ElasticSearch
DSL查询文档

分类

| 查询类型 | 功能描述 | 典型应用场景 | 示例语法 |
|---|---|---|---|
| 查询所有 | 匹配所有文档,无过滤条件 | 数据预览/测试 | json { "query": { "match_all": {} } } |
| 全文检索查询 | 对文本字段分词后匹配,基于倒排索引 | 搜索框模糊匹配、多字段搜索 | json { "query": { "match": { "title": "Elasticsearch指南" } } } |
| 精确查询 | 直接匹配未经分词的字段值(keyword/数值/日期等) | 状态过滤、范围筛选、精确ID查询 | json { "query": { "term": { "status": "published" } } } |
| 地理查询 | 基于经纬度的空间位置计算 | 附近地点搜索、地理围栏 | json { "query": { "geo_distance": { "distance": "10km", "location": "40,-70" } } } |
| 复合查询 | 组合多个查询条件,支持逻辑运算和自定义评分 | 复杂业务场景(权重排序、多条件过滤) | json { "query": { "bool": { "must": [ { "term": { "category": "tech" } } ] } } } |

match_all---匹配所有文档
match_all查询是一个特殊的查询类型,它用于匹配索引中的所有文档,而不考虑任何特定的查询条件。
基本语法:
GET /<your-index-name>/_search
{
"query": {
"match_all": {}
}
}
高级用法
您可以在matchall查询中添加额外的参数来控制搜索结果的显示,例如设置返回的文档数量(size)、开始返回的文档位置(from)、排序规则(sort)以及选择返回哪些字段(source)。
-
size返回指定条数
size 关键字: 指定查询结果中返回指定条数。 默认返回值10条
GET /employee/_search
{
"query": {
"match_all": {}
},
"size": 3
}
-
from&size分页查询
size:显示应该返回的结果数量,默认是 10 from:显示应该跳过的初始结果数量,默认是 0 from 关键字用来指定起始返回位置,和size关键字连用可实现分页效果
GET /employee/_search
{
"query": {
"match_all": {}
},
"from": 0,
"size": 5
}
-
sort指定字段排序
指定查询结果的排序方式,是根据什么进行排序的
# 根据age排序
GET /employee/_search
{
"query": {
"match_all": {}
},
"sort": [
{
"age": "desc"
}
]
}
# 排序的同时进行分页
GET /employee/_search
{
"query": {
"match_all": {}
},
"sort": [
{
"age": "desc"
}
],
"from": 2,
"size": 5
}-
_source返回源数据
指定查询之后返回的字段,定向显示需要的字段与屏蔽不需要的字段
GET /employee/_search
{
"query": {
"match_all": {}
},
"_source": ["name","address"]
}
精确匹配
精确匹配是指的是搜索内容不经过文本分析直接用于文本匹配,这个过程类似于数据库的SQL查询,搜索的对象大多是索引的非text类型字段。此类检索主要应用于结构化数据,如ID、状态和标签等。主要介绍一下term与terms、range的查询方式,因为使用的频率比较高。还有一些其它的精确匹配的类型在这里就不详细展开说明,在前面文章里面的脑图链接中有说明可以进行了解。
基本语法
①term查询
在Elasticsearch 8.x中,term查询用于执行精确匹配查询,它适用于未经过分词处理的keyword字段类型。
GET /{index_name}/_search
{
"query": {
"term": {
"{field.keyword}": {
"value": "your_exact_value"
}
}
}
}
这里的{index_name}是你要查询的索引名称,{field.keyword}是你要匹配的字段名称,.keyword后缀表示该字段是一个keyword类型,用于存储精确匹配的数据。"value"是你要精确匹配的值
②terms查询
在Elasticsearch 8.x中,进行多值精确匹配时,可以使用terms查询。terms查询允许你指定一个字段,并匹配该字段中的多个精确值
GET /<index_name>/_search
{
"query": {
"terms": {
"<field_name>": [
"value1",
"value2",
"value3",
...
