文章目录
- 零、写在前面
- 1、关于页表
- 2、RISC-V Rv39页表机制
- 3、虚拟地址设计
- 4、页表项设计
- 5、访存流程
- 6、xv6 的页表切换
- 7、页表遍历
- 一、Print a page table
- 1.1 说明
- 1.2 实现
- 二、A kernel page table per process
- 2.1 说明
- 2.2 初始化 / 映射相关
- 2.3 用户内核页表的创建和回收
- 2.4 进程切换 / 页表加载
- 三、Simplify `copyin/copyinstr`
- 3.1 说明
- 3.2 copyin_new / copyinstr_new
- 3.3 用户页表拷贝到用户内核页表‘
- 3.4 同步映射
零、写在前面
1、关于页表
页表的基本概念及原理见:主存储器管理
关于 Cache、TLB见:第五章详细梳理
这里进行简要介绍。
页式存储管理将物理内存和虚拟内存划分为等长固定大小的页(Page),通过一张或者多张**页表(Page Table)来记录虚拟页和物理页之间的映射(Mapping)**关系。
2、RISC-V Rv39页表机制
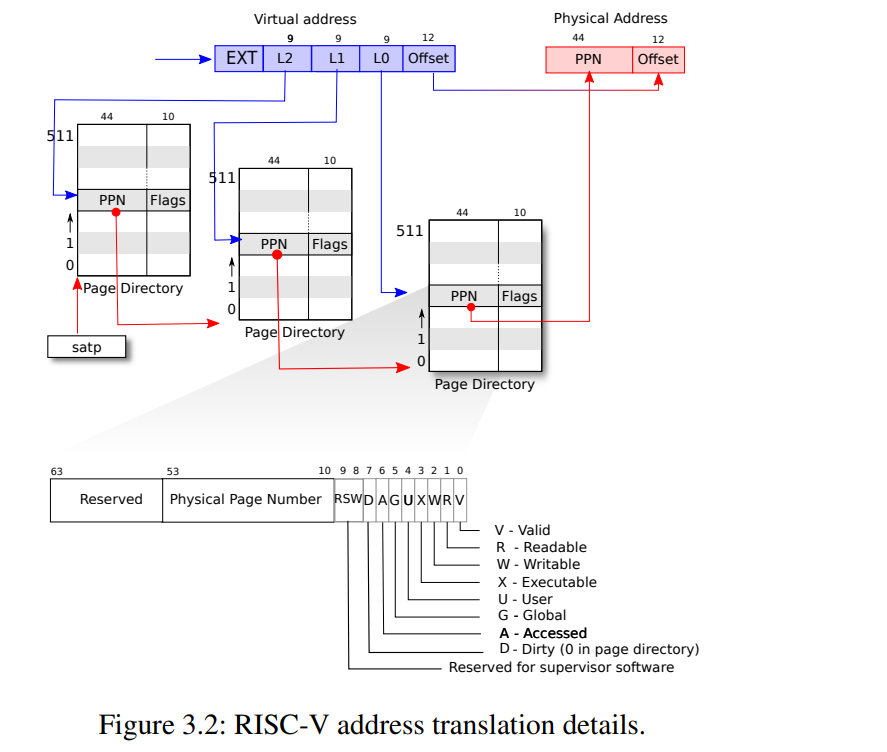
RISC-V 支持 32、39、48、57 和 64 多种分页方式,本实验的 xv6 则是采用的Rv39:
- 虚拟地址(Virtual Address) 空间为39位,即单个进程最大可寻址 2^39 / 2^30 = 2^9 = 512 GB 的内存
- 56 位的 **物理地址(Physical Address)**空间,即 39位的 虚拟地址会被转换为 56位的物理地址
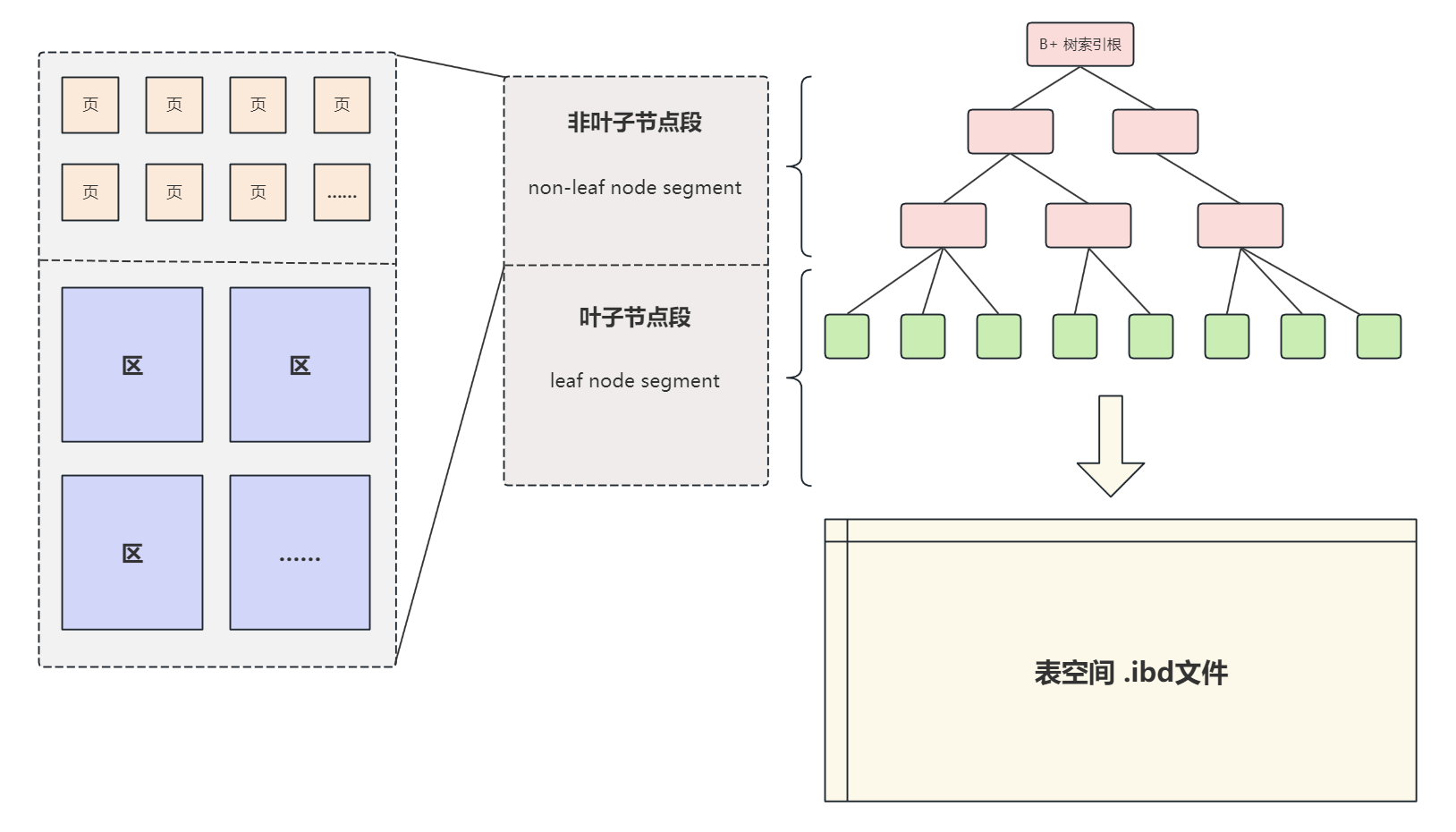
- 三级页表结构,每级页表包含 512 个页表项(PTE, Page Table Entry),每个页表项为 64 字节
- 每张表占用 64 * 512 = 4096 = 4KB 的内存
- 每个进程有三张表,总共需要12KB的内存
- 每页大小为4KB,同时还支持 2MB 和 1GB 的大页模式,但是 xv6 并未采用
页表图如下,按照树形结构组织:
3、虚拟地址设计
63 39 38 30 29 21 20 12 11 0
+------------+------------+------------+------------+------------+
| 保留位 | VPN[2] | VPN[1] | VPN[0] | 页内偏移 |
+------------+------------+------------+------------+------------+
- 第 63~39 位:前25位为保留位,无用
- 第 38~30 位:9位,2^9 = 512,代表在 第二级页表 中的索引值(VPN[2])
- 第 29-21 位:在 第一级页表 中的下标索引(VPN[1])
- 第 20-12位:在 零级页表 中的索引(VPN[0])。
- 第 11-0 位:共 12 位,表示 页内偏移,2^12=4096,保证能够访问到页内的每一个 字节。
4、页表项设计
RISC-V Sv39 有 三级页表,每张 页表 都包含 512 个 页表项(PTE),这里介绍下 页表项(PTE) 的物理结构
63 54 53 10 9 8 7 6 5 4 3 2 1 0
+------------+----------------------------------+------+-+-+-+-+-+-+-+-+
| 保留位 | 44位物理地址 | RSW |D|A|G|U|X|W|R|V|
+------------+----------------------------------+------+-+-+-+-+-+-+-+-+
