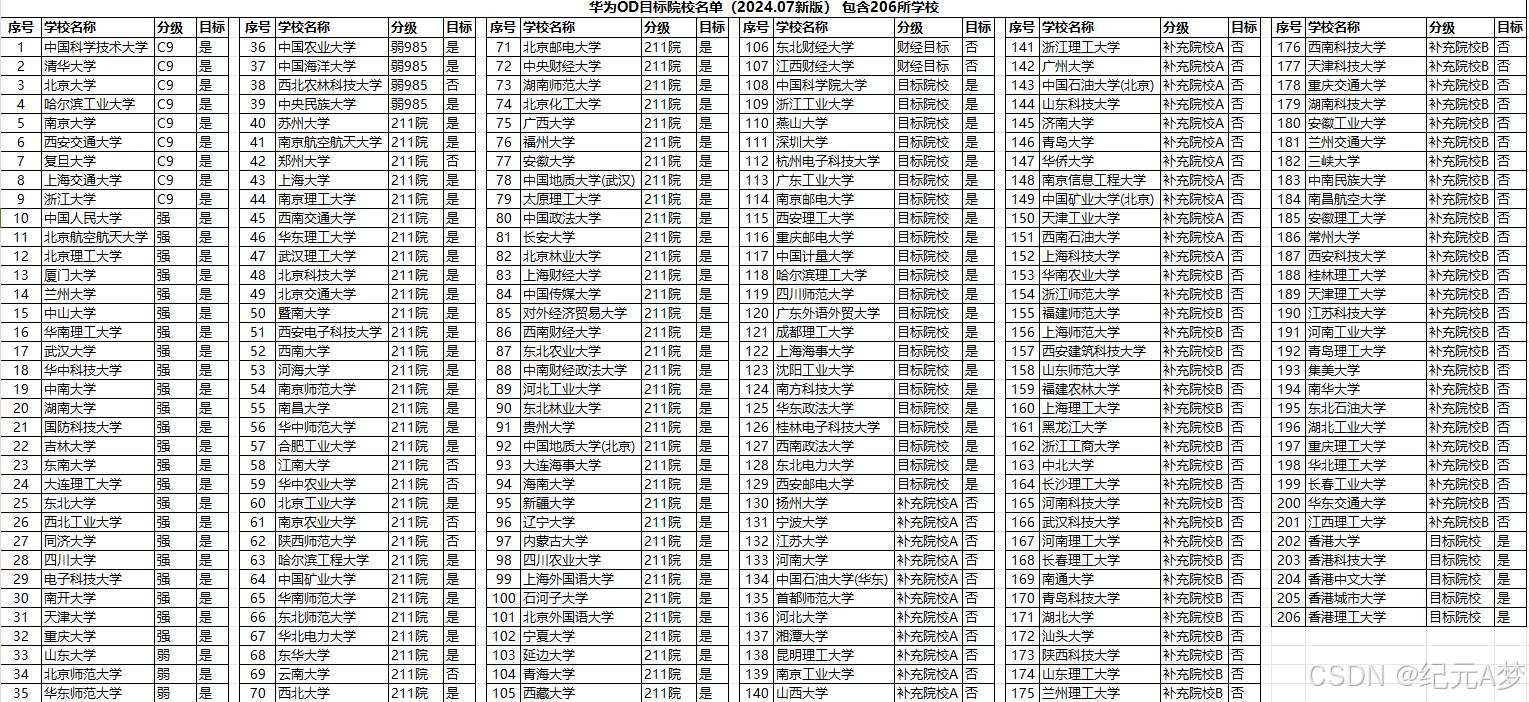
“Nicolas Fleury, Technical Architect” 这份主题为 “C++ in Huge AAA Games” 的内容理解,可以从几个方面切入:
1. 背景
- AAA大作游戏(Triple-A Games)指的是预算高、规模大、制作精良的顶级游戏项目。
- 这些游戏通常代码库庞大,系统复杂,性能要求极高。
- C++ 是游戏开发的主力语言,因其高性能和灵活性。
2. C++ 在 AAA 游戏中的角色
- 性能关键:需要极致优化来保证游戏的流畅运行,尤其是在图形渲染、物理模拟、AI等模块。
- 复杂系统构建:大型游戏包含众多子系统(渲染、音频、物理、网络、UI等),C++ 提供面向对象与模板元编程支持,帮助组织这些复杂逻辑。
- 跨平台支持:游戏需要运行在多种设备(PC、主机、移动端),C++能够实现跨平台的核心逻辑代码。
- 内存管理:手动管理内存对于游戏性能和资源控制至关重要,C++允许细粒度的内存操作。
3. 技术架构和设计挑战
- 代码维护与扩展性:AAA游戏开发周期长,团队庞大,代码架构设计必须兼顾扩展和维护。
- 模块化设计:通过模块和插件机制支持不同游戏内容和功能的快速迭代。
- 工具链支持:开发专用工具(编辑器、调试器、性能分析器)提升开发效率。
- 并发和异步编程:利用多核CPU,提高性能,避免卡顿。
4. 现代C++技术应用
- 利用C++11/14/17/20的新特性(智能指针、并发库、模板改进等)提高代码质量和性能。
- 模板元编程和编译期优化(比如CRTP)在游戏引擎中被广泛使用。
- 避免不必要的虚函数调用,提升性能。
- 使用自定义内存分配器,减少内存碎片和GC停顿。
5. 实际案例和经验分享(可能内容)
- 如何在游戏引擎中实现高效的事件系统、消息传递机制。
- 大型代码库的版本控制和持续集成策略。
- 代码规范和团队协作实践。
总结
Nicolas Fleury讲述的“C++在大型AAA游戏开发中的应用”,主要聚焦如何利用C++的语言特性和工具,解决游戏开发中性能、架构、维护等方面的巨大挑战,确保游戏项目顺利开发与高效运行。
Ubisoft Montreal(育碧蒙特利尔) 在游戏开发中的基本组织与技术环境:
Ubisoft Montreal 的概况
1. 规模庞大
- 2600+ 员工:育碧蒙特利尔是全球最大的游戏工作室之一。
- 相比一般游戏公司(几十人或几百人),Ubisoft Montreal 的规模非常罕见,类似一个“软件开发城市”。
2. 超大型项目支持
- 单个项目可达 1000 人:这包括全球多个工作室协作(例如加拿大、法国、中国等)。
- 蒙特利尔本地可达 400 人:意味着一个项目在单一地点就可以配备数百名开发者,规模相当于一整家公司。
技术团队与环境
3. Technology Group(技术组)
- 300 名开发者专注于技术平台与工具链,不是直接做游戏内容。
- 他们负责的可能包括:
- 游戏引擎的开发与维护(如Anvil、Snowdrop等)
- 渲染、物理、音频、网络等底层系统
- 开发工具(如关卡编辑器、调试器)
- 构建系统、CI/CD 等
4. Windows 为主的开发环境
- 虽然游戏是跨平台(PC, Xbox, PS5等),但开发和调试主要在 Windows 平台进行:
- Visual Studio 是主要 IDE
- 使用 Windows 编译工具链
- 内部工具和脚本以 Windows 兼容为主
总结
这部分内容说明:
Ubisoft Montreal 是一个高度工业化、标准化的游戏生产工厂,拥有巨大的人员与技术投入,开发流程以 Windows 为核心平台支撑全球协作,是全球 AAA 游戏开发的顶级阵地之一。
这段内容展示了 AAA 级大作(Big Games) 的实际代码规模、技术架构与构建效率,我们逐点深入理解:
示例游戏 & 代码量
1. Assassin’s Creed Unity(刺客信条:大革命)
- 6.5M 行 C++ 代码(游戏团队代码)
➤ 游戏逻辑、AI、UI、任务系统、场景管理等。 - 9M 行外部 C++ 代码
➤ 引擎、工具链、第三方库、平台抽象层等,可能由技术组或跨项目共用代码提供。 - 5M 行 C# 代码
➤ 常用于工具开发(如关卡编辑器、调试器、资源管理工具等),也可能用于运行时脚本系统(如 UI 行为)。
合计:20.5M 行代码(主要是 C++ + C#)
2. Rainbow Six: Siege(彩虹六号:围攻)
- 3.5M 行 C++(游戏团队)
➤ 控制射击机制、地图交互、多人同步等。 - 4.5M 行 C++(Technology Group)
➤ 引擎、网络栈、安全系统、低延迟通信优化等。
合计:8M 行 C++
构建效率
Rebuild All(全量构建):3 到 5 分钟
- 这是非常快的重构建速度,尤其考虑到代码行数数百万。
- 表明:
- 使用了极其高效的 增量编译系统(如 Incredibuild、FASTBuild、ccache)
- 模块化项目结构(避免全项目重编译)
- 高性能硬件和构建服务器分布式编译支持
- 精心优化的依赖管理和头文件结构
分析重点
