SPA-RL:通过Stepwise Progress Attribution训练LLM智能体
在大语言模型(LLM)驱动智能体发展的浪潮中,强化学习(RL)面临着延迟奖励这一关键挑战。本文提出的SPA-RL框架,通过创新的分步进度归因机制,将最终奖励分解为细粒度的中间信号,为LLM智能体训练带来了突破性进展,在多个基准任务上刷新了性能上限,一起来探索这一前沿成果!
论文标题
SPA-RL: Reinforcing LLM Agents via Stepwise Progress Attribution
来源
arXiv:2505.20732v1 [cs.CL] + https://arxiv.org/abs/2505.20732
PS: 整理了LLM、量化投资、机器学习方向的学习资料,关注同名公众号 「 亚里随笔」 即刻免费解锁
文章核心
研究背景
大语言模型(LLM)作为智能体在网页导航、具身交互等多步规划任务中展现出强大能力,强化学习(RL)因序贯决策优化特性成为训练关键技术。然而,这类任务普遍存在延迟奖励问题:仅任务完成时提供最终反馈,导致早期动作难以获得有效指导。
现有过程监督方法(如 StepAgent、PRM4A)虽尝试引入中间信号,但多局限于局部动作优化,忽视与长期目标的一致性;传统 PPO 算法在长周期任务中,因优势函数指数衰减导致梯度无法有效传播,进一步加剧了训练困境。如何为 LLM 智能体设计兼具全局目标对齐与细粒度指导的中间奖励信号,成为突破 RL 训练瓶颈的核心挑战。
研究问题
