📢博客主页:https://blog.csdn.net/2301_779549673
📢博客仓库:https://gitee.com/JohnKingW/linux_test/tree/master/lesson
📢欢迎点赞 👍 收藏 ⭐留言 📝 如有错误敬请指正!
📢本文由 JohnKi 原创,首发于 CSDN🙉
📢未来很长,值得我们全力奔赴更美好的生活✨


文章目录
- 🏳️🌈一、什么是表空间结构
- 1.1 表空间与表空间文件的关系是什么?
- 🏳️🌈二、用户数据在表空间中是怎么存储的?
- 🏳️🌈三、为什么要使用页这个数据管理单元?
- 3.1 什么是局部性原理?
- 🏳️🌈四、数据页有哪些基本特性是必须要掌握的? - 页
- 🏳️🌈五、查询的数据超过一页的大小,怎么提高查询效率? - 区
- 5.1 不同的页在磁盘中是不是连续的呢?
- 5.2 为什么不连续的地址会降低查询的效率?
- 5.3 InnoDB如何保证页在磁盘中的连续性?
- 5.4 当表中的数据很少时如何避免空间浪费?
- 🏳️🌈六、如果访问的数据跨区了怎么办? - 区组
- 🏳️🌈七、以上这些数据结构还有优化的空间吗? - 段
- 🏳️🌈八、延伸问题
- 8.1 上面讲的所有操作是在哪里进行的?
- 8.2 查询数据时 MySQL 会一次把表空间中的数据全部加载到内存吗?
- 8.3 每查询一条数据都要进行一次磁盘I/0吗?
- 👥总结
在MySQL架构和存储引擎专题中介绍了使用不同存储引擎创建表时生成的表空间数据文件,在本章节主要介绍使用InnoDB存储引擎创建表时生成的表空间数据文件
🏳️🌈一、什么是表空间结构
创建表时生成的数据文件在哪里?
表空间文件是用来存储表中数据的文件,表空间文件的大小由存储的数据多少决定,不同的表空间文件存储数据的种类也有所不同
在MySQL中表空间分为五类,包括: 系统表空间、独立表空间、通用表空间、临时表空间 和 撤销表空间,这些在上面的InnoDB架构图中都有体现。
