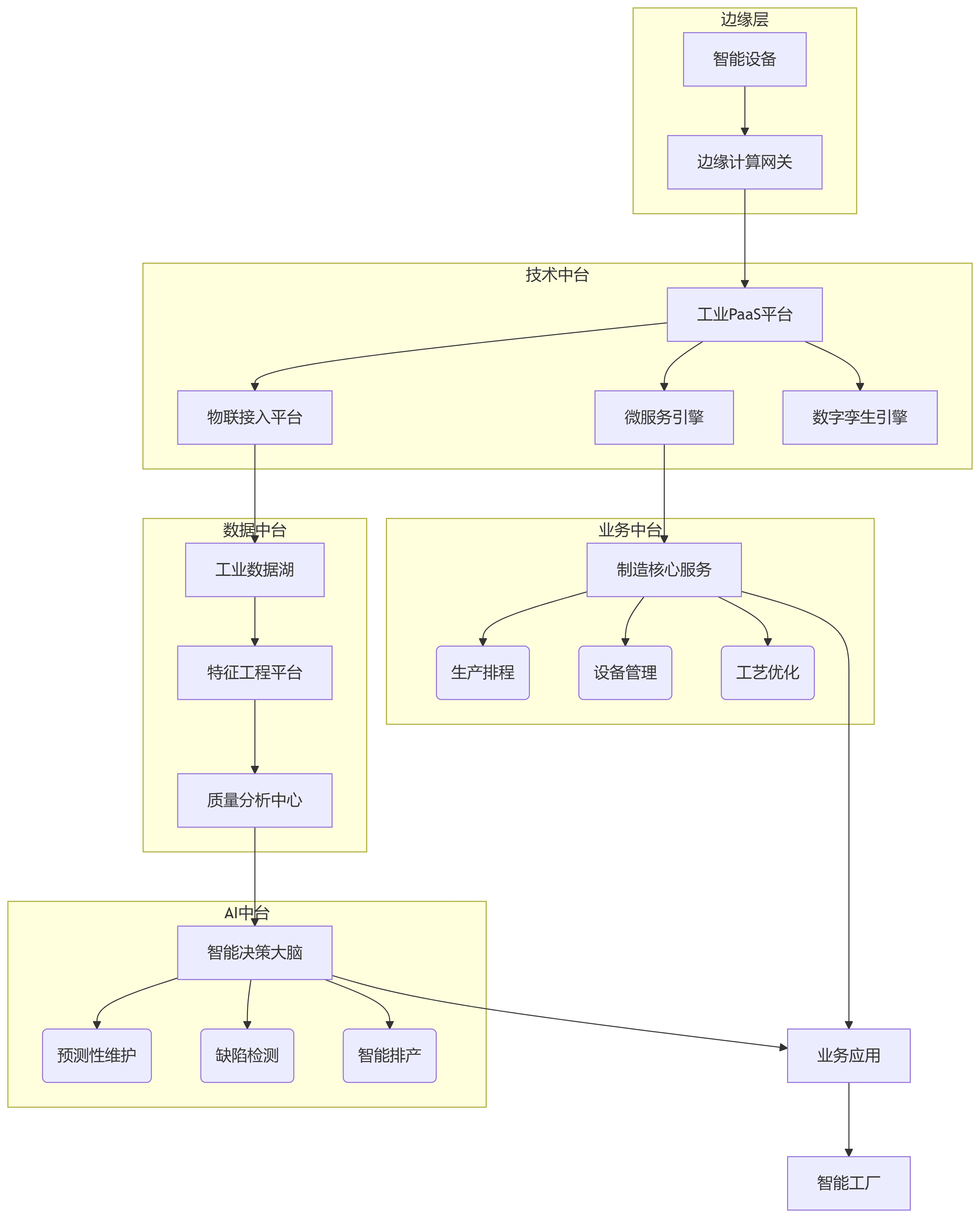
生成对抗网络(Generative Adversarial Networks,GAN)作为深度学习领域的重要突破,通过对抗训练框架实现了强大的生成能力。本文从理论起源、数学建模、网络架构、工程实现到行业应用,系统拆解GAN的核心机制,涵盖基础理论推导、改进模型分析、评估指标设计及多领域实践案例,为复杂分布建模提供完整技术路线。
一、理论基础:从博弈论到生成模型革命
1.1 GAN的起源与核心思想
GAN的全称是Generative adversarial network,中文翻译过来就是生成对抗网络。生成对抗网络其实是两个网络的组合:生成网络(Generator)负责生成模拟数据(大部分情况下是图像),最终目的是“骗过”判别器;判别网络(Discriminator)负责判断输入的数据是真实的还是生成的,目的是找出生成器做的“假数据”。生成网络要不断优化自己生成的数据让判别网络判断不出来,判别网络也要优化自己让自己判断得更准确。二者关系形成对抗,因此叫对抗网络。
1.1.1生成模型的分类与定位
传统生成模型可分为:
(1)显式密度模型:直接学习数据分布p(x),如变分自编码器(VAE)通过最大化对数似然log p(x)。
(2)隐式密度模型:不直接建模p(x),而是通过采样过程生成数据,如GAN通过对抗训练隐式学习分布。
1.1.2对抗训练的哲学思想
GAN是一种深度学习模型,由lan Goodfellow等人于2014年提出,其核心思想源于博弈论中的极小极大博弈(Mini max Game),含两个神经网络组件:
(1)生成器(Generator,G):尝试生成逼真数据,欺骗判别器;
(2)判别器(Discriminator,D):努力区分真实数据与生成数据二者构成零和博弈,通过对抗训练达到纳什均衡。
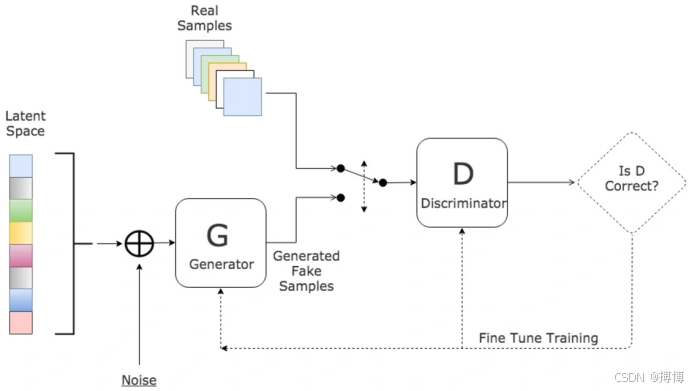
1.1.3 GAN的演进图谱
GAN自提出以来,演进出了很多版本,针对不同的场景进行了多方面的创新。
1.2数学基础:从概率分布到博弈均衡
1.2.1概率分布与KL散度
设真实数据分布为,生成器分布
![]() ,二者差异可通过KL散度衡量:
,二者差异可通过KL散度衡量:
![]()
但直接最小化KL散度需显式计算,在高维空间中难以处理。
1.2.2对抗训练的数学表述
GAN的目标函数可表示为极小极大博弈:
![]()
其中:
(1)x为真实数据,z为随机噪声(通常服从高斯分布或均匀分布);
(2)D(x)表示判别器对真实数据的评分(概率值);
(3)D(G(z))表示判别器对生成数据的评分。
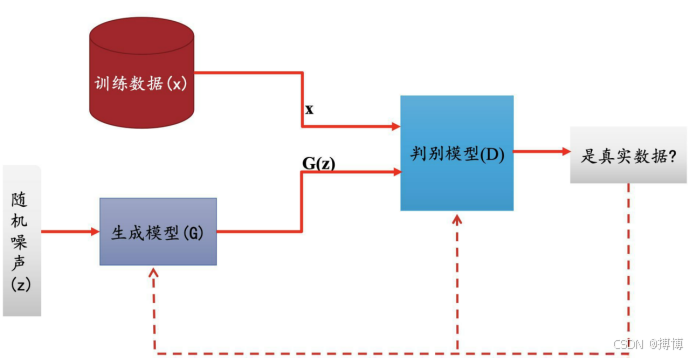
之后将D(x)和D(G(z))都输入到判别模型(D)中,进行判别,判断是否是真是的数据。
1.2.3纳什均衡的存在性
当且仅当生成器数据分布和真实数据分布相等时,即时,判别器无法区分真实与生成数据,此时判别模型(D)的最优解为
![]() ,目标函数达到全局最优解:
,目标函数达到全局最优解:
![]()
1.3理论扩展:从JS散度到Wasserstein距离
