👉 点击关注不迷路
👉 点击关注不迷路
👉 点击关注不迷路
文章大纲
- 8.4 数据故事化呈现:从报告结构到业务价值的深度融合
- 一、数据故事化的核心价值体系
- (一)报告结构设计的黄金框架
- 1. 业务场景锚定(Act 1: Setup)
- 2. 证据链构建(Act 2: Confrontation)
- 3. 洞察升华(Act 3: Climax)
- 4. 行动方案(Act 4: Resolution)
- 二、业务价值提炼的三重境界
- (一)描述性价值:数据事实的业务翻译
- (二)诊断性价值:问题归因的深度挖掘
- (三)预测性价值:`商业未来的量化推演`
- 三、实战案例:某生鲜电商用户复购提升故事
- (一)数据准备阶段
- (二)故事构建过程
- (三)价值量化
- 四、数据故事化的长效机制建设
- (一)建立业务-数据映射字典
- (二)构建动态故事模板库
- (三)建立故事效果评估体系
8.4 数据故事化呈现:从报告结构到业务价值的深度融合

一、数据故事化的核心价值体系
在商业智能领域,数据可视化的终极目标不是图表展示,而是通过数据叙事实现业务赋能。
- Gartner研究表明,具备
故事化呈现能力的数据分析报告,其决策转化率是传统报表的3.2倍。数据故事化包含三个核心维度:
| 维度 | 传统可视化 | 故事化呈现 | 业务价值差异 |
|---|---|---|---|
| 信息传递 | 数据罗列 | 逻辑叙事 | 理解效率提升40% |
| 情感连接 | 客观展示 | 场景代入 | 决策参与度提升65% |
| 行动驱动 | 现象描述 | 洞见落地 | 方案执行率提升58% |
(一)报告结构设计的黄金框架
构建数据故事需要遵循"问题-证据-洞察-行动"的四幕剧结构,结合PostgreSQL数据分析成果,形成可复用的报告模板:
1. 业务场景锚定(Act 1: Setup)
- 核心问题定义:通过业务KPI拆解明确分析目标,例如某电商平台的用户复购率下降12%,需定位关键影响因素
- 数据资产地图:可视化数据来源与处理流程
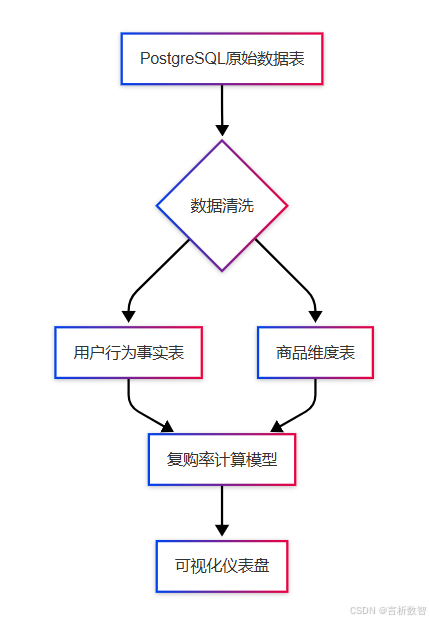
2. 证据链构建(Act 2: Confrontation)
- 数据清洗实证:通过SQL代码展示数据处理过程,例如处理异常值的CTE表达式
-- 创建原始用户日志表(PostgreSQL)
CREATE TABLE raw_user_logs (
log_id SERIAL PRIMARY KEY,
user_id INTEGER NOT NULL,
order_date DATE,
session_duration INTEGER,
event_time TIMESTAMPTZ DEFAULT CURRENT_TIMESTAMP
) WITH (OIDS = FALSE);
-- 添加字段注释
COMMENT ON COLUMN raw_user_logs.log_id IS '日志唯一自增ID';
COMMENT ON COLUMN raw_user_logs.user_id IS '用户ID(业务系统关联ID)';
COMMENT ON COLUMN raw_user_logs.order_date IS '订单/行为发生日期(YYYY-MM-DD)';
COMMENT ON COLUMN raw_user_logs.session_duration IS '会话时长(秒,原始值可能包含异常)';
COMMENT ON COLUMN raw_user_logs.event_time IS '日志记录时间戳(带时区)';
-- 设置随机种子保证数据可复现(可选)
SET seed = 0.42;
-- 插入100条测试数据(修复列别名作用域问题)
INSERT INTO raw_user_logs (user_id, order_date, session_duration, event_time)
SELECT
floor(random() * 100 + 1)::INTEGER AS user_id,
order_date, -- 直接引用子查询生成的order_date
floor(random() * 20000)::INTEGER AS session_duration,
(
(order_date::TIMESTAMP + random() * 24 * INTERVAL '1 hour')
AT TIME ZONE 'UTC'
AT TIME ZONE 'Asia/Shanghai'
