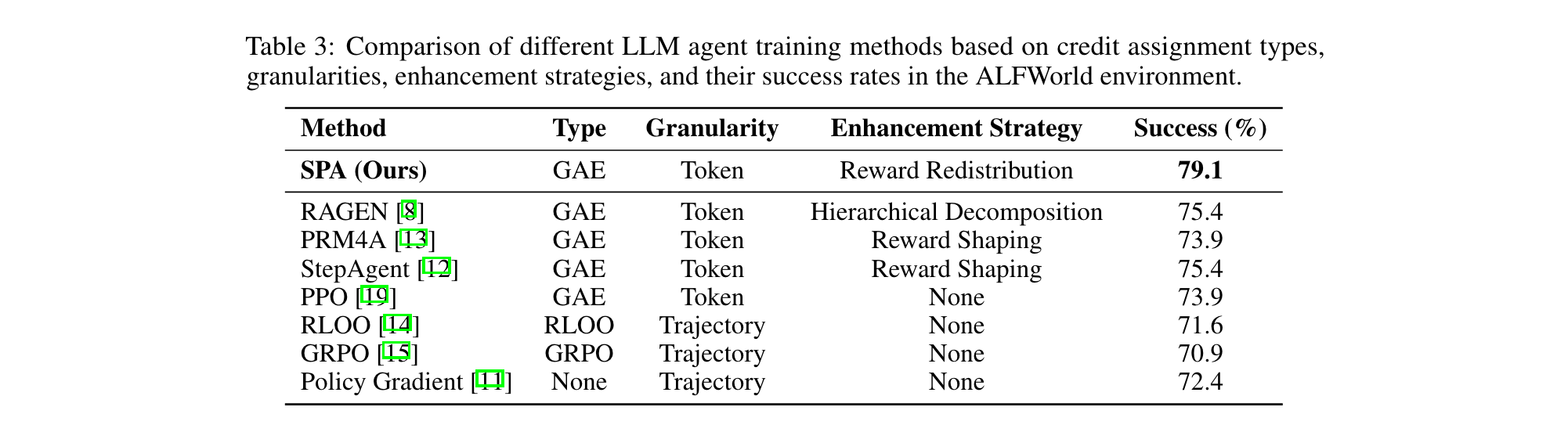
创建并打开文件
open(file,mode)函数
该函数用于打开一个文件并返回对应的文件对象。
file参数指定的是文件路径和文件名,如果没有添加路径,那么默认将文件创建在python的主文件夹里面。mode参数指定的是打开的模式,r表示读取(默认)、w表示写入、x表示排他性创建文件(如果文件已存在则打开失败)、a表示在文件末尾追加内容、+表示更新文件(读取和写入)。
open("file.txt","w") 
注意:如果已经是一个文件对象,那么可以直接调用open方法,不需要传递第一个参数。
from pathlib import Path
p = Path.cwd()/"file.txt"
f = p.open("w")
f.write("hello")
f.close()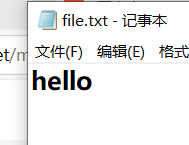
write()方法
该方法将字符串写入对象文件中,并返回写入的字符数量(字符串长度)。
f = open("file.txt","w")
print(f.write("I LOVE Python"))
writelines()方法
将多个字符串写入到文件对象中,不会自动添加换行符,所以通常是人为的加在每个字符串的末尾。此方法没有返回值。
f = open("file.txt","w")
f.writelines(["I love you\n","You love me\n"])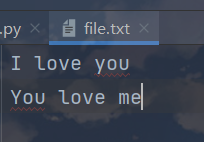
close()方法
该方法用于关闭文件对象,当文件对象关闭之后才能将之前传入的字符串写入文件。
readable()方法
该方法用于判断文件对象是否支持读取。支持则返回True,否则返回False。
writeable()方法
该方法用于判断文件对象是否支持写入。支持则返回True,否则返回False。
f = open("file.txt","r+")
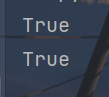
print(f.readable())
print(f.writable())
for读取
python的文件是支持迭代的,我们可以将文件放到for语句里面实现读取。
f = open("file.txt","r+")
for each in f:
print(each)
read()方法
文件对象里面有个指针,被称之为文件指针,它负责指向文件的当前位置,当用户读取一个字符时,文件指针就会指向下一个字符,直到文件的末尾EOF。
f = open("file.txt","r+")
print(f.read())
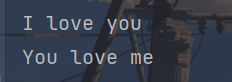
tell()方法
该方法用于返回当前文件指针在文件对象中的位置。
f = open("file.txt","r+")
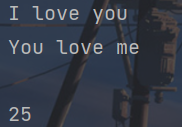
print(f.read())
print(f.tell())
seek(offset,whence)方法
修改文件指针的位置,从whence参数指定的位置(0代表文件的起始位置,1代表当前位置,2代表文件末尾)偏移offset个字节,返回值是新的索引位置。
readline(size=-1)方法
从文件对象中读取指定数量的字符(或遇到EOF停止);当未指定该参数,或参数为负值的时候,读取剩余的所有字符。
flush()方法
将文件对象中的缓存数据写入到文件中(未必有效)。
truncate(pos=None)方法
将文件对象截取到pos的位置,默认是截取到文件指针当前指定的位置。pos之后的文件内容会被清除。
注意:如果将文件模式改为w,但是没有写入任何内容就直接关闭文件对象,那么文件的所有内容都会消失。
f = open("file.txt","w")
f.close()