1. 延迟奖励分配难题: 传统RL中仅任务完成时获得最终奖励,难以将反馈有效传递给早期步骤,导致智能体无法明确各动作对目标的贡献。
2. 局部优化局限性: 现有过程监督方法(如StepAgent、PRM4A)多关注局部动作优化,忽视与长期目标的一致性,易陷入次优解。
3. PPO算法在长周期任务中的失效: 稀疏奖励下PPO的优势函数因指数衰减无法有效传播梯度,尤其在超过20步的长轨迹中性能急剧下降。
主要贡献
1. 提出SPA框架: 首创分步进度归因(Stepwise Progress Attribution, SPA)机制,将最终奖励分解为各步骤的进度贡献,通过进度估计器实现奖励再分配,确保中间信号与全局目标一致。
2. 融合进度与执行信号: 设计融合奖励函数 r t f u s e d = α c t + β g t r_t^{fused} = \alpha c_t + \beta g_t rtfused=αct+βgt,其中 c t c_t ct为步骤贡献分数, g t g_t gt为动作可执行性信号,兼顾任务进度与环境适配性。
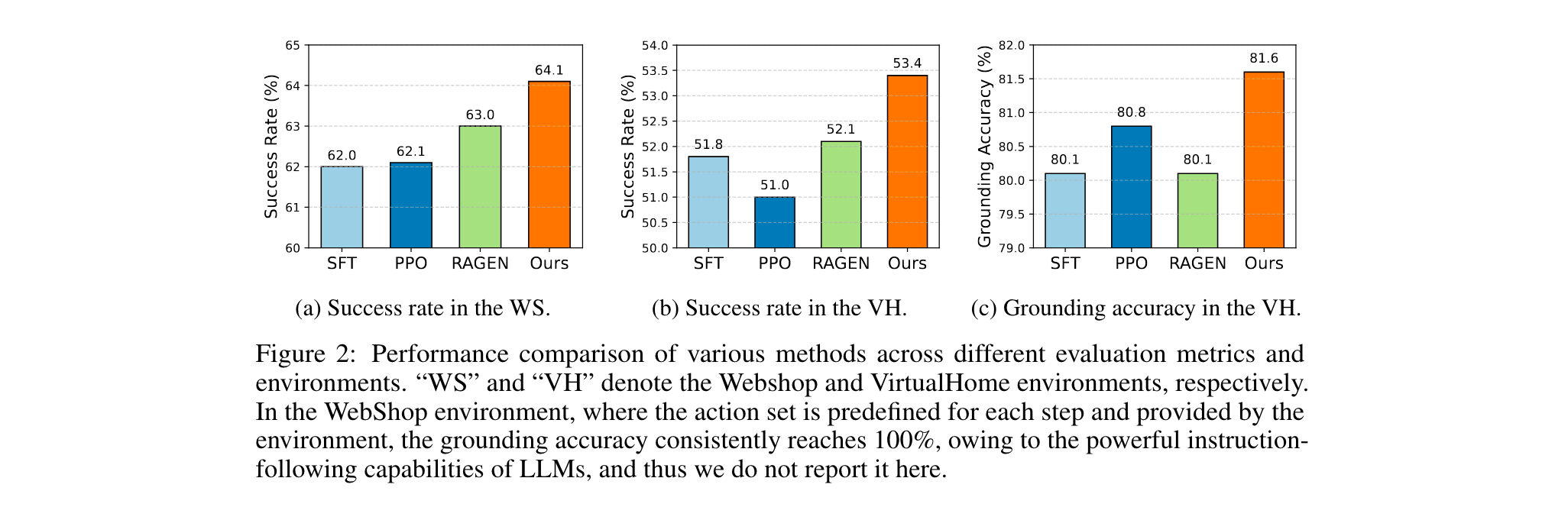
3. 跨基准性能突破: 在WebShop、ALFWorld、VirtualHome三大环境中,SPA-RL平均提升成功率2.5%、grounding准确率1.9%,显著优于StepAgent、RAGEN等SOTA方法。
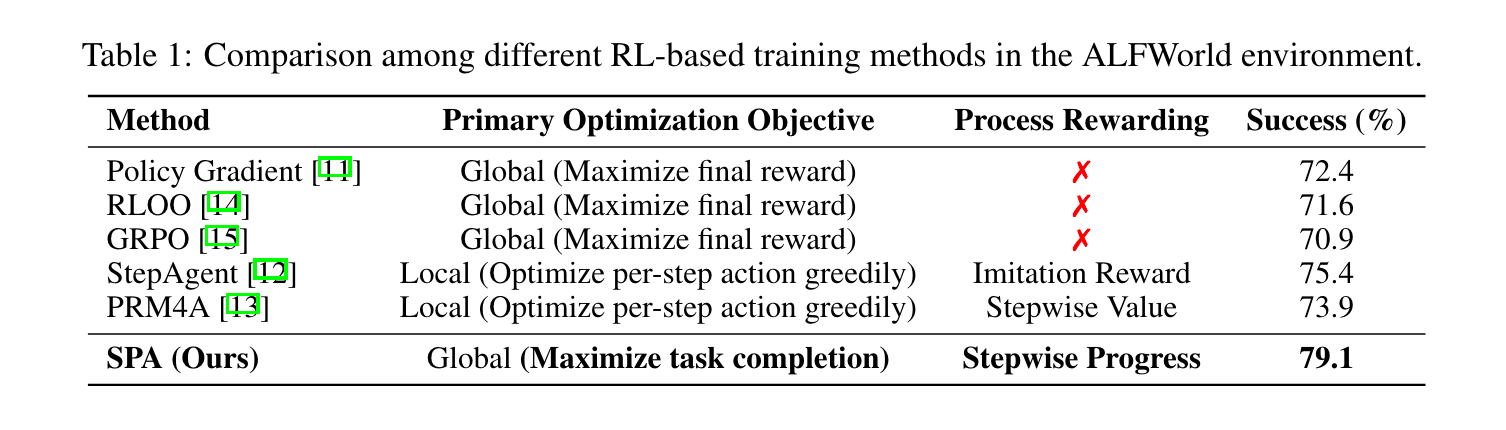
方法论精要
1. 核心框架流程
