AI 数据采集实战指南:基于Bright Data快速获取招标讯息
在招标行业中,快速、准确地获取招标公告、项目详情、投标截止日期和其他关键招标信息,是投标企业提高竞标成功率的核心竞争力。然而,招标信息往往分散在不同的平台和网页,数据格式复杂多变,且常常面临反爬机制如 IP 限制、验证码挑战,人工收集效率低、成本高。

在实际业务中,假设有一家企业希望及时监测主流招标网站上的最新公告和项目信息,如项目名称、预算金额、截止日期等关键内容。然而,由于这些平台普遍设置了反爬机制,包括 IP 限制、验证码验证以及动态页面加载等传统数据采集技术难以攻克的问题,企业在实际数据采集中往往面临较大的技术挑战。
常见网络爬虫挑战及 亮数据 的技术解决方案
在进行大规模网络数据抓取时,经常会遇到 IP 地址限制、验证码拦截以及目标网站数据结构复杂等难题。下面针对这些常见问题,以技术角度介绍亮数据平台提供的解决方案和相关特性。
IP 限制与频繁封禁
许多网站针对来自单一 IP 地址的异常流量会实施频率限制或直接封禁,这使传统使用固定 IP 或单一代理的爬虫方案容易失效。
**亮数据的解决方案:**亮数据提供了自动 IP 轮换功能(IP Rotation)。该平台通过其全球分布的代理节点网络,在连续的请求之间自动切换不同的 IP 地址,使每次请求看起来来自不同来源,从而降低被目标网站识别为爬虫的风险。这种代理池轮换机制有效缓解了频繁封禁的问题,开发者无需手动管理代理列表,即可提高爬取的稳定性。
验证码与反爬机制
很多目标网站使用验证码(包括图形验证码、滑动验证等)和其他反爬虫机制来阻止自动脚本访问。这些机制会要求复杂的人机验证步骤,给爬虫脚本带来极大挑战。
**亮数据的解决方案:**亮数据集成了自动验证码识别和处理功能,能够在无需人工干预的情况下绕过各类验证码挑战。例如,当遇到图形验证码或 reCAPTCHA 时,Bright Data 的爬取引擎可以自动识别并提交正确的验证响应,使数据抓取流程不中断。此外,该平台支持对动态网页的 JavaScript 渲染。这意味着 Bright Data 的爬虫能够像浏览器一样执行页面中的 JavaScript 脚本,拿到渲染后的完整内容,再提取所需数据。借助这些功能,Bright Data 可以应对复杂的反爬措施,确保动态加载的内容也能够顺利获取。
数据结构复杂
