名人说:路漫漫其修远兮,吾将上下而求索。—— 屈原《离骚》
创作者:Code_流苏(CSDN)(一个喜欢古诗词和编程的Coder😊)
目录
- 一、为什么要做词云?让文字"活"起来!
- 二、核心技术栈:让Python为文字插上翅膀
- 1. jieba分词:中文文本处理的利器
- 2. WordCloud:词云生成的核心引擎
- 3. Tkinter:打造友好的图形界面
- 三、核心功能特色:让词云生成更智能
- 1. 智能文本预处理
- 2. 丰富的自定义选项
- 3. 多种文本输入方式
- 四、代码实现亮点:解决实际问题
- 1. 中文字体自动配置
- 2. 异步生成避免界面卡顿
- 五、实际使用演示:从文本到词云
- 1. 启动程序(若有IDE可直接运行)
- 2. 输入示例文本
- 3. 调整参数设置
- 4. 一键生成和导出
- 六、扩展应用:让创意无限延伸
- 1. 个性化定制
- 2. 批量处理
- 3. 集成到Web应用
- 七、完整代码(带注释)
- 八、总结:让数据可视化触手可及
👋 专栏介绍: Python星球日记专栏介绍(持续更新ing)
欢迎大家来到Python星球日记的趣学篇,在趣学篇,我们将带来很多有趣的适合初学者的项目,项目均由个人团队开发及AI vide coding的辅助。
不知道你有没有为枯燥的文本分析发愁?通过今天这篇文章我们可以让你的文字变成炫酷的可视化图表,一起用Python打造一个交互式词云生成器,支持自定义文本输入,一键生成个性化词云,让数据可视化变得简单又有趣!
一、为什么要做词云?让文字"活"起来!
在这个信息爆炸的时代,我们每天都在处理大量的文本数据:微博评论、新闻文章、产品评价、学术论文…如何快速抓住文本的核心内容和关键信息呢?
词云(Word Cloud)就是一个绝佳的解决方案!它能将文本中的高频词汇以不同大小和颜色展示出来,让你一眼就能看出文本的主题和重点。想象一下:
- 产品经理:分析用户反馈,快速定位产品痛点
- 内容创作者:了解文章关键词分布,优化SEO
- 学术研究者:提取论文核心概念,制作研究报告
- 生活达人:把情书、日记做成艺术品

二、核心技术栈:让Python为文字插上翅膀
我们的词云生成器主要基于以下几个强大的Python库:
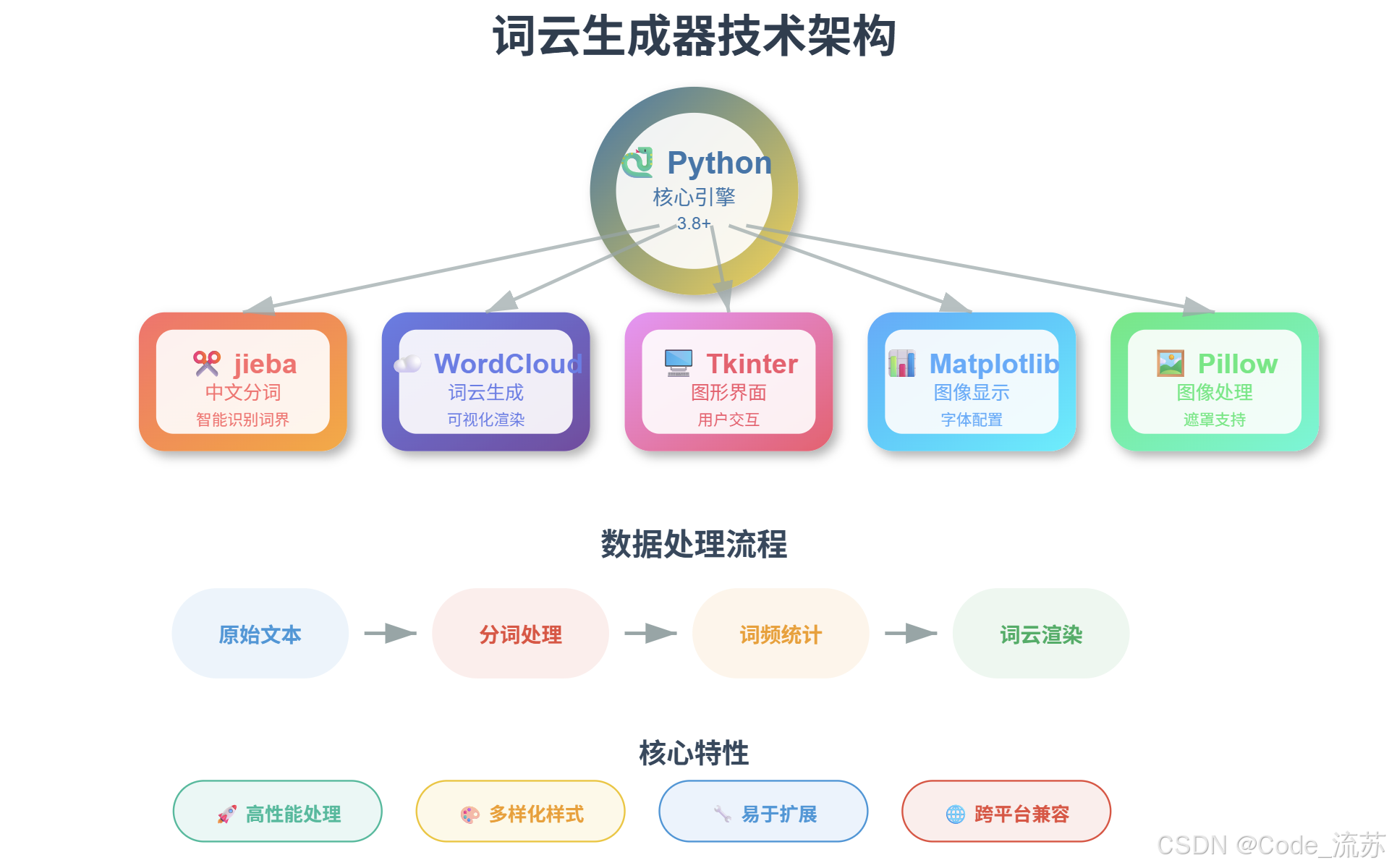
1. jieba分词:中文文本处理的利器
import jieba
text = "人工智能正在改变我们的世界"
words = jieba.cut(text)