| 项目 | 总代码量 | 语言构成 | 说明 |
|---|---|---|---|
| AC Unity | 20.5M LOC | C++ + C# | 复杂任务系统 + 强大的编辑器工具 |
| R6 Siege | 8M LOC | 全部 C++ | 更专注于实时性、多人网络与低延迟处理 |
| 编译速度 | 3–5 分钟 | 可能用了分布式编译 | 说明开发流程高度工业化 |
总结
这些数据揭示:
- 大型游戏的复杂性远超一般软件项目,涉及千万级代码量,多个语言混合。
- 引擎层与游戏层严格分离,由不同团队负责维护。
- 快速构建是生产力的核心指标,即便如此庞大的项目也能几分钟内构建,依赖于强大的工具链与架构设计。
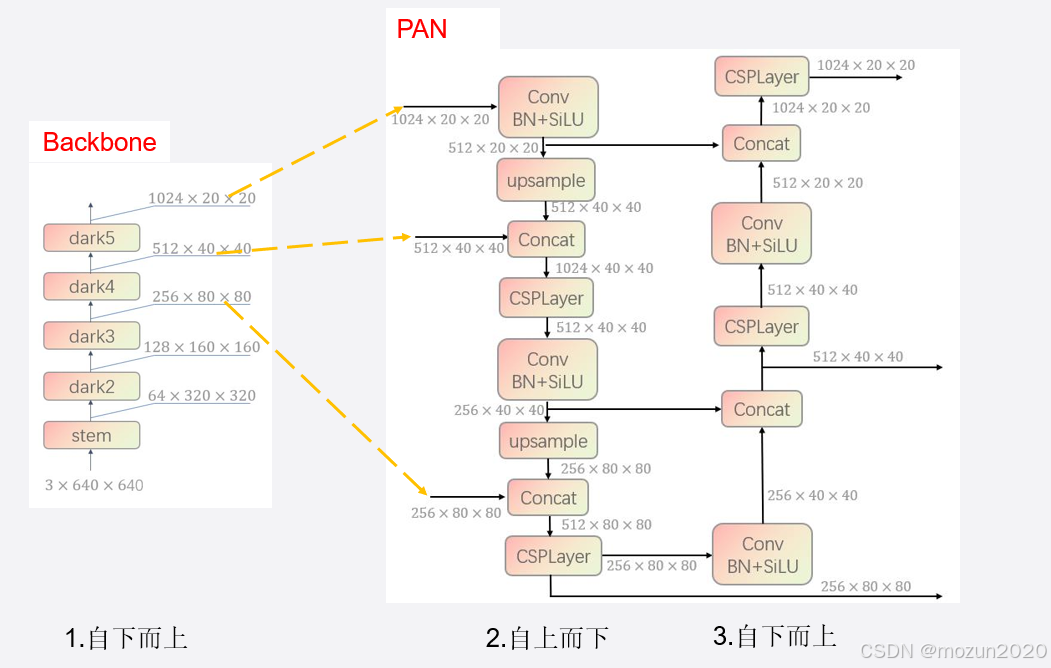
AAA 游戏的代码结构分层(Code Structure)。下面是每一层的功能解释和理解:
1. Gameplay(游戏逻辑层)
- 定义:游戏玩法、角色行为、任务系统、AI、动画逻辑等都在这一层实现。
- 开发者:主要由游戏设计师和游戏程序员负责。
- 示例:
- 玩家移动、攻击
- NPC AI 行为树
- 任务完成条件与剧情触发
- 依赖:调用引擎提供的功能(如物理、渲染、网络等)
2. Engine(游戏引擎层)
- 定义:提供通用的运行时支持,是 gameplay 层的基础。
- 包含模块:物理系统、动画系统、资源加载、声音播放、渲染抽象、场景管理。
- 特性:
- 重用性强(可被多个游戏复用)
- 与平台无关(抽象出平台差异)
- 团队:由 Technology Group 或核心引擎团队负责
3. TCP/IP(网络通信层)
- 定义:处理客户端与服务器之间的数据传输。
- 功能:
- 封装 UDP/TCP 通信逻辑
- 提供可靠性(重传、拥塞控制)
- 实现网络同步、状态复制(replication)
- 典型用途:多人游戏(如《彩虹六号》)的核心模块
4. Graphic(图形层)
- 定义:封装图形渲染的具体细节,处理 GPU 绘制逻辑。
- 功能模块:
- 渲染管线(光照、阴影、后处理)
- 材质系统
- 着色器编译与调度
- 多平台支持(如 DirectX、Vulkan、Metal 等)
- 团队专门负责性能调优与平台兼容性
5. Core(核心基础库层)
- 定义:提供最底层的工具和系统接口,是所有其他模块的基础。
- 功能:
- 内存管理
- 多线程与并发工具
- 日志系统、时间管理
- 平台抽象层(文件系统、IO、窗口系统等)
6. Editor(编辑器工具层)
- 语言:通常使用 C#
- 定义:用于游戏开发过程中的内容创建和调试工具。
- 示例:
- 地图编辑器
- AI 行为编辑器
- 动画控制器可视化工具
- 资源浏览器、调试面板
- 优势:C# 开发效率高,GUI 框架(如 WPF)丰富,适合工具开发
总体结构层次(自顶向下)
┌────────────┐
│ Gameplay │ ← 调用引擎功能,游戏逻辑层
├────────────┤
│ Engine │ ← 提供动画、物理、资源等通用模块
├────────────┤
│ TCP/IP │ ← 多人游戏的通信支持
├────────────┤
│ Graphic │ ← 渲染管线与图形抽象
├────────────┤
│ Core │ ← 内存、平台抽象、基础库
├────────────┤
│ Editor (C#)│ ← 游戏编辑器工具链(外部可视化)
└────────────┘
总结
- 游戏逻辑与引擎分层明确,提升可维护性和复用性。
- 网络、图形、核心库作为独立模块解耦管理。
- 编辑器独立于运行时,采用 C# 提高开发效率。
- 这种架构是支撑数百万行代码协作开发的基础,适用于大团队协同。
“What we Don’t Use(我们不使用的技术)”,反映了在 AAA 级大作开发中(如 Ubisoft 的引擎) 为了性能、可控性、稳定性所做的技术取舍。
以下是每项的详细解释:
1. No RTTI(不使用运行时类型识别)
RTTI 是什么?
RTTI(Run-Time Type Information)允许在运行时查询对象的实际类型(通常通过 dynamic_cast 和 typeid)。
为什么不用?
- 性能开销:启用 RTTI 会增加类的内存占用(vtable 中添加类型信息)和运行时开销。
- 代码尺寸膨胀:对于大型项目,RTTI 生成的元信息会显著增加二进制大小。
- 类型系统封装:AAA 引擎常自定义类型系统(反射、序列化)替代 RTTI,更灵活更可控。
替代方案: - 自定义类型注册系统(ID-based 类型识别)
- 手动反射或静态多态(CRTP)
2. No Exception Handling(不使用异常处理)
异常机制特点:
try/catch结构处理错误- 抛出异常时会遍历调用栈、清理对象、运行析构函数
为什么不用?
- 不可控性能开销:异常传播不可预测,会破坏实时性能要求(如渲染、AI)。
- 二进制尺寸增大:异常支持会引入额外的元数据。
- 平台兼容性差:某些平台(如主机 SDK)不支持或限制异常。
- 调试复杂:异常行为对调试和分析不友好。
替代方案: - 错误码返回 (