不同网站往往有各自独特且复杂的页面结构和数据格式。手工针对每个站点编写解析代码不仅耗时低效,也容易出错,难以适应页面结构的变化。
**亮数据的解决方案:**亮数据提供了自动数据发现(Data Discovery)功能,用于智能解析页面结构并提取数据。具体而言,该功能会自动检测网页中的数据模式和层次结构,定位所需的信息字段,然后将其提取为结构化的数据格式(如 JSON、CSV)。开发者无需手动编写复杂的 DOM 解析和选择器逻辑,就能获取到所需的数据。这种智能提取机制不仅提高了开发效率,也减少了因为页面布局改变而导致爬虫失效的维护工作。
亮数据IDE
亮数据还提供了可视化 IDE(网页抓取工具 IDE),该 IDE 集成了预置爬虫模板、交互式预览和内置调试工具,使得开发者可以在浏览器中可视化地构建和测试爬虫脚本。同时,官方也支持主流编程语言(如 Python、JavaScript、Java 等)调用 API,提高了开发灵活性。Bright Data
核心功能方面,亮数据网页抓取 API 提供了丰富的企业级能力:自动IP轮换、验证码解决、用户代理轮换、JS渲染、数据解析和验证 等功能一应俱全。例如,它可以自动处理常见的反爬机制——无论是动态渲染页面还是出现滑动验证码,都能够自动绕过;同时支持一次性批量请求数千条 URL、并发抓取任务无限制。Bright Data 的爬虫 API 能够将结果以结构化的 JSON、NDJSON 或 CSV 格式返回,极大地简化了数据后续处理。通过后台还支持 Webhook 将数据推送到外部存储(如 S3、GCS 等),灵活嵌入现有流水线中。
##实际使用场景示例
步骤一
通过 官网注册账户并获取 API 密钥,设置所需的权限,例如 IP 自动轮换和验证码解决。