路径处理
pathlib--面向对象的文件系统路径
from pathlib import Path:从pathlib模块中单独导入path,使用这种导入方式,在后面调用模块时就不需要加上模块名了。
cwd()方法
获取当前目录的路径。
from pathlib import Path
print(Path.cwd())

is_dir()方法
判断一个路径是否为一个文件夹。
from pathlib import Path
p = Path.cwd()
q = p/"file.txt"
print(p.is_dir())
print(q.is_dir())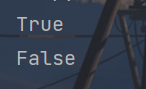
is_file()方法
判断一个路径是否为一个文件。
from pathlib import Path
p = Path.cwd()
q = p/"file.txt"
print(p.is_file())
print(q.is_file())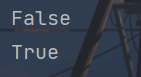
exists()方法
检测一个路径是否存在。
from pathlib import Path
p = Path.cwd()
q = p/"hello.txt"
print(p.exists())
print(q.exists())

name属性
获取路径的最后一个部分。
from pathlib import Path
p = Path.cwd()
q = p/"hello.txt"
print(p.name)
print(q.name)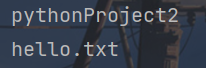
stem属性
获取文件名。
from pathlib import Path
p = Path.cwd()
q = p/"hello.txt"
print(p.stem)
print(q.stem)
suffix属性
用于获取文件的后缀。
from pathlib import Path
p = Path.cwd()
q = p/"hello.txt"
print(p.suffix)
print(q.suffix)
parent属性
获取其父级目录。
from pathlib import Path
p = Path.cwd()
q = p/"hello.txt"
print(p.parent)
print(q.parent)
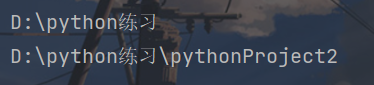
parents属性
获取其逻辑祖先构成的一个不可变序列(可迭代对象)。其支持索引,0是父级目录,1是0的父级目录。
from pathlib import Path
p = Path.cwd()
q = p/"hello.txt"
ps = p.parents
for each in ps:
print(each)
print(ps[0])
print(ps[1])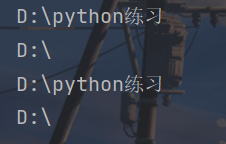
parts属性
将路径的各个组件拆分成元组。
from pathlib import Path
p = Path.cwd()
q = p/"hello.txt"
print(p.parts)

stat()方法
查询文件或文件夹的信息。
from pathlib import Path
p = Path.cwd()
q = p/"hello.txt"
print(p.stat())

