🔥「炎码工坊」技术弹药已装填!
点击关注 → 解锁工业级干货【工具实测|项目避坑|源码燃烧指南】
——从架构到实践,解析音画同步、物理模拟与长视频生成的破局之战
一、技术架构:双雄对垒,殊途同归?
谷歌Veo和OpenAI Sora均采用Latent Diffusion Transformer架构,但技术细节存在显著差异:
1. 核心架构对比
| 模块 | 谷歌Veo | OpenAI Sora |
| 文本编码器 | UL2 Encoder(比T5更强的文本理解能力) | T5 Encoder(传统文本编码模型) |
| 图像/视频编码器 | 支持图像Prompt条件分支 | 未明确提及图像条件输入 |
| 扩散模型 | Transformer-based Diffusion Model | Latent Diffusion Transformer |
| 音频生成模块 | V2A(Video-to-Audio,端到端音画同步) | 依赖后期音频合成 |
技术核心差异:
- Veo的UL2 Encoder在长文本理解和多模态交互上更占优势,尤其支持图像与文本混合输入;
- Sora的Patch-based表示将视频切分为小块(Patch),类似GPT的Token化,灵活性更高,但对长序列建模挑战更大。
二、技术痛点与突破:谁在引领行业?
1. 音画同步:Veo3的“开口说话”革命
传统视频生成模型(包括Sora)生成的画面与音效需分开处理,导致唇形与对白不同步、脚步声与动作错位等问题。
Veo3的破局点:
- V2A技术:从视频像素和文本提示中直接生成音轨,实现对白、环境音效、背景音乐的端到端同步;
- 物理模拟:通过深度学习声音与物体运动的关联(如炒菜滋滋声、脚步咯吱声),确保音画动态匹配。
2. 长视频生成:时长墙的突破
目前主流模型(包括Veo2/Sora)均受限于8秒视频生成,超过10秒易出现角色畸变、场景崩坏。
Veo3的进展:实验室测试15秒1080P视频,但尚未公开;
Sora的策略:通过“重述提示词技术”分段生成,依赖后处理拼接。
3. 物理模拟与真实性
- Veo3:物理模拟精度达92.3%,支持雨水折射、物体碰撞等复杂效果;
- Sora:依赖大规模数据训练,但在超现实场景(如水珠悬浮)中易出错。
三、实践场景:谁更能改变行业规则?
1. 影视与广告创作
- Veo3:一键生成带音效的完整场景(如脱口秀、说唱MV),降低后期成本;
- Sora:擅长高画质特效(如太阳落山、烧烤特写),但需手动配音。
2. 游戏与虚拟现实
