1. 基础概念
线性回归是一种用于建模连续型目标变量(如价格、销量、温度)与一个或多个特征变量(如面积、广告投入、时间)之间线性关系的统计方法。
-
核心思想:找到一条直线(或超平面),使得预测值与真实值的误差最小。
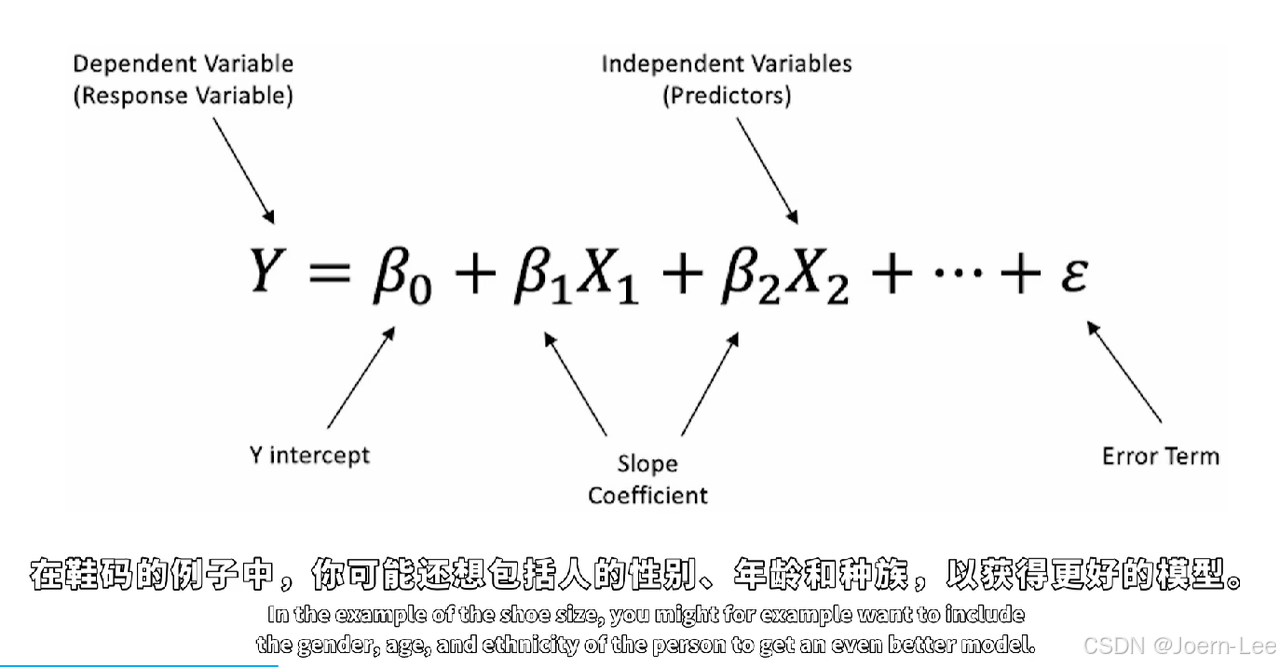
数学形式:
-
简单线性回归:
y = w*x + b-
y:目标变量(如房价) -
x:特征变量(如房屋面积) -
w:权重(斜率),b:偏置(截距)
-
-
多元线性回归:
y = w₁x₁ + w₂x₂ + ... + wₙxₙ + b-
多个特征共同预测目标(如面积、房间数、地段共同预测房价)。
-
-
2. 核心原理
损失函数:均方误差(MSE)
衡量预测值与真实值的差距: MSE = (1/N) * Σ(y_true - y_pred)² 目标是最小化MSE,找到最优的w和b。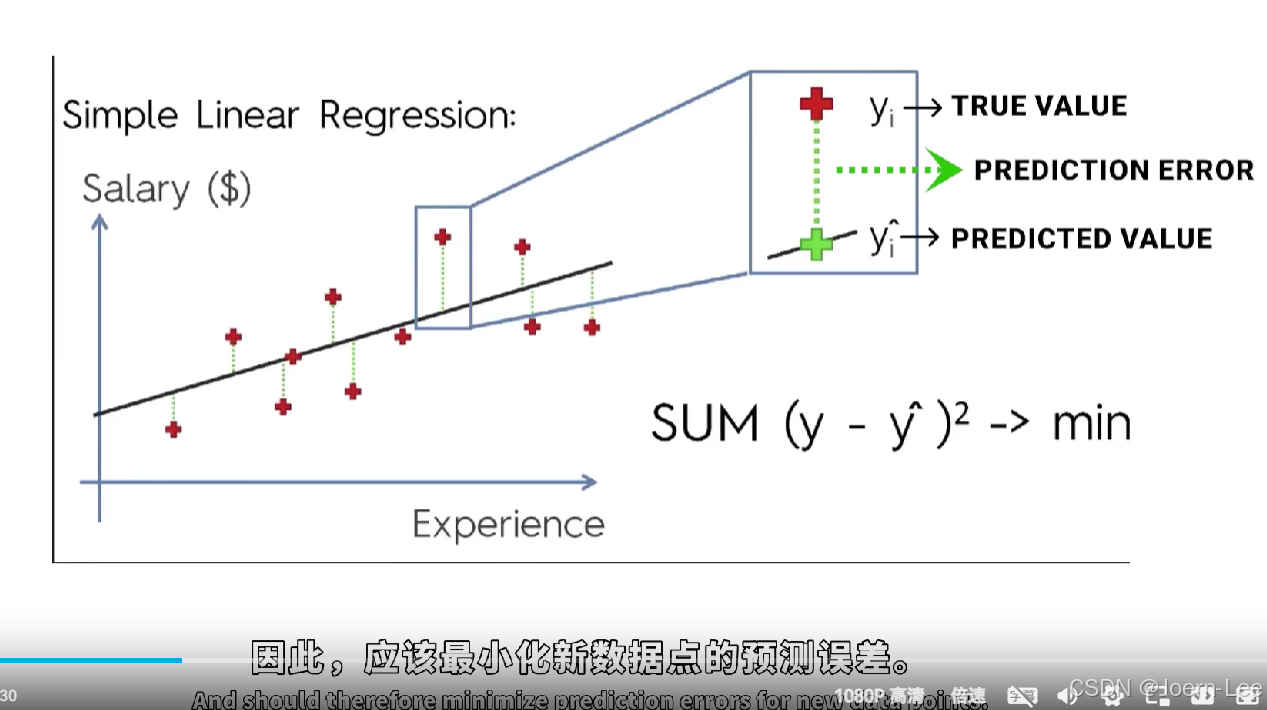
优化方法:梯度下降
通过迭代调整参数w和b,逐步降低损失函数的值(类似“下山找最低点”)。
评估指标
-
R²(决定系数):模型解释数据变异的比例,越接近1越好。
-
均方误差(MSE):越小越好。
3. 实际生产中的例子
案例1:房价预测
-
场景:房地产平台根据历史数据预测房屋售价。
-
特征:面积、房间数、地段评分、房龄。
-
输出:房价(连续值)。
-
应用:用户输入房屋信息后,自动生成估价报告。
案例2:电商销售额预测
-
场景:预测某商品的月度销售额。
-
特征:广告投入、促销力度、季节性指数、竞品价格。
-
输出:销售额(连续值)。
-
应用:优化广告预算分配,制定促销策略。
案例3:能源消耗预测
-
场景:工厂预测电力消耗以降低能源成本。