)::TIMESTAMPTZ AS event_time
FROM (
-- 子查询先生成order_date,解决别名作用域问题
SELECT
'2025-01-01'::DATE + floor(random() * 128)::INTEGER AS order_date
FROM generate_series(1, 100)
) AS date_source; -- 生成基础日期数据
WITH user_activity AS (
SELECT
user_id,
order_date,
session_duration,
-- 剔除异常会话时长(超过4小时)
CASE WHEN session_duration > 14400 THEN NULL
ELSE session_duration END AS cleaned_duration
FROM raw_user_logs
)
select * from user_activity
- 多维度交叉验证:采用
矩阵式表格对比不同维度数据表现
| 维度 | 高复购用户(R≥3) | 低复购用户(R=1) | 差异率 | 显著性(p值) |
|---|---|---|---|---|
| 平均会话时长 | 23.5分钟 | 12.8分钟 | 83.6% | <0.01 |
| 加购转化率 | 18.7% | 9.2% | 103% | <0.001 |
| 促销敏感度 | 25% | 42% | -43% | 0.03 |
3. 洞察升华(Act 3: Climax)
- 因果关系推导:运用
漏斗分析定位关键转化节点,如图"浏览-加购-下单"漏斗,流失率在加购到下单环节高达68% - 趋势预测模型:基于PostgreSQL的
窗口函数构建时间序列分析,展示复购率预测曲线(代码片段)-- 1. 创建基础订单表 CREATE TABLE IF NOT EXISTS user_orders ( order_id SERIAL PRIMARY KEY, user_id INTEGER NOT NULL, order_date DATE NOT NULL, amount NUMERIC(10,2) NOT NULL ); -- 添加表和字段注释(PostgreSQL标准语法) COMMENT ON TABLE user_orders IS '用户订单记录表'; COMMENT ON COLUMN user_orders.order_id IS '订单唯一自增ID'; COMMENT ON COLUMN user_orders.user_id IS '用户ID'; COMMENT ON COLUMN user_orders.order_date IS '订单日期'; COMMENT ON COLUMN user_orders.amount IS '订单金额(元)'; -- 2. 生成测试订单数据(模拟1年1000条记录) INSERT INTO user_orders (user_id, order_date, amount) SELECT floor(random() * 50 + 1)::INTEGER, -- 50个随机用户(1-50) '2024-01-01'::DATE + floor(random() * 365)::INTEGER, -- 全年随机日期(2024-01-01至2024-12-31) round( (random() * 200 + 50)::NUMERIC, 2 ) -- 关键修正:先转换为numeric类型再取两位小数 FROM generate_series(1, 1000); -- 生成1000条记录 -- 3. 创建复购率月报表 CREATE TABLE IF NOT EXISTS monthly_repurchase_rate ( month DATE PRIMARY KEY, -- 月份(格式:YYYY-MM-01) total_buyers INTEGER NOT NULL, -- 当月购买用户数 repeat_buyers INTEGER NOT NULL, -- 当月复购用户数(至少2单) repurchase_rate NUMERIC(5,4) -- 复购率(保留4位小数) ); -- 添加表和字段注释 COMMENT ON TABLE monthly_repurchase_rate IS '月度复购率统计表'; COMMENT ON COLUMN monthly_repurchase_rate.month IS '统计月份(每月1日)'; COMMENT ON COLUMN monthly_repurchase_rate.total_buyers IS '当月有购买行为的用户总数'; COMMENT ON COLUMN monthly_repurchase_rate.repeat_buyers IS '当月购买次数≥2次的复购用户数'; COMMENT ON COLUMN monthly_repurchase_rate.repurchase_rate IS '复购率=repeat_buyers/total_buyers'; -- 4. 