1.1 表空间与表空间文件的关系是什么?
表空间可以理解为MySOL为了管理数据而设计的一种数据结构,主要描述的对结构的定义,表空间文件是对定义的具体实现,以文件的形式存在于磁盘上
系统表空间、独立表空间、通用表空间、临时表空间和撤销表空间的作用?
后面我们会详细介绍每种类型的表空间的作用。
🏳️🌈二、用户数据在表空间中是怎么存储的?
- 首先明确一点,用户的数据以
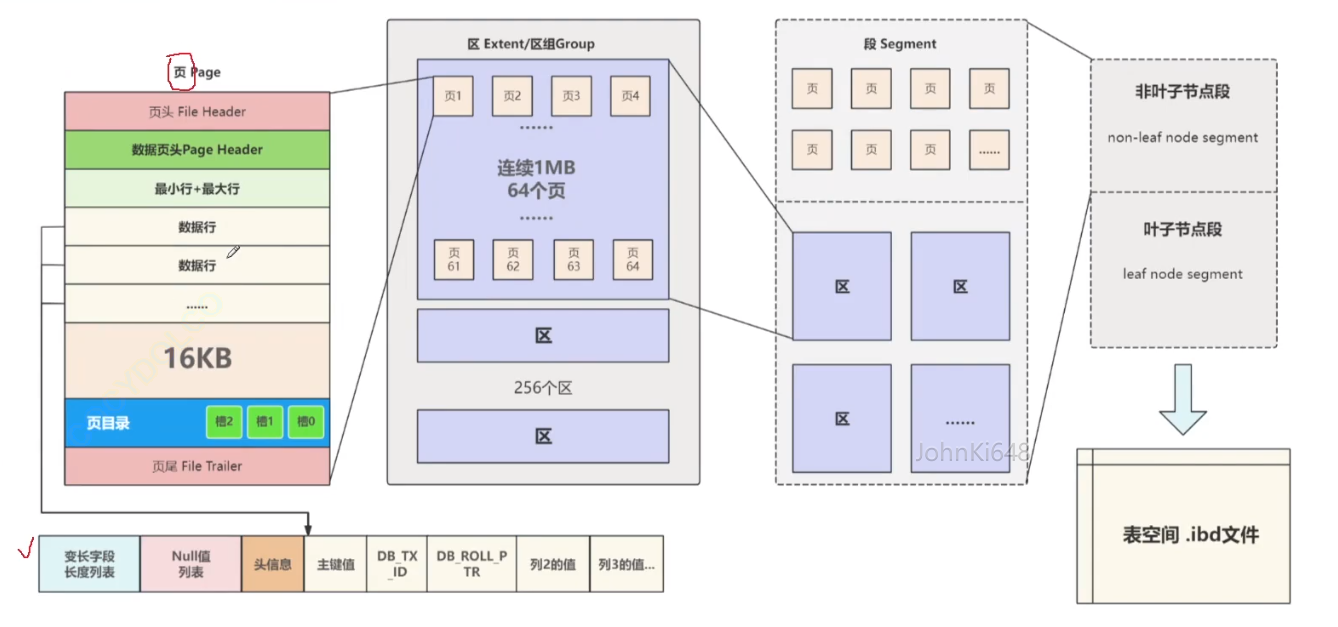
数据行的方式存储在对应的表空间文件中,那么表空间中很多个数据行就需要进行管理,以便后续进行高效的查询; - 为了方便管理,表空间由段(segment)、区组(group)、区(extent)、页(page)、数据行组成其中页是 InnoDB 磁盘管理的最小单位;
🏳️🌈三、为什么要使用页这个数据管理单元?
- 首先要明确一点,MySQL中的
页是应用层的一个概念,是MySQL根据自身的应用场景,定义的一种数据结构。 - 通常操作系统中的文件系统在管理磁盘文件时以4KB大小为一个管理单元,称为"数据块",但是在数据库的应用场景里,查询时数据量都比较大,如果也使用4KB做数据存储的最小的单元,就显的有点小了,同时会造成频繁的磁盘1/0,导致降低效率;
- 所以MySQL根据自身情况定义了
大小为16KB的页,做为磁盘管理的最小单位; - 每次内存与磁盘的交互至少读取一页,所以在磁盘中每个页内部的地址都是连续的,之所以这样做,是因为在使用数据的过程中,根据局部性原理,将来要使用的数据大概率与当前访问的数据在空间上是临近的,所以一次从磁盘中读取一页的数据放入内存中,当下次查询的数据还在这个页中时就可以从内存中直接读取,从而减少磁盘I/0,提高性能
MySQL根据自身的应用场景使用页做为数据管理单元,最主要的目的就是减少磁盘I0,提高性能。
3.1 什么是局部性原理?
