Rust 学习笔记:Cargo 工作区
- Rust 学习笔记:Cargo 工作区
- 创建工作区
- 在工作区中创建第二个包
- 依赖于工作区中的外部包
- 向工作区添加测试
- 将工作区中的 crate 发布到 crates.io
- 添加 add_two crate 到工作区
- 总结
Rust 学习笔记:Cargo 工作区
随着项目的发展,库 crate 可能会越来越大,你可能希望将包(package)进一步拆分为多个库 crate。Cargo 提供了一个称为工作区(Workspaces)的特性,它可以帮助管理串联开发的多个相关包。
创建工作区
工作区是一组共享相同 Cargo.lock 和输出目录的包。
构建工作区有多种方法,我们只展示一种常见的方法。我们将有一个包含二进制文件和两个库的工作区。提供主要功能的二进制文件将依赖于这两个库。一个库提供一个 add_one 函数,另一个库提供一个 add_two 函数。这三个 crate 将是同一个工作区的一部分。
我们首先为工作区创建一个新目录:
$ mkdir add
$ cd add
接下来,在 add 目录中,我们创建 Cargo.toml 文件,它将配置整个工作区。这个文件没有 [package] 部分。相反,它将以一个 [workspace] 部分开始,该部分将允许我们向工作区添加成员。通过将解析器设置为 3,我们还强调在工作区中使用 Cargo 解析器算法的最新和最好版本。
[workspace]
resolver = "3"
接下来,我们将通过在 add 目录中运行 cargo new 来创建加法器二进制 crate:

在工作区内运行 cargo new 还会自动将新创建的包添加到工作区内 Cargo.toml 的 [workspace] 定义中的 members 键中,如下所示:
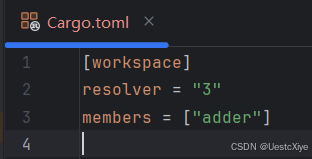
此时,我们可以通过运行 cargo build 来构建工作区。add 目录下的文件应该是这样的:
├── Cargo.lock
├── Cargo.toml
├── adder
│ ├── Cargo.toml
│ └── src
│ └── main.rs
└── target
工作区在顶层有一个目标目录,编译后的工件将被放置到该目录中。adder 包没有自己的目标目录。即使我们要从 adder 目录中运行 cargo build,编译后的工件仍然会在 add/target 而不是 add/adder/target 中结束。Cargo 在工作区的目标目录中采用这样的结构,因为工作区的 crate 是相互依赖的。如果每个 crate 都有自己的目标目录,那么每个 crate 都必须重新编译工作区中的其他 crate,以便将工件放置在自己的目标目录中。通过共享一个目标目录,crate 可以避免不必要的重新构建。
在工作区中创建第二个包
接下来,让我们在工作区中创建另一个成员包,并将其命名为 add_one。
生成一个名为 add_one 的库 crate:

顶层的 Cargo.toml 文件现在将在 members 列表中包含 add_one 路径:
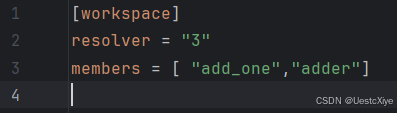
add 目录下的文件树为:
├── Cargo.lock
├── Cargo.toml
├── add_one
│ ├── Cargo.toml
│ └── src