1.3.1原始GAN的局限性
原始GAN使用JS散度(Jensen-Shannon Divergence)作为优化目标,JS散度是在KL散度基础上实现的:
![]()
当与
的支撑集(support)不重叠时,JS散度恒为log2,导致梯度消失。
1.3.2 Wasserstein GAN(WGAN)的突破
Arjovsky等人提出WGAN,使用Wasserstein距离(地球移动距离,Earth Mover's Distance)替代JS散度:
![]()
其中表示所有联合分布
的集合,其边缘分布分别为
和
。
1.3.3 WGAN的理论优势
(1)梯度连续性:即使与
不重叠,Wasserstein距离仍能提供有意义的梯度。
(2)训练稳定性:通过权重裁剪(Weight Clipping)或梯度惩罚(Gradient Penalty)约束判别器为1-Lipschitz函数。
(3)评估指标有效性:Wasserstein距离与生成样本质量线性相关,可用于监控训练过程。
二、数学基础:从目标函数到训练动态
2.1原始GAN的数学推导
在进行原始GAN的数学推导之前,先熟悉一下生成器Generator和判别器Discriminator的处理过程,如下图:
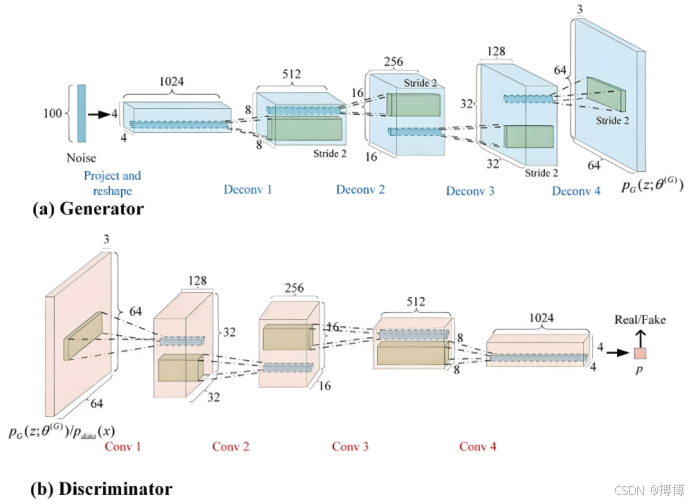
2.1.1判别器的最优解
对于固定的生成器G,判别器D的最优解为:
![]()
即看真实数据分布与生成器数据分布
和真实数据分布
之和的占比,当且仅当
时,各占一半,判别器无法区分真实与生成数据,此时则为判别器(D)的最优解。
证明:将目标函数视为D(x)的函数,对其求导并令导数为0,解得上述表达式。
2.1.2生成器的优化目标
将判别器最优解代入原目标函数,生成器的优化问题转化为:
![]()
进一步推导可得,该目标等价于最小化与
之间的JS散度。
2.2改进GAN的数学模型
2.2.1 WGAN-GP(Gradient Penalty)
为避免权重裁剪导致的参数不稳定,WGAN-GP引入梯度惩罚项:
![]()
其中是真实样本与生成样本的插值,λ为惩罚系数(通常取10)。
2.2.2最小二乘GAN(LSGAN)
使用最小二乘损失替代对数损失,缓解梯度消失问题:
![]()
![]()
2.2.3条件GAN(CGAN)
通过添加条件变量y,实现可控生成:
![]()
条件可以是类别标签、文本描述或图像特征。
2.3训练动力学与模式崩溃
2.3.1模式崩溃(Mode Collapse)现象
生成器可能只学习到数据分布的部分模式,导致生成样本多样性不足。数学上表现为:
![]()
其中δ为狄拉克函数,生成器仅生成k个离散点。
2.3.2梯度消失与训练不稳定
当判别器过强时,生成器梯度接近0,导致训练停滞。例如,当D(G(z))≈0时:
![]()
改进策略:
(1)训练初期最大化log D(G(z))而非最小化log(1-D(G(z)))
(2)判别器使用标签平滑(Label Smoothing),如将真实标签从1改为0.9
三、网络结构:从基础架构到高级变体
3.1基础GAN架构设计
3.1.1生成器网络
典型结构为反卷积网络(Deconvolutional Network):