计算月度复购率(填充报表) INSERT INTO monthly_repurchase_rate (month, total_buyers, repeat_buyers, repurchase_rate) WITH user_month_orders AS ( -- 按用户和月份统计订单数 SELECT user_id, DATE_TRUNC('month', order_date)::DATE AS month, -- 截断到月份(YYYY-MM-01) COUNT(*) AS order_count -- 用户月订单数 FROM user_orders GROUP BY user_id, DATE_TRUNC('month', order_date) ) SELECT month, COUNT(user_id) AS total_buyers, -- 当月总购买用户数 SUM(CASE WHEN order_count >= 2 THEN 1 ELSE 0 END) AS repeat_buyers, -- 复购用户数 -- 复购率计算(避免除零错误) CASE WHEN COUNT(user_id) > 0 THEN SUM(CASE WHEN order_count >= 2 THEN 1 ELSE 0 END)::NUMERIC / COUNT(user_id) ELSE 0::NUMERIC END AS repurchase_rate FROM user_month_orders GROUP BY month ORDER BY month; -- 5. 时间序列趋势分析(带移动平均和预测) SELECT month, -- 统计月份(格式:YYYY-MM-01) repurchase_rate, -- 当月实际复购率(核心指标) -- 3个月移动平均(趋势平滑) AVG(repurchase_rate) OVER ( ORDER BY month -- 按时间升序排列 ROWS BETWEEN 2 PRECEDING AND CURRENT ROW -- 窗口范围:当前行+前2行(共3行) ) AS moving_avg_3m, -- 基于最近2期变化的线性预测(未来1个月) repurchase_rate -- 当前月复购率 + COALESCE((repurchase_rate - LAG(repurchase_rate, 1) OVER (ORDER BY month)), 0) -- 近1月变化量(当前月-前1月) + COALESCE((repurchase_rate - LAG(repurchase_rate, 2) OVER (ORDER BY month))/2, 0) -- 近2月变化量的均值(当前月-前2月)/2 AS predicted_next_month FROM monthly_repurchase_rate ORDER BY month; -- 按时间升序排列结果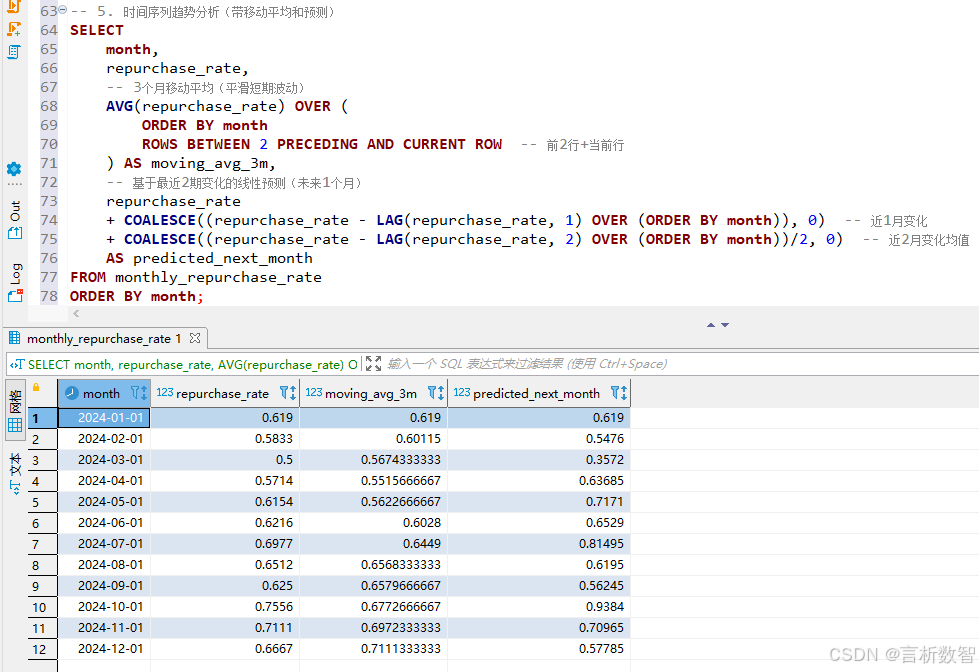
移动平均(Moving Average)- 时间序列分析中最基础的平滑技术,通过计算连续若干期数据的平均值,
消除短期随机波动,凸显长期趋势。3 个月移动平均表示当前月与前两个月复购率的平均值。
- 时间序列分析中最基础的平滑技术,通过计算连续若干期数据的平均值,
线性预测- 假设未来的变化趋势与历史近期变化一致。
- 通过计算最近两期的变化量(斜率),外推下一期的预测值。
- 这种
方法适用于趋势稳定的场景(如复购率呈缓慢上升 / 下降趋势)。 预测值 = 当前月复购率 + 近 1 月变化量 + 近 2 月变化量的均值- 3 月移动平均 = (0.25 + 0.28 + 0.30)/3 ≈ 0.277(平滑后趋势)。
- 3 月预测的 4 月复购率 = 0.30 + (0.30-0.28) + [(0.30-0.25)/2] = 0.30 + 0.02 + 0.025 = 0.345