print(list(words)) # ['人工智能', '正在', '改变', '我们', '的', '世界']
jieba是目前最优秀的中文分词库,能够准确识别词汇边界,这对中文词云生成至关重要。
2. WordCloud:词云生成的核心引擎
from wordcloud import WordCloud
# 基础配置
wordcloud = WordCloud(
font_path='simhei.ttf', # 中文字体
width=800, height=600, # 图片尺寸
background_color='white', # 背景色
max_words=100 # 最大词数
).generate(text)
3. Tkinter:打造友好的图形界面
相比命令行操作,图形界面让词云生成变得更加直观和便民:
- ✅ 大文本框支持长文本输入
- ✅ 实时参数调整和预览
- ✅ 一键文件导入导出
- ✅ 状态反馈和错误提示
三、核心功能特色:让词云生成更智能
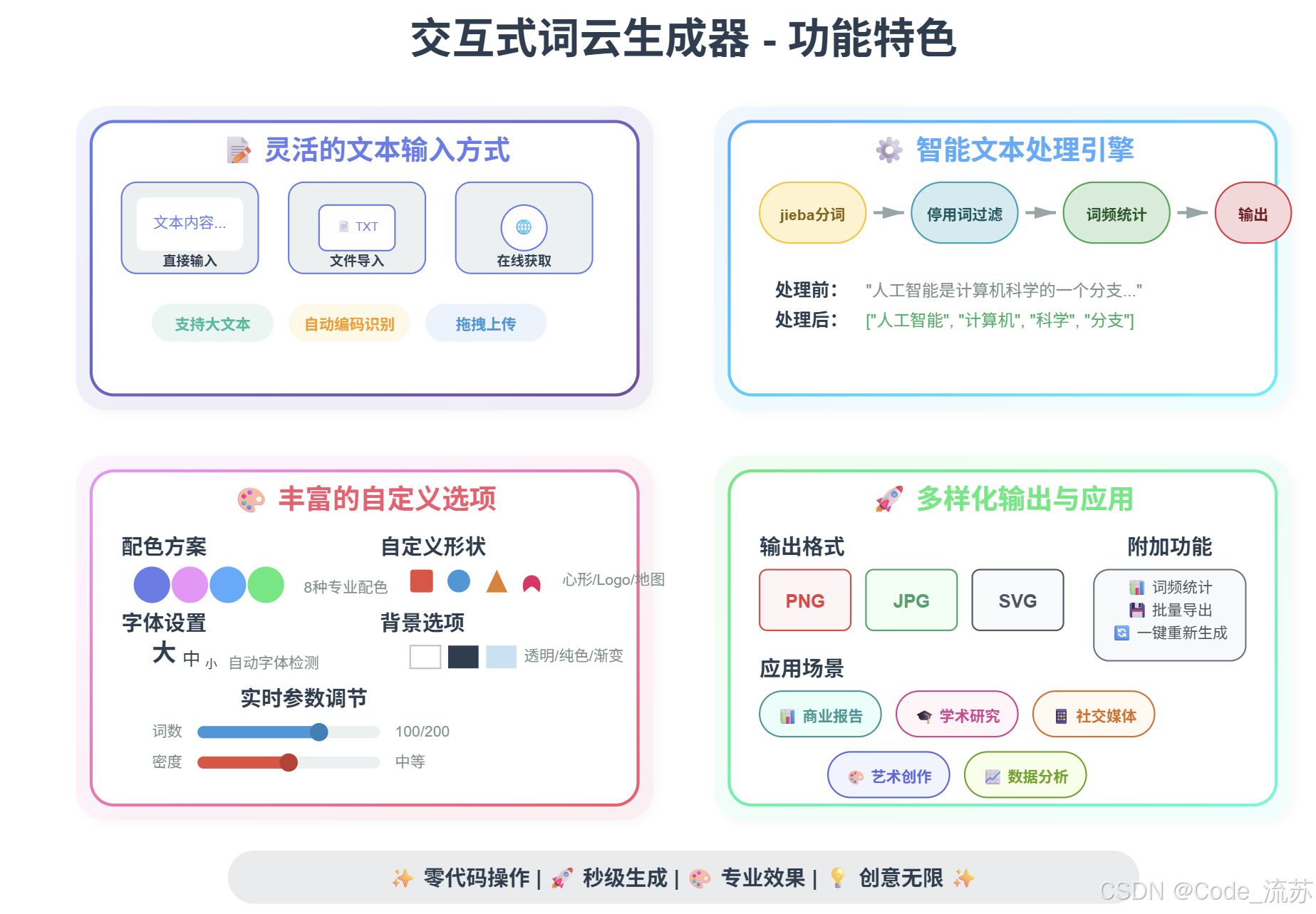
1. 智能文本预处理
我们的生成器不仅仅是简单的分词,还包含了完整的文本清洗流程:
def preprocess_text(self, text):
"""智能文本预处理"""
# 第一步:jieba分词
words = jieba.cut(text.strip())
# 第二步:过滤无效词汇
filtered_words = []
for word in words:
word = word.strip()
# 长度过滤 + 停用词过滤 + 字母判断
if len(word) >= 2 and word not in self.stopwords and word.isalpha():
filtered_words.append(word)
return filtered_words
停用词库包含了常见的无意义词汇,如"的"、“了”、"在"等,确保生成的词云更有价值。
2. 丰富的自定义选项
| 参数 | 选项 | 效果 |
|---|---|---|
| 配色方案 | viridis, plasma, inferno… | 8种专业配色,满足不同审美需求 |
| 背景颜色 | 白色、黑色、浅蓝色… | 适配不同使用场景 |
| 最大词数 | 50-200 | 控制词云密度和复杂度 |
| 图片尺寸 | 800x600, 1200x800… | 适配不同展示需求 |
3. 多种文本输入方式
# 方式一:直接文本输入
text = "在这里粘贴你的文本内容..."