Result,Status) - 明确控制的资源管理(RAII)
assert()和日志机制辅助调试
3. No STL Containers(不使用标准模板库容器)
STL 是什么?
STL(Standard Template Library)提供标准容器(如 std::vector, std::map, std::unordered_map 等)和算法。
为什么不用?
- 不可控内存分配器:STL 容器默认使用全局
new/delete,不支持自定义内存池。 - 不可预测性能:例如
std::map可能引发频繁堆分配或缓存不友好。 - Debug 开销大:调试构建中 STL 的额外断言和检查对大项目构建时间影响大。
- 二进制体积:泛型代码膨胀严重,难以统一控制。
替代方案: - 自定义容器库(如 EASTL, Folly, or internal GameContainers)
- 内存池友好的容器
- 明确对齐、构造策略支持
4. No Boost Includes in Engine(引擎层不使用 Boost)
Boost 是什么?
Boost 是一个广泛使用的 C++ 开源库集合,功能强大,支持现代 C++ 编程。
为什么在 Engine 层不用?
- 过于庞大复杂:Boost 的依赖链冗长,引入一个模块可能牵出几十个文件。
- 编译时间:大量模板和宏,导致编译慢、调试困难。
- 二进制体积:模板实例化导致代码膨胀。
- 维护性问题:不同版本间兼容性差,不利于跨平台构建。
可能仅用于工具层或测试,但不会引入到运行时敏感的引擎核心。
总结
| 禁用项 | 原因 | 替代方案 |
|---|---|---|
| RTTI | 性能开销 / 控制性差 | 自定义类型识别系统 |
| 异常处理 | 不可预测开销 / 平台限制 | 错误码返回 / 日志 / RAII |
| STL 容器 | 内存分配不可控 / 性能不确定 | 自研容器 / 内存池优化容器 |
| Boost(引擎层) | 编译慢 / 模板重 / 二进制臃肿 | 精简工具库、自写轻量工具函数 |
| 这些技术取舍,体现了 AAA 引擎追求的核心价值:性能、稳定性、可维护性、跨平台兼容性。如果你希望深入了解 Ubisoft 是如何构建自己的容器库或错误处理机制,我也可以为你展开讲解。 |
这部分介绍了 FastBuild,一种用于大规模 C++ 项目的高性能构建系统,特别适用于 AAA 游戏开发团队,如 Ubisoft。
FastBuild 简介
FastBuild 是一个 替代 MSBuild 的构建系统,由 Franta Fulin 开发,专为 大规模 C++ 工程的构建效率 设计,尤其在多人并行开发的大项目(如 AAA 游戏)中表现出色。
特点详解
替代 MSBuild for C++
- MSBuild 是微软 Visual Studio 默认的构建系统,但对于大型项目来说效率有限。
- FastBuild 更轻量、更快、支持复杂构建逻辑,且跨平台(支持 Windows、Linux)。
Smarter DLL Dependencies(更智能的 DLL 依赖)
- 自动检测哪些 DLL 真的需要重新构建。
- 减少不必要的编译和链接,提升增量构建速度。
- 优化大型项目中常见的 “链接瓶颈”。
Better CPU Usage(更好的 CPU 利用率)
- 自带任务调度器,可最大化多核 CPU 使用率。
- 编译任务并行化更高效,避免 MSBuild 的线程饥饿问题。
Distribution and Caching(分布式构建与缓存)
- 支持 分布式构建(Build Distribution):
- 可以将编译任务分发到其他机器,提升构建吞吐量。
- 支持 构建缓存(Build Caching):
- 相同输入编译结果可以复用,极大加快多开发者团队构建速度。
Unity Builds Built-in(内置 Unity 构建支持)
- Unity Builds(合并多个
.cpp文件一起编译)是提高编译速度的一种技巧。 - FastBuild 支持内建处理:
- 自动管理哪些文件合并、如何合并。
- 减少编译启动成本(更少的编译单元)。
总结对比
| 特性 | MSBuild | FastBuild |
|---|---|---|
| 开源 | 专有 | 开源(宽松许可证) |
| 多核并行效率 | 一般 | 高效,内置调度器 |
| 增量构建能力 | 一般 | 精细的依赖管理 |
| 分布式构建 | 无原生支持 | 内建支持 |
| 缓存 | (需单独配置) | 编译缓存可选 |
| Unity Build 支持 | 需手工设置 | 内建支持 |
实际意义(如在 Ubisoft)
- 编译百万行 C++ 代码(如 Rainbow Six 的 8M+ LOC)从数十分钟压缩到几分钟。
- 支持大型开发团队 并行工作、不干扰彼此构建流程。
- 更适合 CI/CD 环境,自动重用构建结果,提高提交效率。
你提到的内容是在介绍 Unity Builds(统一编译/合并编译),这是一种在大型 C++ 项目(如 AAA 游戏)中常用的 加速构建 技术,尤其适用于拥有成千上万个 .cpp 文件的大型代码库。
Unity Build 是什么?
