连接管理是一个 HTTP 的关键话题:打开和保持连接在很大程度上影响着网站和 Web 应用程序的性能。在 HTTP/1.x 里有多种模型:短连接、_长连接_和 HTTP 流水线。
下面分别来详细解释
短连接
HTTP 协议最初(0.9/1.0)是个非常简单的协议,通信过程也采用了简单的 “请求 - 应答” 方式。
它底层的数据传输基于 TCP/IP,每次发送请求前需要先与服务器建立连接,收到响应报文后会立即关闭连接。
因为客户端与服务器的整个连接过程很短暂,不会与服务器保持长时间的连接状态,所以就被称为 “短连接”(short-lived connections)。早期的 HTTP 协议也被称为是 “无连接” 的协议。
这是 HTTP/1.0 的默认模型(如果没有指定 Connection 协议头,或者是值被设置为 close)。而在 HTTP/1.1 中,只有当 Connection 被设置为 close 时才会用到这个模型。
问题
在 TCP 协议里,建立连接和关闭连接都是非常 “昂贵” 的操作。TCP 建立连接要有“三次握手”,发送 3 个数据包,需要 1 个 RTT;关闭连接是“四次挥手”,4 个数据包需要 2 个 RTT。
而 HTTP 的一次简单 “请求 - 响应” 通常只需要 4 个包,如果不算服务器内部的处理时间,最多是 2 个 RTT。这么算下来,浪费的时间就是“3÷5=60%”,有三分之二的时间被浪费掉了,传输效率低得惊人。
长连接
针对短连接暴露出的缺点,HTTP 协议就提出了 “长连接” 的通信方式,也叫 “持久连接”(persistent connections)、“连接保活”(keep alive)、“连接复用”(connection reuse)。
把 TCP 的连接和关闭时间成本由原来的一个 “请求 - 应答” 均摊到多个 “请求 - 应答” 上。
这样虽然不能改善 TCP 的连接效率,但基于 “分母效应”,每个 “请求 - 应答” 的无效时间就会降低不少,整体传输效率也就提高了。
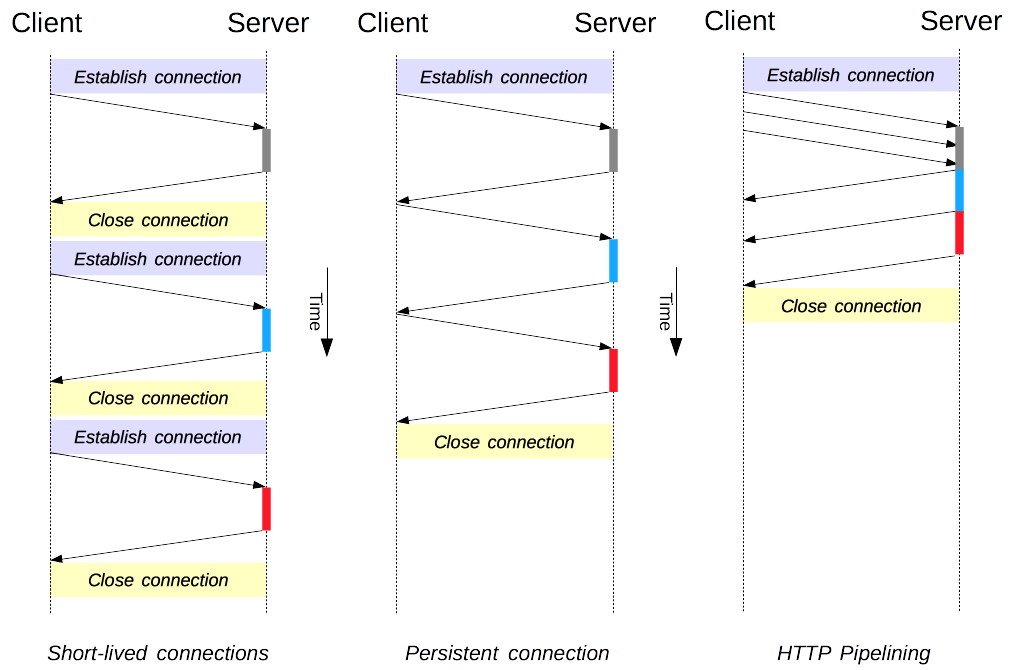
短连接与长连接的对比示意图。
缺点
就算是在空闲状态,它还是会消耗服务器资源,而且在重负载时,还有可能遭受 DoS 攻击。这种场景下,可以使用非长连接,即尽快关闭那些空闲的连接,也能对性能有所提升。
HTTP/1.0 里默认并不使用长连接。把 Connection 设置成 close 以外的其他参数都可以让其保持长连接,通常会设置为 retry-after。
在 HTTP/1.1 里,默认就是长连接的,不再需要标头(但我们还是会把它加上,万一某个时候因为某种原因要退回到 HTTP/1.0 呢)。
HTTP 流水线
默认情况下,HTTP 请求是按顺序发出的。下一个请求只有在当前请求收到响应过后才会被发出。由于会受到网络延迟和带宽的限制,在下一个请求被发送到服务器之前,可能需要等待很长时间。
流水线是在同一条长连接上发出连续的请求,而不用等待应答返回。这样可以避免连接延迟。理论上讲,性能还会因为两个 HTTP 请求有可能被打包到一个 TCP 消息包中而得到提升。就算 HTTP 请求不断的继续,尺寸会增加,但设置 TCP 的最大分段大小(MSS)选项,仍然足够包含一系列简单的请求。
并不是所有类型的 HTTP 请求都能用到流水线:只有幂等方式,比如 GET、HEAD、PUT 和 DELETE 能够被安全地重试。如果有故障发生时,流水线的内容要能被轻易的重试。
今天,所有遵循 HTTP/1.1 标准的代理和服务器都应该支持流水线,虽然实际情况中还是有很多限制:一个很重要的原因是,目前没有现代浏览器默认启用这个特性。
缺点
● 正确的实现流水线是复杂的:传输中的资源大小、多少有效的 RTT 会被用到以及有效带宽都会直接影响到流水线提供的改善。不知道这些的话,重要的消息可能被延迟到不重要的消息后面。这个重要性的概念甚至会演变为影响到页面布局!因此 HTTP 流水线在大多数情况下带来的改善并不明显。
● 流水线受制于队头阻塞(HOL)问题。
由于这些原因,流水线已被 HTTP/2 中更好的算法——==多路复用(multiplexing)==所取代。