# 方式二:文件导入
with open('article.txt', 'r', encoding='utf-8') as f:
text = f.read()
# 方式三:网络爬取(可扩展)
# text = requests.get('https://...').text
四、代码实现亮点:解决实际问题
1. 中文字体自动配置
这是很多初学者容易踩的坑!我们的方案会自动检测系统字体:
def setup_chinese_font(self):
"""跨平台字体自动配置"""
system = platform.system()
if system == "Windows":
font_paths = [
"C:/Windows/Fonts/simhei.ttf", # 黑体
"C:/Windows/Fonts/msyh.ttc", # 微软雅黑
]
elif system == "Darwin": # Mac
font_paths = ["/System/Library/Fonts/PingFang.ttc"]
else: # Linux
font_paths = ["/usr/share/fonts/truetype/wqy/wqy-microhei.ttc"]
# 自动寻找可用字体
for font_path in font_paths:
if os.path.exists(font_path):
return font_path

2. 异步生成避免界面卡顿
大文本处理可能需要几秒钟时间,我们使用多线程来避免界面假死:
def generate_wordcloud_thread(self):
"""后台生成词云,界面保持响应"""
def generate():
self.status_var.set("正在生成词云...")
# 耗时的词云生成过程
wordcloud, word_freq = self.generator.generate_wordcloud(text)
self.status_var.set("✅ 生成成功!")
# 在新线程中运行
thread = threading.Thread(target=generate)
thread.daemon = True
thread.start()
五、实际使用演示:从文本到词云
让我们来看一个完整的使用流程:
1. 启动程序(若有IDE可直接运行)
python wordcloud_generator.py
# 选择 1 启动图形界面(推荐)

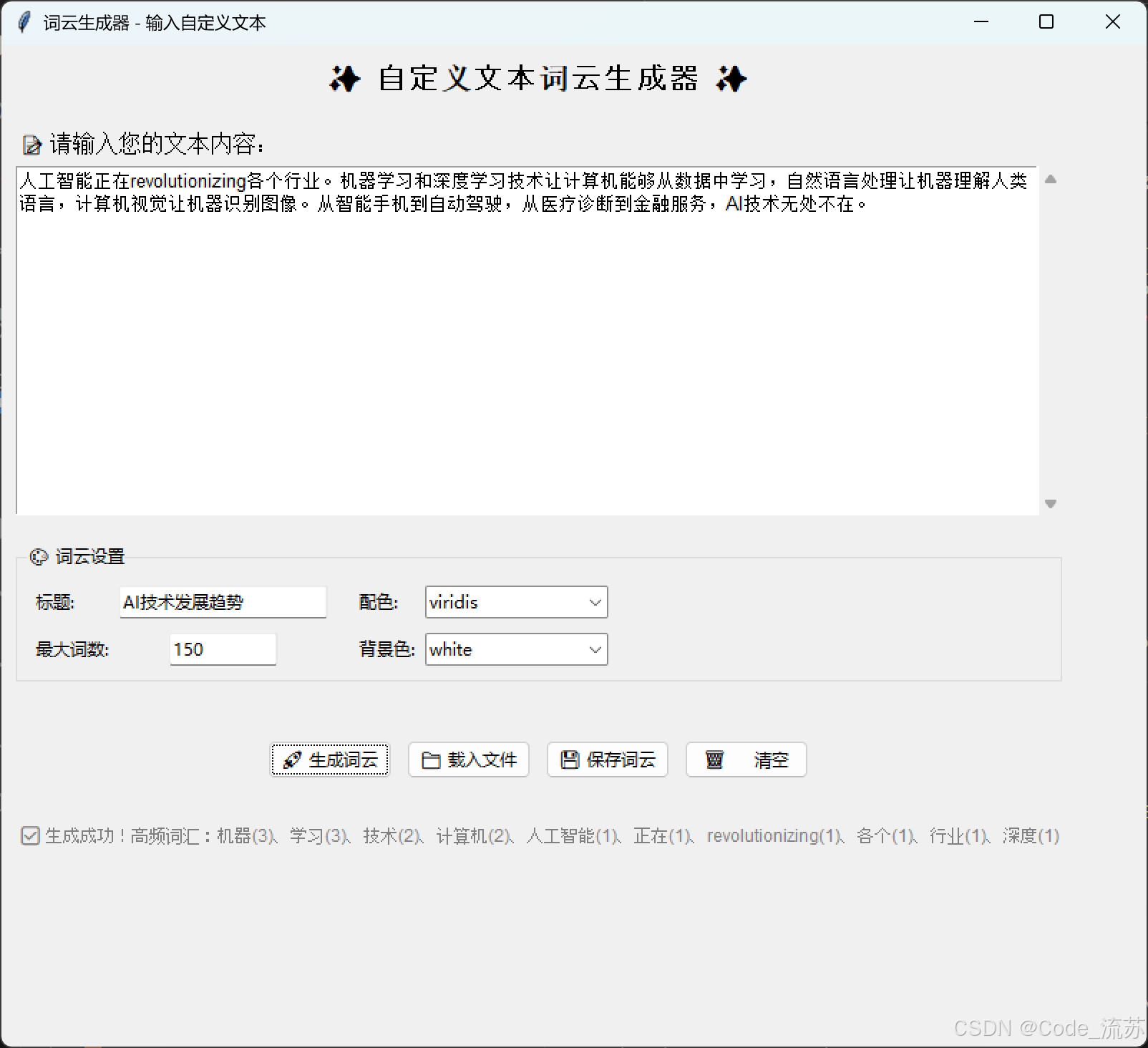
2. 输入示例文本
比如我们输入一段关于人工智能的文章:
人工智能正在revolutionizing各个行业。机器学习和深度学习技术让计算机能够从数据中学习,自然语言处理让机器理解人类语言,计算机视觉让机器识别图像。从智能手机到自动驾驶,从医疗诊断到金融服务,AI技术无处不在。

3. 调整参数设置
- 标题:设置为"AI技术发展趋势"
- 配色:选择"plasma"获得炫酷的渐变效果
- 最大词数:设置为150

4. 一键生成和导出
点击"🚀 生成词云",几秒钟后就能看到炫酷的词云图!程序还会贴心地显示词频统计:


六、扩展应用:让创意无限延伸
1. 个性化定制
# 心形词云(适合情人节贺卡)
heart_mask = create_heart_mask(400)
wordcloud = WordCloud(mask=heart_mask, colormap='Reds')
# 公司Logo形状(适合企业报告)
logo_mask = np.array(Image.open('company_logo.png'))
wordcloud = WordCloud(mask=logo_mask)
2. 批量处理
# 处理多个文档,生成对比词云
documents = ['doc1.txt', 'doc2.txt', 'doc3.txt']
for i, doc in enumerate(documents):
with open(doc, 'r') as f:
text = f.read()
generate_wordcloud(text, title=f"文档{i+1}词云")
3. 集成到Web应用
可以轻松集成到Flask或Django项目中,打造在线词云生成服务:
from flask import Flask, request, send_file
@app.route('/generate', methods=['POST'])
def web_generate():
text = request.form['text']
wordcloud, _ = generator.generate_wordcloud(text)