RISC-V 64位 页表项 在不同的 分页模式 下有不同的结构,因为 xv6 没有用到 RISC-V Sv39 的 大页模式,所以,我们这里也只介绍 Sv39 4KB 的 页表项 结构:
- V:即Valid,有效位,表示该PTE是否有效
- R:Readable,可读
- W:Writable,可写
- X:Executable,可执行
- U:User,用户模式可访问
- 本实验不涉及 G, A, D, RSW 标记位,所以先略
- 10~53位:下一级页表 或者 虚拟内存 的物理地址
- 对于如何利用PTE中44位的地址得到56位的地址也是OS / 计组课程中必不可少的内容了
- 这44位实际上是 56位 地址的高44位,访问 下一级页表 的时候我们把低12位置零
- 如果访问到零级页表,我们把12位页内偏移和该44位地址拼接即可得到虚拟地址对应的物理地址
- 如何得到12位页内偏移?——即虚拟地址的低12位。
5、访存流程
SATP 64寄存器用来控制是否开启分页,高4位 为 mode 位,为 0 表示关闭分页,为 8 表示启用 Sv39 模式
- 当 mode = 0,表示 MMU(Memory Mapping Unit,内存映射部件) 处于 直通(pass-through) 模式,所有地址视为物理地址,直接转给 访存部件处理。
- 访存部件完成读操作后,将数据写入 数据总线,然后通过 控制总线 通知 CPU
- 当 mode = 8,CPU 执行的所有访存都是虚拟地址,MMU 借助页表(当然也可能会有TLB的辅助)完成虚拟地址转换
- 读L2页表,得到L1页表地址
- 读L1页表,得到 L0页表地址
- 读L0页表,和页内地址偏移拼接得到物理地址
- 访存部件去查找对应内容(Cache / 内存)
Sv39 中 SATP的位布局:
| 位数 | 名称 | 说明 |
|---|---|---|
| 63 | MODE | 地址转换模式(0=裸模式,8=Sv39) |
| 62:44 | ASID | 地址空间标识符(Address Space ID) |
| 43:0 | PPN | 页表的物理页号(Page-Table Physical Page Number) |
43~0 即根页表的物理地址。
6、xv6 的页表切换
顶级页表放在哪?
xv6 中 页表是 pagetable_t 类型的指针,定义在 riscv.h 中
// kernel/riscv.h
typedef uint64 *pagetable_t; // 512 PTEs
内核的顶级页表在 kernel/proc.c 中定义,用户页表则存放在 proc 结构体的字段中
// kernel/proc.c
extern pagetable_t kernel_pagetable; // kernel page table
// kernel/proc.h
struct proc {
pagetable_t pagetable; // User page table
};
切换进程的时候,需要重新设置 satp 寄存器,同步切换 页表
// kernel/proc.c
void scheduler(void)
{
struct proc *p;
struct cpu *c = mycpu();
c->proc = 0;
for(;;){
// ...
for(p = proc; p < &proc[NPROC]; p++) {
acquire(&p->lock);
if(p->state == RUNNABLE) {
// 切换到新进程
p->state = RUNNING;
c->proc = p;
w_satp(MAKE_SATP(p->pagetable)); // 把新进程的顶级页表设置到 satp 寄存器
sfence_vma(); // 刷新 TLB
swtch(&c->context, &p->context);
// ...