(1)输入层:随机噪声![]() (通常d=100)
(通常d=100)
(2)全连接层:将噪声映射到高维特征空间
(3)反卷积层:逐步上采样至目标图像尺寸(如64×64×3)
(4)激活函数:输出层使用tanh(映射到[-1,1]),中间层使用ReLU
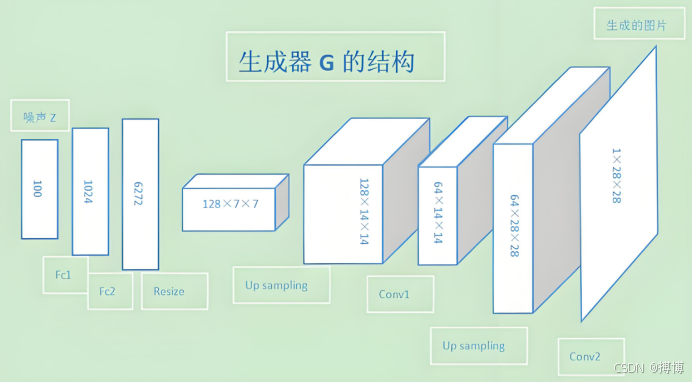
3.1.2判别器网络
典型结构为卷积网络:
(1)输入层:图像![]()
(2)卷积层:逐步下采样提取特征
(3)全连接层:输出二分类概率(真实/生成)
(4)激活函数:输出层使用sigmoid,中间层使用LeakyReLU(斜率0.2)
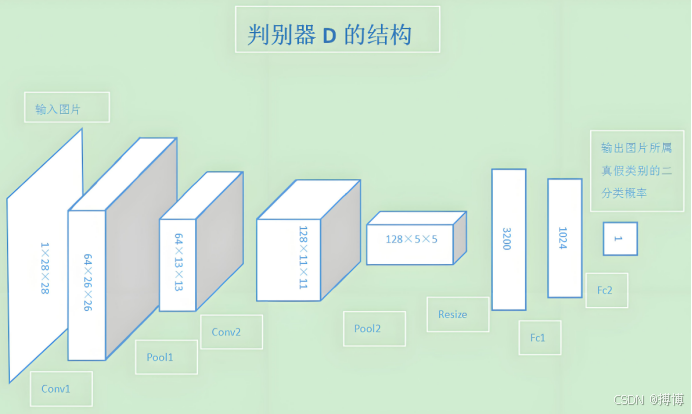
3.2高级GAN架构
3.2.1 DCGAN(深度卷积GAN)
关键改进:
(1)生成器和判别器中使用卷积层替代全连接层
(2)引入批量归一化(Batch Normalization)稳定训练
(3)使用步长卷积(strided convolution)替代池化操作
3.2.2 StyleGAN(风格生成对抗网络)
核心创新:
(1)风格注入机制:通过自适应实例归一化(Adaptive Instance Normalization,AdaIN)将潜在空间分解为内容与风格![]()
(2)渐进式训练:从低分辨率(4×4)逐步训练到高分辨率(1024×1024)
(3)潜在空间解耦:学习到的潜在空间具有语义解释性(如发型、表情等)
3.2.3 TransformerGAN
将Transformer的自注意力机制引入GAN:
(1)生成器:使用基于Transformer的解码器,通过自注意力建模全局依赖
(2)判别器:使用Vision Transformer(ViT)架构,增强对图像全局结构的理解
优势:在高分辨率图像生成中表现更优,减少棋盘效应
3.3特殊场景GAN架构
3.3.1 CycleGAN(循环一致性GAN)
用于无配对图像到图像翻译,引入循环一致性损失:
![]()
其中G:X→Y,F:Y→X为两个生成器。
3.3.2 StarGAN
单模型实现多域图像翻译,通过域标签控制翻译方向:
(1)生成器输入:噪声z +目标域标签c
(2)判别器输出:真假判断+域分类结果
3.3.3 3DGAN
用于生成3D对象,典型架构:
(1)生成器:从噪声生成3D体素网格(Voxel Grid)或点云(Point Cloud)
(2)判别器:评估3D结构的真实性,通常基于3D卷积或Point Net
四、实现技术:从训练到评估的工程实践
4.1训练技巧与稳定性优化
4.1.1初始化策略
(1)生成器:使用正态分布初始化权重,标准差0.02
(2)判别器:使用正交初始化(Orthogonal Initialization),保持梯度范数稳定
4.1.2学习率调度
(1)Adam优化器:默认参数,
(2)学习率衰减:每50-100个epoch将学习率减半
(3)两时间尺度更新规则(TTUR):判别器使用较高学习率,生成器使用较低学习率
4.1.3正则化技术
(1)谱归一化(Spectral Normalization):约束判别器为Lipschitz连续函数,替代权重裁剪