局部性原理是指程序在执行时呈现出局部性规律,在一段时间内,整个程序的执行仅限于程序中的某一部分。相应地,执行所访问的存储空间也局限于某个内存区域,局部性通常有两种形式:时间局部性和空间局部性。
时间局部性(TemporalLocality): 如果一个信息项正在被访问,那么在近期它很可能还会被再次访问。空间局部性(SpatialLocality): 将来要用到的信息大概率与正在使用的信息在空间地址上是临近的。
🏳️🌈四、数据页有哪些基本特性是必须要掌握的? - 页
-
页的
16KB的大小是MySQL的一个默认设置,可以适用于大多数场景,当然也可以根据自己的实际业务场景进行修改页的大小,通过系统变量 innodb_page_size 进行调整与查看,在调整页大小的时候需要保证设置的值是操作系统"数据块"4KB的整数倍,从而保证通过操作系统和磁盘交互时"数据块"的完整性,不被分割或浪费,所以规定了 innodb_page_size 可以设置的值,分别是 4096、8192、16384、32768、65536,对应4KB、8KB、16KB、32KB、64KB: -
每一个页中即使没有数据也会使用
16KB的存储空间,同时与索引的B+树中的节点对应,后续在索引专题中详细讲解B+树的内容,查看页的大小,可以通过系统变量innodb_page_size查看
mysql> SHOW VARIABLES LIKE 'innodb_page_size';
+------------------+-------+
| Variable_name | Value |
+------------------+-------+
| innodb_page_size | 16384 | # 16KB
+------------------+-------+
1 row in set, 1 warning (0.04 sec)
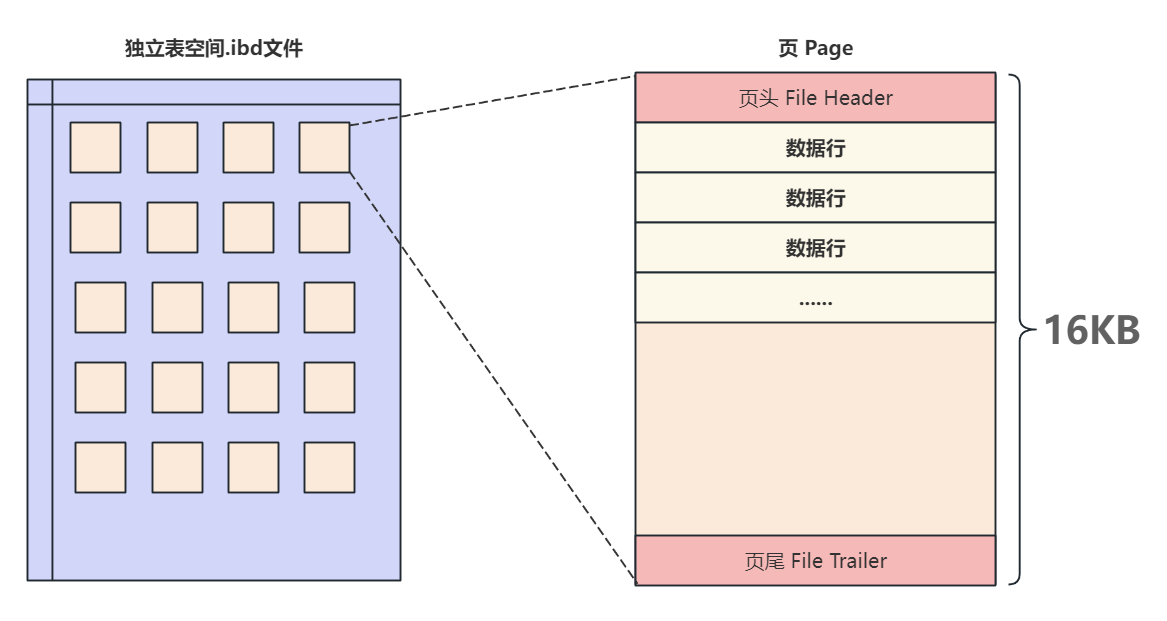
- 在不同的使用场景中,页的结构也有所不同,在MVSOL中有多种不同类型的页,但不论哪种类型的页都会包含
页头(File Header)和页尾(File Trailer),在这页头和页尾之间的页主体信息根据不同的类型有不同的结构,最常用的就是用来存储数据和索引的"索引页",也叫做"数据页",页的主体信息使用数据"行"进行填充,行的结构我们在下面的章节中进行详细介绍,页的基本结构如下图所示:
🏳️🌈五、查询的数据超过一页的大小,怎么提高查询效率? - 区
要解答这个问题,我们先要弄明白前置的几个小问题,首先通过前面的内容,我们了解到磁盘中每个页内部的地址都是连续的,那么我们可以继续提问:
1. 不同的页在磁盘中是不是连续的?