}
release(&p->lock);
}
}
}
7、页表遍历
其实就是用软件方法来模拟 MMU 对于页表的遍历,实现在 xv6 的walk函数中
// kernel/vm.c
pte_t *walk(pagetable_t pagetable, uint64 va, int alloc)
{
// 遍历三级页表
for(int level = 2; level > 0; level--) {
// 1. 从虚拟地址中提取VPN索引
pte_t *pte = &pagetable[PX(level, va)];
// 2. 检查PTE是否有效
if(*pte & PTE_V) {
// 有效,获取下一级页表地址
pagetable = (pagetable_t)PTE2PA(*pte);
} else {
// 无效,需要分配新页表
if(!alloc || (pagetable = (pte_t*)kalloc()) == 0)
return 0;
memset(pagetable, 0, PGSIZE);
*pte = PA2PTE((uint64)pagetable) | PTE_V;
}
}
// 3. 返回最后一级页表项的地址
return &pagetable[PX(0, va)];
}
下面是实验流程,注意切换分支到 pgtbl
其次,2021 的lab 不知道为什么第一个assignment 启动时的顶级页表地址和要求的不一样导致一直无法通过test,所以我换成了2020的lab
一、Print a page table
1.1 说明
为了帮助你更好地了解 RISC-V 的页表,以及未来的调试,这个任务要求编写一个函数来打印页表内容。
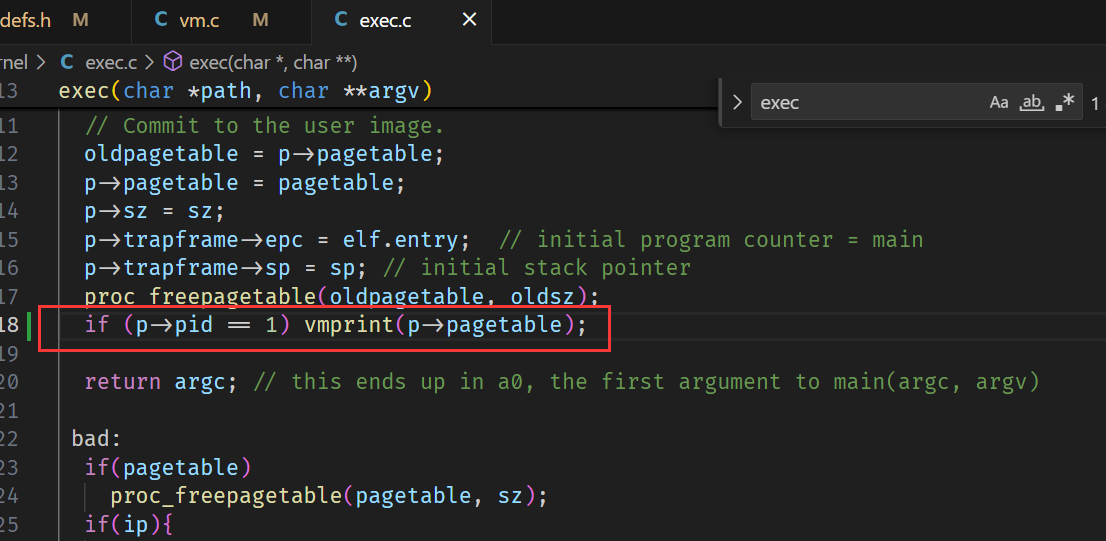
- 定义一个vmprint() 函数,它需要接收一个
pagetable_t参数,按照下面描述的格式打印。在 exec.c 的return argc 前面添加if(p->pid==1) vmprint(p->pagetable),来打印第一个进程的页表。
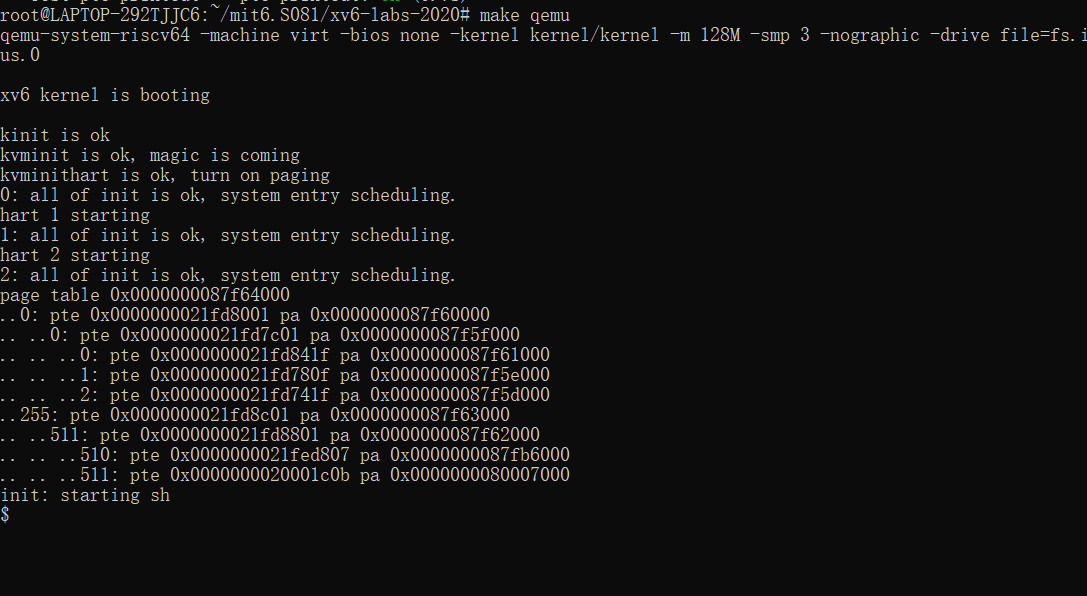
当你启动 xv6,应该有类似如下输出,当完成exec()的时候描述第一个进程的页表
page table 0x0000000087f6e000
..0: pte 0x0000000021fda801 pa 0x0000000087f6a000
.. ..0: pte 0x0000000021fda401 pa 0x0000000087f69000
.. .. ..0: pte 0x0000000021fdac1f pa 0x0000000087f6b000
.. .. ..1: pte 0x0000000021fda00f pa 0x0000000087f68000
.. .. ..2: pte 0x0000000021fd9c1f pa 0x0000000087f67000
..255: pte 0x0000000021fdb401 pa 0x0000000087f6d000
.. ..511: pte 0x0000000021fdb001 pa 0x0000000087f6c000
.. .. ..510: pte 0x0000000021fdd807 pa 0x0000000087f76000
.. .. ..511: pte 0x0000000020001c0b pa 0x0000000080007000
第一行是 vmprint 的参数,随后每一行对应一个页表项,包括指向页表树更深层的页的PTE。每一行 PTE 都以若干个 .. 缩进,.. 的数量表示它在树中的深度。每一行 PTE 都展示了他在页表中的索引,pte 位 以及从 PTE中提取的物理地址。不要打印无效PTE。在上面的例子中,顶层页表页包含了索引 0 和 255 的映射。对于索引 0,下一级页表页只映射了索引 0,而该索引 0 的最底层页表页映射了索引 0、1 和 2。
你的代码输出的物理地址可能和上面不同,但是条目数目和虚拟地址应该相同。
官网的一些提示:
- 可以把
vmprint()放在kernel/vm.c. - 可以使用在 kernel/riscv.h 末尾的宏
- 函数
freewalk或许会对你有所启发 - 在kernel/defs.h 中声明
vmprint以便于在 exec.c 中调用 - 在
%p格式控制符可以打印十六进制 PTE的64位地址
1.2 实现
先在 defs.h 添加声明:
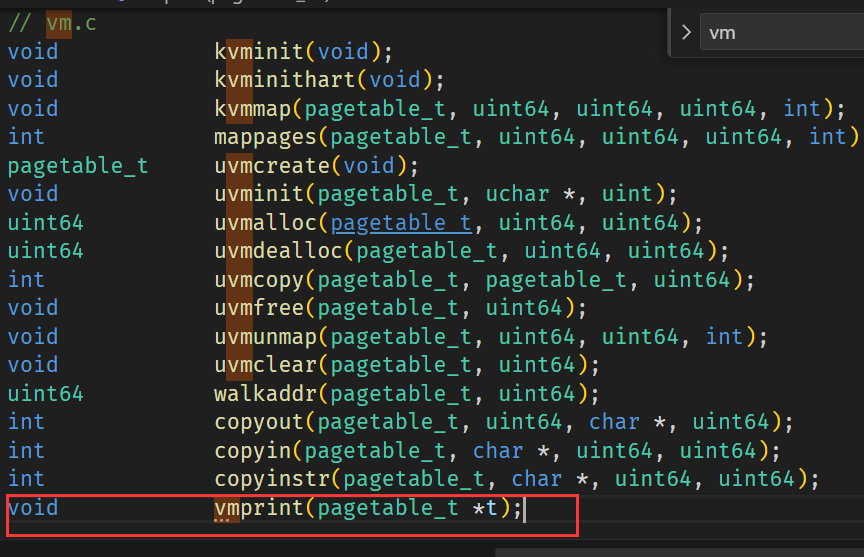
vmprint的实现