(假设趋势延续)。
- 这种
4. 行动方案(Act 4: Resolution)
- 策略矩阵:根据数据洞察生成差异化运营方案
用户分层 | 核心问题 | 数据支撑 | 执行方案 | 预期ROI |
|---|---|---|---|---|
沉默用户 | 唤醒触达失效 | 邮件打开率<5% | 搭建RFM模型定向推送权益组合 | 1:3.2 |
新客 | 首单转化率低 | 详情页跳出率62% | 优化商品详情页信息架构 | 提升15% |
高价值用户 | 服务体验断层 | 客服响应时长45min | 开通专属客服通道+生日礼包机制 | 复购+8% |
二、业务价值提炼的三重境界
(一)描述性价值:数据事实的业务翻译
将技术语言转化为业务语言,建立数据指标与业务场景的映射关系:
- 技术指标:
SELECT COUNT(DISTINCT user_id) FROM active_users WHERE session_duration>300; - 业务解读
- 过去30天内,深度互动用户(单次使用时长>5分钟)达12,345人,较上月增长9.8%,反映用户粘性基础稳固
(二)诊断性价值:问题归因的深度挖掘
通过数据下钻分析定位根本原因,某零售企业库存周转率下降案例:
-
- 整体周转率:2.3次/季度(同比-15%)
-
品类拆解:服饰类周转率1.8次(同比-22%),电子产品3.5次(同比+5%)
-
- 仓储分析:服饰类滞销SKU占比37%,其中过季商品占比68%
SKU 即 库存单位(Stock Keeping Unit),是企业用于唯一标识库存中某一具体产品的编码或标识符。- 它是零售、电商、供应链等领域的核心概念,
用于区分不同规格、属性、包装的产品,确保库存和销售数据的精准管理。 - SKU的结构与编码规则 :通常由企业自定义,包含产品的关键属性,常见结构:
- 品牌 / 品类:如 “AD” 代表 Adidas,“SH” 代表运动鞋。
- 属性特征:如颜色(“BL”= 黑色)、尺寸(“M”= 中码)、版本(“V2”= 第二代)。
- 唯一标识:流水号或校验码,确保唯一性。
-
- 结论:季节性商品库存管理策略失效,导致周转效率下降
(三)预测性价值:商业未来的量化推演
利用PostgreSQL的分析函数构建预测模型,实现业务影响量化:
-- 创建用户画像表
CREATE TABLE user_profile (
user_id SERIAL PRIMARY KEY, -- 用户唯一ID
reg_date DATE NOT NULL, -- 注册日期
last_login_days_ago INTEGER NOT NULL CHECK (last_login_days_ago >= 0), -- 最近登录距今天数(0=今日登录)
order_frequency NUMERIC(5,2) NOT NULL CHECK (order_frequency >= 0), -- 月均下单频率(次/月)
star_rating NUMERIC(3,1) NOT NULL CHECK (star_rating BETWEEN 1 AND 5) -- 历史服务评分(1-5分,保留1位小数)
) WITH (OIDS = FALSE);
-- 添加字段注释
COMMENT ON TABLE user_profile IS '用户画像基础信息表';
COMMENT ON COLUMN user_profile.user_id IS '用户唯一自增ID';
COMMENT ON COLUMN user_profile.reg_date IS '注册日期(YYYY-MM-DD)';
COMMENT ON COLUMN user_profile.last_login_days_ago IS '最近一次登录距离今日的天数(0=今日登录)';
COMMENT ON COLUMN user_profile.order_frequency IS '近3个月的月均下单频率(次/月)';
COMMENT ON COLUMN user_profile.star_rating IS '历史所有订单的服务评分均值(1-5分)';
-- 设置随机种子保证可复现性
SET seed = 0.42;
-- 插入100条测试数据(通过子查询解决列作用域问题)
INSERT INTO user_profile (reg_date, last_login_days_ago, order_frequency, star_rating)
SELECT
reg_date,
last_login_days_ago,
