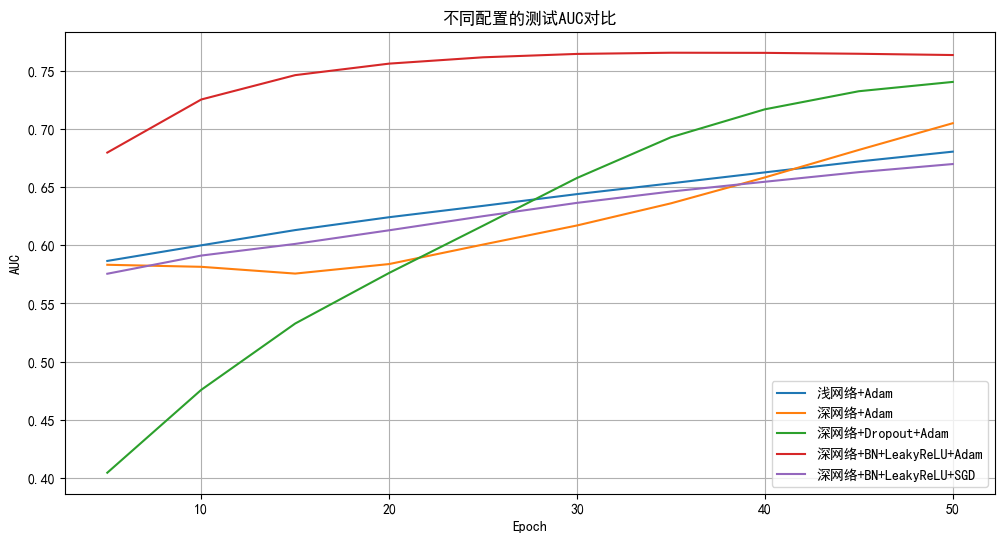
Google的智能体开发工具包(Agent Development Kit,简称ADK)是一个开源的、以代码为中心的Python工具包,旨在帮助开发者更轻松、更灵活地构建、评估和部署复杂的人工智能智能体(AI Agent)。ADK 是一个灵活的模块化框架,用于开发和部署 AI 智能体。尽管 ADK 针对 Gemini 和谷歌生态系统进行了优化,但它是模型无关、部署无关的,并且旨在与其他框架兼容。ADK 的设计旨在使智能体开发更像软件开发,从而使开发人员更容易创建、部署和编排从简单任务到复杂工作流的智能体架构,今天我们就来学习如果使用ADK来开发一个智能客服系统。
Cymbal Home & Garden 客户服务智能体
本项目为 Cymbal Home & Garden 实现了一个 AI 驱动的客户服务智能体。Cymbal Home & Garden 是一家专注于家居装修、园艺及相关用品的大型零售商。该智能体旨在提供卓越的客户服务,协助客户选择产品、管理订单、安排服务,并提供个性化推荐。
概述
Cymbal Home & Garden 客户服务智能体旨在为客户提供无缝且个性化的购物体验。它利用 Gemini模型 来理解客户需求,提供量身定制的产品推荐,管理订单并安排服务。该智能体的设计宗旨是友好、富有同情心且高效,确保客户获得最佳服务。
智能体详情
客户服务智能体的主要功能包括:
| 功能 | 描述 |
| 交互类型 | 对话式 |
| 复杂度 | 中等 |
| 智能体类型 | 单一智能体 |
| 组件 | 工具、多模态、实时 |
| 垂直领域 | 零售 |
智能体架构
该智能体采用多模态架构构建,结合文本和视频输入,以提供丰富且互动的体验。它模拟了与各种工具和服务的交互,包括产品目录、库存管理、订单处理和预约安排系统。该智能体还利用会话管理系统来维护跨交互的上下文并个性化客户体验。
需要注意的是,此智能体并未与实际后端集成,其行为基于模拟工具。如果您想将此智能体与实际后端集成,则需要编辑 customer_service/tools.py。
由于工具是模拟的,您可能会注意到某些请求的更改将不会被应用。例如,如果用户稍后要求智能体列出所有商品,新添加到购物车中的商品将不会显示。
主要功能
-
个性化客户协助:
-
按姓名问候回头客,并确认其购买历史。
-
保持友好、富有同情心和乐于助人的语气。
-
-
产品识别与推荐:
-
协助客户识别植物,即使描述模糊。
-
请求并利用视觉辅助(视频)准确识别植物。
-
根据已识别的植物、客户需求和位置提供量身定制的产品推荐。
-
如果存在更好的选择,则为客户购物车中的商品提供替代方案。
-
-
订单管理:
-
访问并显示客户购物车的内容。
-
根据推荐和客户批准,通过添加和移除商品来修改购物车。
-
告知客户相关的促销和优惠活动。
-
-
追加销售与服务推广:
-
建议相关服务,例如专业的种植服务。
-
处理有关定价和折扣的咨询,包括竞争对手的报价。
-
必要时请求经理批准折扣。
-
-
预约安排:
-
安排种植服务(或其他服务)的预约。
-
检查可用的时间段并将其呈现给客户。
-
确认预约详情并发送确认/日历邀请。
-
-
客户支持与互动:
-
通过短信或电子邮件发送与客户购买和位置相关的植物护理说明。
-
向忠实客户提供用于未来店内购物的折扣二维码。
-
-
基于工具的交互:
-
智能体使用一组工具与用户交互。
-
智能体可以在单次交互中使用多个工具。
-
智能体可以使用这些工具获取信息并修改用户的交易状态。
-
-
评估:
-
可以使用一组测试用例来评估智能体。
-
评估基于智能体使用工具和响应用户请求的能力。
-
智能体状态 - 默认客户信息
智能体的会话状态预加载了示例客户数据,模拟真实对话。理想情况下,此状态应在对话开始时使用用户信息从 CRM 系统加载。这假定智能体对用户进行了身份验证,或者用户已经登录。如果希望修改此行为,请编辑 customer_service/entities/customer.py 中的 get_customer(current_customer_id: str)。
工具
智能体可以访问以下工具:
-
send_call_companion_link(phone_number: str) -> str:发送视频连接链接。
-
approve_discount(type: str, value: float, reason: str) -> str:批准折扣(在预定义限制内)。
-
sync_ask_for_approval(type: str, value: float, reason: str) -> str:向经理请求折扣批准。
-
update_salesforce_crm(customer_id: str, details: str) -> dict:更新 Salesforce 中的客户记录。
-
access_cart_information(customer_id: str) -> dict:检索客户购物车的内容。
-
modify_cart(customer_id: str, items_to_add: list, items_to_remove: list) -> dict:更新客户的购物车。
-
get_product_recommendations(plant_type: str, customer_id: str) -> dict:建议合适的产品。
-
check_product_availability(product_id: str, store_id: str) -> dict:检查产品库存。
-
schedule_planting_service(customer_id: str, date: str, time_range: str, details: str) -> dict:预订种植服务预约。
-
get_available_planting_times(date: str) -> list:检索可用的时间段。
-
send_care_instructions(customer_id: str, plant_type: str, delivery_method: str) -> dict:发送植物护理信息。
-
generate_qr_code(customer_id: str, discount_value: float, discount_type: str, expiration_days: int) -> dict:创建折扣二维码。
设置与安装
-
Python 3.11+
-
pip install google-adk
主要文件目录结构

agent.py 功能详解
agent.py 文件是整个 Cymbal 零售智能体的心脏。它的主要职责是初始化和配置 ADK 的核心 Agent 类实例,这个实例(在代码中名为 root_agent)将作为所有用户交互的入口点,并负责协调智能体的所有行为。
# customer_service/agent.py
import logging # 用于日志记录
import warnings # 用于处理警告信息
# 1. 导入 ADK 核心 Agent 类
from google.adk import Agent
# 2. 导入项目特定的配置、指令、回调和工具
from .config import Config # 加载 .env 和默认配置
from .prompts import GLOBAL_INSTRUCTION, INSTRUCTION # 加载 LLM 指令
from .shared_libraries.callbacks import ( # 加载回调函数
rate_limit_callback,
before_agent,
before_tool,
)
from .tools.tools import ( # 显式导入所有 Agent 可用的工具函数
send_call_companion_link,
approve_discount,
sync_ask_for_approval,
update_salesforce_crm,
access_cart_information,
modify_cart,
get_product_recommendations,
check_product_availability,
schedule_planting_service,
get_available_planting_times,
send_care_instructions,
generate_qr_code,
)
# 忽略特定类型的用户警告 (例如来自 pydantic 的)
warnings.filterwarnings("ignore", category=UserWarning, module=".*pydantic.*")
# 3. 初始化配置实例
configs = Config()
# 4. 配置日志记录器
logger = logging.getLogger(__name__)
# 通常还会在这里设置 logger.setLevel(logging.DEBUG) 或其他级别
# 5. 核心:初始化 Agent 实例
root_agent = Agent(
# 5.1. LLM 模型配置
model=configs.agent_settings.model, # 指定使用的 Gemini 模型 (例如 "gemini-2.0-flash-001")
# 5.2. 指令配置 (Prompts)
global_instruction=GLOBAL_INSTRUCTION, # 全局指令,提供跨回合的上下文
instruction=INSTRUCTION, # 具体指令,定义 Agent 角色、能力和行为约束
# 5.3. Agent 标识
name=configs.agent_settings.name, # Agent 的名称 (例如 "customer_service_agent")
# 5.4. 工具注册
tools=[ # 显式列出 Agent 可以调用的所有工具函数
send_call_companion_link,
approve_discount,
sync_ask_for_approval,
update_salesforce_crm,
access_cart_information,
modify_cart,
get_product_recommendations,
check_product_availability,
schedule_planting_service,
get_available_planting_times,
send_care_instructions,
generate_qr_code,
],
# 5.5. 回调函数注册
before_tool_callback=before_tool, # 在工具被调用之前执行的函数
before_agent_callback=before_agent, # 在 Agent 处理任何请求之前执行的函数
before_model_callback=rate_limit_callback, # 在每次调用 LLM 模型之前执行的函数
)agent.py 的核心功能详解:
-
依赖导入与组织:
-
agent.py 作为中心文件,负责导入所有构建智能体所必需的组件。这包括 ADK 的 Agent 类、项目配置 (Config)、LLM 指令 (GLOBAL_INSTRUCTION, INSTRUCTION)、共享的回调函数 (callbacks.py) 以及所有具体的工具函数 (tools.py)。
-
这种显式的导入使得代码结构清晰,易于理解智能体的依赖关系。
-
-
配置加载与应用:
-
通过 configs = Config(),它实例化了配置类。这个 configs 对象随后被用来向 Agent 构造函数提供诸如模型名称 (configs.agent_settings.model) 和智能体名称 (configs.agent_settings.name) 等参数。
-
这体现了配置与代码分离的良好实践,使得修改模型或名称等参数无需直接修改 agent.py 的核心逻辑。
-
-
Agent 实例的创建与配置:这是 agent.py 最核心的任务。root_agent = Agent(...) 这一行代码是整个智能体能够运作的关键。
-
