 分布式缓存:对于多实例部署,使用 Redis 等分布式缓存。
- 缓存穿透、击穿、雪崩处理:实现相应的保护机制。
- API 设计:
- 分页与限制:API 接口强制分页,限制单次请求返回的数据量。
- 参数校验:严格校验输入参数,防止非法请求。
- 减少 RPC 调用:优化业务逻辑,减少对下游服务的调用次数。
- JVM 调优:
- 合理设置 JVM 堆内存、栈大小。
- 监控 GC 情况,选择合适的 GC 策略。
2.4 数据同步优化
- 同步方式选择:根据实时性要求选择 CDC、Observer 或批量同步。
- 消息队列调优:合理配置 Kafka Topic 分区数、副本数、压缩等。
- 同步服务:
- 水平扩展:部署多个同步服务实例消费 Kafka 消息。
- 批量处理:同步服务内部也应批量处理 Elasticsearch 的写入请求。
- 错误处理与重试:实现健壮的错误处理和重试机制,考虑死信队列。
- 幂等性保证:确保同步操作的幂等性,避免重复处理。
3. 监控与运维
3.1 关键监控指标
- Elasticsearch:
- 集群健康状态:
_cluster/health(status, number_of_nodes, relocating_shards, etc.) - 节点指标:CPU 使用率、内存使用率 (JVM Heap, OS Mem)、磁盘 I/O、磁盘空间、网络 I/O、GC 活动、线程池队列和拒绝数。
- 索引指标:索引速率、查询速率、查询延迟、Segment 数量、索引大小、Refresh/Flush 耗时。
- 集群健康状态:
- HBase:
- 集群状态:HMaster 状态、RegionServer 数量、Region 分布均衡度。
- RegionServer 指标:CPU、内存 (BlockCache Hit Rate, MemStore Size)、磁盘 I/O、网络 I/O、GC 活动、RPC 队列长度、请求延迟、Compaction 队列。
- Region 指标:读写请求数、StoreFile 数量、Region 大小。
- Spring Boot 应用:
- JVM 指标:堆内存使用、GC 次数和耗时、线程数。
- 应用指标:QPS、请求延迟、错误率、数据库连接池状态。
- 业务指标:搜索转化率、索引成功率、同步延迟等。
- 数据同步:
- Kafka 指标:消息生产/消费速率、Lag、分区状态。
- 同步服务指标:处理速率、错误率、端到端延迟。
3.2 监控工具
- 指标采集:Prometheus, Elasticsearch Metricbeat, HBase JMX Exporter。
- 日志收集:Elasticsearch Logstash Kibana (ELK Stack), Fluentd, Loki。
- 可视化与告警:Grafana, Kibana, Prometheus Alertmanager。
- 分布式追踪:Jaeger, Zipkin (需要应用代码集成)。
3.3 告警策略
- 关键指标阈值告警:CPU/内存/磁盘使用率过高、延迟过高、错误率升高、队列积压、集群状态异常 (Yellow/Red)、节点离线等。
- 日志关键字告警:监控错误日志中的关键信息。
- 业务异常告警:同步延迟过大、数据不一致等。
- 分级告警:区分不同严重级别的告警,通知到相应的负责人。
3.4 备份与恢复
- Elasticsearch:
- 使用 Snapshot API 定期备份到共享文件系统 (NFS) 或对象存储 (S3, HDFS)。
- 测试恢复流程。
- HBase:
- 使用 HBase Snapshot 功能进行在线备份。
- 使用 Replication 实现跨集群备份或容灾。
- 定期备份 HDFS 数据。
- 测试恢复流程。
- 配置备份:备份所有组件的配置文件。
3.5 灾难恢复
- 跨可用区/跨地域部署:将集群节点和副本分布在不同的物理区域。
- 数据复制:使用 Elasticsearch CCR (Cross-Cluster Replication) 和 HBase Replication 实现数据异地复制。
- 制定灾难恢复计划:明确 RPO (Recovery Point Objective) 和 RTO (Recovery Time Objective),定期演练恢复流程。
4. 常见问题与解决方案
4.1 数据不一致
- 原因:同步延迟、同步失败、网络问题、组件故障。
- 解决方案:
- 优化同步机制:提高同步实时性,实现可靠的错误处理和重试。
- 补偿机制:定期校验数据,对不一致的数据进行修复。
- 最终一致性:接受短暂不一致,通过校验和修复保证最终一致。
- 监控同步延迟:设置告警,及时发现同步问题。
4.2 Elasticsearch 查询性能慢
- 原因:查询复杂度高、数据量大、分片过多/过少、硬件资源瓶颈、索引设计不合理、GC 频繁。
- 解决方案:
- 优化查询语句:使用 Filter Context、避免深度分页、减少聚合基数。
- 优化索引设计:合理设置分片数、优化映射、使用路由。
- 硬件升级:增加内存、使用 SSD、升级 CPU。
- 集群扩展:增加数据节点。
- JVM 调优:调整堆内存、GC 参数。
- 缓存:利用 Elasticsearch 查询缓存和应用层缓存。
4.3 HBase 写入/读取热点
- 原因:RowKey 设计不合理,导致请求集中在少数 RegionServer。
- 解决方案:
- 优化 RowKey 设计:加盐、哈希、反转等。
- 预分区:建表时根据 RowKey 分布预分区。
- 监控 Region 负载:及时发现并处理热点 Region (手动 Split 或调整负载均衡)。
4.4 Elasticsearch 集群状态 Yellow/Red
- Yellow:主分片可用,但副本分片未分配 (通常是节点不足或磁盘空间问题)。
- 解决方案:检查节点状态、磁盘空间,增加节点或清理磁盘。
- Red:部分主分片不可用 (通常是节点丢失且无可用副本)。
- 解决方案:尽快恢复故障节点,检查数据丢失情况,可能需要从快照恢复。
4.5 HBase RegionServer 宕机
- 原因:硬件故障、OOM、配置错误。
- 解决方案:
- 高可用:HMaster 会自动将宕机 RegionServer 上的 Region 迁移到其他节点。
- 监控与告警:及时发现宕机事件。
- 根因分析:排查宕机原因,修复问题并重启节点。
- 数据恢复:WAL 会保证未持久化的数据在 Region 重新分配后恢复。
4.6 数据同步延迟过大
- 原因:同步服务处理能力不足、Kafka 积压、网络延迟、目标端 (ES) 写入瓶颈。
- 解决方案:
- 扩展同步服务:增加同步服务实例数或处理线程数。
- 优化 Kafka:增加 Topic 分区数,优化 Producer/Consumer 参数。
- 优化 Elasticsearch 写入:调整 Bulk 大小、Refresh Interval,扩展 ES 集群。
- 监控端到端延迟:定位瓶颈环节。
5. 总结
构建和运维大规模的 Spring Boot + Elasticsearch + HBase 搜索系统是一个复杂的工程,需要综合考虑硬件、架构、部署、性能、监控和运维等多个方面。遵循上述最佳实践,并结合具体业务场景持续优化和调整,是保障系统稳定、高效运行的关键。


![[6-01-01].第12节:字节码文件内容 - 属性表集合](https://img-blog.csdnimg.cn/direct/95c228a03ad64d2b977e0794e4fdebf8.png)