- 因为页表是树形组织,所以考虑前序遍历即可
- 注意缩进格式
void vmprint_PreOrder_dfs(pagetable_t pagetable, int d) {
// 4092 = 512 PTES
for (int i = 0; i < 512; i++) {
pte_t pte = pagetable[i];
// valid
if (pte & PTE_V) {
// 打印缩进
for (int j = 0; j < d; j++) {
printf(".. ");
}
uint64 pa = PTE2PA(pte);
printf("..%d: pte %p pa %p\n", i, pte, pa);
if ((pte & (PTE_R | PTE_W | PTE_X)) == 0) {
vmprint_PreOrder_dfs((pagetable_t) pa, d + 1);
}
}
}
}
void vmprint(pagetable_t pagetable) {
printf("page table %p\n", pagetable);
vmprint_PreOrder_dfs(pagetable, 0);
}
添加 vmprint 的调用
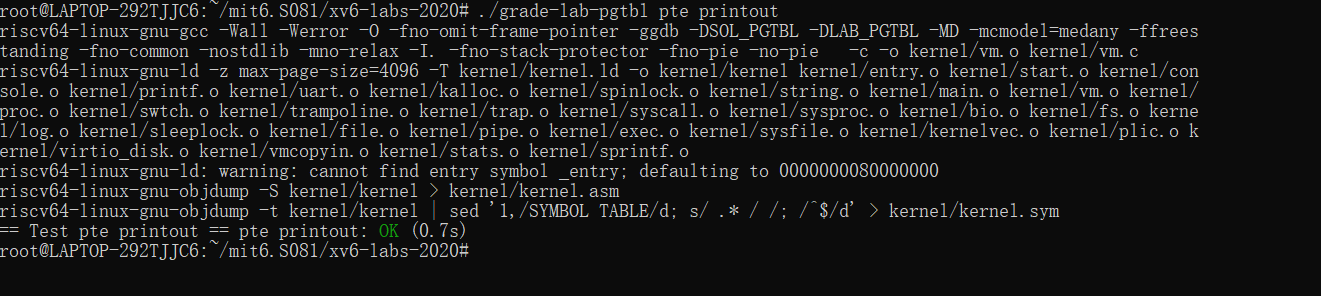
测试
脚本测试:
qemu运行:
二、A kernel page table per process
2.1 说明
Xv6 只有一个内核页表,在执行内核代码时都会使用这个页表。内核页表是一个对物理地址的直接映射,因此内核虚拟地址 x 会映射到物理地址 x。Xv6 还为每个进程的用户地址空间维护一个独立的页表,该页表仅包含该进程用户内存的映射,起始于虚拟地址 0。由于内核页表不包含这些映射,用户地址在内核中是无效的。因此,当内核需要使用系统调用中传入的用户指针(例如传递给 write() 的缓冲区指针)时,必须首先将该指针转换为物理地址。本节及下一节的目标是让内核能够直接解引用用户指针。
你的第一个任务是修改内核,使每个进程在执行内核代码时都使用自己独立的内核页表副本。你需要修改 struct proc 来为每个进程维护一个内核页表,并修改调度器,在切换进程时切换内核页表。在此阶段,每个进程的内核页表应与当前全局的内核页表完全相同。如果 usertests 能够正常运行,你就完成了这一部分的实验。
阅读本作业开头提到的书籍章节和代码;理解虚拟内存的工作方式会更容易正确地修改相关代码。页表设置中的错误可能会导致陷阱(trap),原因是缺失映射,也可能导致读写操作影响到意料之外的物理内存页,甚至可能导致指令从错误的内存页中被执行。
官网的一些提示:
- 在
struct proc中添加一个字段,用于存储进程的内核页表。 - 一种为新进程生成内核页表的合理方法是,实现一个修改版的
kvminit,它生成一个新的页表而不是修改kernel_pagetable。你应该从allocproc中调用该函数。 - 确保每个进程的内核页表中都包含该进程内核栈的映射。在未经修改的 xv6 中,所有内核栈都是在
procinit中设置的。你需要将这部分或全部功能移动到allocproc中。 - 修改
scheduler(),将进程的内核页表加载到 CPU 内核的satp寄存器中(可以参考kvminithart的实现)。不要忘记在调用w_satp()后调用sfence_vma()。 - 当没有进程运行时,
scheduler()应该使用kernel_pagetable。 - 在
freeproc中释放进程的内核页表。 - 你需要一种释放页表而不释放其叶子节点(即物理页)的方法。
vmprint可能会对调试页表有所帮助。- 修改 xv6 的函数或添加新函数是允许的;你可能至少需要在
kernel/vm.c和kernel/proc.c中这样做。(但不要修改kernel/vmcopyin.c、kernel/stats.c、user/usertests.c和user/stats.c。) - 缺失的页表映射可能会导致内核发生页错误,它会打印一条错误消息,其中包括类似
sepc=0x00000000XXXXXXXX的内容。你可以在kernel/kernel.asm中搜索XXXXXXXX来找到出错的位置。
2.2 初始化 / 映射相关
- 我们阅读下 procinit会发现进程块初始化的时候都预留了一页大小的栈空间
- 我们需要把这部分内容移动到 allocproc 中,所以我们注释掉栈空间分配的代码即可
- 即不在初始化的时候提前预留栈空间,而是进程创建的时候再创建栈空间
// initialize the proc table at boot time.