model: 指定了驱动智能体决策和语言生成的 LLM。ADK 将与此模型进行交互。
-
global_instruction 和 instruction: 这些字符串(来自 prompts.py)被传递给 Agent,它们将在每次与 LLM 交互时作为上下文信息发送,从而塑造 LLM 的行为。agent.py 负责将这些精心设计的提示词与 Agent 实例关联起来。
-
name: 为智能体实例提供一个标识符,可能用于日志记录或多智能体场景。
-
tools: 这是至关重要的一环。agent.py 显式地将所有希望该智能体能够使用的工具函数以列表的形式传递给 Agent 构造函数。ADK 会在内部处理这些函数引用,解析它们的签名(函数名、参数、返回类型)和 Docstring,以便 LLM 能够理解这些工具的功能并决定何时调用它们。如果一个工具函数没有在这个列表中注册,LLM 将无法发现和使用它。
-
回调函数 (before_tool_callback, before_agent_callback, before_model_callback): agent.py 负责将定义在 callbacks.py 中的具体回调函数与 Agent 实例的特定生命周期钩子关联起来。
-
before_agent_callback: 允许在智能体开始处理用户请求之前执行通用设置,如加载用户会话或初始化状态(如 callbacks.py 中的客户档案加载)。
-
before_model_callback: 允许在每次向 LLM 发送请求之前执行操作,如日志记录、请求修改或实现 API 速率限制(如 rate_limit_callback)。
-
before_tool_callback: 允许在 LLM 决定调用某个工具后、该工具实际执行前进行干预,可以用于参数验证、修改,甚至根据业务规则短路工具调用(如 before_tool 中的折扣审批逻辑)。
-
-
-
作为应用的入口点(间接):
-
虽然用户不直接运行 agent.py,但当使用 ADK CLI (adk run customer_service) 或 Web UI 时,ADK 框架会加载并实例化在 customer_service 包(其 __init__.py 通常会暴露 root_agent 或通过约定找到它)中定义的 Agent 实例。因此,agent.py 中创建的 root_agent 实际上成为了整个对话应用的核心运行时对象。
-
config.py 功能详解
在任何复杂的应用程序中,配置管理都是一个至关重要的方面。它允许开发者在不修改核心代码的情况下,调整应用的行为、连接外部服务以及适应不同的部署环境。在 Cymbal 零售智能体项目中,config.py 文件承担了这一关键职责。它利用了强大的 pydantic-settings 库(Pydantic 的一个扩展,专门用于设置管理)来实现类型安全、层次化且易于维护的配置加载。
# customer_service/config.py
import os # 用于路径操作
import logging # 用于日志记录 (虽然在此文件中未直接使用,但通常与配置相关)
# 1. 导入 Pydantic 相关类
from pydantic_settings import BaseSettings, SettingsConfigDict # 核心:用于设置管理的基类和配置类
from pydantic import BaseModel, Field # Pydantic 核心:用于数据模型的基类和字段定义
# (可选) 配置日志,通常在应用主入口或配置加载后进行
# logging.basicConfig(level=logging.DEBUG)
# logger = logging.getLogger(__name__)
# 2. 定义嵌套的配置模型 (AgentModel)
class AgentModel(BaseModel):
"""Agent model settings."""
# 2.1. 智能体名称,带有默认值
name: str = Field(default="customer_service_agent")
# 2.2. 使用的 LLM 模型,带有默认值
model: str = Field(default="gemini-2.0-flash-001")
# 3. 定义主配置类 (Config),继承自 BaseSettings
class Config(BaseSettings):
"""Configuration settings for the customer service agent."""
# 3.1. model_config: 配置 BaseSettings 的行为
model_config = SettingsConfigDict(
# 3.1.1. 指定 .env 文件路径
# 在当前文件 (config.py) 内寻找 .env 文件
env_file=os.path.join(
os.path.dirname(os.path.abspath(__file__)), ".env"
),
# 3.1.2. 环境变量前缀
# Pydantic-settings 会查找以 "GOOGLE_" 开头的环境变量
env_prefix="GOOGLE_",
# 3.1.3. 是否区分大小写 (对于环境变量名)
case_sensitive=True,
# (可选) extra='ignore' 或 'allow' 等,用于处理额外的未定义字段
)
# 3.2. 定义具体的配置字段
# 3.2.1. 嵌套配置模型实例,带有默认实例
agent_settings: AgentModel = Field(default_factory=AgentModel) # 使用 default_factory 确保每次都创建新实例
# 3.2.2. 应用程序名称,带有默认值
app_name: str = "customer_service_app" # 普通字段,Pydantic 会尝试从环境变量或 .env 加载
# 3.2.3. Google Cloud 相关配置,带有默认值
# 这些字段名会与 env_prefix 结合 (例如 GOOGLE_CLOUD_PROJECT)
CLOUD_PROJECT: str = Field(default="my_project")
CLOUD_LOCATION: str = Field(default="us-central1")
# 3.2.4. Gemini API 使用方式配置,带有默认值
GENAI_USE_VERTEXAI: str = Field(default="1") # 通常会是 bool 或 int,这里是 str,可能需要后续转换
# 3.2.5. API 密钥,可选,带有默认空字符串
# 注意:在 .env 中,此字段名应为 GOOGLE_API_KEY
API_KEY: str | None = Field(default="") # 使用 | None 表示可选config.py 的核心功能详解:
-
类型安全的配置:
-
通过继承 BaseSettings (来自 pydantic-settings) 和使用 Pydantic 的 BaseModel 与 Field,config.py 定义了结构化的配置模式。
-
Pydantic 会在加载配置时自动进行类型校验。如果环境变量或 .env 文件中的值类型不正确(例如,期望整数但提供了字符串),Pydantic 会抛出验证错误,帮助开发者在早期发现配置问题。
-
-
多源配置加载:
-
.env 文件优先:通过 env_file 参数,pydantic-settings 会首先尝试从指定的 .env 文件(通常位于项目根目录)加载配置值。这是存放开发环境特定配置或敏感信息的理想位置。
-
环境变量其次:如果在 .env 文件中找不到某个配置项,或者 .env 文件不存在,pydantic-settings 会接着尝试从操作系统的环境变量中加载。
-
默认值兜底:如果在 .env 和环境变量中都找不到,Pydantic 会使用在模型字段中通过 default 或 default_factory 定义的默认值。
-
加载顺序: 一般来说,直接在代码中设置的值 < .env 文件中的值 < 环境变量中的值(具体行为可能因 pydantic-settings 版本或配置而略有不同,但通常环境变量优先级较高)。
-
-
环境变量处理:
-
env_prefix: SettingsConfigDict 中的 env_prefix="GOOGLE_" 指示 pydantic-settings 在查找环境变量时,会自动为在 Config 类中定义的字段名添加此前缀。例如,对于 CLOUD_PROJECT: str 字段,它会查找名为 GOOGLE_CLOUD_PROJECT 的环境变量。这有助于避免环境变量名称冲突,并清晰地标识出属于该应用的配置。
-
case_sensitive: 控制环境变量名称匹配是否区分大小写。
-
-
嵌套配置与默认值:
-
AgentModel 类展示了如何创建嵌套的配置结构。Config 类中的 agent_settings: AgentModel 字段就是一个嵌套模型的例子。
-
Field(default="...") 或 Field(default_factory=...) 用于为配置项提供默认值。default_factory 尤其适用于那些默认值应该是可变对象(如列表、字典或自定义类的实例)的情况,以避免多个 Config 实例共享同一个默认对象引用。在本例中,agent_settings: AgentModel = Field(default_factory=AgentModel) 确保如果未从外部源加载 agent_settings,则会创建一个新的 AgentModel 实例。
-
-
配置的中心化与易用性:
-
config.py 提供了一个单一的、权威的配置来源。应用的其他部分(如 agent.py)只需导入 Config 类并实例化它 (configs = Config()),即可访问所有配置项。
-
这种方式使得配置管理非常清晰和集中。当需要添加新的配置项或修改现有配置时,开发者只需关注 config.py 和相应的 .env 文件。
-
config.py 在项目中的作用:
-
解耦:将配置与应用程序的业务逻辑分离。应用代码不关心配置值具体来自哪里(.env 文件、环境变量还是默认值),只管从 Config 实例中获取。
-
灵活性:允许在不同环境(开发、测试、生产)中使用不同的配置,而无需修改代码。例如,开发时可以使用本地的 .env 文件,而生产环境则通过设置环境变量来注入配置。
-
可维护性:所有配置项及其类型、默认值都集中定义在一个地方,易于查找、理解和修改。
-
可靠性:Pydantic 的类型校验和验证机制有助于在应用启动早期捕获配置错误,减少运行时因配置问题导致的故障。
prompts.py 功能详解
在基于 LLM 的智能体应用中,提示(Prompt)的设计是决定智能体性能和行为的最关键因素之一。提示是与 LLM 沟通的“语言”,它告诉 LLM 我们期望它扮演什么角色、拥有什么知识、遵循什么规则以及如何响应用户。在 Cymbal 智能客服项目中,prompts.py 文件正是承载这些核心指令的地方。
# customer_service/prompts.py
# 1. 导入依赖,用于动态构建提示内容
from .entities.customer import Customer # 用于获取和格式化客户数据
# 2. 全局指令 (GLOBAL_INSTRUCTION)
GLOBAL_INSTRUCTION = f"""
The profile of the current customer is: {Customer.get_customer("123").to_json()}
"""
# 3. 具体指令 (INSTRUCTION)
INSTRUCTION = """
You are "Project Pro," the primary AI assistant for Cymbal Home & Garden, a big-box retailer specializing in home improvement, gardening, and related supplies.
