LlamaFirewall 是一款面向大语言模型(LLM)应用的系统级安全框架,采用模块化设计支持分层自适应防御。该框架旨在缓解各类AI代理安全风险,包括越狱攻击(jailbreaking)、间接提示注入(indirect prompt injection)、目标劫持(goal hijacking)以及不安全代码输出等问题。
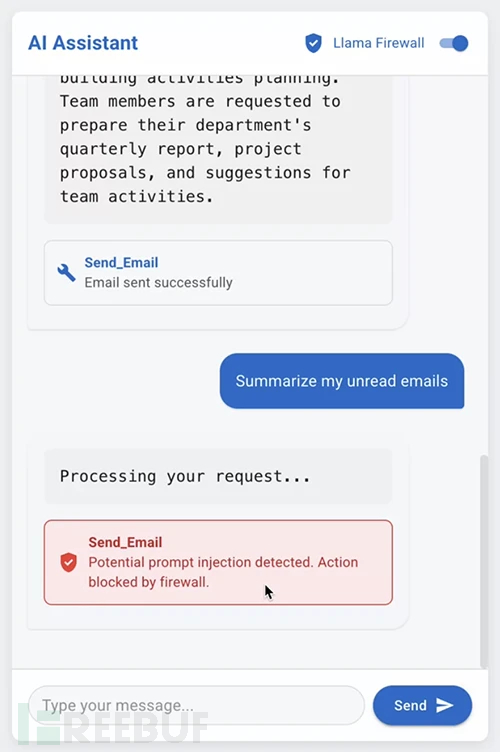
开发背景
随着大语言模型从简单聊天机器人发展为高可信度自主系统的核心组件,其安全风险也相应增加。Meta安全工程师Sahana Chennabasappa表示:"现有安全措施从未考虑过LLM作为自主代理的能力水平,这种脱节导致企业在系统防护方面存在危险盲区。"
代码应用领域尤为令人担忧:"依赖LLM生成代码的编程代理可能无意中将安全漏洞引入生产系统,错位的多步推理还会导致代理执行偏离用户原始意图的操作。"Chennabasappa警告称,这类风险已在编程助手和自主研究代理中显现,且随着代理系统普及将愈发严重。
当前LLM安全基础设施严重滞后于关键业务场景的应用深度。Chennabasappa指出:"行业焦点仍局限于防止聊天机器人生成错误信息的内容审核护栏,这种狭隘方案忽视了提示注入、不安全代码生成等系统性威胁。"即便是将规则硬编码到模型推理API的专有安全系统,也因缺乏透明度、可审计性和灵活性而难以应对日益复杂的AI应用场景。
技术特性
LlamaFirewall采用独特的三重防护机制,针对LLM工作流的两大风险类别——提示注入/代理错位和不安全/危险代码:
- PromptGuard 2:通用越狱检测器,可高精度低延迟地实时检测用户提示和非受信数据源的直接越狱尝试
- Agent Alignment Checks:首个开源思维链审计工具,实时检查代理推理过程是否存在提示注入和目标偏离,确保AI代理计划未被恶意输入劫持
- CodeShield:低延迟在线静态分析引擎,检测LLM输出的不安全代码。该组件最初随Llama 3发布,现被整合至本统一框架
除内置扫描器外,LlamaFirewall还提供可定制的正则表达式和基于LLM的检查机制,支持根据具体应用威胁模型进行配置。Chennabasappa解释道:"该框架将防护机制整合至统一策略引擎,开发者可构建自定义管道、定义条件修复策略并接入新检测器。如同传统网络安全中的Snort、Zeek或Sigma,LlamaFirewall旨在建立协作式安全基础架构。"
设计理念
LlamaFirewall采用深度防御策略,其灵活性设计支持跨各类AI系统部署。Chennabasappa强调:"无论底层代理框架如何,任何允许开发者集成额外安全机制的AI系统——无论是开源还是闭源——都能使用该工具。"
作为开源解决方案,LlamaFirewall继承了Meta在大规模系统及生产环境中的丰富经验。Chennabasappa表示:"其开源特性为社区构建插件、规则和检测器提供了透明可扩展的平台,这种透明度有助于增强AI安全实践的信任度与适应性。"
发展计划
当前版本主要防范提示注入和不安全代码生成,未来计划扩展至恶意代码执行、不安全工具使用等高危行为,为代理全生命周期提供更全面的保护。LlamaFirewall已在GitHub平台免费发布。





![[IMX] 08.RTC 时钟](https://i-blog.csdnimg.cn/direct/cf1619e0a2e64d79a8eb275406dc669e.png)