![]()
(2)梯度惩罚:如WGAN-GP中的实现,防止梯度爆炸
4.2评估指标设计
4.2.1 Inception Score(IS)
基于预训练的Inception模型,评估生成样本的质量与多样性:
![]()
其中p(y|x)是Inception模型对样本x的类别分布预测,p(y)是所有生成样本的平均类别分布。
4.2.2 Frechet Inception Distance(FID)
计算真实数据与生成数据在特征空间中的Wasserstein-2距离:
![]()
其中μ和Σ分别为特征向量的均值和协方差矩阵。
4.2.3感知路径长度(Perceptual Path Length,PPL)
评估潜在空间的平滑性,用于衡量解耦程度:
![]()
4.3硬件加速与框架优化
4.3.1分布式训练
(1)数据并行:在多个GPU上复制模型,分割批次数据
(2)模型并行:将生成器和判别器分布在不同GPU上,适用于超大规模模型
(3)混合精度训练:使用FP16存储权重和激活值,减少显存占用并加速计算
4.3.2主流框架实现
| 框架 | GAN实现特点 | 适用场景 |
| PyTorch | 动态图灵活调试,支持自定义训练循环 | 研究与快速原型开发 |
| TensorFlow | 静态图优化,SavedModel便于部署 | 生产环境大规模部署 |
| Keras | 高层API简化实现,适合初学者 | 教育与基础实验 |
| JAX | 基于XLA的高性能计算,支持自动向量化 | 理论验证与算法创新 |
五、应用示例:多领域生成问题解决方案
5.1图像生成:人脸合成案例
5.1.1数据准备
数据集:CelebA-HQ(30,000张高分辨率人脸图像)
预处理:裁剪、缩放至1024×1024,归一化到[-1,1]
5.1.2模型架构(StyleGAN2)
python代码示例:
import torch import torch.nn as nn
class MappingNetwork(nn.Module):
def __init__(self, z_dim=512, w_dim=512, num_layers=8):
super().__init__()
layers = []
for i in range(num_layers):
layers.append(nn.Linear(z_dim if i == 0 else w_dim, w_dim))
layers.append(nn.LeakyReLU(0.2))
self.net = nn.Sequential(*layers)
def forward(self, z):
return self.net(z)
class SynthesisNetwork(nn.Module):
def __init__(self, w_dim=512, img_resolution=1024):
super().__init__()
# 简化版:包含多个上采样块和风格注入模块
# 实际实现包含ToRGB层、噪声注入等组件
class StyleGAN2(nn.Module):