│ └── lib.rs
├── adder
│ ├── Cargo.toml
│ └── src
│ └── main.rs
└── target
在 add_one/src/lib.rs 中添加一个 add_one 函数:
pub fn add_one(x: i32) -> i32 {
x + 1
}
现在,我们让 adder 包依赖 add_one 库。首先,我们需要在 adder/Cargo.toml 上添加一个对 add_one 的路径依赖。
[dependencies]
add_one = { path = "../add_one" }
Cargo 并不假设工作区中的 crate 将相互依赖,因此我们需要明确依赖关系。
接下来,让我们在 adder crate 中使用 add_one 函数,修改 adder/src/main.rs:
fn main() {
let num = 10;
println!("Hello, world! {num} plus one is {}!", add_one::add_one(num));
}
在顶级的 add 目录中运行 cargo build 来构建工作区。
要从 add 目录运行二进制 crate,我们可以使用 cargo run 加上 -p 参数后接包名来指定我们想要运行的工作区中的哪个包。
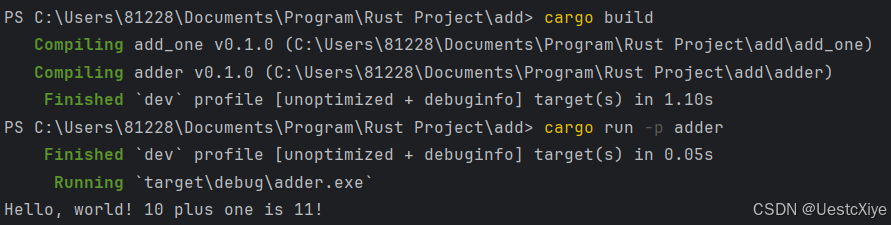
运行了 adder/src/main.rs 中的代码,代码依赖于 add_one crate。
依赖于工作区中的外部包
注意,工作区在顶层只有一个 Cargo.lock 文件,而不是在每个 crate 的目录中都有一个 Cargo.lock。这确保了所有的 crate 都使用相同版本的所有依赖项。
如果我们将 rand 包添加到 adder/Cargo.toml 和 add_one/Cargo.toml 文件中,Cargo 将把这两个包解析为一个 rand 版本,并将其记录在一个 Cargo.lock 中。
让工作区中的所有 crate 使用相同的依赖关系意味着这些 crate 将始终相互兼容。让我们将 rand crate 添加到 add_one/Cargo.toml 文件的 [dependencies] 部分,这样我们就可以在 add_one crate 中使用 rand crate 了:
[dependencies]
rand = "0.8.5"
我们现在可以在 add_one/src/lib.rs 中添加 use rand;。通过在 add 目录中运行 cargo build 来构建整个工作区,将引入并编译 rand crate。我们将得到一个警告,因为我们没有引用我们带入范围的 rand:
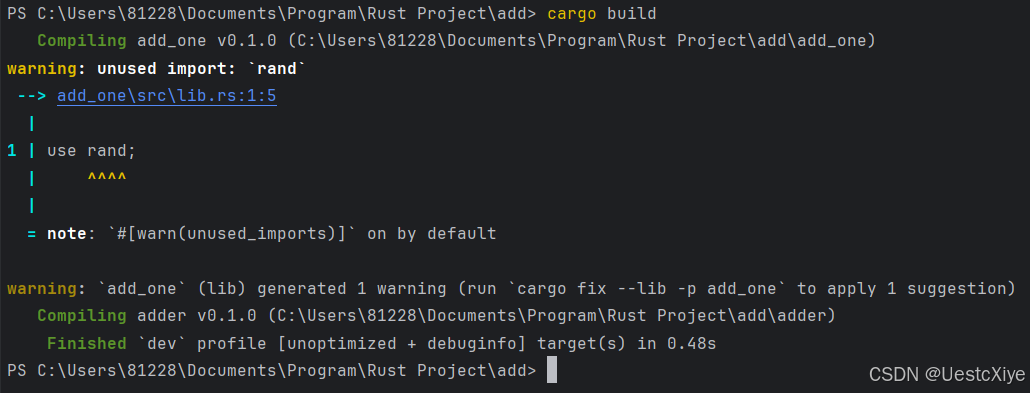
即使在工作区的某个地方使用了 rand,我们也不能在工作区的其他 crate 中使用它,除非我们也将 rand 添加到它们的 Cargo.toml 文件中。
例如,如果我们将 use rand; 添加到 adder/src/main.rs 文件中,我们将得到一个错误:
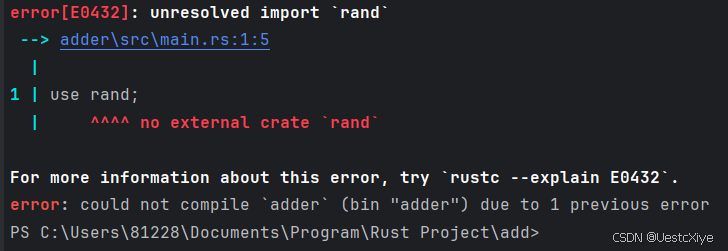
要解决这个问题,需要编辑 adder/Cargo.toml 文件,并指出 rand 也是它的依赖项。
[dependencies]
add_one = { path = "../add_one"}