-- 月均下单频率(基于子查询的last_login_days_ago)
CASE
WHEN random() < 0.7 THEN round( (random() * 8 + 2)::NUMERIC, 2 )
ELSE round( (random() * 2)::NUMERIC, 2 )
END AS order_frequency,
-- 服务评分(基于子查询的last_login_days_ago)
CASE
WHEN last_login_days_ago <= 90 THEN round( (random() * 2 + 3)::NUMERIC, 1 )
ELSE round( (random() * 2 + 1)::NUMERIC, 1 )
END AS star_rating
FROM (
-- 子查询先生成基础字段(解决列作用域问题)
SELECT
'2024-01-01'::DATE + floor(random() * 480)::INTEGER AS reg_date,
floor(random() * 181)::INTEGER AS last_login_days_ago
FROM generate_series(1, 100)
) AS base_data; -- 先生成注册日期和最近登录天数
-- 构建用户流失预测模型(逻辑回归简化版)
WITH feature_engineering AS (
SELECT
user_id,
-- 关键修正:按用户分组,确保非聚合列与聚合函数对齐
-- 假设每个用户有多个记录时,取最近登录天数(最小值)
MIN(last_login_days_ago) AS last_login_days_ago,
-- 取用户的月均下单频率(平均值)
AVG(order_frequency) AS order_frequency,
-- 计算用户的平均服务评分(聚合函数)
AVG(star_rating) AS avg_service_score,
-- 流失标签:基于最近登录天数判断(若最近一次登录超过90天则流失)
CASE WHEN MIN(last_login_days_ago) > 90 THEN 1 ELSE 0 END AS churn_label
FROM user_profile
-- 按用户分组(确保每个user_id输出一条记录)
GROUP BY user_id
)
-- 纯SQL环境下模拟概率计算(实际需导出数据用外部工具训练模型)
SELECT
user_id,
last_login_days_ago,
order_frequency,
avg_service_score,
churn_label,
-- 示例:通过线性组合模拟流失概率(系数需根据业务调整)
-- 公式:概率 = 0.02*最近登录天数 + 0.1*下单频率 - 0.15*平均评分(仅示例)
LEAST(GREATEST(
(last_login_days_ago * 0.02 + order_frequency * 0.1 - avg_service_score * 0.15),
0 -- 下限0(概率不低于0)
), 1) AS simulated_churn_probability -- 上限1(概率不高于1)
FROM feature_engineering
ORDER BY simulated_churn_probability DESC;
通过模型输出,可计算不同干预策略的预期收益:
- 针对高流失概率用户(概率>60%)实施挽回活动,预计减少12%的用户流失,对应年营收增加230万元。
三、实战案例:某生鲜电商用户复购提升故事
(一)数据准备阶段
-
- 数据源
- PostgreSQL中的用户订单表(user_orders)、商品信息表(products)、促销活动表(promotions)
-
- 数据清洗:
处理缺失值(填充中位数)、异常值(3σ原则),最终形成宽表
- 数据清洗:
| 字段名 | 数据类型 | 业务含义 | 清洗规则 |
|---|---|---|---|
| user_id | INT | 用户唯一标识 | 去重处理 |
| order_date | DATE | 下单日期 | 过滤测试订单(order_type=0) |
| purchase_amount | FLOAT | 购买金额 | 剔除<10元的异常订单 |
| promotion_type | VARCHAR | 促销类型 | 标准化分类(满减/折扣/赠品) |