void procinit(void)
{
struct proc *p;
initlock(&pid_lock, "nextpid");
for(p = proc; p < &proc[NPROC]; p++) {
initlock(&p->lock, "proc");
// Allocate a page for the process's kernel stack.
// Map it high in memory, followed by an invalid
// guard page.
// char *pa = kalloc();
// if(pa == 0)
// panic("kalloc");
// uint64 va = KSTACK((int) (p - proc));
// kvmmap(va, (uint64)pa, PGSIZE, PTE_R | PTE_W);
// p->kstack = va;
}
kvminithart();
}
然后我们发现有几个映射相关的函数:
-
kvmmap:添加映射关系到内核页表
-
// add a mapping to the kernel page table. // only used when booting. // does not flush TLB or enable paging. void kvmmap(uint64 va, uint64 pa, uint64 sz, int perm) { if(mappages(kernel_pagetable, va, sz, pa, perm) != 0) panic("kvmmap"); } -
发现它默认把这个映射加到内核页表,这显然不是我们想要的
-
为了提高泛用性,我们实现一个函数vmmap,来支持对任意页表添加映射
-
-
kvmpa:从内核页表查询虚拟地址对应的物理地址
-
// translate a kernel virtual address to // a physical address. only needed for // addresses on the stack. // assumes va is page aligned. uint64 kvmpa(uint64 va) { uint64 off = va % PGSIZE; pte_t *pte; uint64 pa; pte = walk(kernel_pagetable, va, 0); if(pte == 0) panic("kvmpa"); if((*pte & PTE_V) == 0) panic("kvmpa"); pa = PTE2PA(*pte); return pa+off; } -
这显然也不是我们想要的,我们需要给这个函数添加页表参数,因为只有内核页表是全局变量
-
-
kvminit:创建内核页表
-
/* * create a direct-map page table for the kernel. */ void kvminit() { kernel_pagetable = (pagetable_t) kalloc(); memset(kernel_pagetable, 0, PGSIZE); // uart registers kvmmap(UART0, UART0, PGSIZE, PTE_R | PTE_W); // virtio mmio disk interface kvmmap(VIRTIO0, VIRTIO0, PGSIZE, PTE_R | PTE_W); // CLINT kvmmap(CLINT, CLINT, 0x10000, PTE_R | PTE_W); // PLIC kvmmap(PLIC, PLIC, 0x400000, PTE_R | PTE_W); // map kernel text executable and read-only. kvmmap(KERNBASE, KERNBASE, (uint64)etext-KERNBASE, PTE_R | PTE_X); // map kernel data and the physical RAM we'll make use of. kvmmap((uint64)etext, (uint64)etext, PHYSTOP-(uint64)etext, PTE_R | PTE_W); // map the trampoline for trap entry/exit to // the highest virtual address in the kernel. kvmmap(TRAMPOLINE, (uint64)trampoline, PGSIZE, PTE_R | PTE_X); } -
这个函数的意义在于为我们提供了创建页表需要做的工作,我们可以直接copy
-
我们实现函数kvminit 来实现对任意页表的初始化,这需要借助我们前面实现的vmmap函数
-
知道要做什么后,我们就可以动手实现:
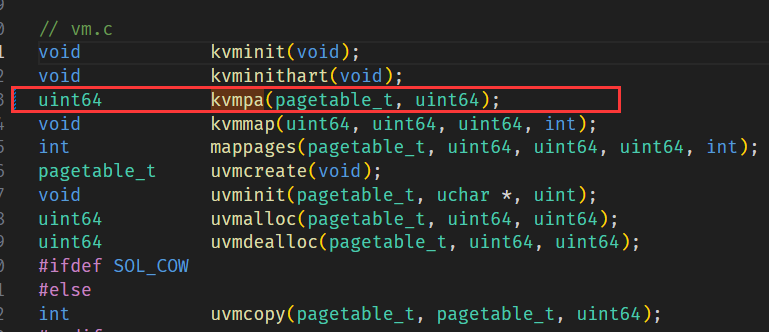
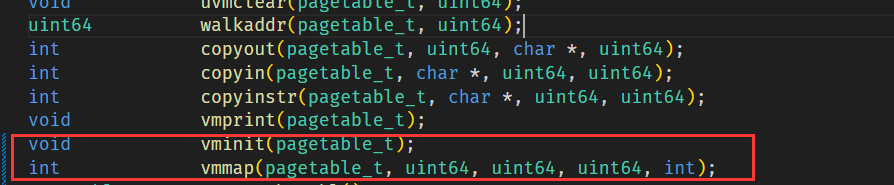
先在 defs.h 中修改/添加函数定义:
vvminit实现
- 我们把原来的kvminit 那里的代码copy过来,让后让 kvminit 调用 vminit
- 值得注意的是,对于 CLINT 的映射,只放到内核页表中
- CLINT 代表的是硬件寄存器被映射到的基内存地址,提供了访问硬件的入口点,十分重要。
/*
* create a direct-map page table for the kernel.
*/
void kvminit() {
kernel_pagetable = (pagetable_t) kalloc();
vminit(kernel_pagetable);
}
void vminit(pagetable_t pagetable) {
memset(pagetable, 0, PGSIZE);
// uart registers
vmmap(pagetable, UART0, UART0, PGSIZE, PTE_R | PTE_W);
// virtio mmio disk interface
vmmap(pagetable, VIRTIO0, VIRTIO0, PGSIZE, PTE_R | PTE_W);
if (pagetable == kernel_pagetable) {
// CLINT only for kernalpgt
vmmap(pagetable, CLINT, CLINT, 0x10000, PTE_R | PTE_W);
}
// PLIC
vmmap(pagetable, PLIC, PLIC, 0x400000, PTE_R | PTE_W);
// map kernel text executable and read-only.
vmmap(pagetable, KERNBASE, KERNBASE, (uint64) etext - KERNBASE, PTE_R | PTE_X);
// map kernel data and the physical RAM we'll make use of.
vmmap(pagetable, (uint64) etext, (uint64) etext, PHYSTOP - (uint64) etext, PTE_R | PTE_W);
// map the trampoline for trap entry/exit to
// the highest virtual address in the kernel.
vmmap(pagetable, TRAMPOLINE, (uint64) trampoline, PGSIZE, PTE_R | PTE_X);
}
kvmpa的修改
- 我们为其增加一个页表参数
- 将原先代码中查内核页表改为查传入得页表
// translate a kernel virtual address to
// a physical address. only needed for
// addresses on the stack.