-
特征:生产线数量、工作时间、室外温度。
-
输出:每小时用电量。
-
应用:动态调整用电计划,避开用电高峰。
案例4:用户行为分析(互联网)
-
场景:预测用户在某APP上的停留时长。
-
特征:用户点击次数、页面加载速度、推荐内容相关性。
-
输出:停留时间(分钟)。
-
应用:优化推荐算法,提升用户留存。
4. 生产中的改进方法
处理非线性关系
-
多项式回归:将特征转换为高次项(如
x²,x³),拟合曲线。-
例如:广告投入与销售额可能呈“边际递减”曲线关系。
-
正则化(防止过拟合)
-
岭回归(Ridge):对权重
w的平方(L2范数)进行惩罚。 -
Lasso回归:对权重
w的绝对值(L1范数)进行惩罚,可自动筛选重要特征。
特征工程
-
归一化/标准化:加速梯度下降收敛。
-
处理缺失值:填充均值或中位数。
-
异常值处理:剔除或缩尾。
5. 优缺点
优点
-
✅ 简单、高效、可解释性强(权重反映特征重要性)。
-
✅ 适合小数据集或低维特征场景。
-
✅ 可作为复杂模型(如神经网络)的基准参考。
缺点
-
❌ 假设特征与目标呈线性关系,难以捕捉复杂模式。
-
❌ 对异常值和多重共线性敏感。
-
❌ 特征需人工设计,无法自动学习高阶交互。
6. 代码工具示例(Python)

7. 适用场景总结
-
推荐使用线性回归:
-
特征与目标关系近似线性。
-
需要快速验证业务假设(如广告投入是否影响销量)。
-
结果需可解释(如向业务部门汇报“面积对房价的影响”)。
-
-
避免使用:
-
数据高度非线性(如图像、音频)。
-
特征维度极高且存在多重共线性。
-
一句话总结
线性回归是“用直线拟合数据”的经典方法,虽简单但广泛应用于工业界,尤其在需要快速验证和解释性的场景中。