🔍 设计动机:为何抛弃继承选择组合?
在实现多维向量类Vector时,我们刻意采用组合模式而非继承,核心优势在于:
- 高扩展性:通过array数组存储分量,天然支持高维向量
- 低耦合:避免继承链带来的隐式依赖
- 序列协议:更纯粹地实现不可变扁平序列的特性
⚙️ 核心实现解析
构造方法设计
def __init__(self, components):
self._components = array(self.typecode, components)
- 参数策略:接受任意可迭代对象(列表/元组/生成器等)
- 兼容取舍:放弃与Vector2d构造参数兼容,但遵循内置序列规范
智能表示优化
def __repr__(self):
components = reprlib.repr(self._components)[6:-1]
return f'Vector({components})'
- reprlib黑科技:自动截断超长元素(默认阈值6个)
- 输出示例:Vector([0.0, 1.0, 2.0, 3.0, 4.0, …])
序列协议实现
| 方法 | 实现要点 | 技术亮点 |
|---|---|---|
| iter | 返回数组迭代器 | 支持解包操作*args |
| bytes | 类型码+数组二进制 | 内存零拷贝优化 |
| frombytes | 使用memoryview解析 | 避免数据复制开销 |
🛠️ 关键方法实现对比
# 绝对值计算(高维扩展)
def __abs__(self):
return math.sqrt(sum(x**2 for x in self))
# 与Vector2d的差异
Vector2d:math.hypot(self.x, self.y)
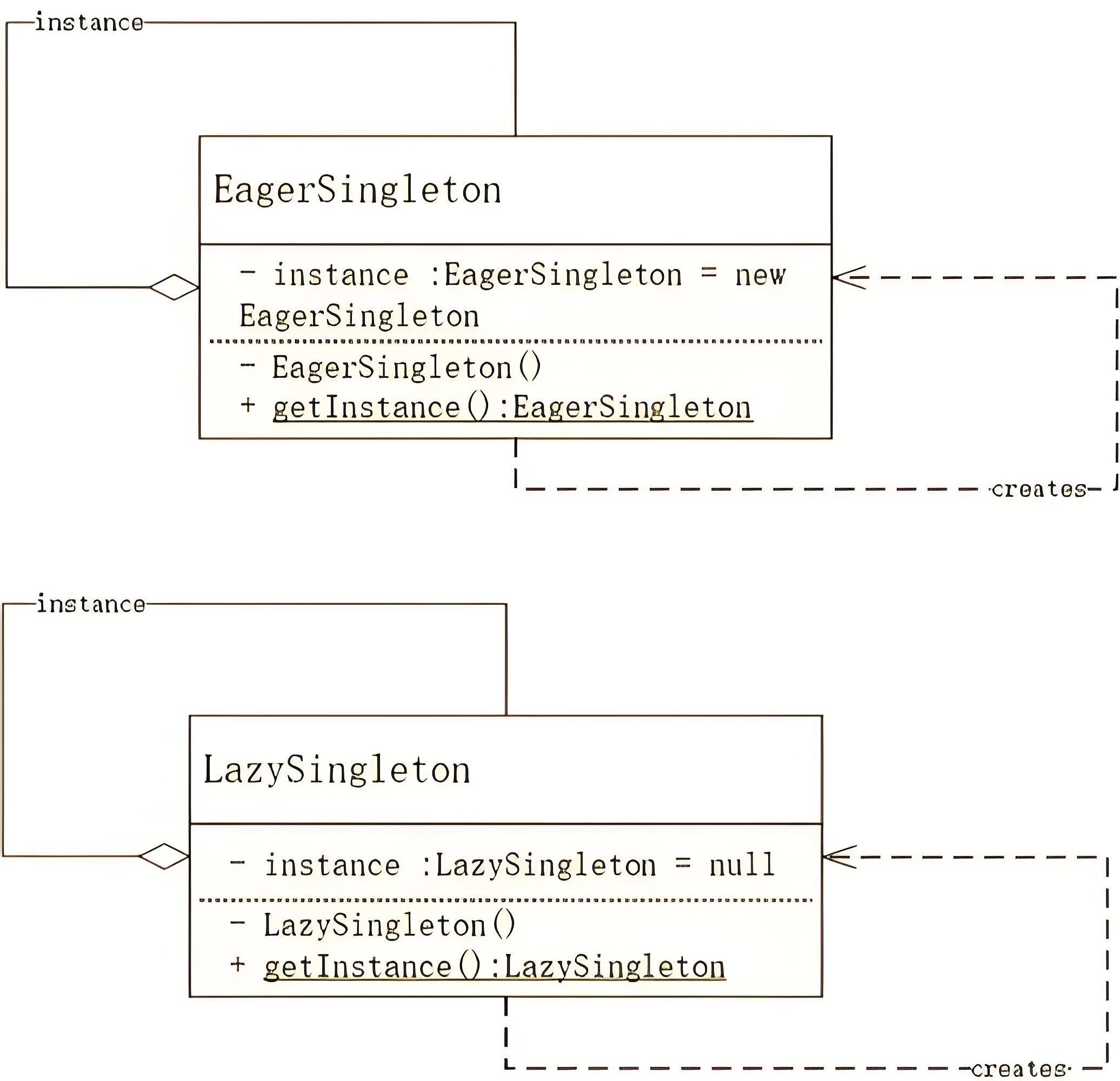
🚫 拒绝继承的深层考量
- 构造方法冲突:Vector2d(x, y) vs Vector(iterable)
- 协议专注性:需要更纯粹地实现序列协议方法
- 功能隔离:避免继承带来的非必要方法污染
💡 最佳实践启示
- 防御性编程:__repr__必须保证永不抛出异常
- 内存优化:使用array比list节省50%以上内存
- 类型统一:所有分量强制转换为float类型存储
- 协议优先:通过实现魔术方法支持原生操作
🧪 兼容性测试要点
# 验证与Vector2d的兼容性
assert Vector([3,4]) == Vector2d(3,4)
assert bytes(Vector([1,2])) == bytes(Vector2d(1,2))
📚 扩展思考
- 如何支持切片操作?
- 怎样实现向量间的数学运算?
- 能否与numpy数组无缝交互?



![[yolov11改进系列]基于yolov11引入自注意力与卷积混合模块ACmix提高FPS+检测效率python源码+训练源码](https://i-blog.csdnimg.cn/direct/2381f3b5816a4edb83b74966be0cfa93.jpeg)