// assumes va is page aligned.
uint64
kvmpa(pagetable_t pagetable, uint64 va) {
uint64 off = va % PGSIZE;
pte_t *pte;
uint64 pa;
pte = walk(pagetable, va, 0);
if (pte == 0)
panic("kvmpa");
if ((*pte & PTE_V) == 0)
panic("kvmpa");
pa = PTE2PA(*pte);
return pa + off;
}
因为kvmpa 定义修改了,所以要在调用出也都加以修改:
在 virtio_disk.c 中有一处调用:
- 修改为使用 用户内核页表 来查询地址
...
#include "virtio.h"
#include "proc.h" // 导入
void
virtio_disk_rw(struct buf *b, int write)
{
uint64 sector = b->blockno * (BSIZE / 512);
...
buf0.sector = sector;
// buf0 is on a kernel stack, which is not direct mapped,
// thus the call to kvmpa().
disk.desc[idx[0]].addr = (uint64) kvmpa(myproc()->kpgtbl, (uint64) &buf0);
}
vmmap的实现
- 把 kvmmap 的代码拿过来,然后注意对 内核页表的情况特判一下
int vmmap(pagetable_t pagetable, uint64 va, uint64 pa, uint64 sz, int perm) {
if (mappages(pagetable, va, sz, pa, perm) != 0) {
if(pagetable == kernel_pagetable){
panic("vmmap");
}
return -1;
}
return 0;
}
2.3 用户内核页表的创建和回收
因为原先进程创建时并未创建用户内核页表,所以我们还要添加用户内核页表的创建和回收的逻辑:
- 定义函数 createUsrpgt 来创建并初始化用户内核页表
- 在 allocproc() 中创建进程时
- 调用新增的 createUsrpgt() 同步创建用户内核页表
- 为新进程分配一页
内核栈空间,并将这页内存映射到用户内核页表,用于执行内核代码
- 在
freeproc()中,增加释放用户内核页表和栈空间的逻辑
先添加定义:

createUsrpgt 的实现
// create user pagetable and initialize
pagetable_t createUsrpgt() {
pagetable_t res = (pagetable_t) kalloc();
vminit(res);
return res;
}
freeUsrpgt 的实现
我们直接两重for循环去释放即可,最后把顶级页表也释放了
void freeUsrpgt(pagetable_t pagetable) {
// 512 PTES for each pgt
for(int i = 0; i < 512; ++ i){
// level-1 page table entry
pte_t l1pte = pagetable[i];
if((l1pte & PTE_V) && (l1pte & (PTE_R | PTE_W | PTE_X)) == 0){
uint64 l1ptepa = PTE2PA(l1pte);
for(int j = 0; j < 512; ++ j){
// level-0 page table entry
pte_t l0pte = ((pagetable_t)l1ptepa)[j];
if((l0pte & PTE_V) && (l0pte & (PTE_R | PTE_W | PTE_X)) == 0){
kfree((void*)PTE2PA(l0pte));
}
}
kfree((void*)l1ptepa);
}
}
// level-2 page table
kfree(pagetable);
}
最后我们只需为进程控制块添加用户内核页表成员变量,在进程的创建和释放函数中调用我们书写的逻辑即可:
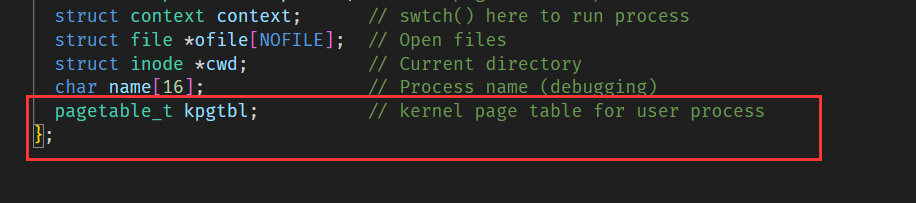
allocproc()的修改:
// allocproc
static struct proc *allocproc(void)
{
// ...
// An empty user page table.
p->pagetable = proc_pagetable(p);
if(p->pagetable == 0){
freeproc(p);
release(&p->lock);
return 0;
}
// create pgt
if((p->kpgtbl = createUsrpgt()) == 0){
freeproc(p);
release(&p->lock);
return 0;
}
char *pa = kalloc();
if(pa == 0) {
freeproc(p);
release(&p->lock);
return 0;
}
uint64 va = KSTACK((int)0);
if(vmmap(p->kpgtbl, va, (uint64)pa, PGSIZE, PTE_R | PTE_W) !=0){
kfree((void*)pa);
freeproc(p);
release(&p->lock);
return 0;
}
p->kstack = va;
return p;
}
freeproc() 的修改:
// free a proc structure and the data hanging from it,
// including user pages.
// p->lock must be held.
static void freeproc(struct proc *p)
{
// ...
if(p->pagetable)
proc_freepagetable(p->pagetable, p->sz);
p->pagetable = 0;
void *kstack_pa = (void *)kvmpa(p->kpgtbl, p->kstack);
kfree(kstack_pa);
// free pgt
if(p->kpgtbl)
freeukpgtbl(p->kpgtbl);
p->kpgtbl = 0;
// ...
}
2.4 进程切换 / 页表加载
根据官网提示的内容,
- 在
scheduler()函数中,当切换到一个进程时,加载该进程的用户内核页表 - 当切换回调度器时,恢复全局
内核页表
// Per-CPU process scheduler.
// Each CPU calls scheduler() after setting itself up.
// Scheduler never returns. It loops, doing:
// - choose a process to run.
// - swtch to start running that process.
// - eventually that process transfers control
// via swtch back to the scheduler.
void scheduler(void)
{
// ...
if(p->state == RUNNABLE) {
// Switch to chosen process. It is the process's job
// to release its lock and then reacquire it
// before jumping back to us.
p->state = RUNNING;
c->proc = p;
// switch the pgt
w_satp(MAKE_SATP(p->kpgtbl));
sfence_vma();
swtch(&c->context, &p->context);
// revert
w_satp(MAKE_SATP(kernel_pagetable));
sfence_vma();
// Process is done running for now.