Unity Build(也叫 Jumbo Build 或 Mega Build)指的是:
将多个
.cpp文件合并进一个.cpp文件中统一编译,从而减少编译单元数量、加快编译速度。
举个例子
你正常可能有:
a.cpp
b.cpp
c.cpp
...
n.cpp
如果每个文件都单独编译:
- 每个文件都要预处理(处理头文件)。
- 每个文件都要走完整的编译流程。
- 非常耗时。
在 Unity Build 中:
你创建一个文件,如:
// unity.cpp
#include "a.cpp"
#include "b.cpp"
#include "c.cpp"
// ...
#include "n.cpp"
只需要编译 一个 unity.cpp 文件:
- 所有
.cpp文件的内容会直接合并、一起预处理、编译。 - 大大减少了头文件重复解析次数。
- 能显著减少编译时间(可高达 30~80% 提升)。
上面的图示意思是:
unity.cpp / workunity.cpp
└── #include "a.cpp"
└── #include "b.cpp"
└── ...
└── #include "n.cpp"
这些 .cpp 文件中本来分别包含的头文件现在会在同一个编译单元中统一处理,所以:
- 头文件共享处理结果,预处理更快。
- 构建启动次数减少,链接压力降低。
- 适合频繁构建的大型团队开发场景。
优势
| 优点 | 说明 |
|---|---|
| 编译速度更快 | 减少编译单元数量、共享头文件解析结果 |
| 更容易控制依赖 | 可组合逻辑相似的文件 |
| CPU 使用率更高 | FastBuild 等系统中效果更显著 |
注意事项
| 问题 | 说明 |
|---|---|
| 链接错误风险 | 如果不同 .cpp 定义了同名 symbol,合并后可能重复定义 |
| 编译粒度降低 | 改动一个 .cpp,整个 unity.cpp 都要重新编译 |
| 容易隐藏依赖问题 | 原本隐藏的 include 错误可能会被“掩盖” |
🛠 FastBuild 中的 Unity Build
FastBuild 支持内建 Unity Build 自动处理:
Unity
{
UnityInputPattern = '**.cpp'
UnityOutputPath = 'code/unity/'
UnityNumFiles = 5 // 每个 Unity 文件包含 5 个 .cpp
}
自动生成:
unity_0.cpp -> 包含 5 个 cpp
unity_1.cpp -> 包含 5 个 cpp
...
这样就不需要你手动维护 unity.cpp 文件。
如需我帮你生成一个 Unity Build 示例(用于 FastBuild 或 CMake),或者解释相关性能对比,我可以继续深入。
这三点是 AAA 游戏开发中用于优化 编译效率 和 代码结构 的重要实践。我们逐条来理解:
1. Precompiled Headers(预编译头文件)
什么是预编译头?
在 C++ 中,头文件(#include)会被编译器反复处理,这会极大拖慢编译速度。预编译头(PCH) 的核心思想是:
把不经常变的头文件(如 STL、引擎核心头)编译一次保存,后续编译时复用这份结果,省去重复解析的成本。
举例:
// pch.h
#include <vector>
#include <string>
#include "engine_core.h"
// pch.cpp
#include "pch.h"
编译器先把 pch.cpp 编译成 .pch 文件。之后你只需:
// 其他文件中
#include "pch.h"
即可快速包含大量通用依赖。
优点:
- 显著加快编译速度(尤其是 Debug 构建)
- 减少重复解析
2. /Ob1 in Debug targets
/Ob1 是 MSVC 编译器优化选项:
/Ob 是什么?
控制 函数内联(inline expansion) 级别:
| 选项 | 含义 |
|---|---|
/Ob0 | 禁止内联(默认 Debug 设置) |
/Ob1 | 内联用 inline 显式声明的函数 |
/Ob2 | 编译器自动内联所有合适函数(Release 默认) |
为什么 Debug 用 /Ob1?
因为:
- Debug 构建默认不开启内联,为了便于调试。
- 但完全不内联(
/Ob0)会让性能严重下降,比如内联访问器函数都要跳转调用。 /Ob1是折中方案:允许手动写了inline的函数被内联,提升性能,但仍保持良好调试体验。
3. Template Classes with Non-template Base Classes(模板类继承非模板基类)
这是什么意思?
一种常见的模板设计技巧。例子:
class Base
{
public:
void common_func() { /* ... */ }
};
template <typename T>
class Derived : public Base
{
public:
void do_something(T value) { /* ... */ }
};
为什么这样做?
