Redis学习打卡-Day7-高可用(下)
前面提到,在某些场景下,单实例存Redis缓存会存在的几个问题:
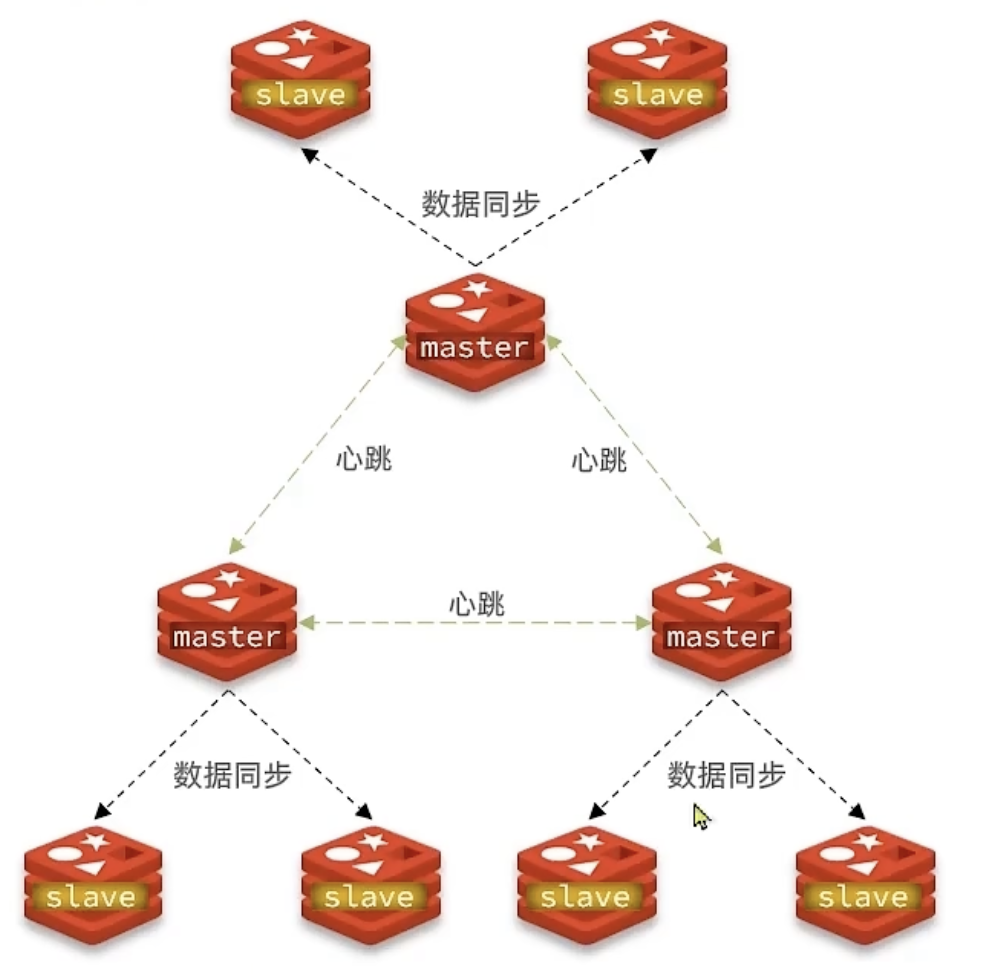
写并发:Redis单实例读写分离可以解决读操作的负载均衡,但对于写操作,仍然是全部落在了master节点上面,在海量数据高并发场景,一个节点写数据容易出现瓶颈,造成master节点的压力上升 。海量数据的存储压力:单实例Redis本质上只有一台Master作为存储,如果面对海量数据的存储,一台Redis的服务器就应付不过来了,而且数据量太大意味着持久化成本高,严重时可能会阻塞服务器,造成服务请求成功率下降,降低服务的稳定性 。针对以上的问题,Redis集群提供了较为完善的方案,解决了存储能力受到单机限制,写操作无法负载均衡的问题。 集群中有多个master,每个master保存不同数据 。 每个master都可以有多个slave节点。 master之间通过ping监测彼此健康状态。 客户端请求可以访问集群任意节点,最终都会被转发到正确节点 。 无中心架构,支持动态扩容 。 数据按照slot存储分布在多个节点,节点间数据共享,可动态调整数据分布 ; 高可用性 。部分节点不可用时,集群仍可用。集群模式能够实现自动故障转移(failover),节点之间通过gossip协议交换状态信息,用投票机制完成Slave到Master的角色转换。不支持批量操作(pipeline)。 数据通过异步复制,不保证数据的强一致性 。可能导致写丢失。 事务操作支持有限,只支持多key在同一节点上的事务操作,当多个key分布于不同的节点上时无法使用事务功能。 key作为数据分区的最小粒度,不能将一个很大的键值对象如hash、list等映射到不同的节点。 不支持多数据库空间,单机下的Redis可以支持到16个数据库,集群模式下只能使用1个数据库空间。 只能使用0号数据库。 在Redis集群里面,又会划分出分区的概念,一个集群中可有多个分区。分区有几个特点:
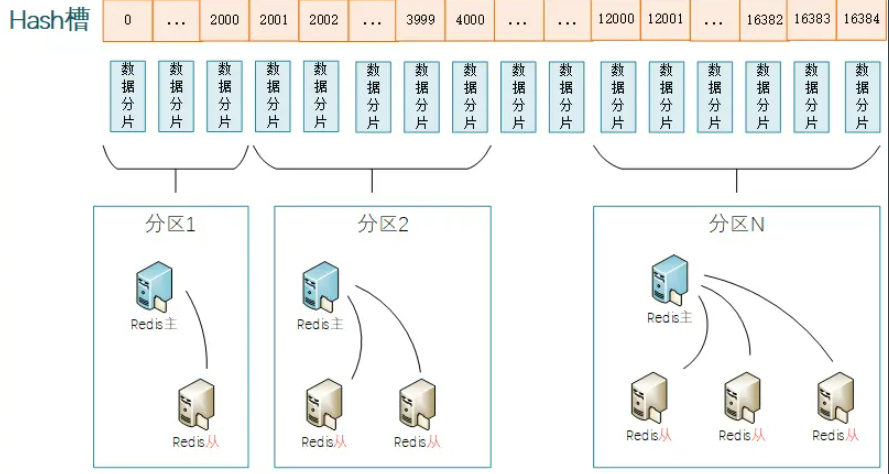
同一个分区内的Redis节点之间的数据完全一样,多个节点保证了数据有多份副本冗余保存,且可以提供高可用保障。 不同分片之间的数据不相同。 通过水平增加多个分片的方式,可以实现整体集群的容量的扩展。 按照Cluster模式进行部署的时候,要求最少需要部署6个Redis节点(3个分片,每个分片中1主1从),其中集群中每个分片的master节点负责对外提供读写操作,slave节点则作为故障转移使用 (master出现故障的时候充当新的master)、对外提供只读请求处理。这一点跟Redis主从复制下读写分离不一样,因为redis集群的核心的理念,主要是使用slave做数据的热备,以及master故障时的主备切换,实现高可用的。 Redis会把master节点映射到0~16383共16384个插槽(hashslot)上。不同的插槽分布在不同的Redis节点上面进行管理,也就是说每个Redis节点只负责一部分的哈希槽。 数据key不是与节点绑定,而是与插槽绑定。redis会根据key的有效部分计算插槽值,分两种情况:
key中包含"{}“,且”{}“中至少包含1个字符,”{}"中的部分是有效部分。 key中不包含"{}",整个key都是有效部分。 例如:key是num,那么就根据num计算,如果是{itcast}num,则根据itcast计算。计算方式是利用CRC16算法得到一个hash值,然后对16384取余,得到的结果就是slot值。 使用哈希槽的好处就在于可以方便的添加或者移除节点,并且无论是添加删除或者修改某一个节点,都不会造成集群不可用的状态。 网络通信效率角度:集群节点通过心跳包(Gossip 协议)交换彼此的槽分配信息,每个心跳包需携带当前节点负责的槽位信息。槽位信息用位图(bitmap)表示:16384 个槽对应 16384 bits = 2048 bytes(约 2KB)。若槽数为 65536(2^16),位图将占用 8192 bytes(约 8KB)。更小的位图降低了网络带宽消耗,同时避免因心跳包过大导致的延迟和性能问题 。 CRC16 算法角度:CRC16 的结果范围是 0-65535,理论上支持最大 65536 个槽。选择 16384而非 65536的考量:
数据分布均匀性:16384 个槽已足够将数据均匀分布到上千个节点。 内存开销:每个节点需维护所有槽的路由信息,16384 的规模在内存占用和扩展性之间平衡。 16384个插槽可以确保每个master节点都有足够的插槽,同时也可以保证插槽数目不会过多或过少,从而保证了Redis Cluster的稳定性和高性能。 启动新节点。 需要在集群中任意节点执行cluster meet命令将新节点加入到集群。 迁移槽以及数据:添加新节点后,需要将一些槽和数据从旧节点迁移到新节点。 迁移槽:为了安全删除节点,Redis集群只能下线没有负责槽的节点。因此如果要下线有负责槽的master节点,则需要先将它负责的槽迁移到其他节点。 忘记节点:通过命令 cluster forget {downNodeId} 通知其他的节点。 Redis集群的故障检测是基于gossip协议的,集群中的每个节点都会定期地向集群中的其他节点发送PING消息,以此交换各个节点状态信息,检测各个节点状态:在线状态、疑似下线状态PFAIL、已下线状态FAIL。 当故障节点下线后,如果是持有槽的主节点则需要在其从节点中找出一个替换它,从而保证高可用。此时下线主节点的所有从节点都担负着恢复义务,这些从节点会定时监测主节点是否进入客观下线状态,如果是,则触发故障恢复流程。故障恢复也就是选举一个节点充当新的master,选举的过程是基于Raft协议选举方式来实现的。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处:http://www.coloradmin.cn/o/2387008.html
如若内容造成侵权/违法违规/事实不符,请联系多彩编程网进行投诉反馈,一经查实,立即删除!

![[IMX] 08.RTC 时钟](https://i-blog.csdnimg.cn/direct/cf1619e0a2e64d79a8eb275406dc669e.png)