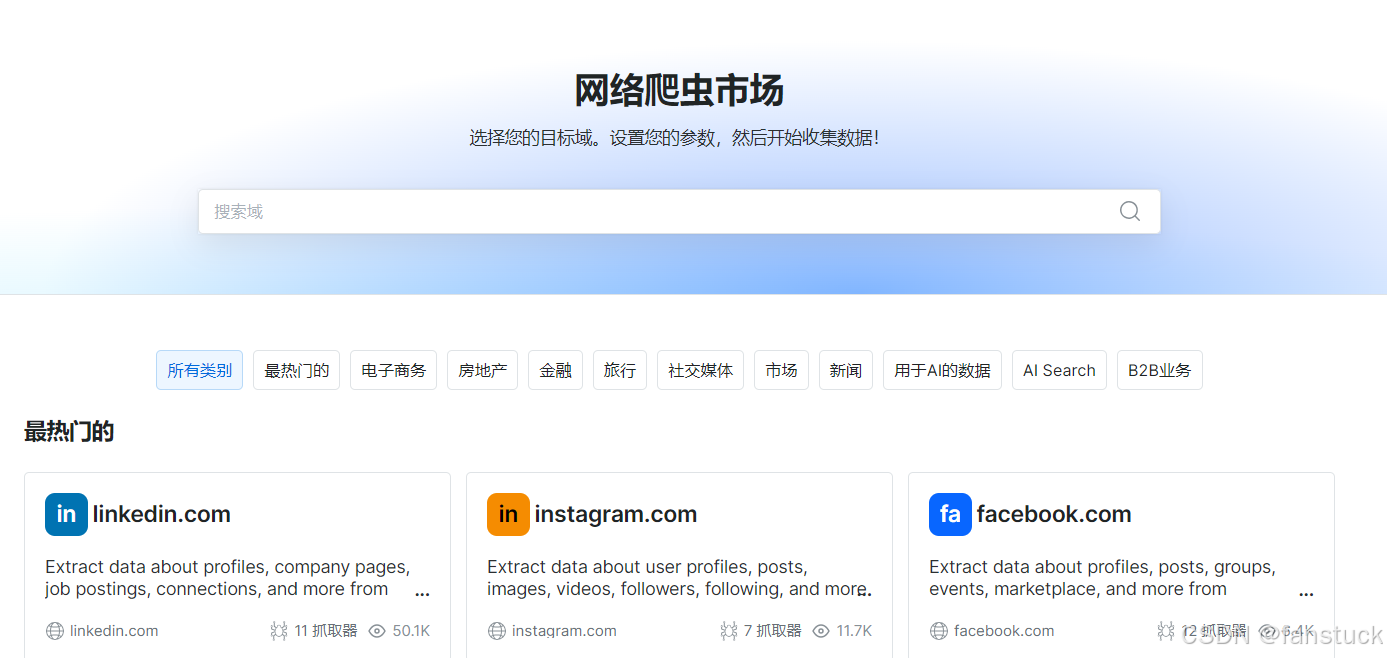
步骤二:确定监测目标
明确需要抓取的招标网站,整理出 URL 列表,如果没有目标网站可以在网络爬虫市场获取到相关领域的URL提供参考:
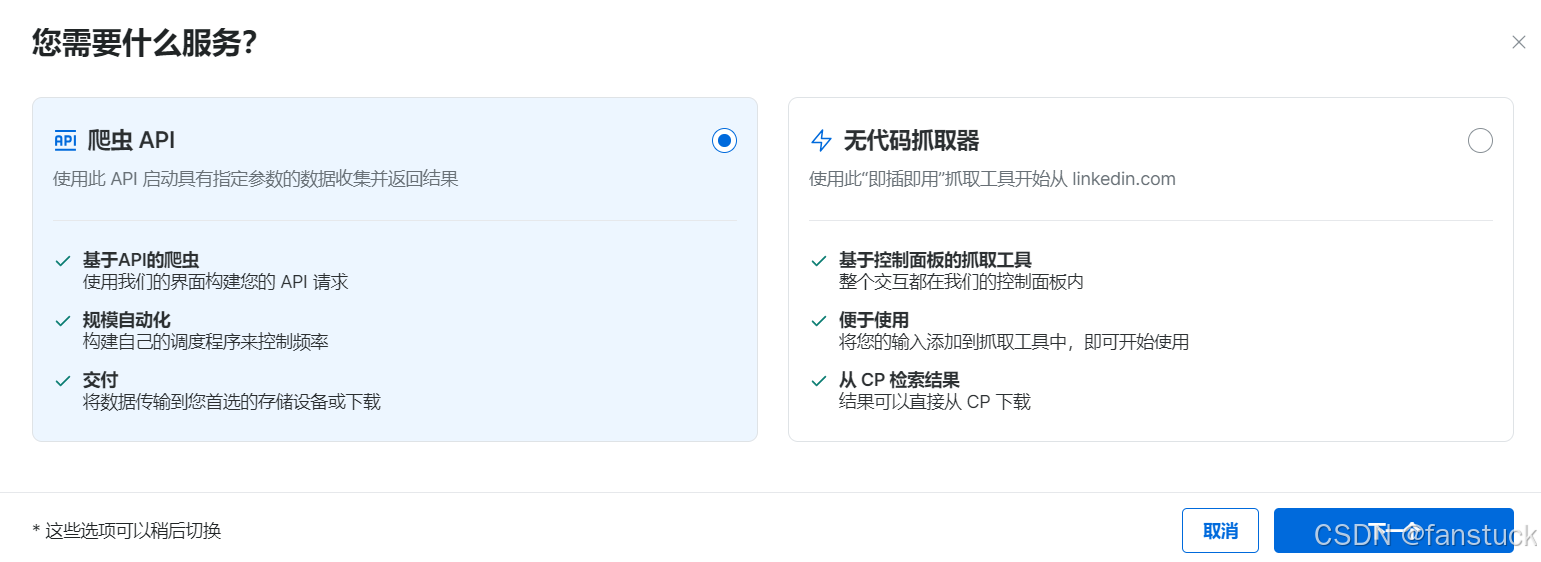
如果有目标的网站直接点击即可获取到服务:
步骤三:调用 Bright Data API 抓取数据
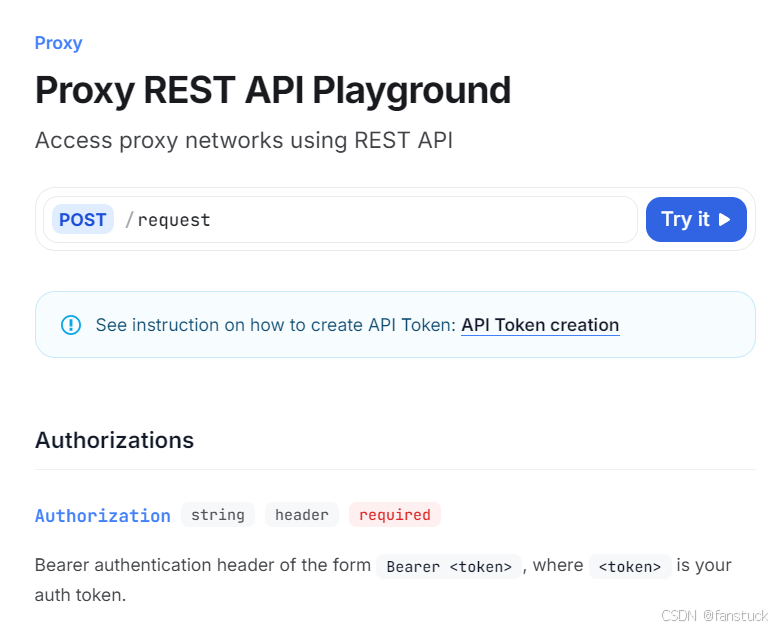
使用 Python 编写请求脚本启动数据抓取:
import requests
url = "https://api.brightdata.com/request"
payload = {
"zone": "default",
"url": target_url,
"format": "json",
"method": "GET",
"country": "CN",
"dns": "local"
}
headers = {
"Authorization": "Bearer YOUR_API_KEY",
"Content-Type": "application/json"
}
response = requests.request("POST", url, json=payload, headers=headers)
data = response.json()
步骤四:下载和处理抓取的数据
获取的数据已结构化为 JSON 格式,便于后续分析。
import pandas as pd
# 转换为 DataFrame
results = pd.json_normalize(data)
如果需要存储更多数据集,推荐直接进入数据集市获取数据样本:
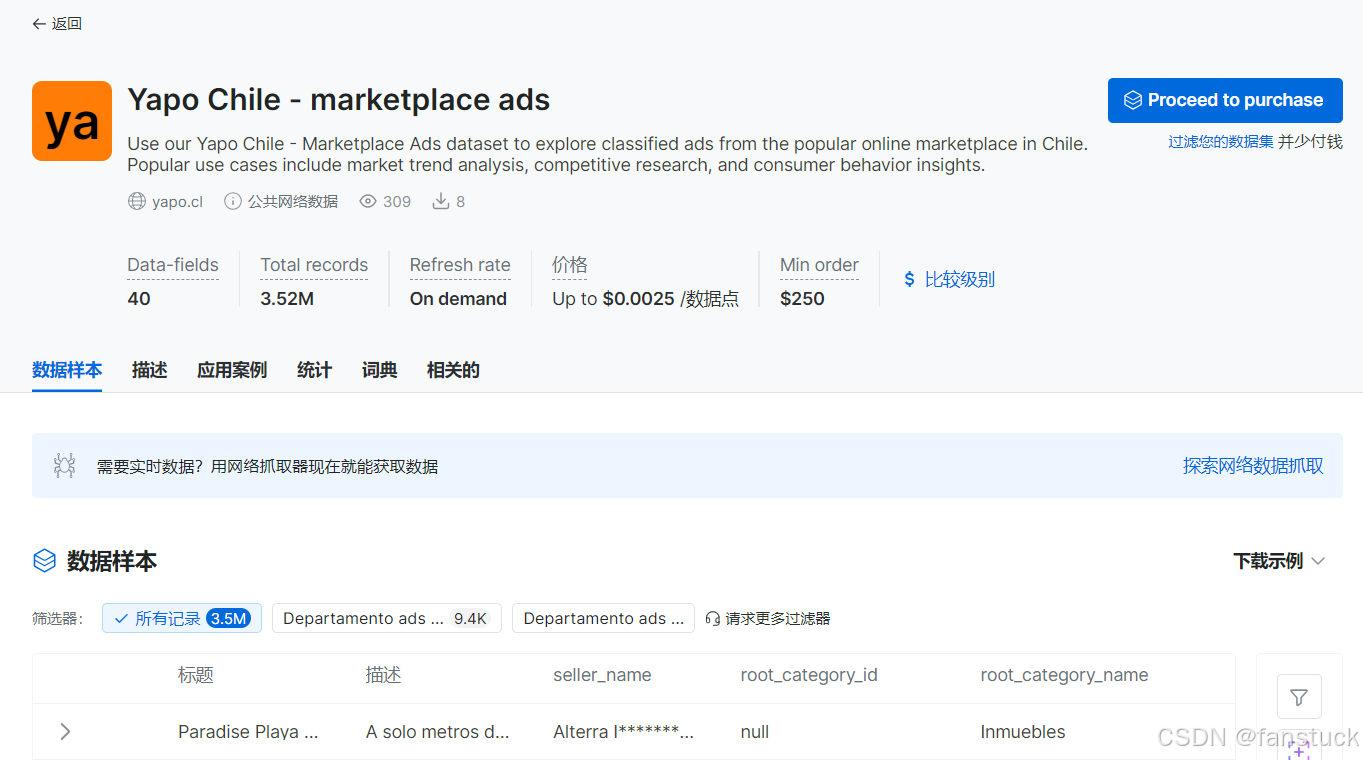
步骤五:数据存储及分析应用
将数据存储于企业内部数据库或导出为 CSV,用于进一步的数据分析和业务决策支持:
results.to_csv('bidding_data.csv', index=False)