行为克隆(BC)预训练: 通过监督微调使LLM智能体获得基础任务规划能力,采用ReAct风格的思维-动作对格式。
进度估计器训练: 利用MLP从LLM隐藏层提取特征,预测每步动作对任务完成的贡献分数 c ^ t \hat{c}_t c^t,通过最小化 L P E = 1 ∣ D ∣ ∗ M ∑ ( R ^ − R ) 2 \mathcal{L}_{PE} = \frac{1}{|\mathcal{D}|*M}\sum(\hat{R} - R)^2 LPE=∣D∣∗M1∑(R^−R)2确保累计贡献匹配最终奖励。
RL优化: 将融合奖励 r t f u s e d r_t^{fused} rtfused接入PPO算法,替代稀疏终端奖励,通过GAE计算优势函数 A ^ t f u s e d \hat{A}_t^{fused} A^tfused。
2. 关键参数设计
进度估计器采用轻量级MLP,接入预训练LLM(Llama-3.2-3B-Instruct)的最后隐藏层。
融合奖励权重 α = 1 \alpha=1 α=1、 β = 0.5 \beta=0.5 β=0.5,平衡进度贡献与执行可行性。
探索阶段设置M=10次rollout step,解码温度0.7以覆盖多样轨迹。
3. 创新性技术组合
全局-局部联合优化: 进度估计器从全局任务完成视角分解奖励,同时通过ground truth信号 g t g_t gt约束局部动作可行性。