# 返回生成的图片
return send_file('wordcloud.png')
七、完整代码(带注释)
# Code_流苏(CSDN)
# 交互式词云生成器 - 支持用户自定义文本输入
import jieba
import matplotlib.pyplot as plt
import matplotlib.font_manager as fm
from wordcloud import WordCloud
import numpy as np
from PIL import Image
from collections import Counter
import os
import platform
import tkinter as tk
from tkinter import scrolledtext, messagebox, filedialog, ttk
import threading
class InteractiveWordCloudGenerator:
"""交互式词云生成器类"""
def __init__(self):
self.font_path = self.setup_chinese_font()
self.stopwords = self.load_stopwords()
def setup_chinese_font(self):
"""自动配置中文字体"""
system = platform.system()
if system == "Windows":
font_paths = [
"C:/Windows/Fonts/simhei.ttf",
"C:/Windows/Fonts/msyh.ttc",
"C:/Windows/Fonts/simsun.ttc",
]
elif system == "Darwin":
font_paths = [
"/System/Library/Fonts/PingFang.ttc",
"/System/Library/Fonts/STHeiti Light.ttc",
]
else:
font_paths = [
"/usr/share/fonts/truetype/wqy/wqy-microhei.ttc",
"/usr/share/fonts/truetype/arphic/uming.ttc",
]
for font_path in font_paths:
if os.path.exists(font_path):
plt.rcParams['font.sans-serif'] = [fm.FontProperties(fname=font_path).get_name()]
plt.rcParams['axes.unicode_minus'] = False
print(f"✅ 字体配置成功: {font_path}")
return font_path
print("⚠️ 未找到理想字体,将使用系统默认字体")
return None
def load_stopwords(self):
"""加载停用词"""
return {
'的', '了', '在', '是', '我', '有', '和', '就', '不', '人', '都', '一', '一个', '上', '也', '很', '到', '说', '要', '去', '你', '会', '着', '没有', '看', '好', '自己', '这',
'那', '里', '后', '以', '时', '来', '用', '她', '他', '如果', '没', '多', '然后', '现在', '可以', '但', '这个', '不能', '只', '这样', '我们', '能', '下', '过', '什么', '年',
'同', '工作', '还', '如', '被', '最', '所', '所以', '因为', '由于', '虽然', '但是', '然而', '不过', '而且', '并且', '或者', '以及', '等等', '比如', '例如', '等',
'!', '?', '。', ',', '、', ';', ':', '"', '"', ''', ''', '(', ')', '【', '】', '《', '》', '—', '…', '·', '\n', '\t', ' '
}
def preprocess_text(self, text):
"""文本预处理"""
# 分词
words = jieba.cut(text.strip())
# 过滤词汇
filtered_words = []
for word in words:
word = word.strip()
if len(word) >= 2 and word not in self.stopwords and word.isalpha():