]
}
}
}
-
<index_name> 是你想要查询的索引名称。
-
<field_name> 是你想要对其执行terms查询的字段名。
-
方括号内的值列表是你希望在查询中匹配的字段值
③range查询
在Elasticsearch 8.x中,进行精确范围查询时,可以使用range查询。
GET /<index_name>/_search
{
"query": {
"range": {
"<field_name>": {
"gte": <lower_bound>,
"lte": <upper_bound>,
"gt": <greater_than_bound>,
"lt": <less_than_bound>
}
}
}
}
-
<index_name> 是你想要查询的索引名称。
-
<field_name> 是你想要对其执行range查询的字段名。
-
gte 表示大于或等于(Greater Than or Equal)。
-
lte 表示小于或等于(Less Than or Equal)。
-
gt 表示严格大于(Greater Than)。
-
lt 表示严格小于(Less Than)。
-
<lower_bound>, <upper_bound>, <greater_than_bound>, <less_than_bound> 是指定的数值边界。
全文检索
全文检索查询旨在基于相关性搜索和匹配文本数据。这些查询会对输入的文本进行分析,将其拆分为词项(单个单词),并执行诸如分词、词干处理和标准化等操作。此类检索主要应用于非结构化文本数据,如文章和评论等。主要介绍一下match与multi_match的查询方式,因为使用的频率比较高。还有一些其它的全文检索类型在这里就不详细展开说明,在前面文章里面的脑图链接中有说明可以进行了解。
全文检索的关键特点:
-
对输入的文本进行分析,并根据分析后的词项进行搜索和匹配。全文检索查询会对输入的文本进行分析,将其拆分为词项,并基于这些词项进行搜索和匹配操作。
-
以相关性为基础进行搜索和匹配。全文检索查询使用相关性算法来确定文档与查询的匹配程度,并按照相关性进行排序。相关性可以基于词项的频率、权重和其他因素来计算。
-
全文检索查询适用于包含自由文本数据的字段,例如文档的内容、文章的正文或产品描述等。
基本语法
①match查询
//match查询(跟据一个字段查询)
GET /<index_name>/_search
{
"query": {
"match": {
"<field_name>": "<query_string>"
}
}
}
<index_name> 是你要搜索的索引名称。 <query_string> 是你要在多个字段中搜索的字符串。 <field1>, <field2>, ... 是你要搜索的字段列表。
②multi_match查询
//multi_match查询(跟据多个字段查询,字段越多查询效率越差)
GET /<index_name>/_search
{
"query": {
"multi_match": {
"query": "<query_string>",
"fields": ["<field1>", "<field2>", ...]