// It should have changed its p->state before coming back.
c->proc = 0;
found = 1;
}
// ...
}
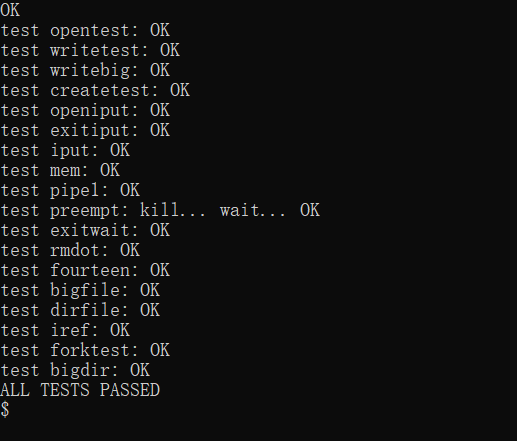
我们最终测试一下:
运行QEMU,输入 usertests
三、Simplify copyin/copyinstr
3.1 说明
内核的 copyin 函数会读取由用户指针指向的内存。它通过将这些指针转换为物理地址来实现这一点,这样内核就可以直接解引用它们。该转换是通过软件方式遍历进程的页表来完成的。本实验的这一部分任务是:为每个进程的内核页表(在上一节中已创建)添加用户地址映射,以便 copyin(以及相关的字符串函数 copyinstr)可以直接解引用用户指针。
将 kernel/vm.c 中 copyin 的函数体替换为调用 copyin_new(定义在 kernel/vmcopyin.c 中);对 copyinstr 和 copyinstr_new 也做同样的替换。为每个进程的内核页表添加用户地址的映射,以便 copyin_new 和 copyinstr_new 能够正常工作。
该方案依赖于用户虚拟地址范围与内核自身使用的指令和数据虚拟地址范围不重叠。Xv6 为用户地址空间使用从零开始的虚拟地址,幸运的是,内核的内存从更高的地址开始。然而,这也限制了用户进程的最大大小必须小于内核使用的最低虚拟地址。在内核启动后,该地址为 0xC000000,即 PLIC 寄存器的地址;参见 kernel/vm.c 中的 kvminit()、kernel/memlayout.h,以及教材中的图 3-4。你需要修改 xv6,以防止用户进程的大小超过 PLIC 的地址。
官网的一些提示:
- 首先将
copyin()替换为对copyin_new()的调用,并使其运行正常,然后再处理copyinstr。 - 每当内核改变一个进程的用户页表映射时,也要同步修改该进程的内核页表。这样的地方包括
fork()、exec()和sbrk()。 - 不要忘了在
userinit中,也要将第一个进程的用户页表包含到它的内核页表中。 - 用户地址在进程的内核页表中的页表项(PTE)应该具有什么权限?(带有
PTE_U标志的页在内核模式下是无法访问的。) - 不要忽视上面提到的 PLIC 限制。
- Linux 使用了一种类似你将要实现的技术。直到几年前,许多内核都在用户态和内核态使用相同的每进程页表,即同时映射用户地址和内核地址,以避免在用户态和内核态之间切换时更换页表。然而,这种设计允许了像 Meltdown 和 Spectre 这样的侧信道攻击。
3.2 copyin_new / copyinstr_new
添加两个函数的声明:

按照官网提示,我们将原来的函数实现放到新函数中,然后在老函数调用新函数:
int copyin(pagetable_t pagetable, char *dst, uint64 srcva, uint64 len) {
// uint64 n, va0, pa0;
//
// while (len > 0) {
// va0 = PGROUNDDOWN(srcva);
// pa0 = walkaddr(pagetable, va0);
// if (pa0 == 0)
// return -1;
// n = PGSIZE - (srcva - va0);
// if (n > len)
// n = len;
// memmove(dst, (void *) (pa0 + (srcva - va0)), n);
//
// len -= n;
// dst += n;
// srcva = va0 + PGSIZE;
// }
// return 0;
return copyin_new(pagetable, dst, srcva, len);
}
// Copy a null-terminated string from user to kernel.
// Copy bytes to dst from virtual address srcva in a given page table,
// until a '\0', or max.
// Return 0 on success, -1 on error.
int copyinstr(pagetable_t pagetable, char *dst, uint64 srcva, uint64 max) {
// uint64 n, va0, pa0;
// int got_null = 0;
//
// while (got_null == 0 && max > 0) {
// va0 = PGROUNDDOWN(srcva);
// pa0 = walkaddr(pagetable, va0);
// if (pa0 == 0)
// return -1;
// n = PGSIZE - (srcva - va0);
// if (n > max)
// n = max;
//
// char *p = (char *) (pa0 + (srcva - va0));
// while (n > 0) {
// if (*p == '\0') {
// *dst = '\0';
// got_null = 1;
// break;
// } else {
// *dst = *p;
// }
// --n;
// --max;
// p++;
// dst++;
// }
//
// srcva = va0 + PGSIZE;
// }
// if (got_null) {
// return 0;
// } else {
// return -1;
// }
return copyinstr_new(pagetable, dst, srcva, max);
}
3.3 用户页表拷贝到用户内核页表‘
添加函数 u2kvmcopy 声明,该函数负责拷贝用户页表到用户内核页表:
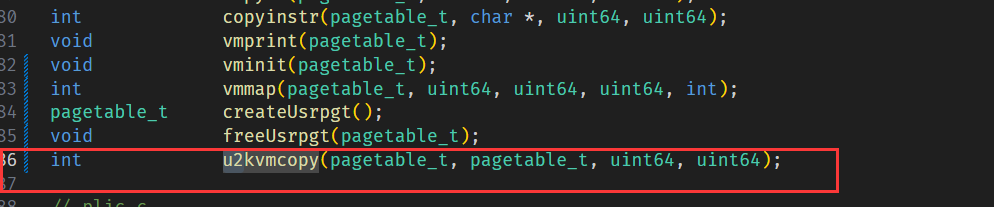
然后实现:
-
函数从 begin 开始,以页为单位(PGSIZE)遍历到 end ,为每一页创建映射。
-
使用 walk() 函数去用户页表里面,找虚拟地址 i 对应的页表项(PTE),检查该页表项是否存在,以及该页是否有效。
-
拿到pte后我们进一步得到物理地址pa
-
unset 掉 PTE_U 位,因为内核页表不能被用户访问
-
调用 mappages() 把 pa 映射到 用户内核页表 即可,这一步执行完以后,satp 中的根页表设置为 用户内核页表,这样也可以访问用户内存了。
int u2kvmcopy(pagetable_t upgtbl, pagetable_t kpgtbl, uint64 begin, uint64 end)
{
pte_t *pte;
uint64 pa, i;
uint flags;
for(i = begin; i < end; i += PGSIZE){
if((pte = walk(upgtbl, i, 0)) == 0)
panic("uvmmap_copy: pte should exist");
if((*pte & PTE_V) == 0)
panic("uvmmap_copy: page not present");
pa = PTE2PA(*pte);
// unset PTE_U because dest is kernal
flags = PTE_FLAGS(*pte) & (~PTE_U);
if(mappages(kpgtbl, i, PGSIZE, pa, flags) != 0){
uvmunmap(kpgtbl, 0, i / PGSIZE, 0);
return -1;
}
}
return 0;
}
3.4 同步映射
在创建(fork、exec)、修改(growproc)用户空间页表时,调用 u2kvmcopy() 把新增或修改的用户页表内容,同步 映射 到用户内核页表中。
fork()
- ```c
// Create a new process, copying the parent.