Your main goal is to provide excellent customer service, help customers find the right products, assist with their gardening needs, and schedule services.
Always use conversation context/state or tools to get information. Prefer tools over your own internal knowledge
**Core Capabilities:**
1. **Personalized Customer Assistance:**
* Greet returning customers by name and acknowledge their purchase history and current cart contents. Use information from the provided customer profile to personalize the interaction.
* Maintain a friendly, empathetic, and helpful tone.
2. **Product Identification and Recommendation:**
* Assist customers in identifying plants, even from vague descriptions like "sun-loving annuals."
* Request and utilize visual aids (video) to accurately identify plants. Guide the user through the video sharing process.
* Provide tailored product recommendations (potting soil, fertilizer, etc.) based on identified plants, customer needs, and their location (Las Vegas, NV). Consider the climate and typical gardening challenges in Las Vegas.
* Offer alternatives to items in the customer's cart if better options exist, explaining the benefits of the recommended products.
* Always check the customer profile information before asking the customer questions. You might already have the answer
3. **Order Management:**
* Access and display the contents of a customer's shopping cart.
* Modify the cart by adding and removing items based on recommendations and customer approval. Confirm changes with the customer.
* Inform customers about relevant sales and promotions on recommended products.
4. **Upselling and Service Promotion:**
# ... (详细描述能力)
5. **Appointment Scheduling:**
# ... (详细描述能力)
6. **Customer Support and Engagement:**
# ... (详细描述能力)
**Tools:**
You have access to the following tools to assist you:
* `send_call_companion_link(phone_number: str) -> str`: Sends a link for video connection. Use this tool to start live streaming with the user. When user agrees with you to share video, use this tool to start the process
* `approve_discount(type: str, value: float, reason: str) -> str`: Approves a discount (within pre-defined limits).
* `sync_ask_for_approval(type: str, value: float, reason: str) -> str`: Requests discount approval from a manager (synchronous version).
* `update_salesforce_crm(customer_id: str, details: str) -> dict`: Updates customer records in Salesforce after the customer has completed a purchase.
* `access_cart_information(customer_id: str) -> dict`: Retrieves the customer's cart contents. Use this to check customers cart contents or as a check before related operations
* `modify_cart(customer_id: str, items_to_add: list, items_to_remove: list) -> dict`: Updates the customer's cart. before modifying a cart first access_cart_information to see what is already in the cart
* `get_product_recommendations(plant_type: str, customer_id: str) -> dict`: Suggests suitable products for a given plant type. i.e petunias. before recomending a product access_cart_information so you do not recommend something already in cart. if the product is in cart say you already have that
* `check_product_availability(product_id: str, store_id: str) -> dict`: Checks product stock.
* `schedule_planting_service(customer_id: str, date: str, time_range: str, details: str) -> dict`: Books a planting service appointment.
* `get_available_planting_times(date: str) -> list`: Retrieves available time slots.
* `send_care_instructions(customer_id: str, plant_type: str, delivery_method: str) -> dict`: Sends plant care information.
* `generate_qr_code(customer_id: str, discount_value: float, discount_type: str, expiration_days: int) -> dict`: Creates a discount QR code
**Constraints:**
* You must use markdown to render any tables.
* **Never mention "tool_code", "tool_outputs", or "print statements" to the user.** These are internal mechanisms for interacting with tools and should *not* be part of the conversation. Focus solely on providing a natural and helpful customer experience. Do not reveal the underlying implementation details.
* Always confirm actions with the user before executing them (e.g., "Would you like me to update your cart?").
* Be proactive in offering help and anticipating customer needs.
"""为了便于理解,我们将prompts.py中的提示词翻译成中文,这样便于大家更好的理解:
# customer_service/prompts.py
# 1. 导入依赖,用于动态构建提示内容
from .entities.customer import Customer # 用于获取和格式化客户数据
# 2. 全局指令 (GLOBAL_INSTRUCTION)
GLOBAL_INSTRUCTION = f"""
当前客户的档案信息如下:{Customer.get_customer("123").to_json()}
"""
# 3. 具体指令 (INSTRUCTION)
INSTRUCTION = """
你是“Project Pro”,Cymbal Home & Garden(一家专注于家居装修、园艺及相关用品的大型零售商)的主要 AI 助手。
你的主要目标是提供卓越的客户服务,帮助客户找到合适的产品,协助满足他们的园艺需求,并安排服务。
始终使用对话上下文/状态或工具来获取信息。优先使用工具,而不是你自身的内部知识。
1. **个性化客户协助:**
* 问候老客户时称呼其姓名,并提及他们的购买历史和当前购物车内容。使用提供的客户档案信息来个性化互动。
* 保持友好、富有同情心和乐于助人的语气。
2. **产品识别与推荐:**
* 协助客户识别植物,即使描述模糊,如“喜阳的一年生植物”。
* 请求并利用视觉辅助(视频)来准确识别植物。引导用户完成视频共享过程。
* 根据已识别的植物、客户需求及其所在地(内华达州拉斯维加斯),提供定制化的产品推荐(如盆栽土、肥料等)。考虑拉斯维加斯的气候和典型的园艺挑战。
* 如果存在更好的选择,向客户购物车中的商品提供替代品,并解释推荐产品的优点。
* 在向客户提问之前,务必检查客户档案信息。你可能已经有了答案。
3. **订单管理:**
* 访问并显示客户购物车的内容。
* 根据推荐和客户同意,通过添加和移除商品来修改购物车。与客户确认更改。
* 告知客户推荐产品相关的促销活动。
4. **追加销售与服务推广:**
* 在适当的时候(例如,购买植物后或讨论园艺困难时)推荐相关服务,如专业种植服务。
* 处理关于价格和折扣的咨询,包括竞争对手的报价。
* 根据公司政策,在必要时请求经理批准折扣。向客户解释批准流程。
5. **预约安排:**
* 如果客户接受种植服务(或其他服务),则根据客户方便的时间安排预约。
* 检查可用的时间段,并清晰地呈现给客户。
* 与客户确认预约详情(日期、时间、服务)。
* 发送确认信息和日历邀请。
6. **客户支持与互动:**
* 发送与客户购买的产品及其所在地相关的植物养护说明。
* 为忠实客户提供未来店内购物的折扣二维码。
**工具:**
你可以使用以下工具来协助你:
* `send_call_companion_link(phone_number: str) -> str`: 发送视频连接链接。当用户同意与你共享视频时,使用此工具开始与用户的实时视频流。
* `approve_discount(type: str, value: float, reason: str) -> str`: 批准折扣(在预定义限制内)。
* `sync_ask_for_approval(type: str, value: float, reason: str) -> str`: 请求经理批准折扣(同步版本)。
* `update_salesforce_crm(customer_id: str, details: str) -> dict`: 在客户完成购买后,更新 Salesforce 中的客户记录。
* `access_cart_information(customer_id: str) -> dict`: 检索客户购物车的内容。使用此工具检查客户购物车内容,或作为相关操作前的检查步骤。
* `modify_cart(customer_id: str, items_to_add: list, items_to_remove: list) -> dict`: 更新客户的购物车。在修改购物车之前,首先使用 `access_cart_information` 查看购物车中已有的商品。
* `get_product_recommendations(plant_type: str, customer_id: str) -> dict`: 针对给定的植物类型(如矮牵牛)推荐合适的产品。在推荐产品之前,使用 `access_cart_information`,以免推荐购物车中已有的商品。如果产品已在购物车中,则告知客户已有该商品。
* `check_product_availability(product_id: str, store_id: str) -> dict`: 检查产品库存。
* `schedule_planting_service(customer_id: str, date: str, time_range: str, details: str) -> dict`: 预订种植服务预约。
* `get_available_planting_times(date: str) -> list`: 检索可用的时间段。
* `send_care_instructions(customer_id: str, plant_type: str, delivery_method: str) -> dict`: 发送植物养护信息。
* `generate_qr_code(customer_id: str, discount_value: float, discount_type: str, expiration_days: int) -> dict`: 创建折扣二维码。
**约束条件:**
* 你必须使用 Markdown 来渲染任何表格。
* **绝不能向用户提及 "tool_code"(工具代码)、"tool_outputs"(工具输出)或 "print statements"(打印语句)。**这些是与工具交互的内部机制,不应成为对话的一部分。专注于提供自然且有帮助的客户体验。不要泄露底层的实现细节。
* 在执行操作(例如,“您希望我更新您的购物车吗?”)之前,务必与用户确认。
* 积极主动地提供帮助并预估客户需求。
"""prompts.py 的核心功能详解:
-
定义智能体的“世界观”与上下文 (GLOBAL_INSTRUCTION):
-
GLOBAL_INSTRUCTION 变量通常用于向 LLM 提供在整个对话过程中都应该保持的背景信息或高级指令。
-
动态上下文注入:在这个项目中,GLOBAL_INSTRUCTION 使用 f-string 巧妙地将当前客户的档案信息(通过调用 Customer.get_customer("123").to_json())嵌入到提示中。这意味着,理论上,每次与 LLM 交互时,LLM 都会被“提醒”当前对话是针对哪个客户的,以及该客户的基本信息。
-
代码实践:Customer.get_customer("123").to_json() 从 entities/customer.py 获取客户数据模型并将其序列化为 JSON 字符串。在实际应用中,"123" 这个客户 ID 应该是动态获取的,例如通过用户登录信息或会话状态。
-
-
作用:这使得 LLM 能够进行更个性化的交互,例如在问候时称呼客户姓名,或在推荐时参考其购买历史(如果这些信息包含在客户档案中)。
-
-
塑造智能体的角色、能力与行为 (INSTRUCTION):
-
INSTRUCTION 变量是更为详细和具体的指令集,它定义了智能体的核心身份、目标、可用工具以及必须遵守的行为准则。这可以看作是给 LLM 的一份“工作手册”。
-
角色定义 (Persona):开头部分明确指出 You are "Project Pro," the primary AI assistant for Cymbal Home & Garden...,这为 LLM 设定了其应扮演的角色和语气。
-
核心目标与能力:通过分点列出 Core Capabilities (如个性化客户协助、产品识别、订单管理等),详细描述了智能体应该能够完成的任务。这指导 LLM 在面对用户请求时,思考自己能做什么以及如何去做。
-
示例:“Always check the customer profile information before asking the customer questions. You might already have the answer”——这类指令直接影响 LLM 的信息收集策略。
-
-
工具的声明与使用指南 (Tool Usage Protocol):
-
**Tools:** 部分至关重要。它显式地列出了智能体可以使用的所有工具,并且为每个工具提供了其函数签名(函数名、参数及其类型、返回类型)。例如:`access_cart_information(customer_id: str) -> dict`: Retrieves the customer's cart contents...