}
}
}
<index_name> 是你要搜索的索引名称。 <query_string> 是你要在多个字段中搜索的字符串。 <field1>, <field2>, ... 是你要搜索的字段列表
Boolean查询
-
搜索上下文(Query Context):使用搜索上下文时,ElasticSearch需要计算每个文档与搜索条件的相关度得分,这个得分的计算需要使用一套复杂的计算公式,有一定的性能开销,带文本分析的全文检索的查询语句很适合放在搜索上下文中
-
过滤上下文(Filter Context):使用过滤上下文时,ElasticSearch只需要判断搜索条件根文档数据是否匹配。过滤上下文的查询不需要进行相关度得分计算,还可以使用缓存加快响应的速度,很多术语级查询语句都适合放在过滤上下文中
| 特性 | 搜索上下文(Query Context) | 过滤上下文(Filter Context) |
|---|---|---|
| 作用 | 计算文档相关性得分,影响排序结果 | 判断文档是否匹配条件,不计算得分 |
| 性能 | 计算成本较高(需计算相关性) | 高效(结果可缓存,无需计算得分) |
| 典型使用场景 | 全文检索、模糊匹配、需要结果排序的场景 | 精确筛选(状态过滤、范围查询)、高频重复条件过滤 |
| 语法位置 | query 参数内(如 bool.must、bool.should) | filter 参数内(如 bool.filter、bool.must_not) |
| 缓存机制 | 不缓存结果 | 自动缓存结果(提升重复查询性能) |

//must关键词
GET /books/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"title": "java编程"
}
},{
"match": {
"description": "性能优化"
}
}
]
}
}
}
//should关键词
GET /books/_search
{
"query": {
"bool": {
"should": [
{
"match": {
"title": "java编程"
}
},{
"match": {
"description": "性能优化"
}
}
],
"minimum_should_match": 1
}
}
}
//filter关键词
GET /books/_search
{
"query": {
"bool": {
"filter": [
{
"term": {
"language": "java"
}
},
{
"range": {
"publish_time": {
"gte": "2010-08-01"
}
}
}
]
}
}
}地理查询
地理查询旨在跟据用户给出的地理位置信息来查询附近的目标资源的信息以及数量
基本语法
-
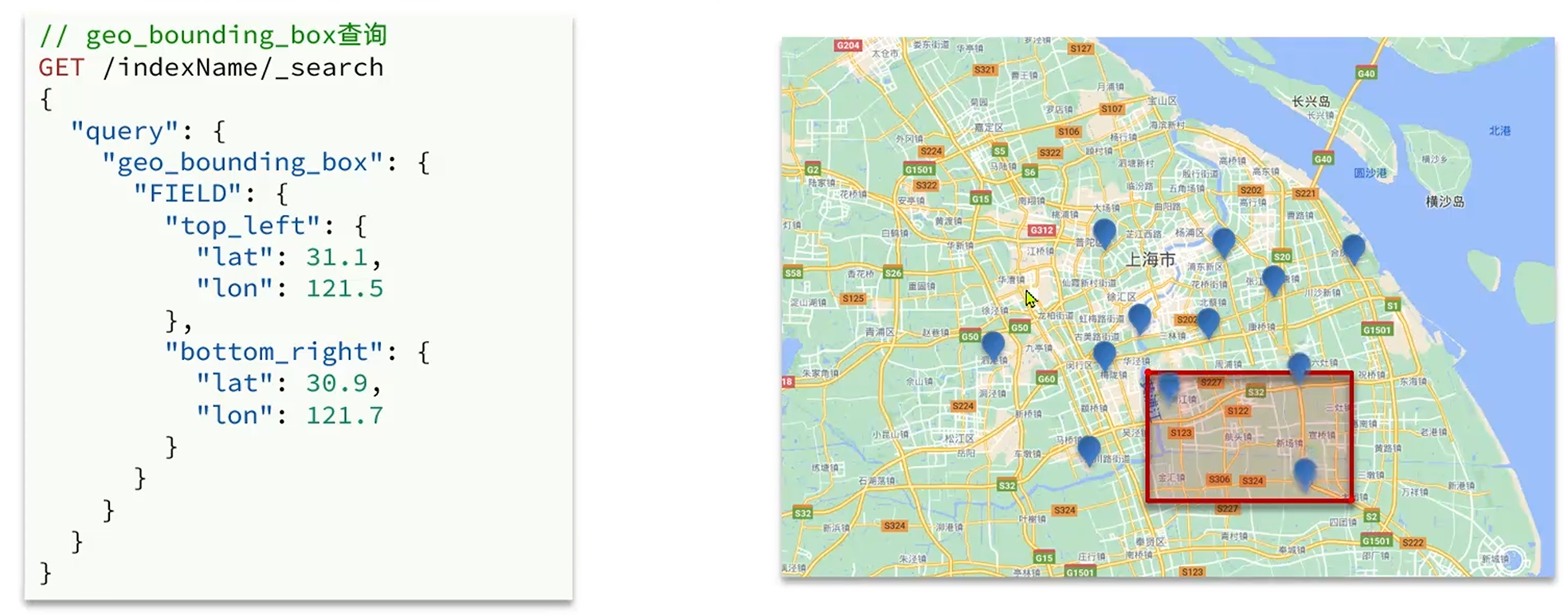
geo_bounding_box查询
查询地理坐标在框定的正方形区域内的目标资源,跟据左上经纬度(top_left)和右下经纬度(bottom_right)来构建区域方型,进而确定资源
-
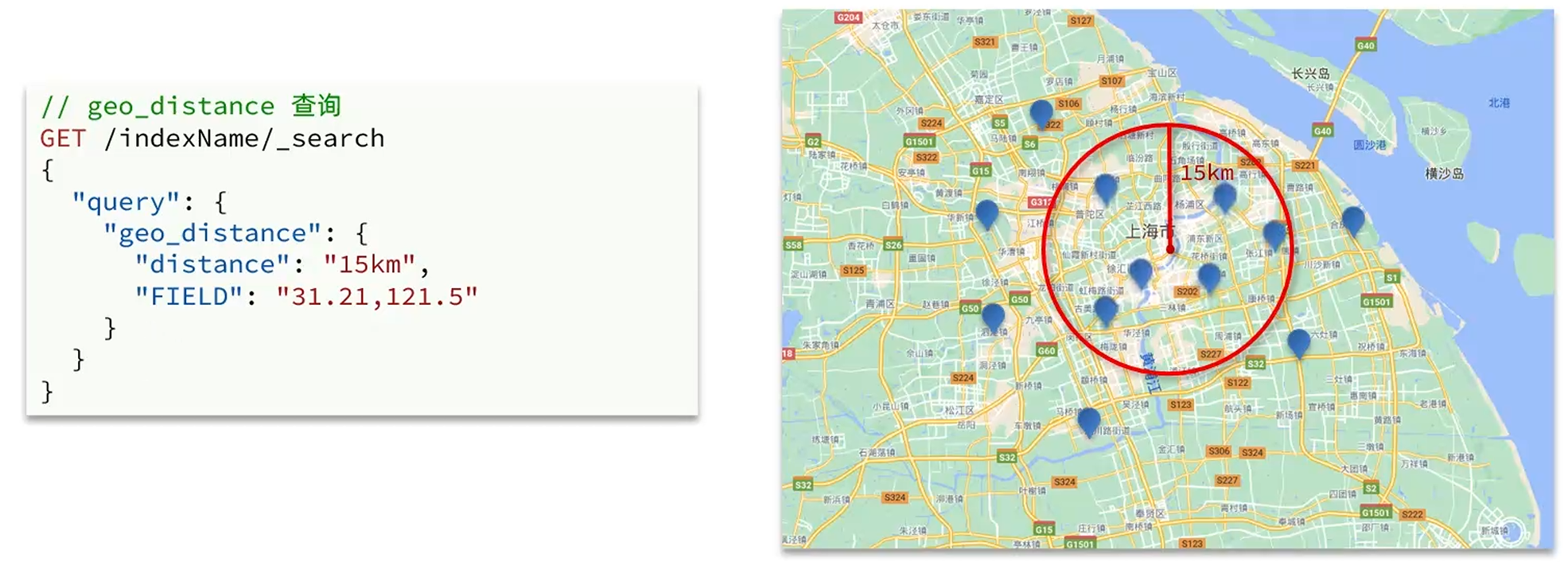