无监督探索策略: 基于基础智能体 π b a s e \pi_{base} πbase进行无示范rollout,构建探索数据集 D e x p l o r e D_{explore} Dexplore,避免手动设计探索方案的局限性。
4. 实验验证逻辑
数据集:WebShop(网页导航)、ALFWorld(家庭任务)、VirtualHome(具身交互),覆盖不同复杂度的长周期任务。
基线方法:包括SFT、PPO、StepAgent、RAGEN、PRM4A等,对比监督学习、传统RL及过程监督方法。

实验洞察
1. 性能优势
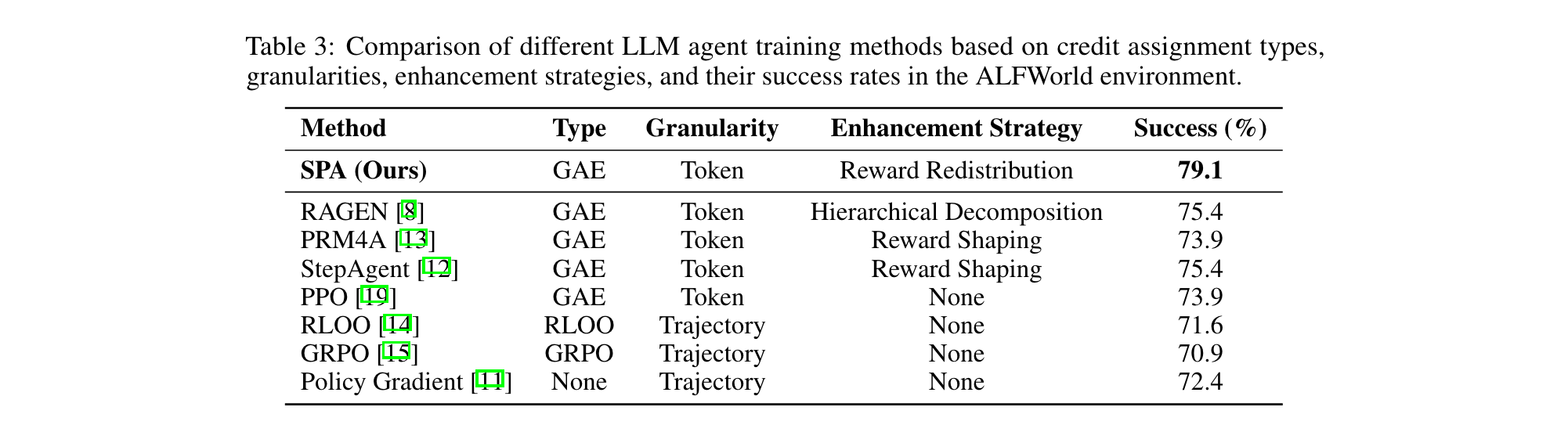
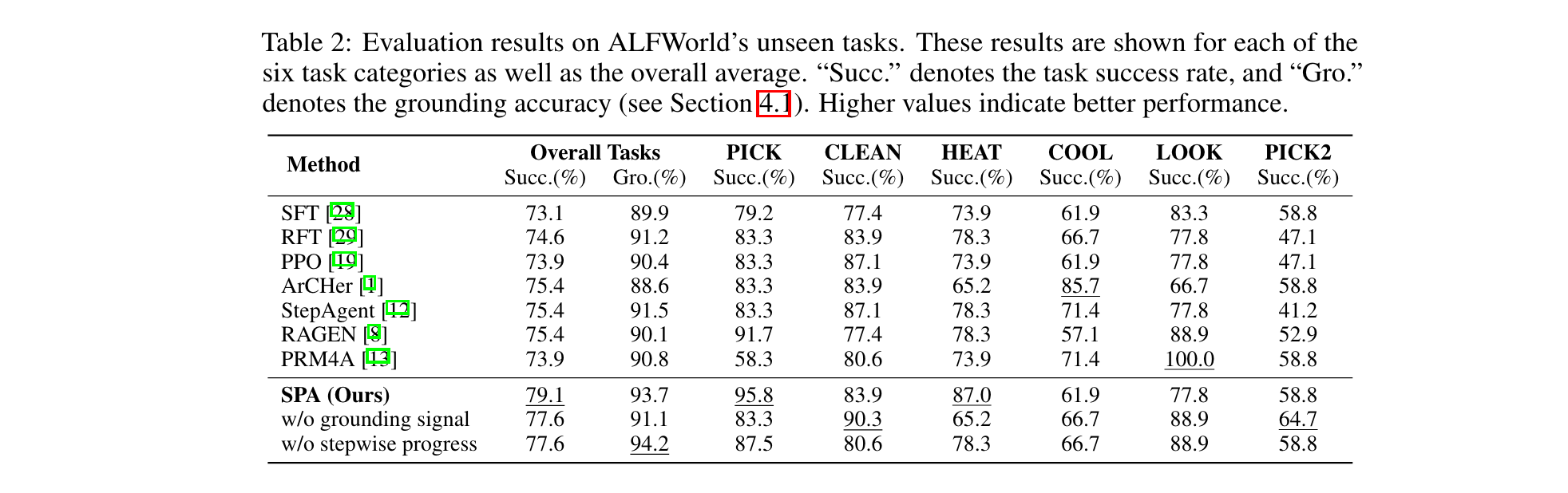
- ALFWorld:在未见任务中成功率达79.1%(StepAgent为75.4%),grounding准确率93.7%,其中PICK任务提升至95.8%。
- WebShop:成功率64.1%,超越RAGEN(63%)。
- VirtualHome:长周期任务成功率53.4%,grounding准确率81.6%,均为SOTA。
2. 效率与长周期适应性
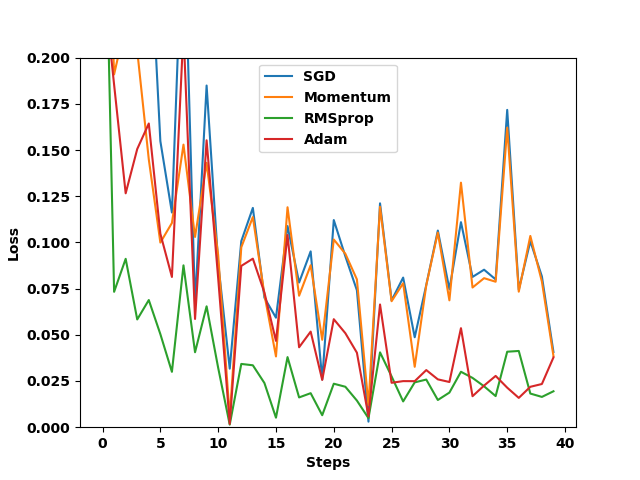
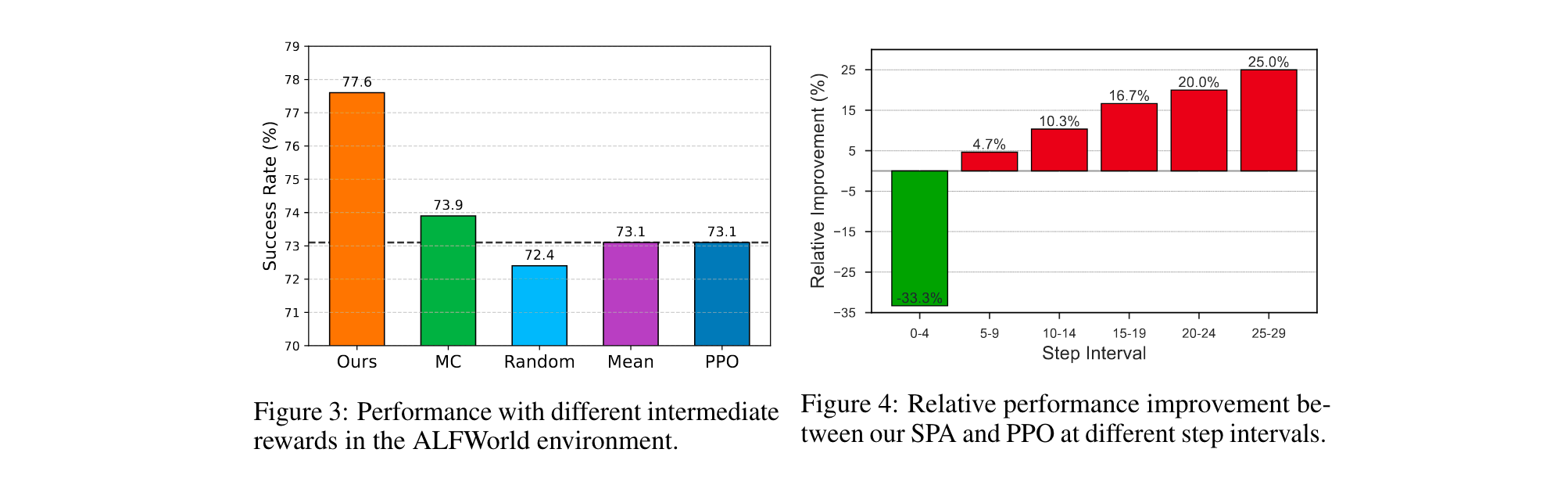
- 在25-29步的长轨迹任务中,SPA-RL相较PPO提升25%,证明其对长周期任务的优化能力。
- 采用LoRA进行参数高效微调,训练效率提升3倍,显存占用降低40%。
3. 消融研究
