目录
摘要
1. 引言
2. Transformer架构核心原理
2.1 自注意力机制
2.2 位置编码
2.3 前馈神经网络
3. 从GPT到ChatGPT的演进
3.1 GPT系列模型架构
3.2 训练流程优化
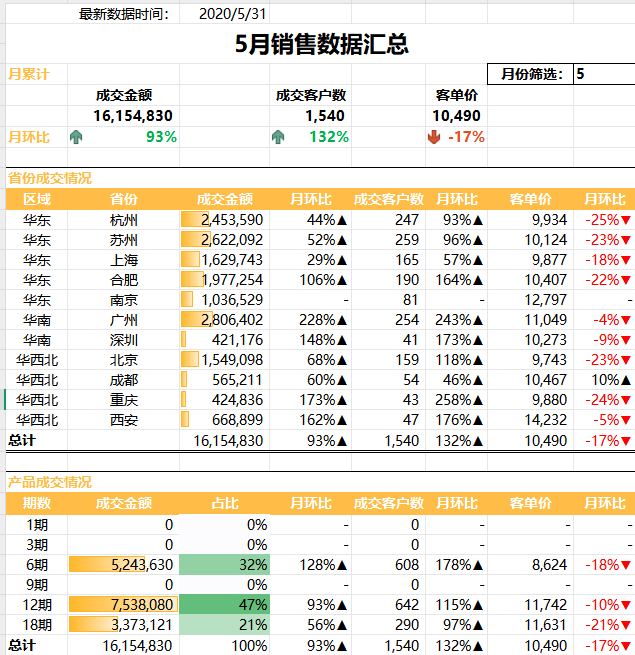
4. 应用场景与案例分析
4.1 代码生成
4.2 文本摘要
4.3 问答系统
5. 挑战与未来方向
5.1 当前技术挑战
5.2 未来发展方向
后记
参考文献
摘要
本文系统性地探讨了大语言模型(Large Language Model, LLM)的核心技术原理、架构演进和实际应用。首先介绍了Transformer架构的关键组件及其数学表达,包括自注意力机制和前馈神经网络;然后详细分析了从GPT到ChatGPT的模型演进路径;接着探讨了大语言模型在多个领域的应用场景;最后讨论了当前技术面临的挑战和未来发展方向。通过数学公式和架构图解,本文为读者提供了对大语言模型技术原理的深入理解。
关键词:大语言模型、Transformer、自注意力机制、GPT、深度学习
1. 引言
近年来,以ChatGPT为代表的大语言模型在自然语言处理领域取得了突破性进展,引发了学术界和工业界的广泛关注。这些模型基于Transformer架构,通过海量数据和强大算力训练而成,展现出惊人的语言理解和生成能力。本文将深入剖析大语言模型的技术原理,帮助读者理解其工作机制和潜在应用。
2. Transformer架构核心原理
2.1 自注意力机制
自注意力机制是Transformer架构的核心组件,其数学表达如下:
Attention(Q, K, V) = softmax(QK^T/√d_k)V
其中:
- Q(Query)表示查询向量
- K(Key)表示键向量
- V(Value)表示值向量
- d_k是键向量的维度
- softmax函数用于计算注意力权重
多头注意力机制进一步扩展了这一概念:
2.2 位置编码
由于Transformer不包含循环或卷积结构,需要显式地注入位置信息:



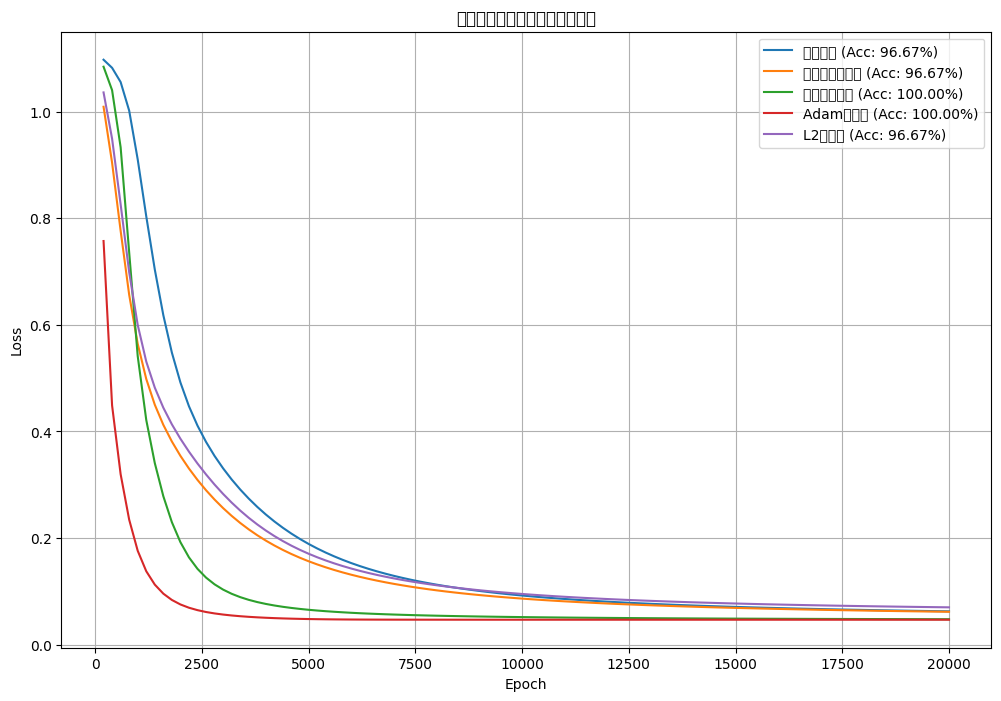
![[神经网络]使用olivettiface数据集进行训练并优化,观察对比loss结果](https://i-blog.csdnimg.cn/direct/d3f9b3ecf99f4846a6417d79091f3908.png#pic_center)