geo_distance查询
查询以目标位置为圆心,指定路径为半径的圆形区域内的目标资源的信息
高亮显示
Elasticsearch 的高亮显示功能允许在搜索结果中突出显示匹配的关键词或短语,帮助用户快速定位相关信息。
GET /hotel/_search
{
"query":{
"搜索方式":{
"字段名":"搜索内容"
}
},
"highlight":{
"fields":{
"字段名":{
"pre_tags":"<em>", //用来标记高亮字段的前置标签
"post_tags":"</em>" //用来标记高亮字段的后置标签
},
"字段名2":{
"pre_tags":"<em>", //用来标记高亮字段的前置标签
"post_tags":"</em>", //用来标记高亮字段的后置标签
"require_field_match":"false"
}
}
}
}
示例演示
//使用自定义高亮显示来标识(可以)
GET /products/_search
{
"query": {
"multi_match": {
"fields": ["name","desc"],
"query": "牛仔"
}
},
"highlight": {
"post_tags": ["</span>"],
"pre_tags": ["<span style='color:red'>"],
"fields": {
"*":{}
}
}
}
//多字段高亮配置
GET /products/_search
{
"query": {
"term": {
"name": {
"value": "牛仔"
}
}
},
"highlight": {
"pre_tags": ["<font color='red'>"],
"post_tags": ["<font/>"],
"require_field_match": "false",
"fields": {
"name": {},
"desc": {}
}
}
}相关参数说明:
-
highlight 关键字: 可以让符合条件的文档中的关键词高亮。
-
highlight相关属性:
-
pre_tags 前缀标签
-
post_tags 后缀标签
-
tags_schema 设置为styled可以使用内置高亮样式
-
require_field_match 多字段高亮需要设置为false
ES向量检索

核心特性
-
向量数据类型
-
dense_vector:支持浮点数密集向量(如BERT、ResNet生成的向量)。 -
sparse_vector(实验性):支持稀疏向量(如TF-IDF高维稀疏表示)。
-
-
近似最近邻搜索(ANN)
-
基于 HNSW(Hierarchical Navigable Small World) 算法,平衡精度与性能。
-
支持 欧氏距离(l2)、余弦相似度(cosine)、点积(dot_product) 等相似度计算方式。
-
-
性能优化
-
支持 量化(Quantization) 减少存储占用(如int8量化)。
-
通过 段合并优化(Force Merge) 提升检索速度。
-
-
混合检索
-