修改路径
mkdir()方法
创建文件夹。如果想要创建的文件夹已经存在会报错。
from pathlib import Path
p = Path.cwd()/"hello"
p.mkdir()
p.mkdir()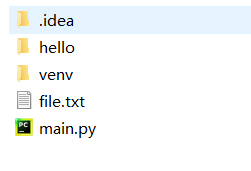

如果不想进行提示,那么我们可以将exist_ok参数设置为True。
注意:如果路径中存在多个不存在的父级目录,也会报错。可以通过设置parents参数为True,创建不存在的多级目录。
修改文件
rename()方法
修改文件名。
from pathlib import Path
p = Path.cwd()/"file.txt"
p.rename("NewFile.txt")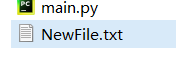
replace()方法
替换指定的文件或者文件夹。
删除文件夹或文件
rmdir()方法
用于删除文件夹。但目录不为空不会随意删除,需要显示有unlink将文件夹里面的文件删除。
unlink()方法
用于删除文件。
查找文件
glob()方法
from pathlib import Path
n = Path('.')
print(list(n.glob("*.txt"))) ![]()
绝对路径和相对路径
绝对路径
是文件真正存在的路径。从根目录开始一级一级的指向最终的文件或者文件夹。
相对路径
以当前目录为基准,进行一级一级的目录推导的路径。使用.(点)来表示当前所在的目录,使用两个紧挨着的.(点)来表示上一级目录。
resolve()方法
该方法可以将相对路径转换为绝对路径。
from pathlib import Path
print(Path("./file.txt"))
print(Path("./file.txt").resolve())
iterdir()方法
获取当前路径下所有子文件和子文件夹的对象。
from pathlib import Path
p = Path.cwd()
q = p/"hello.txt"
for each in p.iterdir():
print(each)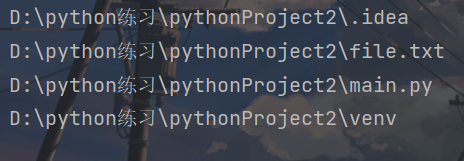
with语句和上下文管理器
from pathlib import Path
with open("file.txt") as f:
f.write("I love you")
"""
相当于
f = open("file.txt","w")
f.write("I love you")
"""
使用上下文管理器就是上文打开文件,下文关闭文件。使用上下文管理器就不需要手动的关闭文件,文件处理的代码只需要放在with语句的缩进中。使用上下文管理器的最大优势就是能够确保资源的施放。
pickle
解决的是永久存储Python对象的问题,允许将字符串、列表、字典这些python对象保存为文件的形式。将python对象序列化就是将python对象转换为二进制字节流的过程。
dump()方法
将数据传入pickle文件中。
import pickle
x,y,z=1,2,3
s = "py"
l = ["hello",520,1314]
d = {"one":1,"two":2}
with open("data.pkl","wb") as f:#后缀必须是pkl,wb是以二进制形式打开,二进制可写入的形式
pickle.dump(x,f)
pickle.dump(y, f)
pickle.dump(z, f)
pickle.dump(s, f)
pickle.dump(l, f)
pickle.dump(d, f)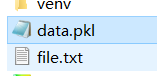
load()方法
将pickle文件中的二进制数据重新读取。
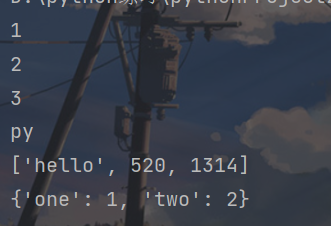
import pickle
with open("data.pkl","rb") as f:#后缀必须是pkl,rb是以二进制形式打开,二进制可读入的形式
x = pickle.load(f)
y = pickle.load(f)
z = pickle.load(f)
s = pickle.load(f)
l = pickle.load(f)
d = pickle.load(f)
print(x,y,z,s,l,d,sep="\n")