filtered_words.append(word)
return filtered_words
def generate_wordcloud(self, text, title="自定义词云", save_path=None,
width=800, height=600, background_color='white',
colormap='viridis', max_words=100):
"""生成词云"""
if not text.strip():
print("❌ 输入文本为空,请输入有效内容")
return None, None
# 预处理文本
words = self.preprocess_text(text)
if not words:
print("❌ 处理后没有有效词汇,请检查输入内容")
return None, None
# 计算词频
word_freq = Counter(words)
text_for_cloud = ' '.join(words)
# 词云配置
config = {
'width': width,
'height': height,
'background_color': background_color,
'max_words': max_words,
'colormap': colormap,
'relative_scaling': 0.5,
'min_font_size': 10
}
if self.font_path:
config['font_path'] = self.font_path
try:
# 生成词云
wordcloud = WordCloud(**config).generate(text_for_cloud)
# 显示词云
plt.figure(figsize=(12, 8))
plt.imshow(wordcloud, interpolation='bilinear')
plt.axis('off')
plt.title(title, fontsize=16, pad=20)
plt.tight_layout()
# 保存文件
if save_path:
plt.savefig(save_path, dpi=300, bbox_inches='tight')
print(f"✅ 词云已保存: {save_path}")
plt.show()
return wordcloud, word_freq
except Exception as e:
print(f"❌ 词云生成失败: {e}")
return None, word_freq
class WordCloudGUI:
"""图形界面版本的词云生成器"""
def __init__(self):
self.generator = InteractiveWordCloudGenerator()
self.setup_gui()
def setup_gui(self):
"""设置图形界面"""
self.root = tk.Tk()
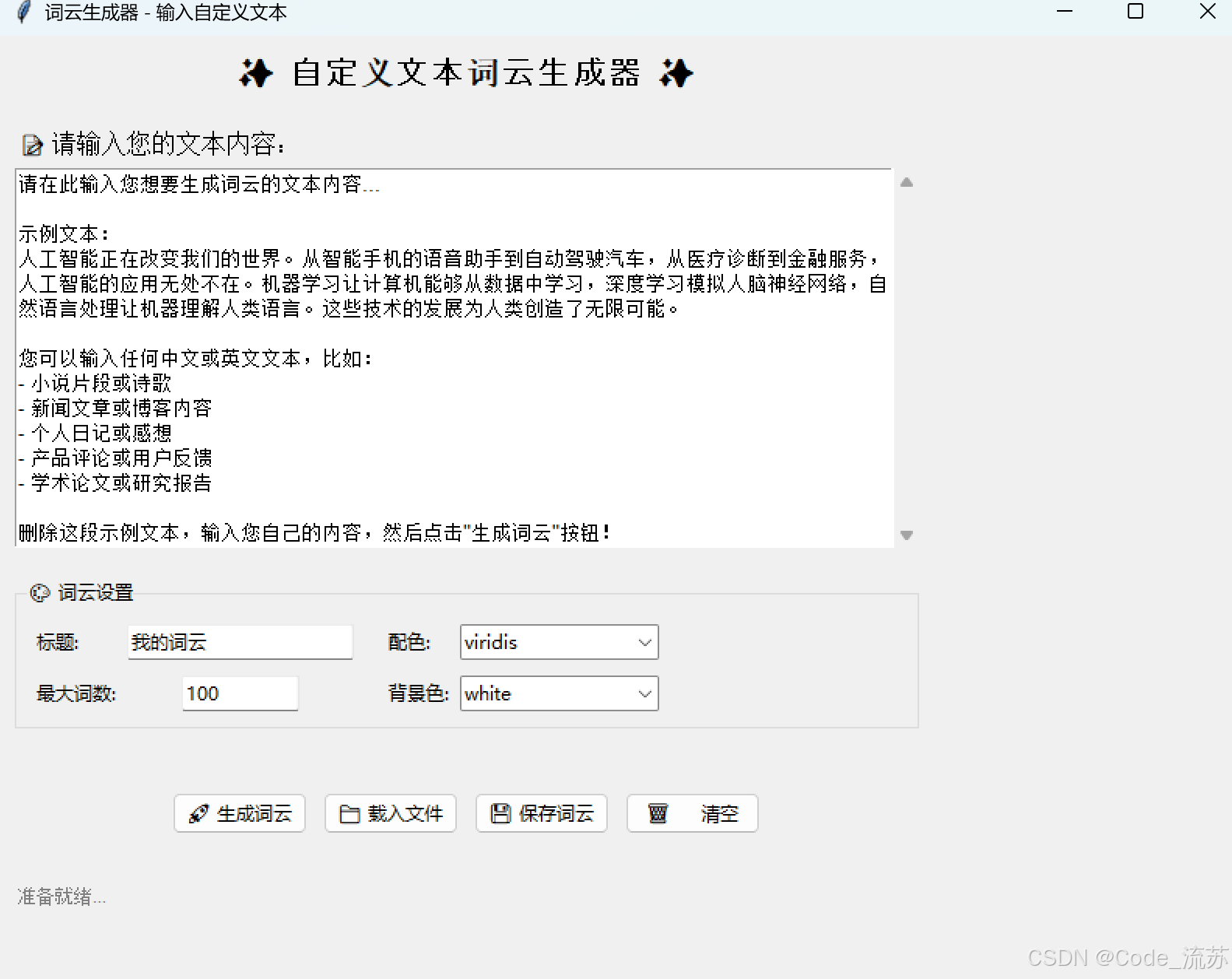
self.root.title("词云生成器 - 输入自定义文本")
self.root.geometry("800x700")
# 创建主框架
main_frame = ttk.Frame(self.root, padding="10")
main_frame.grid(row=0, column=0, sticky=(tk.W, tk.E, tk.N, tk.S))
# 标题
title_label = ttk.Label(main_frame, text="✨ 自定义文本词云生成器 ✨",
font=("Arial", 16, "bold"))
title_label.grid(row=0, column=0, columnspan=2, pady=(0, 20))
# 文本输入区域
ttk.Label(main_frame, text="📝 请输入您的文本内容:",
font=("Arial", 12)).grid(row=1, column=0, columnspan=2, sticky=tk.W, pady=(0, 5))
self.text_input = scrolledtext.ScrolledText(main_frame, width=80, height=15,
wrap=tk.WORD, font=("Arial", 10))
self.text_input.grid(row=2, column=0, columnspan=2, pady=(0, 20), sticky=(tk.W, tk.E))
# 设置区域
settings_frame = ttk.LabelFrame(main_frame, text="🎨 词云设置", padding="10")