结合传统全文检索(BM25)与向量检索,实现多模态搜索。
-

搜索相关性
概念:在搜索引擎中描述一个文档与查询语句匹配程度的度量标准。
ElasticSearch 5之前的版本评分机制,或者打分模型是基于TF_IDF实现的。从ElasticSearch 5之后默认的打分机制改成了Okapi BM25。
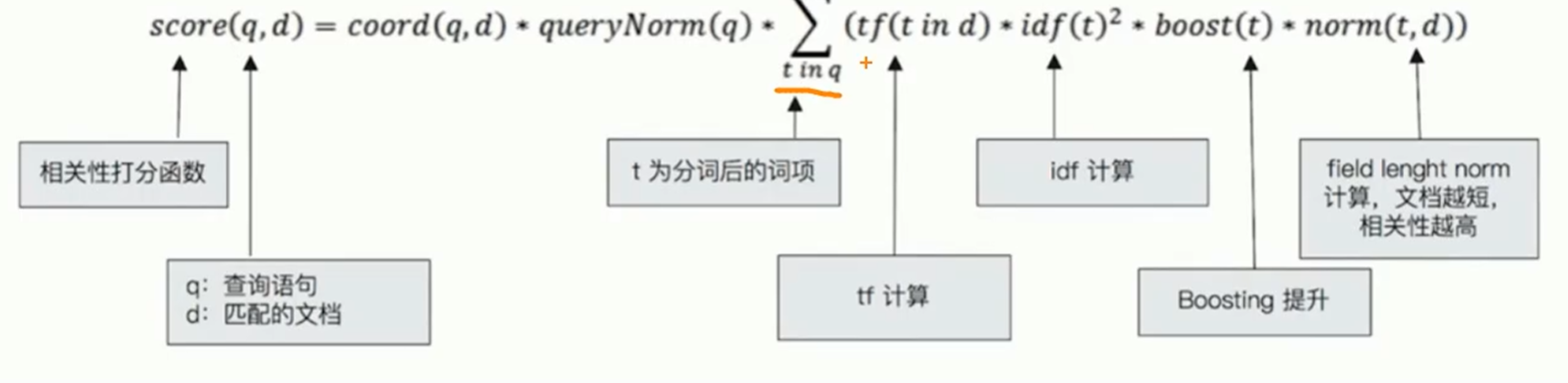
TF_IDF算法:
-
TF是词频:检索词在文档中出现的频率越高,相关性也就越高
-
IDF是逆向文本频率:每个检索词在索引中出现的频率,频率越高,相关性就越低。
-
字段长度归一值:检索词出现在一个内容短的title要比同样的词出现在一个内容长的content字段权重更大
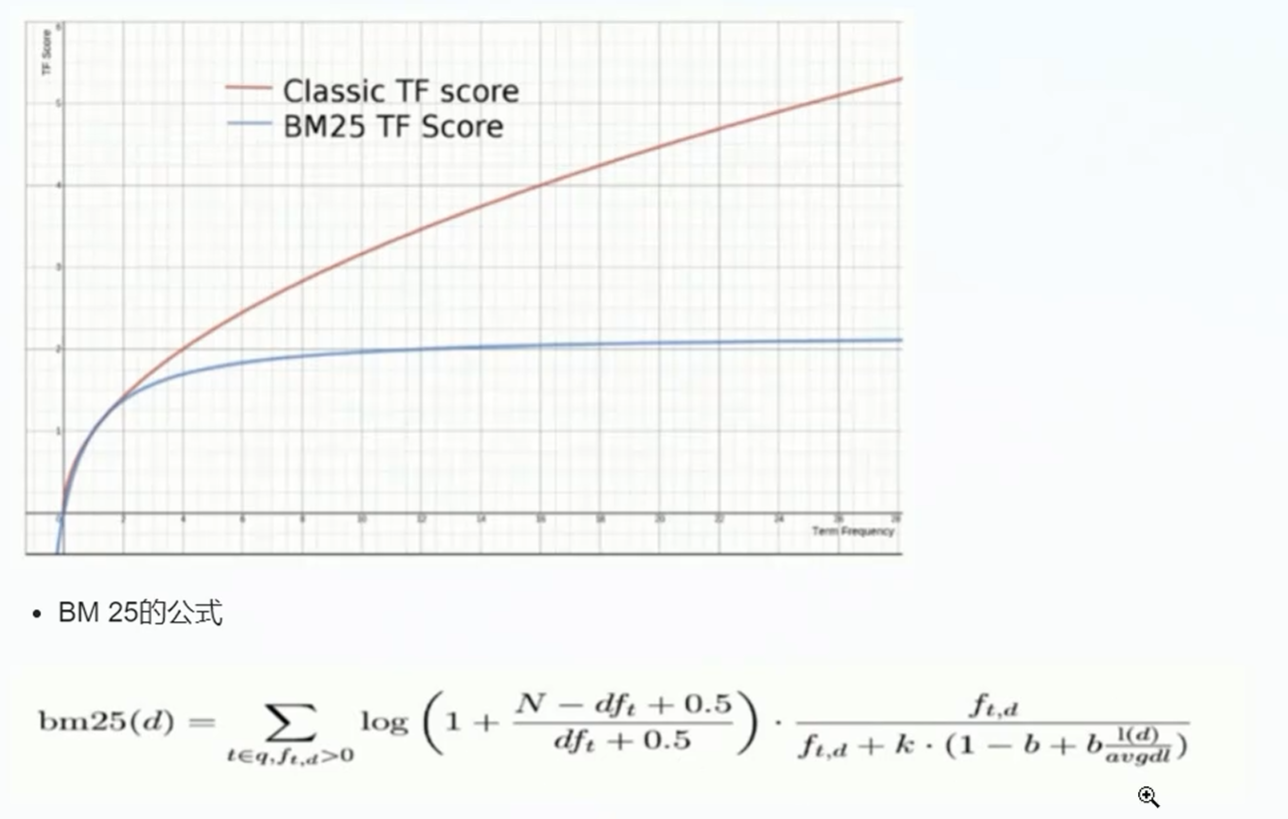
BM 25算法:
和经典的TF_IDF的算法比较起来,当TF无限增加时,BM 25算分会趋近于一个数值
自定义评分策略

Index Boost(索引级权重)
作用:提升指定索引的文档相关性,适用于跨索引搜索。
GET /index1,index2/_search
{
"indices_boost": [
{ "index1": 1.5 }, // index1的文档相关性提升50%
{ "index2": 0.8 } // index2的文档相关性降低20%
],
"query": { "match_all": {} }
}
Boosting Query(条件权重)
作用:提升或降低匹配特定条件的文档评分。
GET /products/_search
{
"query": {
"boosting": {
"positive": { "match": { "title": "手机" } }, // 匹配的文档基础评分
"negative": { "term": { "brand": "A" } }, // 匹配此条件的文档降权
"negative_boost": 0.2 // 负向权重系数(原评分 × 0.2)
}
}
}
Function Score(自定义评分)
作用:通过函数动态计算文档评分,支持多种评分函数组合。
GET /articles/_search
{
"query": {
"function_score": {
"query": { "match": { "content": "AI" } }, // 基础查询
"functions": [
{
"filter": { "term": { "category": "tech" } }, // 过滤条件
"weight": 2 // 符合条件文档评分 ×2
},
{
"field_value_factor": { // 字段值影响评分
"field": "views",
"modifier": "log1p",
"factor": 0.1
}
}
],
"boost_mode": "multiply" // 评分计算方式(默认sum)
}
}
}
Rescore Query(二次评分)
作用:对初始查询结果进行二次评分,优化性能。
GET /logs/_search
{
"query": { "match": { "message": "error" } },