- 复用非模板代码(如工具函数、接口函数),避免模板代码重复生成多个版本。
- 非模板基类可以被预编译(减轻模板代码带来的代码膨胀)。
- 更方便调试和链接(尤其在大型项目中)。
好处:
- 编译速度更快
- 模板代码结构更清晰
- 避免代码重复膨胀(template bloat)
总结
| 技术 | 作用 | 优点 |
|---|---|---|
| Precompiled Headers | 加快头文件解析 | 编译更快,重复包含少 |
/Ob1 | 减少 Debug 构建性能损耗 | 部分内联优化,调试依然容易 |
| 模板类继承非模板基类 | 模板与通用代码分离 | 控制代码膨胀,提升可维护性 |
模板(templates) 在大型 C++ 项目(比如 AAA 游戏)中引发的一个常见问题:代码膨胀(code bloat)和编译重复(redundant instantiations),特别是在使用 Unity Build 时。我们来逐步解析:
背景:模板是编译时生成的
template<typename T>
class Array {
// ...
};
Array<int> a;
Array<float> b;
每个 T 类型(int, float, MyClass1 等)都会 生成一个完整的类定义。这叫做模板实例化(template instantiation)。
Unity Build 引入的问题
Unity Build 是一种把多个 .cpp 文件合并进一个大的 .cpp 文件里再编译的方法,比如:
// unity1.cpp
#include "a.cpp"
#include "b.cpp"
#include "c.cpp"
// unity2.cpp
#include "d.cpp"
#include "e.cpp"
现在设想:
a.cpp使用了Array<int>、Array<float>b.cpp又使用了Array<int>、Array<MyClass1>c.cpp使用了Array<float>、Array<MyClass2>等等
在没有特别控制的情况下:
每个 Unity 编译单元都会为它用到的模板实例再编译一遍!
导致的问题
1. 重复实例化
你可能会在多个 unityX.obj 文件中看到:
Array<int>
Array<float>
Array<MyClass1>
Array<MyClass2>
...
这样:
- 编译时间增加
- 目标文件变大
- 链接器合并这些重复符号也变慢(甚至可能出现 ODR 问题)
解决思路
- 显示实例化(Explicit Instantiation)
- 在某个
.cpp中专门声明:template class Array<int>; template class Array<float>; template class Array<MyClass1>; - 其他地方只
extern template:extern template class Array<int>;
- 在某个
- 减少模板使用频率(template hoisting)
- 把非类型相关的代码从模板中“拔”出来,封装进基类(前面讲的技巧)
- 分离 Unity Build 和模板类定义文件
- 把模板类放在不参与 Unity Build 的专用编译单元中
总结图示理解
Array<int> <== 被 a.cpp、b.cpp、c.cpp 重复生成
Array<float> <== 被 a.cpp、c.cpp 重复生成
Array<MyClass1>==> b.cpp 生成
Array<MyClass2>==> c.cpp 生成
...
这些都可能出现在:
unity1.obj
unity2.obj
unity3.obj
如果不控制,就会 浪费大量编译时间与空间。
C++ 模板代码膨胀问题的优化策略 的继续,标题“Templates: Unify Code”指的是模板统一代码结构以减少重复实例化。让我们逐句解释其含义:
问题背景(重复的“Array”代码)
在大型游戏项目中(如前所述的 Unity builds),每个模板实例都会生成独立的代码,比如:
template<typename T>
class Array {
// A lot of stuff here...
};
每次用 Array<int>、Array<float> 等都会生成一份完整代码,导致:
- 编译慢
- 可执行文件膨胀
- 链接慢
解决策略:“Unify Code”——模板基类分离(Template Hoisting)
这张图或结构想表达的是:
原始结构(问题版本)
template<typename T>
class Array {
// A lot of stuff
// Depends on T
}
每种 T 都要重新实例化“a lot of stuff”,即使里面有些内容与 T 无关。
优化结构:将非模板代码移到基类中
class BaseArray {
// A lot of stuff
// NOT dependent on T
};
template<typename T>
class Array : public BaseArray {
// Only T-specific logic
};
这样“非模板代码”只编译一次(BaseArray),模板只包含必要的泛型逻辑。
额外技巧:函数 inline 控制
图中提到:Inlined functions
- 对于小函数可以
inline,避免函数调用开销 - 但如果模板函数太多都
inline,会造成 代码膨胀
所以你要平衡使用: - 把非 T 相关函数写在
BaseArray中,非模板,减少重复 - 把需要 T的函数放模板中,根据需要决定是否 inline
总结
| 旧方式(问题) | 新方式(优化) |
|---|---|
| 所有逻辑都写在模板里 | 将与 T 无关的逻辑抽取到非模板基类中 |
| 编译时间长、二进制文件大 | 编译时间更短,减少代码重复 |
多个 .obj 重复实例化 | 共享 BaseArray 实现,节省空间 |
这部分内容主要是介绍 Ubisoft 在大型项目中如何通过“代码生成”优化开发流程、提高效率并减少复杂性。我们逐条理解:
标题:Generated Code(生成代码)
指的是通过工具自动生成 .h 和 .cpp 文件中的部分内容,而不是人工手写全部逻辑。
🔹 IDL for object model
“IDL” = Interface Definition Language
Ubisoft 使用类似 IDL 的语言描述游戏对象、接口或组件,例如:
object Character {
int health;
float speed;
void jump();
}
然后通过工具 自动生成对应的 C++ 类代码:
class Character {
int health;
float speed;
public:
void jump();
};
优点:
- 减少手写代码
- 保持接口一致
- 更容易做跨语言绑定(如 C#、Lua)
🔹 Generated code regions in corresponding .h and .cpp files
即:在 .h 和 .cpp 中有自动生成的区域(典型做法是特殊注释标记):
// BEGIN GENERATED CODE
void jump();
int getHealth();
// END GENERATED CODE
这让开发者 在保留手写逻辑的同时,插入自动维护的结构代码。
编辑时不会破坏生成器逻辑,也便于版本控制。
🔹 Avoiding some meta-programming
元编程(如模板偏特化、SFINAE、宏魔法)会使代码复杂、编译慢、难调试。
Ubisoft 倾向于:
- 用生成代码 替代复杂的模板技巧
- 保持代码清晰易读
- 减少编译时间
例如:
// 生成不同类型的序列化代码,而不是使用模板+偏特化
void serialize(Character& c) { ... }
void serialize(Item& i) { ... }