rand = "0.8.5"
构建 adder 包会将 rand 添加到 Cargo.lock 中 adder 的依赖列表中,但不会下载 rand 的其他副本。Cargo 的语义版本规则将确保工作区中使用 rand 包的每个包中的每个 crate 使用相同的版本,只要它们指定 rand 的兼容版本,就可以节省空间,并确保工作区中的 crate 彼此兼容。
假设同一工作区中有一个 crate 依赖 rand 0.8.0,另一个 crate 依赖 rand 0.8.1。根据语义版本规则,这两个语义版本是兼容的,所以这两个 crate 都使用 rand 0.8.1,或者使用更新的补丁版本,比如 0.8.2。
如果工作区中的 crate 指定了相同依赖项的不兼容版本,Cargo 将解析每个版本,但仍将尝试解析尽可能少的版本。
假设同一工作区中有一个 crate 依赖 rand 0.8.0,另一个 crate 依赖 rand 0.7.0。因为语义版本不兼容,Cargo 为每个 crate 使用不同版本的 rand。
向工作区添加测试
在 add_one crate 中添加一个对 add_one 函数的测试:
pub fn add_one(x: i32) -> i32 {
x + 1
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn it_works() {
assert_eq!(3, add_one(2));
}
}
现在在顶级 add 目录中运行 cargo test。在这样的工作区中运行 cargo test 将为工区中的所有 crate 运行测试:
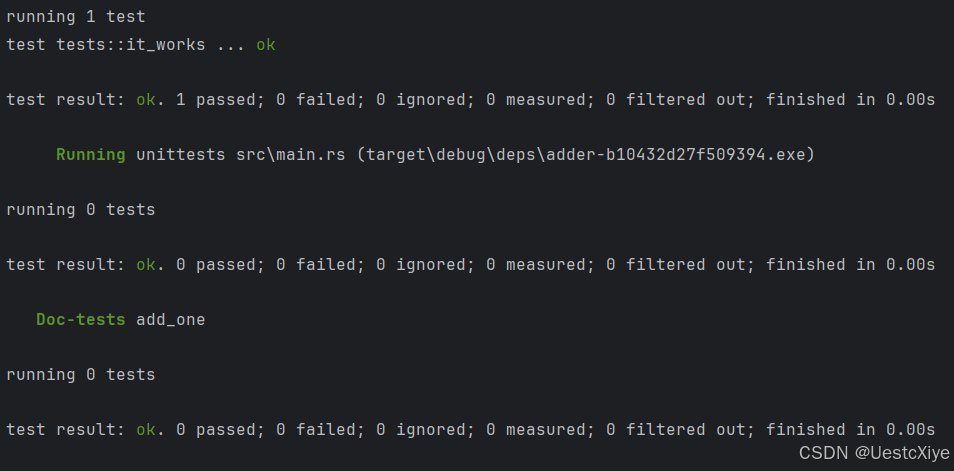
输出的第一部分显示通过了 add_one crate 中的 it_works 测试。下一节显示在 adder crate 中没有找到任何测试,最后一节显示在 add_one crate 中没有找到任何文档测试。
我们还可以通过使用 -p 标志并指定我们想要测试的 crate 的名称,在顶层目录下对工作区中的特定 crate 运行测试:
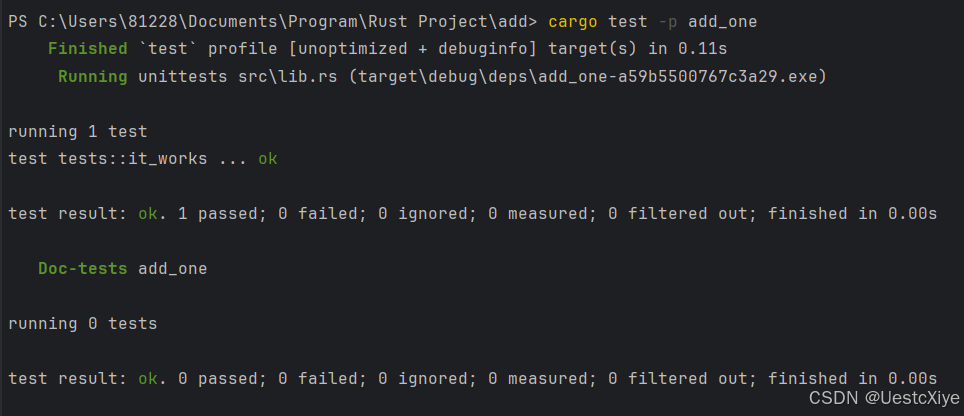
该输出显示 cargo test 只运行了add_one crate 的测试,而没有运行 adder crate 的测试。
将工作区中的 crate 发布到 crates.io
如果将工作区中的 crate 发布到 crates.io,那么工作区中的每个 crate 都需要单独发布。与 cargo test 类似,我们可以通过使用 -p 标志并指定我们想要发布的 crate 的名称,在工作区中发布特定的 crate。
添加 add_two crate 到工作区
以与 add_one crate 类似的方式将 add_two crate 添加到该工作区。

adder/Cargo.toml:
[dependencies]
add_one = { path = "../add_one"}
add_two = { path = "../add_two"}
rand = "0.8.5"
在 add_two/src/lib.rs 中添加以下代码:
pub fn add_two(x: i32) -> i32 {
x + 2
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn it_works() {