settings_frame.grid(row=3, column=0, columnspan=2, sticky=(tk.W, tk.E), pady=(0, 20))
# 标题设置
ttk.Label(settings_frame, text="标题:").grid(row=0, column=0, sticky=tk.W)
self.title_var = tk.StringVar(value="我的词云")
ttk.Entry(settings_frame, textvariable=self.title_var, width=20).grid(row=0, column=1, padx=(5, 20))
# 配色方案
ttk.Label(settings_frame, text="配色:").grid(row=0, column=2, sticky=tk.W)
self.colormap_var = tk.StringVar(value="viridis")
colormap_combo = ttk.Combobox(settings_frame, textvariable=self.colormap_var, width=15)
colormap_combo['values'] = ('viridis', 'plasma', 'inferno', 'magma', 'cool', 'hot', 'spring', 'summer')
colormap_combo.grid(row=0, column=3, padx=(5, 0))
# 最大词数
ttk.Label(settings_frame, text="最大词数:").grid(row=1, column=0, sticky=tk.W, pady=(10, 0))
self.max_words_var = tk.StringVar(value="100")
ttk.Entry(settings_frame, textvariable=self.max_words_var, width=10).grid(row=1, column=1, padx=(5, 20), pady=(10, 0))
# 背景色
ttk.Label(settings_frame, text="背景色:").grid(row=1, column=2, sticky=tk.W, pady=(10, 0))
self.bg_color_var = tk.StringVar(value="white")
bg_combo = ttk.Combobox(settings_frame, textvariable=self.bg_color_var, width=15)
bg_combo['values'] = ('white', 'black', 'lightgray', 'lightblue', 'lightyellow', 'lightgreen')
bg_combo.grid(row=1, column=3, padx=(5, 0), pady=(10, 0))
# 按钮区域
button_frame = ttk.Frame(main_frame)
button_frame.grid(row=4, column=0, columnspan=2, pady=20)
# 生成词云按钮
generate_btn = ttk.Button(button_frame, text="🚀 生成词云",
command=self.generate_wordcloud_thread,
style="Accent.TButton")
generate_btn.pack(side=tk.LEFT, padx=(0, 10))
# 载入文件按钮
load_btn = ttk.Button(button_frame, text="📁 载入文件",
command=self.load_file)
load_btn.pack(side=tk.LEFT, padx=(0, 10))
# 保存词云按钮
save_btn = ttk.Button(button_frame, text="💾 保存词云",
command=self.save_wordcloud)
save_btn.pack(side=tk.LEFT, padx=(0, 10))
# 清空文本按钮
clear_btn = ttk.Button(button_frame, text="🗑️ 清空",
command=self.clear_text)
clear_btn.pack(side=tk.LEFT)
# 状态栏
self.status_var = tk.StringVar(value="准备就绪...")