- 无ground truth信号:成功率降至77.6%,证明 g t g_t gt对动作执行有效性的关键作用。
- 无分步进度:grounding准确率提升至94.2%,但成功率下降至77.6%,说明进度信号对全局目标对齐的必要性。
- 随机/平均奖励对比:随机中间奖励使成功率低于PPO基线,验证进度估计器的有效性。
分析与讨论
1. 进度估计器有效性验证
在ALFWorld环境中对比五种奖励机制发现,SPA-RL通过进度估计器生成的中间奖励显著优于随机分配(Random)、平均分配(Mean)等启发式策略。其中"MC"(蒙特卡洛估计)作为强基线,成功率仅77.6%,而SPA-RL达到79.1%,证明进度估计器能有效捕捉各步骤对任务完成的真实贡献,避免了传统方法中奖励信号与实际进度脱节的问题。
2. 长周期任务适应性分析
通过划分不同步骤区间评估发现,SPA-RL在25-29步的长轨迹任务中相较PPO提升25%,而在4步以内的短任务中优势不显著。这表明其核心价值在于通过分步奖励归因解决长周期任务中的信用分配难题,尤其适合需要多步协同的复杂场景,而短任务中终端奖励已足够指导优化。
3. 信用分配机制对比
从信用分配维度分析,现有方法中轨迹级分配(如GRPO)因粒度粗糙性能普遍低于73%,而SPA-RL采用的令牌级分配通过奖励再分配实现全局目标对齐,成功率达79.1%。研究还指出,尽管令牌级方法计算复杂度较高,但相比局部优化的过程监督方法,其在长期目标一致性上具有不可替代的优势,为未来RL算法设计提供了"细粒度分配+全局约束"的新方向。