强化练习1 神经网络训练案例(SG)
#划分数据集 #以下5行需要背
folder = datasets.ImageFolder(root='C:/水果种类智能训练/水果图片', transform=trans_compose)
n = len(folder)
n1 = int(n*0.8)
n2 = n-n1
train, test = random_split(folder, [n1, n2])#训练并保存模型
import torchmetrics
lossf = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=0.01)
metricsf = torchmetrics.Accuracy(task='multiclass', num_classes=len(folder.classes))
for i in range(1):
for batchX, batchY in data_loader:
#以下17行需要背 中文是对应题目的要求可以不背
device = torch.device("cpu")
batchX = batchX.to(device)
batchY = batchY.to(device)
model = model.to(device)
# 清零梯度
optimizer.zero_grad()
# 前向传播
outputs = model(batchX)
# 计算损失
loss = lossf(outputs, batchY)
# 反向传播
loss.backward()
# 更新参数
optimizer.step()
# 计算准确率
preds = torch.argmax(outputs, dim=1)
metricsf.update(preds, batchY)
# 每个 epoch 结束后打印损失和准确率
epoch_loss = loss.item()
epoch_accuracy = metricsf.compute()
print(f'Epoch {i + 1}, Loss: {epoch_loss:.4f}, Accuracy: {epoch_accuracy:.4f}')
# 重置评估指标
metricsf.reset()
torch.save(model.state_dict(), '2-2model_test.pth')
print("模型已保存为 2-2model_test.pth")强化练习2 简答题
数据采集培训大纲(以下为参考,自己要修改,与下面一致的会造成雷同)
- 基础认知:明晰数据采集概念、重要性与应用场景。
- 方法技巧:讲授多种采集方式,涵盖网络、传感器等,分享实操窍门。
- 工具运用:熟练掌握 Excel、Python 等工具用于数据获取与整理。
常见问题及解决方法(选2条背)
- 目标不明确
- 问题:未清晰界定采集数据的用途与范围,导致收集大量无关数据,遗漏关键信息。比如市场调研时,不清楚要分析用户哪类消费行为,盲目收集。
- 解决方法:项目启动前,组织跨部门会议,与业务、分析团队深入沟通,基于业务需求和分析目的,详细梳理数据需求清单,明确数据用途、范围、字段及预期成果。
- 样本偏差
- 问题:选取样本缺乏代表性,如调查城市居民出行方式,仅在高档社区采样,无法反映整体情况。
