一、引言
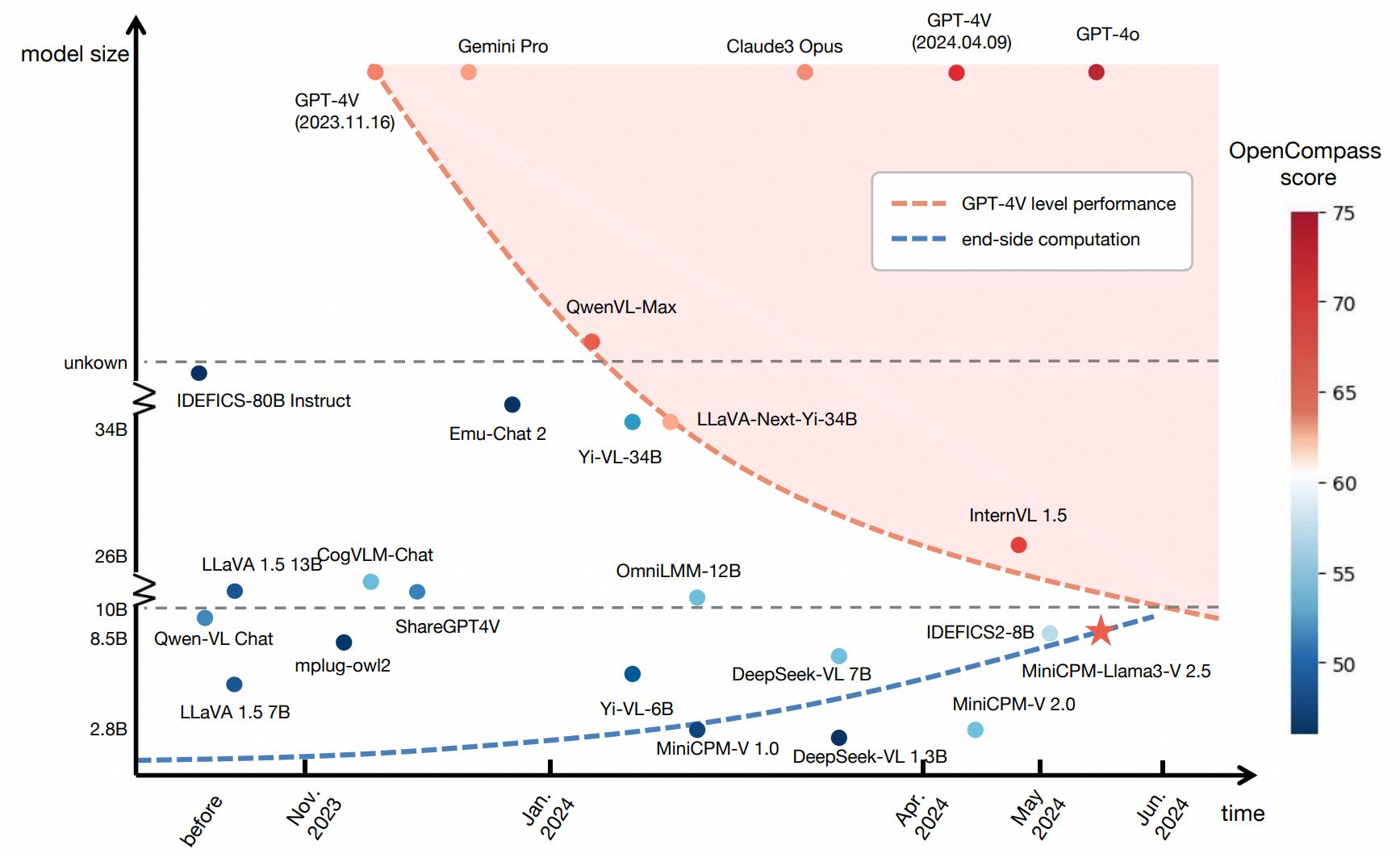
在多模态大语言模型(MLLMs)快速发展的背景下,现有模型因高参数量(如 72B、175B)和算力需求,仅能部署于云端,难以适配手机、车载终端等内存和算力受限的端侧设备。MiniCPM-V聚焦 “轻量高效” 与 “端侧落地”,通过架构创新、训练优化和部署适配,打造高知识密度的端侧 MLLM,实现性能与效率的平衡,推动多模态 AI 从云端走向终端。
二、创新点与核心思路
2.1 现有方法的局限性
-
云端依赖的本质矛盾
- 算力鸿沟:云端模型(如 GPT-4V)需数百张 A100 GPU 训练,端侧设备(如手机)算力仅为其万分之一,无法运行高参模型。
- 内存瓶颈:典型端侧设备内存为 12-16GB,而 7B 参数量模型仅权重就需 28GB(FP16),远超硬件限制。
- 实时性需求