"rescore": {
"window_size": 50, // 对前50个结果二次评分
"query": {
"rescore_query": {
"function_score": {
"query": { "match_all": {} },
"script_score": {
"script": "_score * doc['severity'].value" // 根据严重程度调整评分
}
}
}
}
}
}
总结:
| 方法 | 适用场景 | 性能影响 | 灵活性 |
|---|---|---|---|
| Index Boost | 多索引搜索时优先级控制 | 低 | 低 |
| Boosting Query | 简单条件降权(如排除低质量内容) | 中 | 中 |
| Function Score | 复杂评分逻辑(如热度、点击率加权) | 高 | 高 |
| Rescore Query | 分页后优化Top N结果(如精细化排序) | 可控 | 中 |
多字段查询优化
最佳字段搜索
-
最佳字段(Best Fields):在多个字段中返回评分最高的
-
多数字段(Most Fields):匹配多个字段,返回各个字段评分之和
-
混合字段(Cross Fields):跨字段匹配,待查询内容在多个字段中都显示
最佳字段(Best Fields)
核心逻辑
-
评分机制:从所有匹配字段中取 最高评分 作为文档最终评分。
-
适用场景:关键词集中在单一字段(如商品标题优先于描述)。
-
默认类型:
multi_match的默认策略即为best_fields。
//语法示例
GET /products/_search
{
"query": {
"multi_match": {
"query": "无线蓝牙耳机",
"fields": ["title^3", "description"], // title权重提升3倍
"type": "best_fields",
"tie_breaker": 0.3 // 其他字段评分的30%加入总分。平衡因子
}
}
}
多数字段(Most Fields)
核心逻辑
-
评分机制:将 所有匹配字段的评分累加 作为文档最终评分。
-
适用场景:关键词分散在多个字段(如标题和描述均含部分关键词)。
GET /articles/_search
{
"query": {
"multi_match": {
"query": "机器学习框架",
"fields": ["title", "content", "tags"],
"type": "most_fields", // 合并所有字段评分
"minimum_should_match": "50%" // 至少匹配50%词项
}
}
}
混合字段(Cross Fields)
核心逻辑
-
评分机制:将多个字段视为 一个整体字段,要求所有词项在 任意字段组合 中匹配。
-
适用场景:跨字段严格匹配(如地址:省+市+街道需完整匹配)。
GET /users/_search
{
"query": {
"multi_match": {
"query": "张三 杭州 西湖区",
"fields": ["province", "city", "district"],