🔹 Custom Edit and Continue through our own programming language generating C++
Ubisoft 为实现“自定义的 Edit and Continue(编辑代码不中断运行)”机制:
- 创建了自己的语言(可能是 DSL)
- 将其编译为 C++
- 这样可以动态插入/替换行为逻辑而不中断游戏运行
这对开发大规模游戏非常重要: - 快速迭代
- 热更新脚本逻辑
- 改一个 AI 行为不必重新编译整个引擎
总结
| 项目 | 含义与优势 |
|---|---|
| IDL for object model | 自动生成对象代码,提高一致性 |
| Generated code regions | 保持手写与自动代码共存,方便管理 |
| Avoiding meta-programming | 用生成代码替代复杂模板,提高性能 |
| Custom Edit and Continue | 自研语言 + C++ 生成,支持热更与快速调试 |
这段内容讲的是 Ubisoft 团队用来优化和维护大规模 C++ 代码的工具,理解如下:
Tools(工具)
• .obj Analyzer
- 用来分析编译生成的
.obj文件 - 可以统计所有翻译单元(Translation Units)中 符号(symbols)大小
- 主要用于找出哪些编译单元体积大,帮助优化编译和链接时间
• Total symbol sizes for all translation units together
- 统计所有翻译单元中符号的大小总和
- 用来衡量项目整体的编译产物大小
- 帮助发现编译膨胀(code bloat)问题
• Useless #include Remover
- 自动检测和移除 无用的
#include头文件 - 头文件冗余会导致编译时间变长,代码耦合度高
- 移除后代码更清晰,编译更快
• We have our own tool
- Ubisoft 有自己开发的工具做上述分析和移除工作
- 方便结合自家项目和编译系统使用
• Google’s include-what-you-use looks better
- Google 的开源工具 include-what-you-use 也可以做类似头文件使用分析
- 觉得它更好用、更先进,可能会参考或采用
总结
Ubisoft 为了应对巨大的代码量和复杂性,使用和开发了专门的工具:
| 工具名 | 作用 |
|---|---|
| .obj Analyzer | 分析目标文件大小,找出编译膨胀点 |
| Total symbol sizes | 统计所有符号大小,评估整体编译产物 |
| Useless #include Remover | 自动检测并清理不必要的头文件,提升编译速度与代码质量 |
| 自研工具 | 结合项目定制的分析和清理工具 |
| include-what-you-use | Google 的优秀工具,作为参考和可能替代方案 |
这段内容讲的是 性能优化的重要性,结合具体的例子说明了代码写法对性能的巨大影响,理解如下:
Performance Importance(性能重要性)
- Last console generation was 8 years
最新一代主机发布已有8年,意味着硬件性能提升有限,需要软件层面极致优化。 - 90/10 principle: 10% of code running 90% of time
90/10法则:只有10%的代码占用了程序90%的执行时间,所以性能优化要聚焦这部分关键代码。 - Frame rate reality pushing us
实时游戏的帧率要求推动性能优化非常严格,稍有差错就会卡顿。
Example(示例)
struct Data
{
Data() {
for (int i = 0; i < 64; ++i)
values[i] = i;
}
int values[64];
};
Data* data = new Data[1 << 20]; // 申请超大内存块,超过一百万个 Data 对象
两个循环顺序对性能影响极大
int total = 0;
for (int i = 0; i < size1; ++i)
for (int j = 0; j < size2; ++j)
total += data[j].values[i];
for (int j = 0; j < size2; ++j)
for (int i = 0; i < size1; ++i)
total += data[j].values[i];
性能结果
- 在我的PC上,第二种循环方式快8倍!
原因分析
- 缓存局部性(Cache locality)
第二种循环方式是按照内存布局顺序访问数据,连续访问数组data[j].values[i]的元素,CPU缓存命中率更高。 - 第一种循环方式:先遍历
i再遍历j,访问跨越了不连续的内存,缓存失效多,导致频繁内存加载,性能极差。
总结
- 合理的数据访问顺序对性能影响巨大
- 在写大数据量循环时,考虑内存访问模式和缓存优化,是游戏和高性能代码中必须的优化方向。
计算机内存层次结构(Memory Hierarchy) 的基础知识,理解如下:
Memory Hierarchy(内存层次结构)
现代计算机为了兼顾速度和容量,内存设计成多层次结构,每层的访问速度和容量都不同:
- CPU(中央处理器)
处理器内部包含极高速的寄存器,执行计算核心。 - L1 Cache(一级缓存)
- 速度最快、容量最小(几十KB)
- 与CPU核心最近,存放最频繁访问的数据和指令
- 访问延迟极低,通常1-3个CPU周期
- L2 Cache(二级缓存)
- 比L1大(几百KB到几MB),速度稍慢
- 缓存L1未命中的数据
- L3 Cache(三级缓存)
- 容量更大(几MB到几十MB),速度更慢
- 通常为多个核心共享
- RAM(主内存/随机存取存储器)
- 容量大(GB级别),但访问速度明显慢于缓存(几十到上百纳秒)
- 存放当前程序运行所需的大部分数据和代码
- HDD(硬盘驱动器)
- 容量最大(TB级别),存储持久化数据
- 访问速度最慢(几毫秒级),机械硬盘延迟更高
关键点
- 速度从CPU到HDD逐层递减,容量逐层递增
- CPU执行速度非常快,若每次都直接访问RAM或硬盘,会极大拖慢程序
- 缓存作为中间层,通过预测和局部性原理,存放热点数据,提高整体性能
- 优化程序要考虑 缓存局部性,让数据尽可能利用高速缓存,减少慢速内存访问。
你给的这个结构图描述了多核CPU及其缓存层次的典型架构,理解如下:
Cache & CPU Core 架构示意(多核处理器缓存层次)
- Core(核心)
- CPU内部的计算单元,每个核心可以独立执行指令。
- L1 Cache(一级缓存)
- 每个核心都有自己独立的L1缓存(通常分为L1指令缓存和L1数据缓存)
- 容量小,速度快,直接为核心服务,降低访问延迟。
- L2 Cache(二级缓存)
- 通常每个核心或一对核心共享一个L2缓存
- 容量比L1大,速度比L1慢些,缓存未命中的数据。
- L3 Cache(三级缓存)
- 多核心共享的缓存(可能是所有核心都共享)
- 容量更大,速度更慢,但比主内存快得多
- 用于缓存核心之间共享的数据,减少访问RAM的次数。
- RAM(主内存)
- 所有核心共享的主内存,容量最大,但访问延迟最高。
总结
- L1是核心私有的高速缓存,靠近核心,最先访问。
- L2可能是核心私有或共享,作为L1的后备缓存。
- L3是所有核心共享的缓存池,提供较大容量共享缓存。
- 主内存是所有核心共享的外层存储,访问最慢。
这个层次结构旨在平衡速度与容量,减少多核处理器访问内存瓶颈,提高整体性能。
你给出的两段代码其实是一样的,都是:
for (int j = 0; j < size2; ++j)
for (int i = 0; i < size1; ++i)
total += data[j].values[i];
你想要理解的是为什么这种访问方式会导致 Data Cache Miss(数据缓存未命中),我来帮你解释。
为什么会发生 Data Cache Miss?