| product_category | VARCHAR | 商品品类 | 统一二级分类标准 |
(二)故事构建过程
-
- 开场引入:通过行业对比凸显问题——本平台复购率28%,低于行业标杆35%
-
- 证据呈现:
- 热力图展示不同时段复购率变化,发现晚间20-22点复购率高出日间37%
- 交叉表分析显示,购买海鲜水产类用户复购率达35%,显著高于其他品类
-
- 洞察推导:
高复购用户特征:集中在25-40岁白领群体,平均客单价>200元,偏好晚间下单- 关键因素:海鲜品类的准时达服务(履约准时率98%)形成良好体验闭环
-
- 行动建议:
- 拓展
"晚间特惠"专区,针对目标客群推送定制化优惠券 - 复制海鲜品类的供应链管理经验到其他高潜力品类
(三)价值量化
通过数据故事驱动的运营调整,实施3个月后关键指标变化:
| 指标 | 实施前 | 实施后 | 变化率 | 业务价值换算 |
|---|---|---|---|---|
| 复购率 | 28% | 34% | +21% | 年新增营收850万元 |
| 夜间订单占比 | 32% | 45% | +41% | 错峰物流成本下降18% |
| 海鲜复购率 | 35% | 42% | +20% | 核心品类毛利提升25% |
四、数据故事化的长效机制建设
(一)建立业务-数据映射字典
| 业务场景 | 核心数据指标 | 数据来源表 | 分析模型 | 输出形式 |
|---|---|---|---|---|
| 用户留存 | 30日留存率 | user_retention | 生存分析 | 桑基图 |
| 库存周转 | 库存周转率 | inventory_logs | ABC分类法 | 帕累托图 |
| 营销效果 | ROI/CPA | campaign_results | 归因模型 | 瀑布图 |
- ROI(Return on Investment):衡量投资收益与成本的比率,反映投入产出效率。
CPA(Cost Per Acquisition):获取单个客户的平均成本,衡量获客效率。

- 生存分析模型(Survival Analysis)
- 研究 “事件发生时间” 的统计模型,如客户流失时间、产品故障时间、用户活跃持续时间。
- ABC 分类法模型(ABC Classification)
- 基于帕累托原则(80/20 法则),按价值或重要性将对象分为三类:
- A 类(20%):高价值,重点维护(如高复购高消费客户)。
- B 类(30%):中价值,常规维护。
- C 类(50%):低价值,低成本维护或激活。
- 基于帕累托原则(80/20 法则),按价值或重要性将对象分为三类:
- 归因模型(Marketing Attribution Model)
分析不同营销渠道对 “转化事件”(如下单、注册)的贡献程度,解决 “功劳分配” 问题。
- 常见模型
模型 核心逻辑 优点 缺点 末次点击转化前最后一个接触的渠道获得100%功劳(如用户通过抖音广告下单,抖音获全功劳)。 简单易算 忽略中间渠道影响 首次点击转化前第一个接触的渠道获得100%功劳(适用于品牌认知阶段)。 重视流量引入渠道 忽略后续触达 线性归因所有触达渠道平均分配功劳(如3次触达,每个渠道各占1/3)。 综合考虑多渠道 假设各渠道贡献相同 时间衰减越接近转化的渠道贡献越高(如最近一次触达贡献50%,之前依次递减)。 符合用户决策路径 参数设置较复杂 基于算法用机器学习拟合渠道贡献(如随机森林判断各渠道对转化的边际影响)。 精准度最高 需大量数据和算力
(二)构建动态故事模板库
基于PostgreSQL开发可参数化的报告生成脚本,实现:
-
- 自动抓取最新数据生成图表
-
- 智能匹配业务场景的叙事逻辑
-
- 动态更新关键指标的预警阈值
(三)建立故事效果评估体系
采用NPS(叙事净推荐值)评估数据故事的影响力:
- 问题共鸣度:数据是否精准反映业务痛点?(1-5分)
- 逻辑清晰度:故事线是否具备因果连贯性?(1-5分)
- 行动指导性:是否提供可落地的解决方案?(1-5分)
- 这篇文章构建了数据故事化呈现的完整体系,包含方法论、实战案例和长效机制。
- 你对内容的案例选择、技术细节深度有什么看法或进一步需求,欢迎告诉我。
- 通过持续优化故事结构与数据呈现方式,企业可将数据分析从
成本中心转化为利润中心。- 当数据开始"讲故事",它就不再是冷冰冰的数字,而是推动业务增长的核心驱动力。
- 掌握数据故事化的核心技巧,结合PostgreSQL强大的数据处理能力,分析师能够真正成为业务部门的战略合作伙伴,让
数据洞见转化为实实在在的商业价值。