assert_eq!(4, add_two(2));
}
}
修改 adder/src/main.rs:
fn main() {
let num = 10;
println!("Hello, world! {num} plus one is {}!", add_one::add_one(num));
println!("Hello, world! {num} plus two is {}!", add_two::add_two(num));
}
运行 cargo run:

运行 cargo test:
PS C:\Users\81228\Documents\Program\Rust Project\add> cargo test
Compiling add_two v0.1.0 (C:\Users\81228\Documents\Program\Rust Project\add\add_two)
Compiling adder v0.1.0 (C:\Users\81228\Documents\Program\Rust Project\add\adder)
Finished `test` profile [unoptimized + debuginfo] target(s) in 0.43s
Running unittests src\lib.rs (target\debug\deps\add_one-a59b5500767c3a29.exe)
running 1 test
test tests::it_works ... ok
test result: ok. 1 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Running unittests src\lib.rs (target\debug\deps\add_two-927f837920a25f8c.exe)
running 1 test
test tests::it_works ... ok
test result: ok. 1 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Running unittests src\main.rs (target\debug\deps\adder-30ef0042878a10a4.exe)
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Doc-tests add_one
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Doc-tests add_two
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
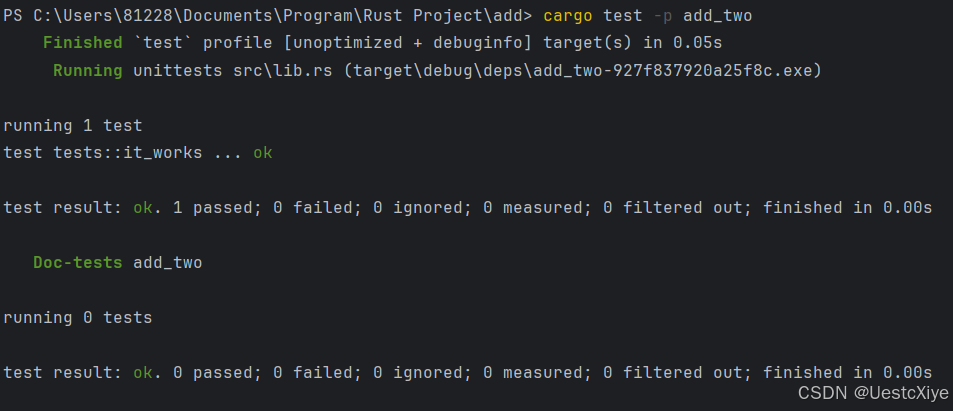
运行 cargo test -p add_two:
总结
随着项目的增长,请考虑使用工作区:它使得开发者能够使用更小、更容易理解的组件,而不是使用一大块代码。此外,如果经常同时更改,则将 crate 保存在工作区中可以使它们之间的协调更容易。



![MCP:让AI工具协作变得像聊天一样简单 [特殊字符]](https://i-blog.csdnimg.cn/direct/e09176c05a7144f8982a633e92c816ca.png)