背景
data是一个数组,每个元素是一个Data结构体- 每个
Data结构体有一个values[64]的数组 - 内存中
data数组是连续存储的,即data[0],data[1], … 连续排列
代码分析
这段代码:
for (int j = 0; j < size2; ++j) // 外层循环遍历 data 数组元素
for (int i = 0; i < size1; ++i) // 内层循环遍历每个元素中的 values 数组
total += data[j].values[i];
- 外层是访问
data[j](内存中间隔很大,因为一个Data结构体比较大), - 内层是访问这个
Data中的values[i]。
缓存未命中(Cache Miss)的原因
- 空间局部性(Spatial Locality)差:
你先固定了j,访问data[j].values[0..size1-1]是连续访问,这很好,访问values是顺序的,缓存命中率不错。 - 但是外层
j循环大,内层i小,整体内存访问是:
data[0].values[0],data[0].values[1], …,data[0].values[size1-1],
接着data[1].values[0],data[1].values[1], …,data[1].values[size1-1],
如此循环,内存跳跃大,因为data[0],data[1]间隔很大(每个Data结构体包含64个int数组,跨度大) - CPU缓存通常会把数据按缓存行(通常64字节)加载到缓存中。
- 当内存跳跃很大时,每次访问新的
data[j]会导致缓存行替换,原来的缓存行被替换出去,导致缓存未命中频繁发生。
优化的访问方式
改成:
for (int i = 0; i < size1; ++i)
for (int j = 0; j < size2; ++j)
total += data[j].values[i];
即交换两层循环,先访问 values[i],对每个 i 依次访问 data[j]:
- 这样访问顺序是按
values[i]维度遍历, - 内存访问在
data[j]方向(间隔较大),但因为数据结构本身布局是data数组的连续元素,这种方式更有利于利用缓存行中的空间。
总结
- 代码访问顺序影响缓存命中率
- 按照数据在内存中顺序访问,缓存命中率高
- 跨越跳跃访问数据会造成缓存未命中,性能下降
你给的例子里有两个写法,目的是对 values 数组的元素求和并累加到 m_Total。
代码示例1(直接累加到成员变量):
for (int i = 0; i < count; ++i)
{
m_Total += values[i];
}
代码示例2(先累加到局部变量,再赋值):
int64_t total = 0;
for (int i = 0; i < count; ++i)
{
total += values[i];
}
m_Total = total;
为什么第二种写法更好?
- 性能和优化角度:
- 避免频繁访问内存(成员变量)
m_Total是对象成员,通常在内存中。每次循环写操作m_Total += values[i]都可能导致内存访问,可能产生写回(write-back),带来缓存同步开销。 - 局部变量存储在寄存器
total是局部变量,编译器往往会把它放在CPU寄存器里,读写速度极快。这样循环内部对total的操作基本是寄存器操作,速度比访问内存快很多。 - 减少数据依赖和优化空间
在第一个版本中,m_Total每次更新后可能导致依赖链较长,限制了CPU流水线优化。
第二个版本计算完成后只写一次,减少了循环内的数据依赖。
总结
| 优点 | 第一种写法 | 第二种写法(推荐) |
|---|---|---|
| 读写效率 | 频繁访问内存 | 主要在寄存器操作 |
| CPU流水线优化 | 受限 | 更好 |
| 代码清晰度 | 一步完成 | 明确分两步,更易优化 |
提供的是几种常见的 C++ 单例(Singleton)设计模式实现示例,核心思想是全局唯一实例管理。下面帮你理清这些概念和代码。
1. MyLibSingletonStorer
struct MyLibSingletonStorer
{
MyManager m_MyManager;
MyOtherManager m_MyOtherManager;
...
};
- 这是一个存储所有单例对象的结构体,里面保存了多个单例类的实例。
- 主要目的是把多个单例集中管理在一起,方便构造和销毁。
2. 传统单例模板类
template <typename T>
class Singleton {
protected:
Singleton() { ms_Inst = this; }
private:
static T* ms_Inst = nullptr;
public:
static T* GetInst() { return ms_Inst; }
};
- 这个模板类是单例模式的核心实现。
- 保护构造函数确保外部不能随意创建实例。
- 静态指针
ms_Inst用来保存唯一实例地址。 - 构造时,将
ms_Inst指向自身。 - 通过
GetInst()静态方法访问单例。
3. 继承自单例模板的具体类
class MyManager : public Singleton<MyManager> { ... };
- 具体的单例类继承自模板,自动获得单例行为。
- 只会有一个
MyManager实例,并且可用MyManager::GetInst()获取。
4. GlobalSingleton 和 Scoped 生命周期管理
struct MyLibSingletonStorer
{
GlobalSingleton<MyManager>::Scope m_MyManager;
MyOtherManager m_MyOtherManager;
...
};
- 这里引入了
GlobalSingleton,用于更精细地管理单例的生命周期,通常带有构造和销毁控制。 Scope是一种RAII封装,自动在构造时创建单例,在析构时销毁。
5. GlobalSingleton 伪代码示例
void Construct() { new (&m_Data.m_Buffer) T(); }
void Destroy() { GetInst().~T(); }
T& GetInst() { return *(T*)&m_Data.m_Buffer; }
- 这里
m_Data.m_Buffer是预分配的内存缓冲区,用于手动调用构造函数和析构函数。 Construct()使用 定位new 在缓冲区中构造对象。Destroy()调用析构函数销毁实例。GetInst()返回缓冲区中对象的引用。- 这种方式避免了动态内存分配,控制对象创建和销毁时机。
总结
| 概念 | 说明 |
|---|---|
Singleton 模板 | 经典单例实现,静态指针管理唯一实例 |
MyLibSingletonStorer | 集中存储所有单例实例,方便统一管理 |
GlobalSingleton | 通过手动构造和析构,管理单例生命周期,避免内存泄漏 |
**代码缓存未命中(Code Cache Miss)问题,尤其是在涉及虚函数调用和多态(多种派生类型)**的场景下。
背景分析
- 虚函数调用过程:
- 对象指针
obj里存着指向虚函数表(vtable)的指针。 obj->Draw()调用时,先通过 vtable 找到Draw()函数地址,然后跳转执行。
- 对象指针
- 代码缓存(Code Cache):
- 现代 CPU 通过**指令缓存(Instruction Cache)**加速代码执行。
- 如果 CPU 需要执行的代码不在缓存中(缓存未命中),则需要从主存加载代码,导致延迟。
- 代码缓存未命中的情形:
- 如果程序频繁调用大量不同的虚函数实现(多态下多种类型)时,CPU 需要跳转到许多不同的代码位置。
- 这导致指令缓存里放不下所有代码片段,产生大量未命中,降低性能。
具体例子解读
struct Shape {
virtual void Draw()=0;
...