- 解决方法:运用科学抽样方法,像分层抽样,按城市区域、收入水平等分层后随机抽取;扩大样本覆盖范围,涵盖不同特征群体,必要时用统计方法评估样本代表性。
- 数据来源不可靠
- 问题:采用劣质数据源,像某些非官方网站数据,可能存在错误、过时或被篡改,影响数据质量。
- 解决方法:优先选用官方机构、权威数据库等可靠数据源;对新数据源,先小范围验证数据准确性,对比多个来源数据,分析差异。
强化练习3 人工智能系统设计
def __init__(self):
super(MyNet, self).__init__()
self.fc1 = nn.Linear(14, 128)
self.bn1 = nn.BatchNorm1d(128)
self.relu = nn.ReLU()
# 第二层
self.fc2 = nn.Linear(128, 256)
self.bn2 = nn.BatchNorm1d(256)
self.relu = nn.ReLU()
# 第三层
self.fc3 = nn.Linear(256, 2)
def forward(self, x):
x = self.fc1(x)
x = self.bn1(x)
x = self.relu(x)
x = self.fc2(x)
x = self.bn2(x)
x = self.relu(x)
out = self.fc3(x)
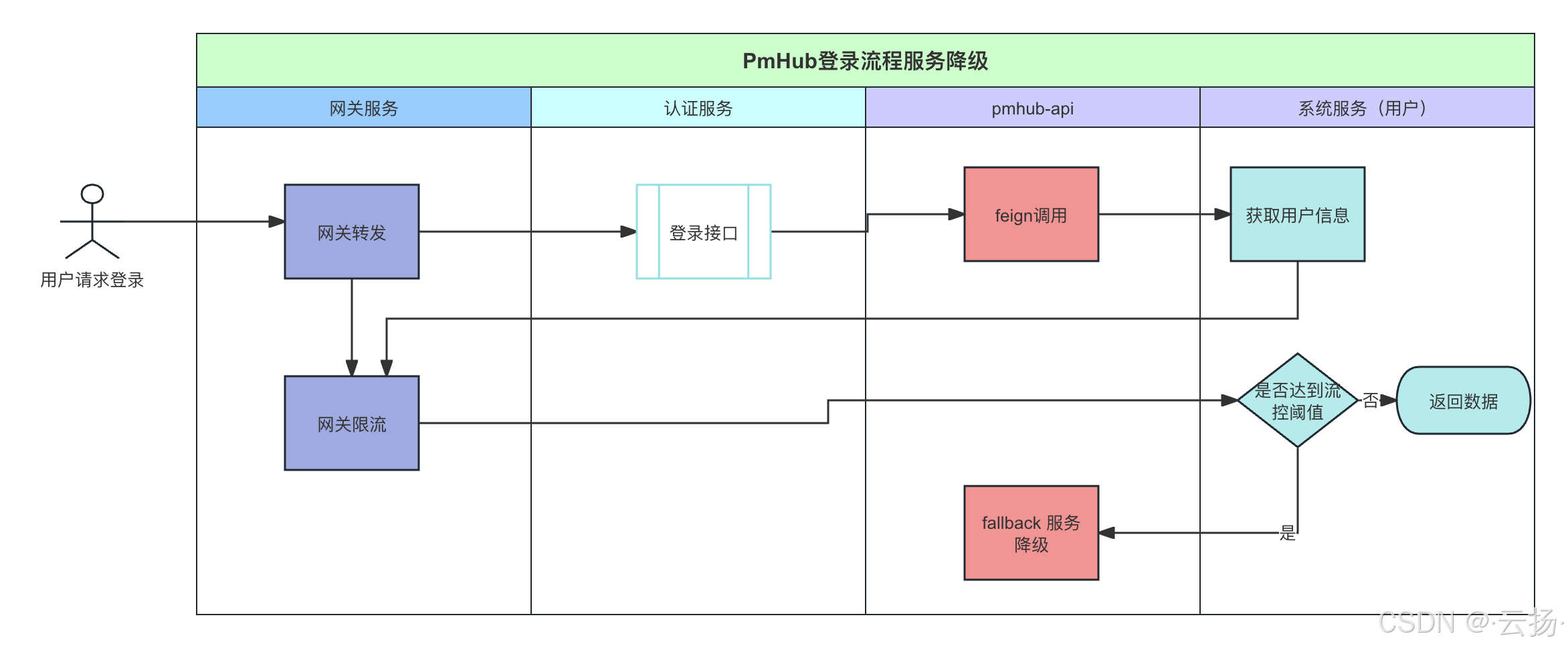
return out流程图:
读取XX数据
检查数据是否正确
是
数据清洗
数据分析处理
模型加载
根据模型进行推理
输出响应结果
结束
强化练习4 gs程序分析
三种网络爬虫的主要搜索策略及特点
广度优先 (BFS)
特点:通用搜索引擎、大规模抓取
优点:覆盖广、避免陷入深层结构、并行友好
缺点:可能抓取较多低质量页面
深度优先 (DFS)
特点:静态网站、专题爬取
优点:可快速深入特定分支
缺点:易陷入循环、覆盖效率低
最佳优先
特点:聚焦爬虫、垂直搜索引擎
优点:高效获取高价值页面
缺点:计算复杂、可能遗漏相关页面流程图完善
- (a)处:判断文件是否为图像文件(可通过文件扩展名判断是否为常见图像格式,如.png、.jpg 等 )。
- (b)处:判断图像文件是否为
.png格式。(tif根据题目要求改) - (c)处:判断图像文件分辨率是否为
x x y(根据题目要求改) 。
问题及改善(此题用自己的话回答 不能直接照抄下面的)
问题:严格按格式和分辨率筛,会丢有用图像致数据不足,且仅靠扩展名判格式易误筛。
改进:使用Opencv库进行图像处理
for filename in os.listdir(input_folder):# 遍历输入文件夹中的所有文件
if filename.lower().endwith('png'):
image_path = os.path.join(input_folder, filename)
with Image.open(image_path) as img:
if img.size != (100, 100)
continue
output_path = os.path.join(output_folder, filename)
img.save(output_path)
print('处理完毕')