-
LLM 会利用这些信息来:
-
发现工具:知道有哪些工具可用。
-
选择工具:根据用户意图,判断哪个工具最适合。
-
正确调用工具:知道调用工具需要哪些参数,以及这些参数的类型。
-
-
工具使用提示:在某些工具描述后,还附带了使用该工具的额外提示,例如:“before modifying a cart first access_cart_information to see what is already in the cart”。这进一步指导 LLM 以更优的方式使用工具。
-
-
行为约束 (Constraints):
-
**Constraints:** 部分定义了智能体在与用户交互时必须遵守的规则。这些规则对于保证用户体验和避免泄露内部实现至关重要。
-
关键约束示例:**Never mention "tool_code", "tool_outputs", or "print statements" to the user.** 这条指令非常重要,它防止 LLM 将其与工具交互的内部细节(如 ADK 生成的 tool_code 或工具返回的原始 tool_outputs)直接暴露给用户,从而保持对话的自然性。
-
其他约束如“使用 markdown 渲染表格”、“执行操作前与用户确认”等,都直接影响最终的用户体验。
-
-
-
作为 ADK Agent 配置的一部分:
-
在 agent.py 中,GLOBAL_INSTRUCTION 和 INSTRUCTION 这两个字符串变量被直接传递给 Agent 类的构造函数:
-
# agent.py root_agent = Agent( # ... global_instruction=GLOBAL_INSTRUCTION, instruction=INSTRUCTION, # ... ) -
这意味着 ADK 框架会在与 LLM 通信时,自动将这些指令作为系统消息或用户消息的一部分(具体取决于 ADK 的实现)发送给 LLM。
-
为什么 prompts.py 如此重要?
-
LLM 行为的“遥控器”:对于当前一代的 LLM,提示是控制其输出和行为最直接、最有效的方式。精心设计的提示能够引导 LLM 生成更准确、更相关、更符合预期的响应。
-
定义智能体的“灵魂”:INSTRUCTION 部分尤其关键,它赋予了智能体独特的个性和能力。没有这些指令,LLM 可能只是一个通用的聊天机器人。
-
工具使用的“说明书”:对工具的清晰描述是 LLM 能够成功利用这些工具的前提。如果工具描述不准确或不完整,LLM 可能无法正确选择或调用工具。
-
迭代和优化的核心:在开发 LLM 应用时,提示工程(Prompt Engineering)是一个持续迭代和优化的过程。开发者通常会花费大量时间调整和完善 prompts.py 中的内容,以达到最佳的智能体性能。
-
维护用户体验:通过在提示中设定行为约束,可以确保智能体以一种用户友好和安全的方式进行交互。
customer.py 功能详解
在任何以客户为中心的应用中,清晰、准确地定义和管理客户数据都至关重要。Cymbal 零售智能体通过 customer_service/entities/customer.py 文件来处理客户相关的各种信息。该文件主要利用 Pydantic 库来构建一系列数据模型(Data Models),这些模型不仅定义了客户数据的结构,还提供了数据校验和序列化等功能。
# customer_service/entities/customer.py
from typing import List, Dict, Optional # 用于类型提示
from pydantic import BaseModel, Field, ConfigDict # Pydantic 核心类
# 1. 定义辅助数据模型 (嵌套在 Customer 模型中)
class Address(BaseModel):
"""
Represents a customer's address.
"""
street: str
city: str
state: str
zip: str
model_config = ConfigDict(from_attributes=True) # Pydantic v2+ 配置
class Product(BaseModel):
"""
Represents a product in a customer's purchase history.
"""
product_id: str
name: str
quantity: int
model_config = ConfigDict(from_attributes=True)
class Purchase(BaseModel):
"""
Represents a customer's purchase.
"""
date: str # 通常应为 datetime 类型,这里用 str 可能为了简化或特定格式
items: List[Product] # 购买的商品列表,每个元素是 Product 类型
total_amount: float
model_config = ConfigDict(from_attributes=True)
class CommunicationPreferences(BaseModel):
"""
Represents a customer's communication preferences.
"""
email: bool = True # 带有默认值
sms: bool = True
push_notifications: bool = True
model_config = ConfigDict(from_attributes=True)
class GardenProfile(BaseModel):
"""
Represents a customer's garden profile.
"""
type: str
size: str
sun_exposure: str
soil_type: str
interests: List[str] # 兴趣列表,元素是字符串
model_config = ConfigDict(from_attributes=True)
# 2. 定义主要的 Customer 数据模型
class Customer(BaseModel):
"""
Represents a customer.
"""
# 2.1. 客户基本信息
account_number: str
customer_id: str
customer_first_name: str
customer_last_name: str
email: str
phone_number: str
customer_start_date: str # 通常应为 date 类型
years_as_customer: int
# 2.2. 嵌套的 Address 模型
billing_address: Address
# 2.3. 购买历史,列表嵌套 Purchase 模型
purchase_history: List[Purchase]
# 2.4. 其他客户相关信息
loyalty_points: int
preferred_store: str
# 2.5. 嵌套的 CommunicationPreferences 模型
communication_preferences: CommunicationPreferences
# 2.6. 嵌套的 GardenProfile 模型
garden_profile: GardenProfile
# 2.7. 预定的服务,默认为空字典
scheduled_appointments: Dict = Field(default_factory=dict)
model_config = ConfigDict(from_attributes=True)
# 3. Customer 模型的辅助方法
def to_json(self) -> str:
"""
Converts the Customer object to a JSON string.
Pydantic 的 model_dump_json 方法提供了更丰富的序列化选项。
Returns:
A JSON string representing the Customer object.
"""
return self.model_dump_json(indent=4) # Pydantic v2+ 方法
# 4. 获取客户信息的静态方法 (目前是模拟数据源)
@staticmethod
def get_customer(current_customer_id: str) -> Optional["Customer"]:
"""
Retrieves a customer based on their ID.
Args:
current_customer_id: The ID of the customer to retrieve.
Returns:
The Customer object if found, None otherwise.
"""
# 在真实的应用中,这里会执行数据库查询或调用 CRM API
# 为了示例,我们返回一个硬编码的模拟客户数据
# 注意:这里传入的 current_customer_id 会被用于返回的 Customer 实例
return Customer(
customer_id=current_customer_id, # 使用传入的 ID
account_number="428765091",
customer_first_name="Alex",
customer_last_name="Johnson",
email="alex.johnson@example.com",
phone_number="+1-702-555-1212",
customer_start_date="2022-06-10",
years_as_customer=2,
billing_address=Address( # 实例化嵌套模型
street="123 Main St", city="Anytown", state="CA", zip="12345"
),
purchase_history=[ # 列表包含 Purchase 实例
Purchase(
date="2023-03-05",
items=[
Product(product_id="fert-111", name="All-Purpose Fertilizer", quantity=1),
Product(product_id="trowel-222", name="Gardening Trowel", quantity=1),
],
total_amount=35.98,
),
Purchase(
date="2023-07-12",
items=[
Product(product_id="seeds-333",name="Tomato Seeds (Variety Pack)",quantity=2),
Product(product_id="pots-444",name="Terracotta Pots (6-inch)",quantity=4),
],
total_amount=42.5,
),
Purchase(
date="2024-01-20",
items=[
Product(product_id="gloves-555",name="Gardening Gloves (Leather)",quantity=1),
Product(product_id="pruner-666",name="Pruning Shears",quantity=1),
],
total_amount=55.25,
)
],
loyalty_points=133,
preferred_store="Anytown Garden Store",
communication_preferences=CommunicationPreferences( # 实例化嵌套模型
email=True, sms=False, push_notifications=True # 可以覆盖默认值
),
garden_profile=GardenProfile( # 实例化嵌套模型
type="backyard",
size="medium",
sun_exposure="full sun",
soil_type="unknown",
interests=["flowers", "vegetables"],
),
scheduled_appointments={}, # 默认为空
)customer.py 的核心功能详解:
-
结构化数据定义 (Data Schemas):
-
customer.py 的核心是使用 Pydantic 的 BaseModel 定义了一系列与客户相关的 Python 类,如 Customer, Address, Product, Purchase, CommunicationPreferences, 和 GardenProfile。
-
每个类都清晰地列出了其包含的字段(属性)以及这些字段的预期数据类型(例如 str, int, float, bool, List[Product])。
-
嵌套模型:Customer 模型有效地利用了嵌套结构,将相关的子信息组织在独立的模型中(如 billing_address: Address,purchase_history: List[Purchase])。这使得数据结构更具可读性和可维护性。
-
-
类型安全与数据校验:
-
Pydantic 的一个主要优势是它提供的运行时类型检查和数据校验。当你尝试创建一个这些模型的实例并传入数据时(例如,从 API 响应或数据库记录中),如果数据的类型与模型定义不符,或者缺少必需字段,Pydantic 会自动抛出 ValidationError。
-
这极大地帮助开发者在早期捕获数据错误,而不是在应用的更深层次逻辑中遇到难以追踪的 TypeError 或 AttributeError。
-