};
obj->Draw();
obj->Draw()是虚函数调用,需要通过 vtable 跳转到具体函数。- 如果
obj指向不同类型(Circle, Square, Triangle等),对应不同的Draw()实现。
switch (shapeType) {
case CIRCLE_SHAPE:
// 调用 Circle::Draw()
...
}
switch语句会基于类型判断直接调用对应函数。- 这种方法可以避免虚函数调用的间接跳转,代码路径更确定。
代码缓存未命中问题的本质
- 虚函数调用时跳转目标多样,分散,CPU难以预测并加载相关代码块,指令缓存未命中率高。
- switch语句调用固定代码位置,跳转目标有限,更利于指令缓存命中。
性能优化建议
- 减少过多的虚函数调用,尤其是在性能敏感代码中。
- 尽量避免大量不同类型交替调用相同接口,避免频繁跳转多处代码。
- 通过数据局部性和代码局部性优化,例如将相似类型的对象集中处理。
- 使用
switch等结构在合适场景替代虚函数,减少间接调用。
总结
| 现象 | 说明 |
|---|---|
| 虚函数调用 | 多态实现,间接跳转,导致指令缓存命中率降低 |
| switch-case调用 | 直接跳转,目标固定,更有利于指令缓存 |
| Code Cache Miss | CPU指令缓存未命中,导致性能下降 |
游戏开发或者高性能C++编程中**避免使用堆分配(heap allocation)**的策略和理由。
为什么要避免堆分配?
- 堆分配代价重(Heavy):
堆的分配和释放比栈慢很多,调用系统API(如new/delete)会增加开销。 - 全局堆使用(Global):
堆通常是全局共享资源,多线程环境下竞争激烈,影响性能和延迟。 - 内存碎片(Fragmentation):
长时间使用堆内存会导致碎片,降低缓存效率,甚至引起性能下降和内存不足。
如何避免堆分配?
- 使用栈内存或者局部内存(In-place allocation)
例如:
替代为:void Foo() { Array<ubiU32> values; // 可能堆分配 ... }void Foo() { InplaceArray<ubiU32, 8> values; // 在对象内部预分配8个元素空间,避免堆分配 ... }InplaceArray是一种内置缓冲区的容器,可以存放固定数量元素,不用堆分配。 - 判断指针是否指向栈上的对象,选择合适的分配器
这里通过检查当前对象是否在栈上,选择高效分配策略,减少堆分配。if (IsPtrOnStack(this)) FrameAllocator::Allocate(...); // 用帧分配器分配快速短生命周期内存 else ... // 其他情况,可能用不同的分配策略 - 使用自定义分配器(FrameAllocator等)
这些分配器专门设计用于快速分配和释放短生命周期对象,通常配合栈式结构,性能更优。
总结
避免堆分配能够:
- 降低内存管理开销
- 降低内存碎片风险
- 提升缓存命中率
- 提升整体性能,尤其是游戏这类对性能要求高的系统
大型多线程C++项目在调试时面临的挑战以及为了提高调试效率所做的折衷措施:
调试挑战(Debugging Challenges)
- 庞大的多线程代码库
多线程程序复杂,调试时容易遇到竞态条件、死锁等难以定位的问题。 - 某些bug仅在优化版中重现
代码经过编译器优化后,bug才出现,调试版本(非优化)可能看不到这些问题。 - 避免为了调试而频繁重新编译
频繁切换编译选项(如开启/关闭调试信息)会浪费时间,影响开发效率。 - 调试版本必须足够快
过慢的调试版本会影响开发体验,降低调试效率。
禁用的一些特性(Some Disabled Stuff)
- 调试迭代器(Debug Iterators)被禁用
调试迭代器能捕获迭代器越界等错误,但会带来额外性能开销,因此禁用以提高调试速度。 - Visual Studio Debugger Heap禁用(设置了 _NO_DEBUG_HEAP=1)
关闭调试堆,以减少堆管理的开销,避免调试时堆操作太慢。 - Windows Fault Tolerant Heap禁用
关闭Windows的容错堆,减少额外检查,提高性能。
简而言之,为了在大型、多线程、复杂的游戏代码里快速有效地调试,必须在调试功能和性能之间找到平衡,禁用一些影响性能的调试特性,同时保证调试版本能快速构建和运行。
这部分讲的是在Release版本调试时遇到的常见问题和相关技术。
Debugging Release Code(调试发布版代码)
- “My Callstack is RIP”
这是一个比喻,意思是调试时调用栈(call stack)丢失或无法使用。- Release版本经过优化,编译器会重排指令、内联函数、剔除无用代码,导致调用栈信息不完整或不可用。
- 这让定位崩溃点或异常位置非常困难。
- Memory Tagging(内存标记)
- 用于追踪和标记内存分配,帮助定位内存泄漏或访问越界的问题。
- 代码示例:
Particle* particle = ubiNew(Particle, "FX Particle", fxManager);
这里调用了自定义的ubiNew内存分配函数,带有内存标签(“FX Particle”),方便后续追踪。
- Breaks / Memory Corruption(崩溃 / 内存损坏)
- Release代码更难调试,尤其是当存在内存破坏(如越界写、悬空指针)时,程序可能突然崩溃或表现异常。
- 由于优化,错误可能不会在错误发生时立即显现,调试起来极其复杂。
总结
- 调试Release版本非常困难,调用栈信息可能丢失。
- 内存标记和自定义内存管理是辅助定位问题的重要手段。
- 内存损坏问题在Release版特别棘手,需要结合多种工具和策略定位。


![[CSS3]vw/vh移动适配](https://i-blog.csdnimg.cn/img_convert/87f142fa3e13d6ef00e2e6514dacaf3b.png)