- Veo3:支持多人物唇形同步与动态音效,适合NPC对话生成;
- Sora:更注重场景构建(如开放世界探索)。
3. 教育与电商
- Veo3:快速生成带解说的商品视频,支持文字提示修改物体(如替换产品logo);
- Sora:需额外工具辅助编辑,流程复杂度更高。
四、可视化架构图(Mermaid语法)
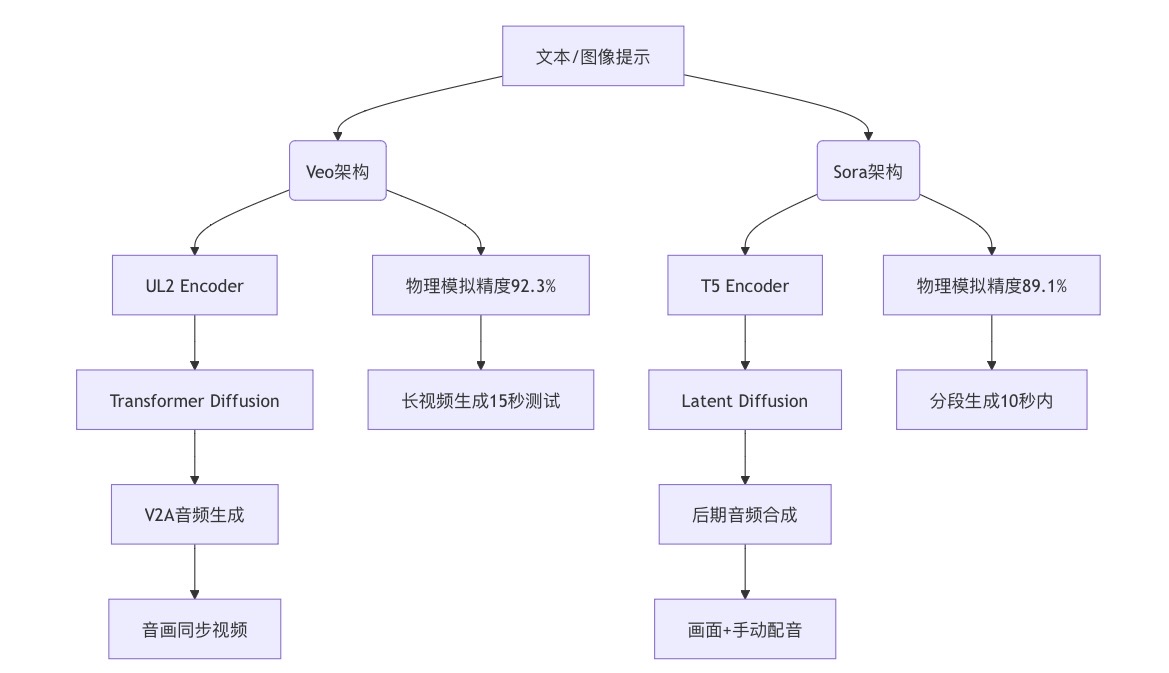
五、技术趋势与未来展望
- 音画一体生成:Veo3的V2A技术将成标配,Sora需补足音频短板;
- 长视频生成:突破“时长墙”是关键,可能依赖更高效Transformer架构;
- 多语言与全球化:Veo3目前仅支持英文提示,中文及小语种市场需深耕;
- 成本与商业化:Veo3订阅费249.99美元/月,Sora尚未公开商用计划,普惠化仍是长期目标。
附:专有名词说明表
| 英文/中文全称 | 解释 |
| Latent Diffusion Transformer | 潜空间扩散模型,通过压缩视频/图像到低维空间生成内容,降低计算复杂度 |
| UL2 Encoder | 谷歌开发的文本编码器,性能优于T5,支持多模态输入 |
| V2A (Video-to-Audio) | Veo3的核心音频生成技术,从视频像素和文本提示中直接生成同步音效 |
| Patch-based | Sora采用的数据表示方式,将视频切分为小块(类似GPT的Token) |
| 重述提示词技术 | Sora通过多次优化用户提示词,提升视频生成的准确性 |
| 物理模拟精度 | 视频生成中物体运动、光线反射等符合现实物理规律的程度 |
| 时长墙 | 当前AI视频生成模型在生成10秒以上视频时的质量崩溃问题 |
结语:谷歌Veo3凭借音画同步与物理模拟优势,在影视、游戏等领域率先落地;而Sora以高画质和灵活性见长,但商业化进程缓慢。未来竞争将聚焦于长视频生成与生态整合,AI视频时代已全面开启!
🚧 您已阅读完全文99%!缺少1%的关键操作:
加入「炎码燃料仓」
🚀 获得:
√ 开源工具红黑榜 √ 项目落地避坑指南
√ 每周BUG修复进度+1%彩蛋
(温馨提示:本工坊不打灰工,只烧脑洞🔥)



![[yolov11改进系列]基于yolov11引入自注意力与卷积混合模块ACmix提高FPS+检测效率python源码+训练源码](https://i-blog.csdnimg.cn/direct/2381f3b5816a4edb83b74966be0cfa93.jpeg)