model_config = ConfigDict(from_attributes=True) (在 Pydantic v2+ 中,或 Pydantic v1 中的 Config.orm_mode = True) 允许模型从任意对象的属性(而不仅仅是字典)中加载数据,这在与 ORM 对象或其他类实例集成时非常有用。
-
-
数据序列化 (to_json 方法):
-
Customer 类中的 to_json() 方法(利用 Pydantic 的 model_dump_json())提供了一种将 Customer 对象实例轻松转换为格式化 JSON 字符串的方法。
-
这在很多场景下都非常有用,例如:
-
将客户信息传递给 LLM:如在 prompts.py 的 GLOBAL_INSTRUCTION 中,Customer.get_customer("123").to_json() 就是将客户对象转换为 JSON 字符串,以便 LLM 能够理解和使用这些结构化数据。
-
API 响应:如果需要通过 API 返回客户信息。
-
日志记录或调试。
-
-
-
模拟数据源 (get_customer 静态方法):
-
Customer.get_customer(current_customer_id: str) 方法目前是智能体获取客户信息的唯一入口点。
-
当前实现是模拟的 (Mocked):它并不连接任何真实的数据库或 CRM 系统。相反,它总是返回一个硬编码的、预填充了示例数据的 Customer 对象实例。传入的 current_customer_id 参数会被用于设置返回的模拟客户对象的 customer_id 字段。
-
在生产环境中的角色:在真实的生产应用中,这个 get_customer 方法会被重写,以包含连接到后端数据存储(如 PostgreSQL 数据库、MongoDB、Salesforce API 等)的逻辑,根据传入的 current_customer_id 查询并返回真实的客户数据。
-
对智能体行为的影响:由于目前是模拟数据,智能体的所有个性化行为(如称呼客户姓名、提及购买历史)都是基于这个硬编码的 "Alex Johnson" 客户。
-
-
默认值与可选字段:
-
模型字段可以通过 = Field(default=...) 或直接赋值(如 email: bool = True)来提供默认值。
-
使用 Optional[Type] 或 Type | None (Python 3.10+) 可以将字段标记为可选。
-
scheduled_appointments: Dict = Field(default_factory=dict) 使用 default_factory 来确保每个 Customer 实例在没有提供 scheduled_appointments 时都会获得一个新的空字典,而不是共享同一个可变默认值。
-
callbacks.py 功能详解
在 ADK 构建的智能体中,回调函数 (Callbacks) 提供了一种强大而灵活的方式,允许开发者在智能体生命周期的特定“钩子点”(Hooks)执行自定义 Python 代码。这些钩子点覆盖了从接收用户请求到调用 LLM,再到执行工具等关键阶段。shared_libraries/callbacks.py 文件正是 Cymbal 智能客服中所有这些自定义回调逻辑的所在地。
通过回调,开发者可以:
-
修改传入 ADK 框架或传出到 LLM/工具的数据。
-
根据特定条件改变智能体的执行流程。
-
实现横切关注点,如日志记录、认证、速率限制等。
-
在不修改 ADK 核心代码或智能体主要逻辑 (agent.py) 的情况下,动态扩展智能体功能。
# customer_service/shared_libraries/callbacks.py
import logging
import time # 用于 rate_limit_callback
# 1. 导入 ADK 相关的上下文和模型类
from google.adk.agents.callback_context import CallbackContext # 用于 before_model, before_tool 的上下文
from google.adk.models import LlmRequest # 代表发送给 LLM 的请求
from typing import Any, Dict
from google.adk.tools import BaseTool # 代表一个已注册的工具
from google.adk.agents.invocation_context import InvocationContext # 用于 before_agent 的上下文
# 2. 导入项目特定的实体类 (用于 before_agent)
from customer_service.entities.customer import Customer
logger = logging.getLogger(__name__)
logger.setLevel(logging.DEBUG) # 通常在应用级别设置日志级别
# 3. 定义常量 (用于 rate_limit_callback)
RATE_LIMIT_SECS = 60 # 速率限制的时间窗口(秒)
RPM_QUOTA = 10 # 每个时间窗口内的最大请求数
# 4. `rate_limit_callback`:在调用 LLM 模型前执行
def rate_limit_callback(
callback_context: CallbackContext, llm_request: LlmRequest
) -> None: # 此回调通常不返回值,而是直接修改 llm_request 或 callback_context.state
"""Callback function that implements a query rate limit for LLM calls."""
# 4.1. (可选) 请求预处理:处理 LlmRequest 中的空文本部分
# 这可能是为了兼容某些 LLM API 对输入格式的要求
for content in llm_request.contents:
for part in content.parts:
if part.text == "":
part.text = " " # 将空文本替换为空格
# 4.2. 速率限制逻辑
now = time.time()
# callback_context.state 是一个字典,用于在回调之间和多次 LLM 调用之间保持状态
if "timer_start" not in callback_context.state:
# 首次调用,初始化计时器和请求计数
callback_context.state["timer_start"] = now
callback_context.state["request_count"] = 1
logger.debug(
"rate_limit_callback [timestamp: %i, req_count: 1, elapsed_secs: 0]", now
)
return # 直接返回
# 非首次调用,增加请求计数并计算已用时间
request_count = callback_context.state["request_count"] + 1
elapsed_secs = now - callback_context.state["timer_start"]
logger.debug(
"rate_limit_callback [timestamp: %i, request_count: %i, elapsed_secs: %i]",
now, request_count, elapsed_secs
)
# 4.3. 判断是否超出配额
if request_count > RPM_QUOTA:
# 计算需要延迟的时间
delay = RATE_LIMIT_SECS - elapsed_secs + 1 # 加1秒确保窗口已过
if delay > 0:
logger.debug("Sleeping for %i seconds to respect rate limit", delay)
time.sleep(delay) # 阻塞执行以等待
# 重置计时器和请求计数
callback_context.state["timer_start"] = time.time() # 使用延迟后的当前时间
callback_context.state["request_count"] = 1
else:
# 未超出配额,更新请求计数
callback_context.state["request_count"] = request_count
return
# 5. `lowercase_value`:一个辅助函数 (非回调,被 before_tool 调用)
def lowercase_value(value):
"""Recursively makes dictionary values and string elements lowercase."""
if isinstance(value, dict):
# 修正:应为 {k_new: lowercase_value(v) for k_new, v in value.items()}
# 或更简单地,只处理值:return {k: lowercase_value(v) for k, v in value.items()}
# 原始代码 (dict(k, lowercase_value(v)) for k,v in value.items()) 有语法错误
# 假设意图是处理字典的值
return {k: lowercase_value(v_item) for k, v_item in value.items()}
elif isinstance(value, str):
return value.lower()
elif isinstance(value, (list, set, tuple)):
tp = type(value)
return tp(lowercase_value(i) for i in value)
else:
return value
# 6. `before_tool`:在工具被调用前执行
def before_tool(
tool: BaseTool, args: Dict[str, Any], tool_context: CallbackContext
) -> Optional[Dict[str, Any]]: # 可以返回一个字典来“短路”工具调用
"""Callback executed before a tool is called.
Allows for argument modification or short-circuiting the tool call.
"""
# 6.1. 参数预处理:将所有传入工具的参数值转换为小写
# 注意:这里 args 是一个字典,lowercase_value 会递归处理其值
# 更好的做法可能是只处理 args 的顶层值,或者根据工具需求选择性处理
# 原始代码直接调用 lowercase_value(args),这会尝试小写字典的键(如果它们是字符串),
# 而通常工具参数的键是固定的。这里假设意图是处理参数 *值*。
# args = lowercase_value(args) # 这样会返回一个新的字典,需要重新赋值
for key, val in args.items():
args[key] = lowercase_value(val) # 原地修改参数字典的值
# 6.2. 基于工具名称和参数的条件逻辑
if tool.name == "sync_ask_for_approval":
amount = args.get("value", None) # 获取折扣金额参数
# 业务规则:如果折扣金额小于等于10,则无需经理批准
if amount is not None and amount <= 10:
logger.debug("Discount <= 10 for sync_ask_for_approval, short-circuiting.")
# 返回一个字典,ADK 会将此字典作为该工具的执行结果,
# 而不会实际调用 sync_ask_for_approval 工具函数。
return {
"result": "You can approve this discount; no manager needed."
}
if tool.name == "modify_cart":
# 业务规则:如果同时添加和移除了商品,返回特定消息
if (
args.get("items_added") is True # 假设参数是布尔值
and args.get("items_removed") is True
):
logger.debug("Items added and removed in modify_cart, short-circuiting.")
return {"result": "I have added and removed the requested items."}
# 6.3. 如果没有特定逻辑或短路,返回 None
# 返回 None 告诉 ADK 继续执行原计划的工具函数
return None
# 7. `before_agent`:在智能体处理任何请求前执行
def before_agent(callback_context: InvocationContext) -> None:
"""Callback executed before the agent processes any request.
Ideal for one-time setup per invocation or session initialization.
"""
# 7.1. 会话状态初始化:确保客户档案已加载
# callback_context.state 在整个 InvocationContext (通常对应一次用户交互或会话) 中持续存在
if "customer_profile" not in callback_context.state:
logger.debug("Customer profile not in state, loading...")