开发者可以在本地代码中快速编写请求脚本并触发爬虫任务。Bright Data 将返回一个 snapshot_id,表示异步抓取任务已开始。随后,我们可以使用此 ID 拉取结果数据:
# 等待任务完成后,下载结果数据
download_url = f"https://api.brightdata.com/datasets/v3/result/{snapshot_id}"
res = requests.get(download_url, headers=headers)
data = res.json() # 结构化的抓取结果
返回的数据为 JSON 格式(也可选 CSV/NDJSON),包含了职位名称、公司、描述等字段。我们可遍历 data["items"] 等字段,将内容保存或导入数据库。
任务调度: 对于大规模数据采集,可将上述脚本部署到服务器并使用 定时任务(如 Linux crontab、Apache Airflow、Celery 等) 定期运行。例如,每天凌晨抓取一次最新职位信息,确保训练数据的时效性。此外,Bright Data 还支持通过 Webhook 自动将结果推送到指定存储(如 Amazon S3、Google Cloud Storage 等),方便与数据管道集成。
数据存储与结构化输出: 亮数据 输出的数据已是结构化格式,可直接加载到数据处理流程中。例如,我们可以将 JSON 结果转为 Pandas DataFrame,清洗后导出 CSV 供机器学习使用。数据字段已经分列(职位名、公司名、地点、发布时间、职位描述等),无需额外解析,大幅缩减了后处理工作量。
技术特性与适用能力分析
反封锁机制支持
亮数据提供了基于全球代理池的 IP 和用户代理轮换机制,用于降低被目标网站识别为自动访问的风险。平台集成了验证码识别功能,在应对滑动验证、图形验证码等交互式拦截机制时,具备自动处理能力,适用于反爬策略较为复杂的网站。
任务扩展与稳定性支持