def __init__(self, z_dim=512, w_dim=512, img_resolution=1024):
super().__init__()
self.mapping = MappingNetwork(z_dim, w_dim)
self.synthesis = SynthesisNetwork(w_dim, img_resolution)
def forward(self, z):
w = self.mapping(z)
img = self.synthesis(w)
return img5.1.3训练过程
(1)损失函数:使用r1正则化的WGAN-GP损失
(2)渐进式训练:从4×4逐步训练到1024×1024,每阶段训练约200k步
(3)评估指标:FID=2.82(在FFHQ数据集上)
5.2图像到图像翻译:语义分割转真实图像
5.2.1问题定义
将Cityscapes数据集的语义分割图(19类)转换为逼真的城市街景图像。
5.2.2模型架构(SPADE)
python代码示例:
class SPADE(nn.Module):
def __init__(self, norm_nc, label_nc):
super().__init__()
self.param_free_norm = nn.BatchNorm2d(norm_nc, affine=False)
self.mlp_shared = nn.Sequential(
nn.Conv2d(label_nc, 128, kernel_size=3, padding=1),
nn.ReLU()
)
self.mlp_gamma = nn.Conv2d(128, norm_nc, kernel_size=3, padding=1)
self.mlp_beta = nn.Conv2d(128, norm_nc, kernel_size=3, padding=1)
def forward(self, x, segmap):
normalized = self.param_free_norm(x)
segmap = nn.functional.interpolate(segmap, size=x.size()[2:], mode='nearest')
actv = self.mlp_shared(segmap)
gamma = self.mlp_gamma(actv)
beta = self.mlp_beta(actv)
return normalized * (1 + gamma) + beta
class SPADEResnetBlock(nn.Module):
def __init__(self, fin, fout, seg_nc):
super().__init__()
self.conv1 = nn.Conv2d(fin, fout, kernel_size=3, padding=1)
self.conv2 = nn.Conv2d(fout, fout, kernel_size=3, padding=1)
self.norm1 = SPADE(fin, seg_nc)
self.norm2 = SPADE(fout, seg_nc)