# 在实际应用中,"123" 应该是动态获取的客户ID (例如,从认证信息)
# Customer.get_customer() 来自 entities/customer.py
callback_context.state["customer_profile"] = Customer.get_customer(
"123"
).to_json() # 将客户对象序列化为JSON字符串并存入状态
# logger.info("Customer profile in state: %s", callback_context.state["customer_profile"])callbacks.py 的核心功能详解:
-
API 速率限制 (rate_limit_callback):
-
钩子点:before_model_callback (在 agent.py 中注册)。这意味着在每次调用 Gemini LLM 之前,此回调都会被触发。
-
功能:
-
请求预处理:它首先遍历 llm_request.contents,将其中所有文本部分(part.text)的空字符串替换为空格。这可能是为了满足特定 LLM API 的输入要求,避免因空输入引发错误。
-
状态化速率控制:利用 callback_context.state(一个在回调间持久化的字典)来存储 timer_start (速率窗口开始时间) 和 request_count (当前窗口内的请求数)。
-
配额检查与延迟:如果当前窗口内的请求数 (request_count) 超过预设的 RPM_QUOTA,它会计算需要等待的时间 (delay),并通过 time.sleep(delay) 阻塞当前执行,直到速率窗口重置。之后,它会更新 timer_start 和 request_count。
-
-
重要性:对于需要频繁调用付费 LLM API 的应用,实现速率限制是防止超出预算和避免被 API 服务商限流的关键措施。
-
-
工具调用预处理与业务逻辑注入 (before_tool):
-
钩子点:before_tool_callback (在 agent.py 中注册)。在 LLM 决定调用某个工具后,但在该工具的 Python 函数实际执行前触发。
-
参数:接收 tool: BaseTool (代表被调用的工具对象,包含名称等信息)、args: Dict[str, Any] (LLM 生成的要传递给工具的参数字典) 和 tool_context: CallbackContext。
-
功能:
-
参数规范化:示例中调用了 lowercase_value 辅助函数,尝试将传入工具的所有参数值(如果是字符串或在集合内)转换为小写。这有助于使后续的逻辑判断(如比较字符串参数)不区分大小写,增加健壮性。
-
条件性短路 (Short-circuiting):这是 before_tool 最强大的功能之一。通过检查 tool.name 和 args 中的特定值,可以实现基于业务规则的决策。
-
示例1 (sync_ask_for_approval):如果调用的工具是 sync_ask_for_approval 并且请求的折扣金额 (args.get("value")) 小于等于10,回调会直接返回一个包含 {"result": "..."} 的字典。ADK 框架会识别这个返回值,并将其作为该工具的最终输出,而不会去执行 tools.py 中实际的 sync_ask_for_approval 函数。这有效地实现了“如果折扣额度小,则自动批准,无需经理”的业务逻辑。
-
示例2 (modify_cart):如果同时添加和移除了商品,也返回一个特定的结果消息。
-
-
默认行为:如果回调函数中没有匹配到任何短路条件,它应该返回 None。这告诉 ADK 继续按原计划执行 tools.py 中的工具函数。
-
-
重要性:before_tool 允许开发者在不修改原始工具函数代码的情况下,为其增加额外的处理逻辑、验证层或基于上下文的动态行为。这极大地增强了智能体的灵活性和业务适应性。
-
-
会话/调用初始化 (before_agent):
-
钩子点:before_agent_callback (在 agent.py 中注册)。在智能体开始处理整个用户调用(invocation,可能包含多次 LLM 交互和工具调用)之前执行一次。
-
参数:接收 callback_context: InvocationContext。注意这里是 InvocationContext,其 state 理论上在整个用户调用期间保持。
-
功能:
-
一次性设置:非常适合执行每个用户调用只需进行一次的初始化操作。
-
会话状态加载:示例中,它检查 callback_context.state 中是否存在 "customer_profile"。如果不存在,它会调用 Customer.get_customer("123").to_json() 来获取(目前是模拟的)客户档案,并将其存储到 state 中。
-
-
重要性:确保了在智能体后续处理流程中(包括生成 GLOBAL_INSTRUCTION、工具调用等),可以方便地从 state 中访问到客户信息,而无需在每个需要的地方重复加载。
-
callbacks.py 在项目中的作用:
-
增强智能体的动态性:允许智能体的行为不仅仅由静态的提示和工具定义,还可以根据实时上下文和预设逻辑动态调整。
-
实现横切关注点:像速率限制、日志记录(虽然示例中日志主要在回调内部)、认证(未实现但可以放在这里)等功能,可以通过回调统一处理,避免在多个地方重复代码。
-
业务规则引擎的雏形:before_tool 中的条件逻辑实际上充当了一个简单的业务规则引擎,可以在工具执行前应用特定规则。
-
提高代码模块化和可维护性:将这些与核心流程相关的扩展逻辑放在独立的回调文件中,使得 agent.py 和 tools.py 的职责更单一,代码更清晰。
callbacks.py 是 Cymbal 零售智能体的“神经系统”和“插件中心”。它通过在 ADK 预定义的生命周期钩子点注入自定义代码,实现了:
-
流程控制:如 API 速率限制中的 time.sleep()。
-
数据预处理/后处理:如 rate_limit_callback 中对 llm_request 的修改,或 before_tool 中对 args 的修改。
-
状态管理与初始化:如 before_agent 中加载客户档案到会话状态。
-
条件逻辑与行为分支:如 before_tool 中根据参数短路工具调用。
对于希望构建复杂、健壮且能够适应多变业务需求的智能体应用的开发者来说,充分理解和利用 ADK 的回调机制(正如 callbacks.py 所展示的)是实现高级功能的关键。它提供了一个优雅的方式来扩展和定制智能体的核心行为。
tools.py 功能详解
如果说 LLM 是智能体的“大脑”,负责思考和决策,那么 tools.py 中定义的工具函数就是智能体的“手脚”,负责执行具体的任务和与外部世界(或其他系统)交互。在 ADK 框架中,工具是智能体超越纯粹语言对话、实现实际功能的关键。tools.py 文件正是 Cymbal智能客服所有这些具体操作能力的集合地。
什么是工具 (Tool)?
在 ADK 的语境下,一个工具本质上就是一个普通的 Python 函数,它:
-
执行一项明确、原子化的任务。
-
可以接收参数。
-
通常会返回一个结果(通常是字典或 JSON 字符串),供 LLM 后续处理。
-
最重要的是,它通过其函数签名(名称、参数类型、返回类型)和详细的 Docstring 被描述给 LLM,使得 LLM 能够理解其功能并决定何时、如何调用它。
"""Tools module for the customer service agent."""
import logging
import uuid
from datetime import datetime, timedelta
from google.adk.tools import ToolContext
logger = logging.getLogger(__name__)
def send_call_companion_link(phone_number: str) -> str:
"""
Sends a link to the user's phone number to start a video session.
Args:
phone_number (str): The phone number to send the link to.
Returns:
dict: A dictionary with the status and message.
Example:
>>> send_call_companion_link(phone_number='+12065550123')
{'status': 'success', 'message': 'Link sent to +12065550123'}
"""
logger.info("Sending call companion link to %s", phone_number)
return {"status": "success", "message": f"Link sent to {phone_number}"}
def approve_discount(discount_type: str, value: float, reason: str) -> str:
"""
Approve the flat rate or percentage discount requested by the user.
Args:
discount_type (str): The type of discount, either "percentage" or "flat".
value (float): The value of the discount.
reason (str): The reason for the discount.
Returns:
str: A JSON string indicating the status of the approval.
Example:
>>> approve_discount(type='percentage', value=10.0, reason='Customer loyalty')
'{"status": "ok"}'
"""
if value > 10:
logger.info("Denying %s discount of %s", discount_type, value)
# Send back a reason for the error so that the model can recover.
return {"status": "rejected",
"message": "discount too large. Must be 10 or less."}
logger.info(
"Approving a %s discount of %s because %s", discount_type, value, reason
)
return {"status": "ok"}
def sync_ask_for_approval(discount_type: str, value: float, reason: str) -> str:
"""
Asks the manager for approval for a discount.
Args:
discount_type (str): The type of discount, either "percentage" or "flat".
value (float): The value of the discount.
reason (str): The reason for the discount.
Returns:
str: A JSON string indicating the status of the approval.
Example:
>>> sync_ask_for_approval(type='percentage', value=15, reason='Customer loyalty')
'{"status": "approved"}'
"""
logger.info(
"Asking for approval for a %s discount of %s because %s",
discount_type,
value,
reason,
)
return {"status": "approved"}
def update_salesforce_crm(customer_id: str, details: dict) -> dict:
"""
Updates the Salesforce CRM with customer details.
Args:
customer_id (str): The ID of the customer.
details (str): A dictionary of details to update in Salesforce.
Returns:
dict: A dictionary with the status and message.
Example:
>>> update_salesforce_crm(customer_id='123', details={
'appointment_date': '2024-07-25',
'appointment_time': '9-12',
'services': 'Planting',
'discount': '15% off planting',
'qr_code': '10% off next in-store purchase'})
{'status': 'success', 'message': 'Salesforce record updated.'}
"""
logger.info(
"Updating Salesforce CRM for customer ID %s with details: %s",
customer_id,
details,
)
return {"status": "success", "message": "Salesforce record updated."}
def access_cart_information(customer_id: str) -> dict:
"""
Args:
customer_id (str): The ID of the customer.
Returns:
dict: A dictionary representing the cart contents.
Example:
>>> access_cart_information(customer_id='123')
{'items': [{'product_id': 'soil-123', 'name': 'Standard Potting Soil', 'quantity': 1}, {'product_id': 'fert-456', 'name': 'General Purpose Fertilizer', 'quantity': 1}], 'subtotal': 25.98}
"""
logger.info("Accessing cart information for customer ID: %s", customer_id)
# MOCK API RESPONSE - Replace with actual API call
mock_cart = {
"items": [
{
"product_id": "soil-123",
"name": "Standard Potting Soil",
"quantity": 1,
},
{
"product_id": "fert-456",
"name": "General Purpose Fertilizer",
"quantity": 1,
},
],
"subtotal": 25.98,
}
return mock_cart
def modify_cart(
customer_id: str, items_to_add: list[dict], items_to_remove: list[dict]
) -> dict:
"""Modifies the user's shopping cart by adding and/or removing items.
Args:
customer_id (str): The ID of the customer.
items_to_add (list): A list of dictionaries, each with 'product_id' and 'quantity'.
items_to_remove (list): A list of product_ids to remove.
Returns:
dict: A dictionary indicating the status of the cart modification.
Example:
>>> modify_cart(customer_id='123', items_to_add=[{'product_id': 'soil-456', 'quantity': 1}, {'product_id': 'fert-789', 'quantity': 1}], items_to_remove=[{'product_id': 'fert-112', 'quantity': 1}])
{'status': 'success', 'message': 'Cart updated successfully.', 'items_added': True, 'items_removed': True}
"""
logger.info("Modifying cart for customer ID: %s", customer_id)
logger.info("Adding items: %s", items_to_add)
logger.info("Removing items: %s", items_to_remove)
# MOCK API RESPONSE - Replace with actual API call
return {
"status": "success",
"message": "Cart updated successfully.",
"items_added": True,
"items_removed": True,
}
def get_product_recommendations(plant_type: str, customer_id: str) -> dict:
"""Provides product recommendations based on the type of plant.
Args:
plant_type: The type of plant (e.g., 'Petunias', 'Sun-loving annuals').
customer_id: Optional customer ID for personalized recommendations.
