Dataset和Dataloader类
知识点回顾:
- Dataset类的__getitem__和__len__方法(本质是python的特殊方法)
- Dataloader类
- minist手写数据集的了解
作业:了解下cifar数据集,尝试获取其中一张图片
Dataset和Dataloader类
1. Dataset类的 __getitem__ 和 __len__ 方法
-
__getitem__方法:-
就像餐厅的菜单系统,顾客可以通过菜单(索引)点菜(获取数据项)。
__getitem__方法允许我们通过索引获取数据集中的单个数据项。 -
例如,
dataset[0]可以获取数据集中的第一个数据项。
-
-
__len__方法:-
就像餐厅知道今天准备了多少道菜供顾客选择。
__len__方法返回数据集的总长度,即数据集中有多少个数据项。 -
例如,
len(dataset)可以返回数据集的总大小。
-
2. Dataloader类
-
Dataloader 就像餐厅的传菜员,负责将准备好的菜品(数据项)按批次送到顾客(模型)面前。Dataloader 类负责将数据集分成批次,并在训练过程中逐批提供数据。
-
它可以打乱数据顺序(洗牌),以确保模型在训练过程中不会因为数据顺序而产生偏差。
-
它还可以利用多线程加速数据加载过程。
MNIST手写数据集
-
MNIST数据集 就像一个包含手写数字图片的菜谱库,每张图片是一个手写数字(0-9),图片大小为28x28像素,数据集分为训练集和测试集,分别用于训练和测试模型。
作业:了解 CIFAR 数据集,尝试获取其中一张图片
1. CIFAR 数据集
-
CIFAR-10 是一个包含10个类别的图片数据集,每个类别有6000张图片,图片大小为32x32像素。类别包括飞机、汽车、鸟、猫、鹿、狗、青蛙、马、船和卡车。
-
CIFAR-100 是一个包含100个类别的图片数据集,每个类别有600张图片。
2. 获取 CIFAR 数据集中的一张图片
以下是使用 PyTorch 获取 CIFAR-10 数据集中一张图片的示例代码:
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader , Dataset # DataLoader 是 PyTorch 中用于加载数据的工具
from torchvision import datasets, transforms # torchvision 是一个用于计算机视觉的库,datasets 和 transforms 是其中的模块
import matplotlib.pyplot as plt
# 设置随机种子,确保结果可复现
torch.manual_seed(42)
# 1. 数据预处理,该写法非常类似于管道pipeline
# transforms 模块提供了一系列常用的图像预处理操作
# 先归一化,再标准化
transform = transforms.Compose([
transforms.ToTensor(), # 转换为张量并归一化到[0,1]
transforms.Normalize((0.1307,), (0.3081,)) # MNIST数据集的均值和标准差,这个值很出名,所以直接使用
])
# 2. 加载MNIST数据集,如果没有会自动下载
train_dataset = datasets.MNIST(
root='./data',
train=True,
download=True,
transform=transform
)
test_dataset = datasets.MNIST(
root='./data',
train=False,
transform=transform
)
import matplotlib.pyplot as plt
# 随机选择一张图片,可以重复运行,每次都会随机选择
sample_idx = torch.randint(0, len(train_dataset), size=(1,)).item() # 随机选择一张图片的索引
# len(train_dataset) 表示训练集的图片数量;size=(1,)表示返回一个索引;torch.randint() 函数用于生成一个指定范围内的随机数,item() 方法将张量转换为 Python 数字
image, label = train_dataset[sample_idx] # 获取图片和标签
# 可视化原始图像(需要反归一化)
def imshow(img):
img = img * 0.3081 + 0.1307 # 反标准化
npimg = img.numpy()
plt.imshow(npimg[0], cmap='gray') # 显示灰度图像
plt.show()
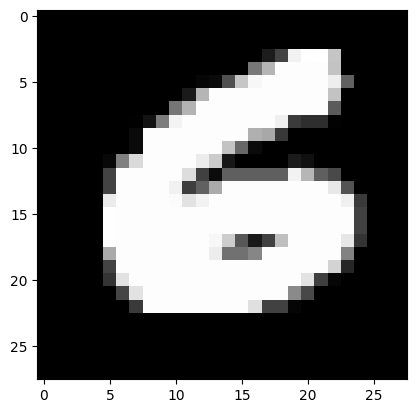
print(f"Label: {label}")
imshow(image)
# 3. 创建数据加载器
train_loader = DataLoader(
train_dataset,
batch_size=64, # 每个批次64张图片,一般是2的幂次方,这与GPU的计算效率有关
shuffle=True # 随机打乱数据
)
test_loader = DataLoader(
test_dataset,
batch_size=1000 # 每个批次1000张图片
# shuffle=False # 测试时不需要打乱数据
)
@浙大疏锦行