// Sets up child kernel stack to return as if from fork() system call.
int fork(void)
{
//...
// Copy user memory from parent to child.
if(uvmcopy(p->pagetable, np->pagetable, p->sz) < 0){
freeproc(np);
release(&np->lock);
return -1;
}
np->sz = p->sz;
// copy pgt of np to user kernal pgt
if (u2kvmcopy(np->pagetable, np->kpgtbl, 0, np->sz) < 0) {
freeproc(np);
release(&np->lock);
return -1;
}
np->parent = p;
//
}
```
-
exec()-
int exec(char *path, char **argv) { ... // Save program name for debugging. for(last=s=path; *s; s++) if(*s == '/') last = s+1; safestrcpy(p->name, last, sizeof(p->name)); // remove the former mappings uvmunmap(p->kpgtbl, 0, PGROUNDUP(oldsz) / PGSIZE, 0); // copy the new pgt to kernal pgt if (u2kvmcopy(pagetable, p->kpgtbl, 0, sz) < 0) { goto bad; } // Commit to the user image. oldpagetable = p->pagetable; p->pagetable = pagetable; ... }
-
-
growproc()-
int growproc(int n) { uint sz; struct proc *p = myproc(); sz = p->sz; // can't exceed PLIC if(n > 0 && sz + n >= PLIC) return -1; uint oldsz = sz; if(n > 0){ if((sz = uvmalloc(p->pagetable, sz, sz + n)) == 0) { return -1; } // add new memory mapping to kpgtbl after malloc u2kvmcopy(p->pagetable, p->kpgtbl, PGROUNDUP(oldsz), sz); } else if(n < 0){ sz = uvmdealloc(p->pagetable, sz, sz + n); // likewise, remove map after free uvmunmap(p->kpgtbl, PGROUNDUP(sz), (PGROUNDUP(oldsz) - PGROUNDUP(sz)) / PGSIZE, 0); } p->sz = sz; return 0; }
-
-
userinit-
官网提示了要在 userinit 这里把第一个用户进程特殊处理,因为第一个用户进程是用户空间第一个进程,内核代码初始化完成了以后直接跳转,并没有调用fork 和 exec
-
// Set up first user process. void userinit(void) { ... // allocate one user page and copy init's instructions // and data into it. uvminit(p->pagetable, initcode, sizeof(initcode)); p->sz = PGSIZE; // first user process map user pgt to kernal pgt if (u2kvmcopy(p->pagetable, p->kpgtbl, 0, PGSIZE) < 0) panic("userinit: u2kvmcopy"); // prepare for the very first "return" from kernel to user. p->trapframe->epc = 0; // user program counter p->trapframe->sp = PGSIZE; // user stack pointer ... }
-
-
在 vminit 中对CLINT特判,因为 CLINT 已经映射到用户内核页表,如果重复对 CLINT映射,会报
remap重复映射的错误-
事实上 CLINT 是每一个CPU核独有的部分,因而除了用户内核页表外,都不能对其映射。
-
void vminit(pagetable_t pagetable) { memset(pagetable, 0, PGSIZE); ... // virtio mmio disk interface vmmap(pagetable, VIRTIO0, VIRTIO0, PGSIZE, PTE_R | PTE_W); if (pagetable == kernel_pagetable) { // CLINT vmmap(pagetable, CLINT, CLINT, 0x10000, PTE_R | PTE_W); } // PLIC vmmap(pagetable, PLIC, PLIC, 0x400000, PTE_R | PTE_W); ... }
-
运行测试:
我们运行 make qemu 来测试一下:
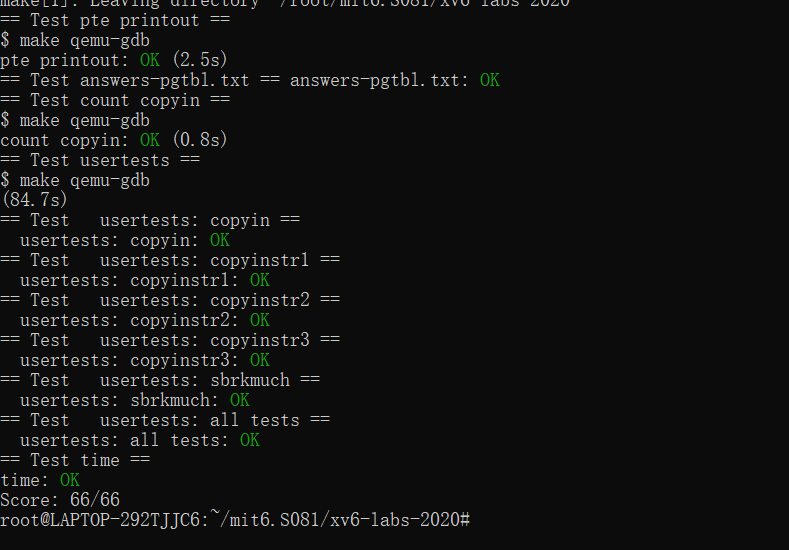
也是终于结束了。目前耗时最长的一个lab了qwq








![[特殊字符] 免税商品优选购物商城系统 | Java + SpringBoot + Vue | 前后端分离实战项目分享](https://i-blog.csdnimg.cn/direct/54982aae52634d5aaf6a6eaa6806fc85.png)