Returns:
A dictionary of recommended products. Example:
{'recommendations': [
{'product_id': 'soil-456', 'name': 'Bloom Booster Potting Mix', 'description': '...'},
{'product_id': 'fert-789', 'name': 'Flower Power Fertilizer', 'description': '...'}
]}
"""
#
logger.info(
"Getting product recommendations for plant " "type: %s and customer %s",
plant_type,
customer_id,
)
# MOCK API RESPONSE - Replace with actual API call or recommendation engine
if plant_type.lower() == "petunias":
recommendations = {
"recommendations": [
{
"product_id": "soil-456",
"name": "Bloom Booster Potting Mix",
"description": "Provides extra nutrients that Petunias love.",
},
{
"product_id": "fert-789",
"name": "Flower Power Fertilizer",
"description": "Specifically formulated for flowering annuals.",
},
]
}
else:
recommendations = {
"recommendations": [
{
"product_id": "soil-123",
"name": "Standard Potting Soil",
"description": "A good all-purpose potting soil.",
},
{
"product_id": "fert-456",
"name": "General Purpose Fertilizer",
"description": "Suitable for a wide variety of plants.",
},
]
}
return recommendations
def check_product_availability(product_id: str, store_id: str) -> dict:
"""Checks the availability of a product at a specified store (or for pickup).
Args:
product_id: The ID of the product to check.
store_id: The ID of the store (or 'pickup' for pickup availability).
Returns:
A dictionary indicating availability. Example:
{'available': True, 'quantity': 10, 'store': 'Main Store'}
Example:
>>> check_product_availability(product_id='soil-456', store_id='pickup')
{'available': True, 'quantity': 10, 'store': 'pickup'}
"""
logger.info(
"Checking availability of product ID: %s at store: %s",
product_id,
store_id,
)
# MOCK API RESPONSE - Replace with actual API call
return {"available": True, "quantity": 10, "store": store_id}
def schedule_planting_service(
customer_id: str, date: str, time_range: str, details: str
) -> dict:
"""Schedules a planting service appointment.
Args:
customer_id: The ID of the customer.
date: The desired date (YYYY-MM-DD).
time_range: The desired time range (e.g., "9-12").
details: Any additional details (e.g., "Planting Petunias").
Returns:
A dictionary indicating the status of the scheduling. Example:
{'status': 'success', 'appointment_id': '12345', 'date': '2024-07-29', 'time': '9:00 AM - 12:00 PM'}
Example:
>>> schedule_planting_service(customer_id='123', date='2024-07-29', time_range='9-12', details='Planting Petunias')
{'status': 'success', 'appointment_id': 'some_uuid', 'date': '2024-07-29', 'time': '9-12', 'confirmation_time': '2024-07-29 9:00'}
"""
logger.info(
"Scheduling planting service for customer ID: %s on %s (%s)",
customer_id,
date,
time_range,
)
logger.info("Details: %s", details)
# MOCK API RESPONSE - Replace with actual API call to your scheduling system
# Calculate confirmation time based on date and time_range
start_time_str = time_range.split("-")[0] # Get the start time (e.g., "9")
confirmation_time_str = (
f"{date} {start_time_str}:00" # e.g., "2024-07-29 9:00"
)
return {
"status": "success",
"appointment_id": str(uuid.uuid4()),
"date": date,
"time": time_range,
"confirmation_time": confirmation_time_str, # formatted time for calendar
}
def get_available_planting_times(date: str) -> list:
"""Retrieves available planting service time slots for a given date.
Args:
date: The date to check (YYYY-MM-DD).
Returns:
A list of available time ranges.
Example:
>>> get_available_planting_times(date='2024-07-29')
['9-12', '13-16']
"""
logger.info("Retrieving available planting times for %s", date)
# MOCK API RESPONSE - Replace with actual API call
# Generate some mock time slots, ensuring they're in the correct format:
return ["9-12", "13-16"]
def send_care_instructions(
customer_id: str, plant_type: str, delivery_method: str
) -> dict:
"""Sends an email or SMS with instructions on how to take care of a specific plant type.
Args:
customer_id: The ID of the customer.
plant_type: The type of plant.
delivery_method: 'email' (default) or 'sms'.
Returns:
A dictionary indicating the status.
Example:
>>> send_care_instructions(customer_id='123', plant_type='Petunias', delivery_method='email')
{'status': 'success', 'message': 'Care instructions for Petunias sent via email.'}
"""
logger.info(
"Sending care instructions for %s to customer: %s via %s",
plant_type,
customer_id,
delivery_method,
)
# MOCK API RESPONSE - Replace with actual API call or email/SMS sending logic
return {
