KaiwuDB 在边缘计算场景中主要应用于 工业物联网(IIoT)、智能电网、车联网 等领域,通过其分布式多模架构和轻量化设计,在边缘侧承担 数据实时处理、本地存储与协同分析 的核心作用。以下是具体案例和功能解析:
1. 典型边缘计算案例
(1) 工业设备边缘监控(智能制造)
- 场景:工厂产线设备传感器(如温度、振动)高频采集数据,需实时预警故障。
- KaiwuDB 的作用:
- 边缘存储:在边缘网关部署 KWDB,缓存原始时序数据(默认压缩比≥10:1),减少云端传输压力。
- 实时计算:通过 SQL 函数就地执行异常检测(如
WHERE vibration > 阈值),触发本地告警。 - 云端协同:仅上传聚合结果(如每小时均值)到中心集群,降低带宽消耗。
(2) 新能源电站管理(智能电网)
- 场景:分布式光伏/风电设备需本地处理发电量、环境数据。
- KaiwuDB 的作用:
- 多模融合:关联设备关系表(如电站拓扑)与时序数据(发电功率),生成带属性的分析报表。
- 断网续传:边缘节点在网络中断时持续存储数据,恢复后自动同步到云端。
- 动态负载均衡:通过
Range Partition自动均衡边缘节点间的数据分布。
(3) 智能车辆数据预处理(车联网)
- 场景:车载传感器(GPS、摄像头)产生海量数据,需实时过滤关键事件。
- KaiwuDB 的作用:
- 流式计算:通过
WINDOW函数实时计算车速突变、急刹车等事件。 - 分级存储:原始数据保留在车载边缘端,事件摘要上传至云端(符合 GDPR 数据最小化原则)。
- 流式计算:通过
2. 边缘场景中的核心能力
| 功能 | 技术实现 | 边缘价值 |
|---|---|---|
| 轻量级时序存储 | 列式存储 + 自适应压缩(ZSTD/Snappy) | 节省边缘设备存储空间(1TB 原始数据→约100GB) |
| 低延迟分析 | 内置流处理引擎(支持 OVER 窗口函数) | 本地响应时间<100ms,避免云端往返延迟 |
| 云边数据同步 | 基于 Raft 的增量同步协议,断点续传 | 弱网环境下仍保障数据一致性 |
| 资源隔离 | 通过 Resource Groups 限制边缘节点 CPU/内存占用 | 避免边缘计算影响设备控制任务 |
3. 边缘部署架构
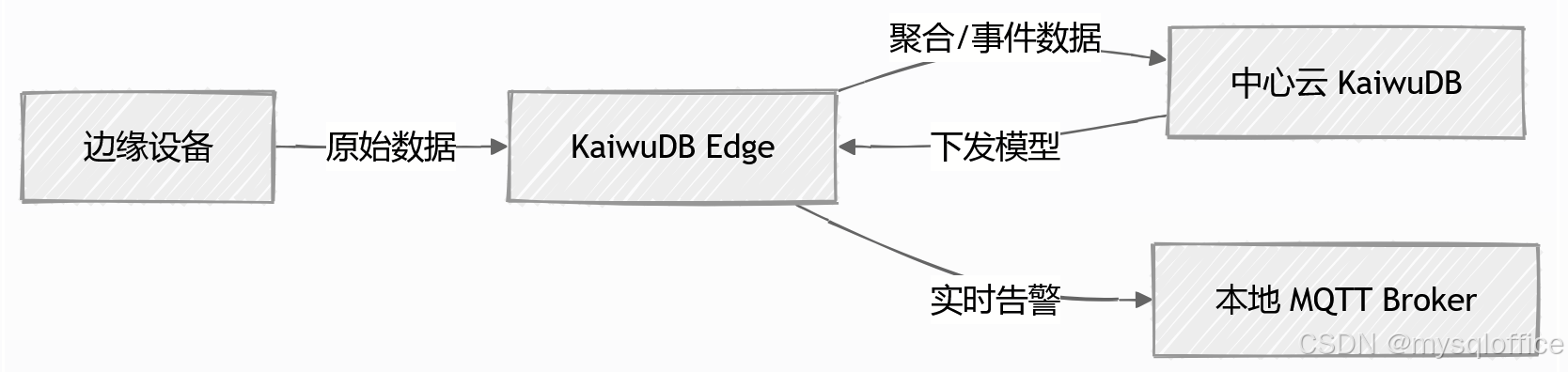
- 边缘层:运行 KWDB 社区版(无原生 AI),支持 ARM/x86 架构,最低配置要求:
- CPU:4核
- 内存:8GB
- 存储:100GB SSD(支持 TF 卡扩展)
- 云端:执行全局分析、模型训练,并通过 OTA 更新边缘计算规则。
4. 优势总结
- 降本增效:减少 70%+ 云端数据传输量,带宽成本降低 50%+。
- 实时性:边缘侧分析延迟<1秒,满足工业级实时控制需求。
- 离线可用:支持边缘设备完全断网运行,数据最长缓存 30 天。