其 API 设计支持高并发请求处理,能够在一次任务中批量抓取大量页面数据。平台具备可扩展基础设施,可根据流量需求自动扩容抓取任务,适用于大规模数据采集应用场景。根据公开说明,系统稳定性达到高可用标准,适合对抓取成功率有较高要求的任务部署。
解析与运维成本优化
亮数据支持自动化的数据字段识别与结构化提取功能,开发者可减少手动编写 DOM 提取逻辑的工作量。此外,平台为云端托管架构,省去了构建代理池、浏览器渲染环境等底层组件配置的需求,适合资源有限或希望快速集成数据采集能力的团队使用。
结构化数据输出与合规性说明
返回数据经过结构化处理,支持标准格式如 JSON、CSV 输出,便于后续集成至数据处理流程中。根据平台披露,其服务遵循包括 GDPR、CCPA 在内的主要隐私合规要求,并在相关法律争议中获得了对其抓取合法性的认可。开发者在数据合规处理方面可参考其合规文档与实践建议。
适用场景示例
亮数据的爬虫服务可应用于多种场景,如招聘信息采集、市场行情监控、评论情感分析、价格变动追踪等。其脚本结构可复用,通过修改目标 URL 即可切换任务类型,适用于构建灵活的通用数据采集工具链。
Bright Data
综上所述,亮数据的网页抓取工具凭借全面的特性和高可用性,为开发者提供了一站式的爬虫解决方案。实际使用中,我们体验到开发效率显著提升,很多繁琐的反爬对策都由平台自动完成。它解决了传统爬虫中常见的 IP 封锁、反爬墙、复杂结构解析 等难题,同时保持高度的扩展性和合规性。对于需要快速构建训练数据管道和开展数据驱动业务的团队来说,Bright Data Web Scraper 是一个值得尝试的利器。
![[AI]主流大模型、ChatGPTDeepseek、国内免费大模型API服务推荐(支持LangChain.js集成)](https://i-blog.csdnimg.cn/direct/94e97f54c91d4f3b9b7b735451200a7c.png)





![[Java恶补day8] 3. 无重复字符的最长子串](https://i-blog.csdnimg.cn/direct/00dfe46415c648d1b664b2e5cd5c4afc.png)