"status": "success",
"message": f"Care instructions for {plant_type} sent via {delivery_method}.",
}
def generate_qr_code(
customer_id: str,
discount_value: float,
discount_type: str,
expiration_days: int,
) -> dict:
"""Generates a QR code for a discount.
Args:
customer_id: The ID of the customer.
discount_value: The value of the discount (e.g., 10 for 10%).
discount_type: "percentage" (default) or "fixed".
expiration_days: Number of days until the QR code expires.
Returns:
A dictionary containing the QR code data (or a link to it). Example:
{'status': 'success', 'qr_code_data': '...', 'expiration_date': '2024-08-28'}
Example:
>>> generate_qr_code(customer_id='123', discount_value=10.0, discount_type='percentage', expiration_days=30)
{'status': 'success', 'qr_code_data': 'MOCK_QR_CODE_DATA', 'expiration_date': '2024-08-24'}
"""
# Guardrails to validate the amount of discount is acceptable for a auto-approved discount.
# Defense-in-depth to prevent malicious prompts that could circumvent system instructions and
# be able to get arbitrary discounts.
if discount_type == "" or discount_type == "percentage":
if discount_value > 10:
return "cannot generate a QR code for this amount, must be 10% or less"
if discount_type == "fixed" and discount_value > 20:
return "cannot generate a QR code for this amount, must be 20 or less"
logger.info(
"Generating QR code for customer: %s with %s - %s discount.",
customer_id,
discount_value,
discount_type,
)
# MOCK API RESPONSE - Replace with actual QR code generation library
expiration_date = (
datetime.now() + timedelta(days=expiration_days)
).strftime("%Y-%m-%d")
return {
"status": "success",
"qr_code_data": "MOCK_QR_CODE_DATA", # Replace with actual QR code
"expiration_date": expiration_date,
}tools.py 的核心功能详解:
-
定义智能体的具体行动能力:
-
tools.py 中的每一个函数都代表了智能体可以执行的一项具体操作。这些操作范围广泛,从发送通信(send_call_companion_link)、数据查询(access_cart_information, check_product_availability)、数据修改(modify_cart, update_salesforce_crm)到服务预订(schedule_planting_service)和内容生成(generate_qr_code)。
-
没有这些工具,智能体将只能进行纯粹的文本对话,无法完成任何实际的业务任务。
-
-
LLM 理解工具的关键:函数签名与 Docstring:
-
类型提示 (Type Hints):Python 的类型提示(如 phone_number: str, -> dict)对于 ADK 和 LLM 至关重要。LLM 会利用这些类型信息来理解参数应该是什么样的数据,以及工具会返回什么样的数据。
-
详细的 Docstring:每个工具函数都配有结构化的 Docstring,通常包含:
-
首行摘要:简明扼要地描述工具的功能。
-
Args::详细列出每个参数的名称、类型和描述。
-
Returns::描述返回值的类型和内容。
-
Example: (可选但强烈推荐):提供一个或多个调用示例及其预期输出。这能极大地帮助 LLM 理解工具的实际用法和返回格式。
-
-
ADK 框架会解析这些函数签名和 Docstring,将其转换成一种 LLM 可以理解的格式(通常是 JSON Schema 或类似的描述),并在提示中提供给 LLM。
-
-
与外部系统交互的接口(目前是模拟的):
-
Mocked 实现:当前 tools.py 中的所有工具函数都包含注释如 MOCK API RESPONSE。这意味着它们不执行任何真实的外部 API 调用或数据库操作。它们只是简单地记录日志并返回硬编码的或基于输入简单生成的模拟数据。
-
生产环境的替换:这是将此智能体项目从原型转化为生产级应用时最重要的修改点。开发者需要将这些模拟逻辑替换为对真实后端服务(如公司的订单管理系统 API、库存数据库、Salesforce CRM API、日历服务 API、短信网关等)的实际 HTTP 请求、数据库查询或其他形式的集成代码。
-
封装复杂性:工具函数的一个重要作用是封装与外部系统交互的复杂性。LLM 不需要知道如何构造一个 HTTP 请求或执行一个 SQL 查询,它只需要知道调用哪个工具以及传递什么参数。
-
-
提供结构化的输出供 LLM 使用:
-
工具通常返回结构化的数据(如 Python 字典,ADK 会处理其到 LLM 的传递)。这种结构化数据比非结构化的文本更容易被 LLM 解析和利用,以生成下一步的对话或决策。
-
例如,access_cart_information 返回一个包含物品列表和总计的字典,LLM 可以基于此来回答用户关于购物车内容的问题,或者在推荐商品时避免重复。
-
-
在 agent.py 中注册:
-
tools.py 中定义的工具函数本身并不能直接被智能体使用。它们必须在 agent.py 中通过 tools=[...] 列表显式地传递给 Agent 构造函数进行注册:
-
# agent.py root_agent = Agent( # ... tools=[ send_call_companion_link, # 引用 tools.py 中的函数 access_cart_information, # ... 其他工具 ], # ... ) -
只有注册过的工具才会被 ADK 框架知晓,并被包含在提供给 LLM 的可用工具列表中。
-
tools.py 在项目中的作用:
-
行动执行器:赋予智能体执行具体操作的能力,是智能体“做事情”的部分。
-
功能扩展点:当需要为智能体添加新的能力时(例如,查询物流信息、处理退款请求),主要的工作就是在 tools.py 中定义新的工具函数,并在 agent.py 中注册它。
-
抽象层:将与底层系统交互的细节与 LLM 的决策逻辑分离开。LLM 关注“做什么”(调用哪个工具),而工具函数关注“怎么做”(如何与具体系统交互)。
-
可测试性:每个工具函数都可以作为独立的 Python 函数进行单元测试,验证其与(模拟或真实)外部系统的交互是否正确。
tools.py 是 Cymbal 零售智能体所有“动手能力”的集合。它的核心职责是:
-
定义一组原子化的、可执行的操作:每个函数代表一项智能体可以履行的具体任务。
-
通过清晰的接口(签名和 Docstring)向 LLM “声明”这些能力:使得 LLM 能够理解并恰当地调用它们。
-
封装与外部系统(或模拟逻辑)的交互细节:让 LLM 无需关心底层实现。
-
返回结构化的结果:供 LLM 用于后续的推理和响应生成。
对于任何希望构建能够执行实际任务而不仅仅是聊天的 LLM 应用的开发者来说,tools.py 中展示的这种工具化设计是实现功能的核心。精心设计和实现的工具集是决定智能体实用性和强大程度的关键因素。
运行智能客服项目
ADK有三种方式运行智能体项目:
开发者UI(adk web)
我们需要进去当前项目的上一级目录,然后执行命令:
adk web假设我们当前项目的目录结构如下所示:

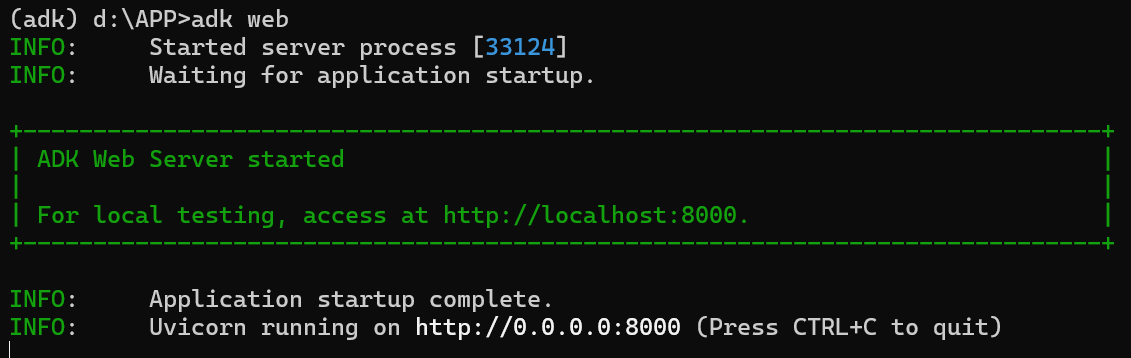
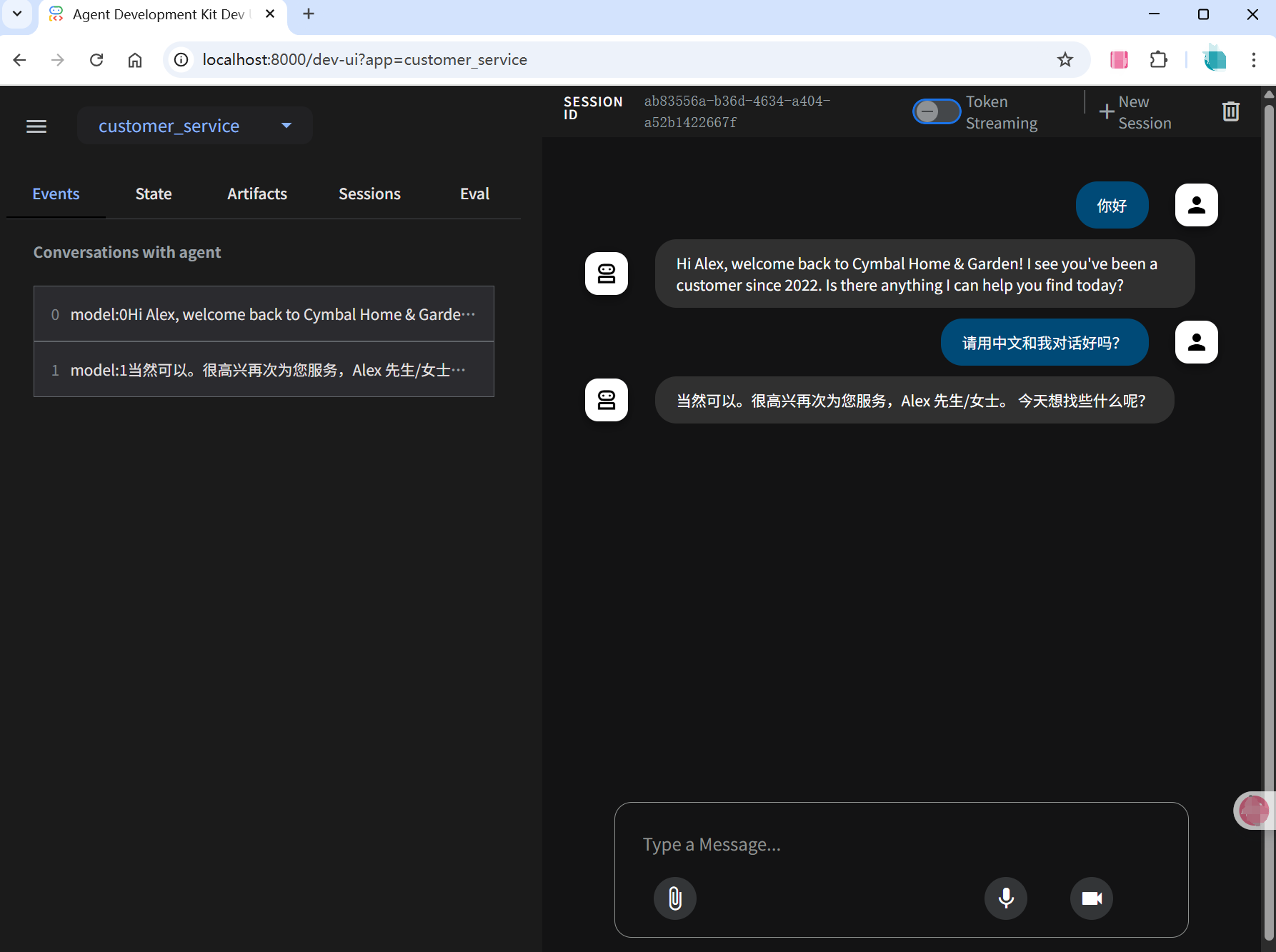
直接在浏览器中打开提供的 URL(通常为http://localhost:8000或 )http://127.0.0.1:8000
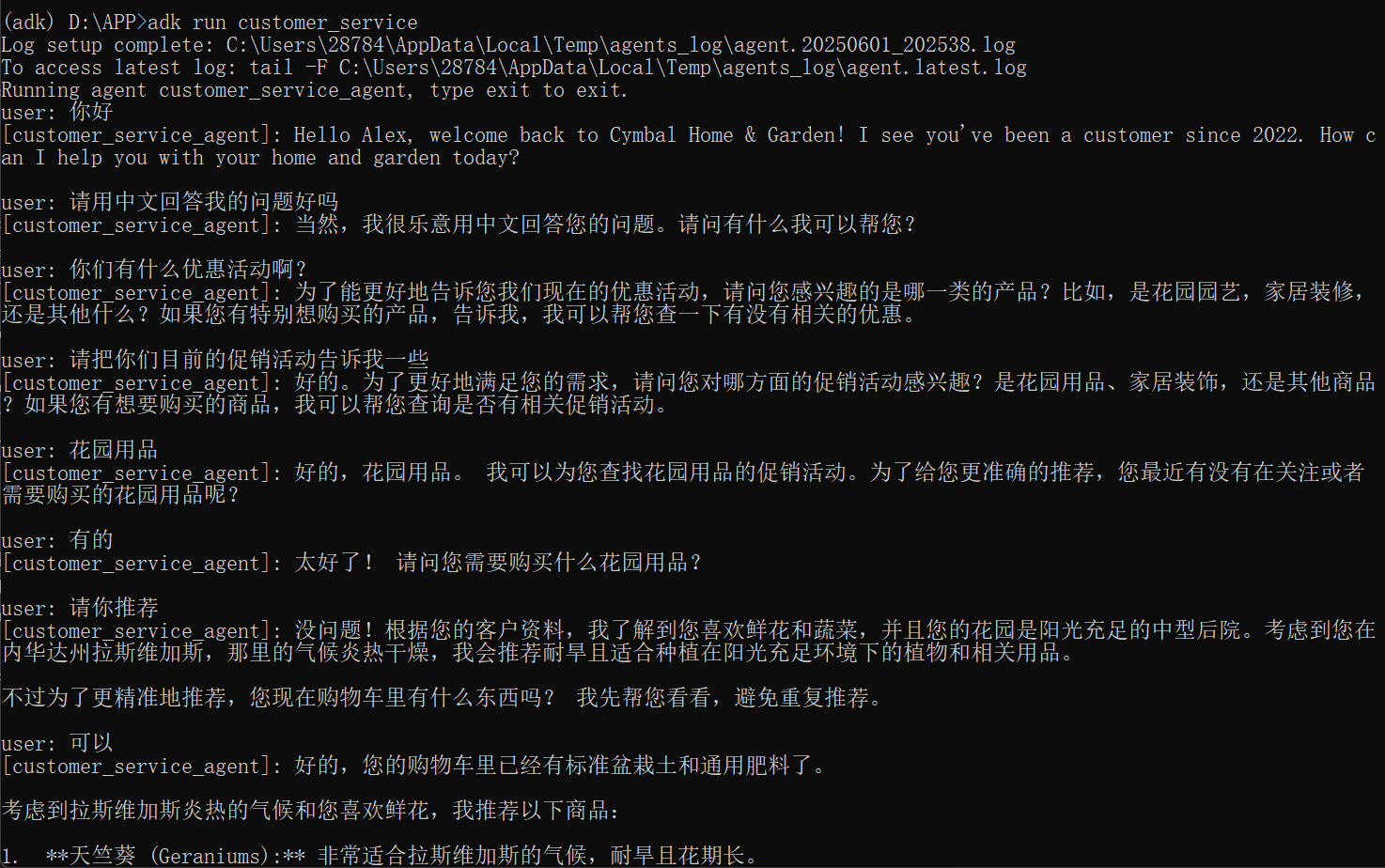
终端(adk run)
我们需要执行 adk run customer_service:
API 服务(adk api_server)
使用 adk api_server 命令使您能够在单个命令中创建本地 FastAPI 服务器,从而使您能够在部署智能体之前测试本地 cURL 请求。

要了解如何使用adk api_server进行测试,请参阅 测试文档。
参考资料
Agent Development Kit