status_label = ttk.Label(main_frame, textvariable=self.status_var,
font=("Arial", 9), foreground="gray")
status_label.grid(row=5, column=0, columnspan=2, sticky=tk.W, pady=(10, 0))
# 示例文本
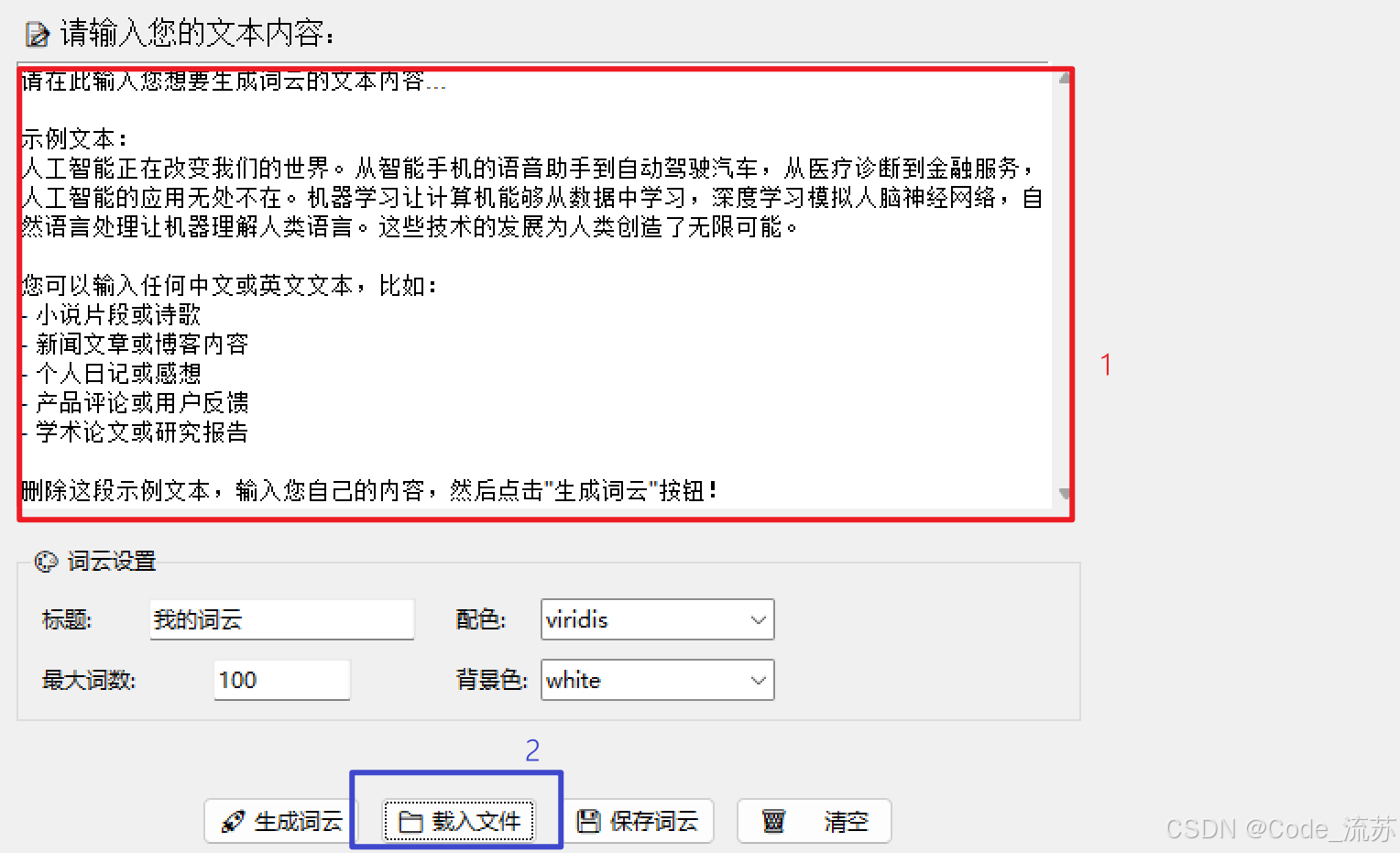
sample_text = """请在此输入您想要生成词云的文本内容...
示例文本:
人工智能正在改变我们的世界。从智能手机的语音助手到自动驾驶汽车,从医疗诊断到金融服务,人工智能的应用无处不在。机器学习让计算机能够从数据中学习,深度学习模拟人脑神经网络,自然语言处理让机器理解人类语言。这些技术的发展为人类创造了无限可能。
您可以输入任何中文或英文文本,比如:
- 小说片段或诗歌
- 新闻文章或博客内容
- 个人日记或感想
- 产品评论或用户反馈
- 学术论文或研究报告
删除这段示例文本,输入您自己的内容,然后点击"生成词云"按钮!"""
self.text_input.insert(tk.END, sample_text)
# 存储最后生成的词云
self.last_wordcloud = None
def generate_wordcloud_thread(self):
"""在新线程中生成词云,避免界面卡顿"""
def generate():
self.status_var.set("正在生成词云...")