"type": "cross_fields", // 所有词项需在任意字段中覆盖
"operator": "AND" // 必须匹配所有词项
}
}
}
| 维度 | Best Fields | Most Fields | Cross Fields |
|---|---|---|---|
| 评分重点 | 单字段最佳匹配 | 多字段累计贡献 | 跨字段联合覆盖 |
| 适用场景 | 核心字段优先级高(如标题) | 多字段互补(如标题+描述) | 严格跨字段匹配(如姓名+地址) |
| 性能开销 | 低 | 中 | 高(需跨字段验证) |
| 典型参数 | tie_breaker | minimum_should_match | operator(需设为AND) |
聚合
简介:聚合(Aggregation) 是数据处理中的一种核心操作,指将多行数据合并为单个统计值的过程。它常用于对数据集进行汇总分析。
-
桶(Bucket)聚合:用来对文档做分组
-
TermAggregation:按照文档字段值进行分组
-
Date Histogram:按照日期阶梯进行分组。如一周为一组,一月为一组
-
-
度量(Metric)聚合:用于计算一些值,比如:最大值、最小值、平均值等
-
Avg:求平均值
-
Max:求最大值
-
Min:求最小值
-
Stats:同时求max、min、avg、sum等
-
-
管道(Pipeline)聚合:其它聚合的结果为基础做聚合,类比于嵌套聚合
-
Derivative(导数聚合):计算相邻分桶的差值。
-
Moving Average(移动平均):计算滑动窗口内的平均值。
-
Bucket Script(自定义脚本):用脚本处理多个聚合结果。
-
桶(Bucket)聚合

//按照文档字段进行分组检索
{
"aggs": {
"group_by_field": {
"terms": { "field": "字段名" }
}
}
}//按照日期进行分组检索
{
"aggs": {
"group_by_date": {
"date_histogram": {
"field": "日期字段",
"calendar_interval": "1d" // 间隔:1天、1M、1y 等
}
}
}
}
度量(Metric)聚合

{
"aggs": {
"metric_name": { "avg": { "field": "数值字段" } }
}
}
管道(Pipeline)聚合
// 先按日期分桶,再计算每月销售额的月环比增长率
GET /sales/_search
{
"size": 0,
"aggs": {
"sales_per_month": {
"date_histogram": { "field": "date", "calendar_interval": "1M" },
"aggs": {
"total_sales": { "sum": { "field": "amount" } },
"monthly_growth": {
"derivative": { "buckets_path": "total_sales" } // 导数聚合
}
}
}
}
}