self.actvn = nn.LeakyReLU(0.2)
self.shortcut = nn.Conv2d(fin, fout, kernel_size=1, bias=False)
def forward(self, x, seg):
x_s = self.shortcut(x)
dx = self.conv1(self.actvn(self.norm1(x, seg)))
dx = self.conv2(self.actvn(self.norm2(dx, seg)))
out = x_s + dx
return out
5.2.3实验结果
(1)评估指标:FID=18.6,LPIPS=0.125
(2)控制能力:通过调整分割图中的类别分布,可生成不同场景的街景
5.3文本到图像生成:基于CLIP的可控生成
5.3.1模型架构(DALL-E2简化版)
(1)文本编码器:使用预训练的CLIP文本编码器
(2)图像编码器:使用预训练的CLIP图像编码器
(3)扩散模型:基于文本特征生成图像,通过CLIP引导优化
5.3.2关键技术
(1)交叉注意力机制:文本特征与图像特征通过交叉注意力交互
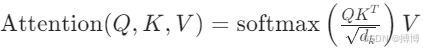
(2)CLIP引导:通过最大化生成图像与文本描述在CLIP特征空间中的余弦相似度
![]()
5.3.3生成示例
输入文本:“一只戴着太阳镜的金毛犬在沙滩上奔跑”
生成结果:成功生成符合描述的逼真图像,毛发细节和动态表现良好
5.4视频生成:动作条件下的人体视频合成
5.4.1模型设计(MoCoGAN)
1.生成器:
(1)内容编码器:提取人物外观特征
(2)动作编码器:处理动作序列(光流或关节点)
(3)解码器:融合内容与动作特征生成视频帧
2.判别器:
(1)空间判别器:评估单帧图像质量
(2)时间判别器:评估帧间连贯性
5.4.2实验结果
在Human3.6M数据集上,生成的人体动作自然流畅
评估指标:FrechetVideoDistance(FVD)=108.2
六、挑战与未来方向
6.1当前技术瓶颈
(1)训练稳定性:模式崩溃、梯度消失/爆炸等问题仍需手动调参
(2)评估困难:缺乏统一、可靠的评估指标,IS和FID存在局限性
(3)可控性不足:难以精确控制生成结果的特定属性(如人脸的年龄、表情)
6.2前沿研究方向
(1)基于扩散模型的生成:通过迭代去噪过程生成高质量样本,如DALL-E2、Stable Diffusion
(2)生成对抗的理论突破:探索新的博弈理论框架,解决训练不稳定性
(3)多模态生成:融合文本、音频、3D等多种模态信息,实现更复杂场景的生成
(4)生成模型的可解释性:开发方法解释生成过程,理解潜在空间语义
七、结语
生成对抗网络通过对抗训练的创新思想,为数据生成提供了强大工具,其影响已渗透到计算机视觉、自然语言处理、音频处理等多个领域。从理论推导到工程实现,GAN的发展印证了深度学习中“对抗训练”范式的有效性——通过构建竞争机制,模型能够学习到更复杂、更真实的数据分布。未来,随着理论的完善和技术的融合,GAN将在创意设计、虚拟现实、科学模拟等领域发挥更大作用,推动人工智能从感知智能向创造智能迈进。