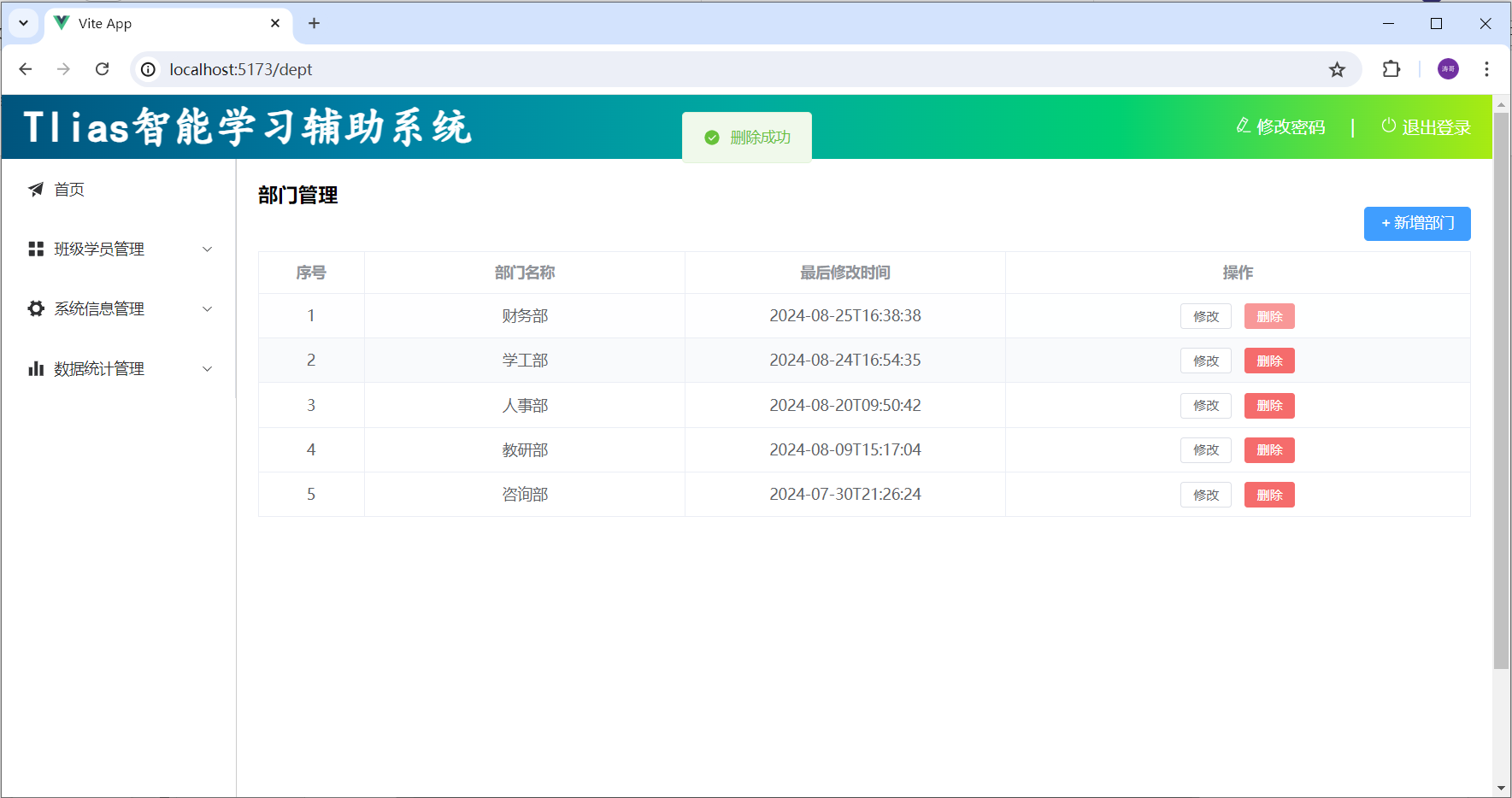
Count(1)查询过程
如果表里只有主键索引,没有二级索引时,InnoDB循环遍历主键索引,将读取到的记录返回给Server层,但是不会读取记录中的任何字段的值,因为count函数的参数是1,不是字段,所以不需要读取记录中的字段值。当遇到的不是NULL,server层每从InnoDB读取到一条记录,就将count变量加1。
Count(*)其实等于count(0),使用Count(*)时,MySQL将*参数转化为参数0
Count(1)执行效率会比Count(主键字段)高一点的原因:就是不需要读取记录中的字段值。
当执行主键索引,如果表里存在二级索引,优化器会选择二级索引进行扫描
原因:体积更小,只包含索引列和主键值,密度更高,每页能存储更多记录,减少I/O次数
Count(字段)效率最差,因为采用全表扫描的方式来统计。
效率比较
Count(*)=count(1)>count(主键字段)>count(字段)