self.root.update()
text = self.text_input.get(1.0, tk.END)
title = self.title_var.get()
colormap = self.colormap_var.get()
background = self.bg_color_var.get()
try:
max_words = int(self.max_words_var.get())
except ValueError:
max_words = 100
self.max_words_var.set("100")
wordcloud, word_freq = self.generator.generate_wordcloud(
text, title=title, colormap=colormap,
background_color=background, max_words=max_words
)
if wordcloud:
self.last_wordcloud = wordcloud
self.status_var.set(f"✅ 词云生成成功!共包含 {len(word_freq)} 个不同词汇")
# 显示词频统计
if word_freq:
top_words = word_freq.most_common(10)
freq_text = "高频词汇:" + "、".join([f"{word}({freq})" for word, freq in top_words])
self.status_var.set(f"✅ 生成成功!{freq_text}")
else:
self.status_var.set("❌ 词云生成失败,请检查输入文本")
# 在新线程中运行
thread = threading.Thread(target=generate)
thread.daemon = True
thread.start()
def load_file(self):
"""载入文本文件"""
file_path = filedialog.askopenfilename(
title="选择文本文件",
filetypes=[("文本文件", "*.txt"), ("所有文件", "*.*")]
)
if file_path:
try:
with open(file_path, 'r', encoding='utf-8') as file:
content = file.read()
self.text_input.delete(1.0, tk.END)
self.text_input.insert(1.0, content)
self.status_var.set(f"✅ 文件载入成功: {os.path.basename(file_path)}")
except Exception as e:
messagebox.showerror("错误", f"无法载入文件: {e}")
def save_wordcloud(self):
"""保存词云图片"""
if not self.last_wordcloud:
messagebox.showwarning("提示", "请先生成词云再保存")
return
file_path = filedialog.asksaveasfilename(
title="保存词云",
defaultextension=".png",
filetypes=[("PNG图片", "*.png"), ("JPG图片", "*.jpg"), ("所有文件", "*.*")]
)
if file_path:
try:
self.last_wordcloud.to_file(file_path)
self.status_var.set(f"✅ 词云已保存: {os.path.basename(file_path)}")
except Exception as e:
messagebox.showerror("错误", f"保存失败: {e}")
def clear_text(self):
"""清空文本"""
self.text_input.delete(1.0, tk.END)
self.status_var.set("文本已清空")
def run(self):
"""运行GUI"""
self.root.mainloop()
# 命令行版本的交互式生成器
def console_interactive_generator():
"""命令行交互式词云生成器"""
generator = InteractiveWordCloudGenerator()
print("🎉 欢迎使用交互式词云生成器!")
print("=" * 50)
while True:
print("\n📝 请选择文本输入方式:")
print("1. 直接输入文本")
print("2. 从文件读取")
print("3. 使用示例文本")
print("4. 启动图形界面")
print("5. 退出程序")
choice = input("\n请输入选择 (1-5): ").strip()
if choice == '1':
print("\n请输入您的文本内容(输入完成后按 Ctrl+D 或输入 'END' 结束):")
lines = []
while True:
try:
line = input()
if line.strip() == 'END':
break
lines.append(line)
except EOFError:
break
text = '\n'.join(lines)
elif choice == '2':
file_path = input("请输入文件路径: ").strip()
try:
with open(file_path, 'r', encoding='utf-8') as f:
text = f.read()
print(f"✅ 文件读取成功: {file_path}")
except Exception as e:
print(f"❌ 文件读取失败: {e}")
continue
elif choice == '3':
text = """
科技改变生活,人工智能引领未来。在这个数字化时代,机器学习和深度学习技术正在revolutionizing各个行业。
从智能手机到智能家居,从自动驾驶到智能医疗,AI技术无处不在。数据科学家们利用大数据分析,
为企业提供精准的商业洞察。云计算平台支撑着这一切的实现,而区块链技术则为数据安全保驾护航。
未来,量子计算和边缘计算将开启新的技术纪元,为人类社会带来更多可能性。
"""
print("✅ 使用示例文本")
elif choice == '4':
print("🚀 启动图形界面...")
gui = WordCloudGUI()
gui.run()
continue
elif choice == '5':
print("👋 感谢使用,再见!")
break
else:
print("❌ 无效选择,请重新输入")
continue
# 生成词云
if 'text' in locals() and text.strip():
# 获取自定义设置
title = input("\n请输入词云标题(默认:我的词云): ").strip() or "我的词云"
save_name = input("请输入保存文件名(默认:my_wordcloud.png): ").strip() or "my_wordcloud.png"
print("\n🎨 生成词云中...")
wordcloud, word_freq = generator.generate_wordcloud(text, title=title, save_path=save_name)
if word_freq:
print(f"\n📊 词频统计(前10个):")
for word, freq in word_freq.most_common(10):
print(f" {word}: {freq}")
def quick_generate(text, title="快速词云"):
"""快速生成函数 - 适合在其他脚本中调用"""
generator = InteractiveWordCloudGenerator()
return generator.generate_wordcloud(text, title=title)
if __name__ == "__main__":
print("🎯 词云生成器启动选项:")
print("1. 图形界面版本(推荐)")
print("2. 命令行交互版本")
mode = input("请选择模式 (1 或 2): ").strip()
if mode == "1":
# 启动图形界面
app = WordCloudGUI()
app.run()
else:
# 启动命令行版本
console_interactive_generator()
界面预览:
八、总结:让数据可视化触手可及
通过这个交互式词云生成器,我们不仅学会了:
- 技术技能:jieba分词、WordCloud库、Tkinter界面开发
- 设计思维:用户体验优化、错误处理、跨平台兼容
- 实用工具:可以直接用于工作、学习、生活中的文本分析
更重要的是,这个项目展示了Python在数据可视化领域的强大能力。几百行代码就能打造出专业级的文本分析工具,这就是Python的魅力所在!
💻 完整代码已经在文章中为你准备好了,快去动手试试吧!不管是分析用户评论、制作研究报告,还是给女朋友做个浪漫的文字云,这个工具都能帮你轻松搞定!
让我们一起用代码让世界变得更有趣!🎉
创作者:Code_流苏(CSDN)(一个喜欢古诗词和编程的Coder😊)


![reverse_ssh 建立反向 SSH 连接指南 混淆AV [好东西哟]](https://i-blog.csdnimg.cn/direct/84f6ca44553f4eec8eedab4ae22d9a35.png)


![[Python] Python运维:系统性能信息模块psutil和系统批量运维管理器paramiko](https://i-blog.csdnimg.cn/direct/07e98d1de4ff4044a669f7cf11e80f1e.png)