2. 如果页不连续对访问效率是否有影响?
3. InnoDB如何保证页在磁盘中的连续性?
解决以上三个小问题之后当前的问题自然也就解决了,我们接着往下看。
5.1 不同的页在磁盘中是不是连续的呢?
- 答案是不一定,在不做任何控制的情况下,不同页在磁盘中申请的地址
大概率是不连续的。 - 我们可以很快的分析出来连续的地址对查询效率的影响,如果页在磁盘中可以被连续读取,那么查询效率就高,否则果询效率就低。
5.2 为什么不连续的地址会降低查询的效率?
- 当存储介质是机械硬盘时,访问不连续的地址会带来磁盘寻址的开销,也就是磁头在不同盘面、磁道和扇区的机械转动,这个过程称为
磁盘随机访问,非常影响效率,磁盘结构如下图所示:
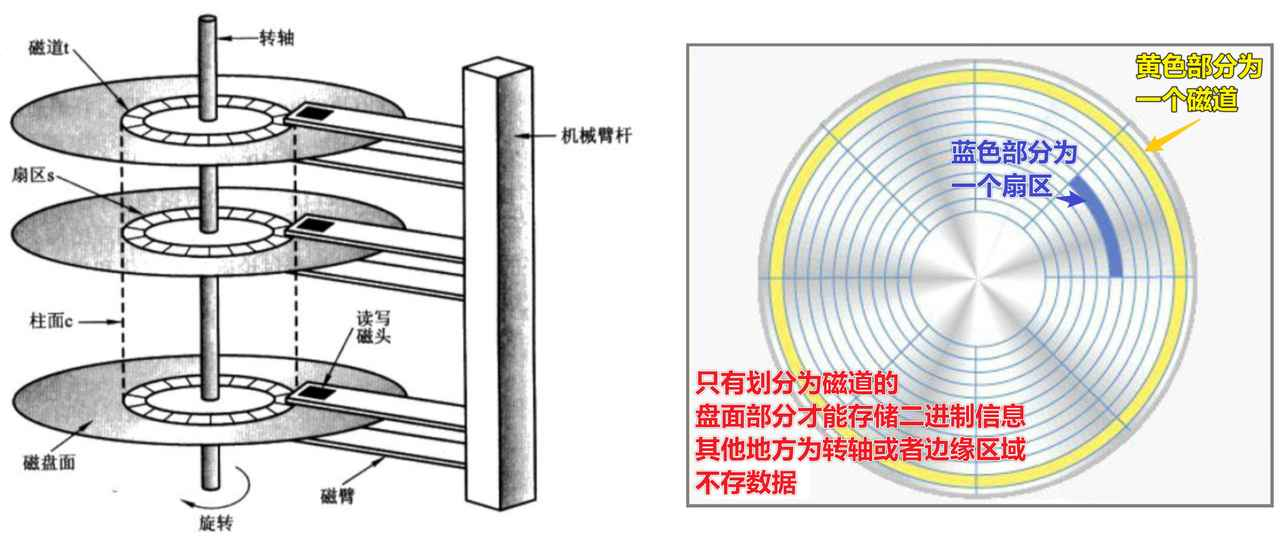
扇区是磁盘中存储数据的最小单位,固定为 512B
- 经过以上的分析,当查询的数据大于一页时不加任何控制会产生磁盘随机访问 ,这个是影响查询效率的主要因素,那么现在怎么提高查询效率的问题就变成了,页在磁盘中是否连续的问题,我们换个问法。
5.3 InnoDB如何保证页在磁盘中的连续性?
- 为了解决磁盘随机访问非常低效的问题,需要尽可能在磁道上读取连续的数据,减少磁头的移动,从而提升效率,MySQL使用
Extent(区)这个结构来管理页,规定每个区固定大小为 1MB ,可以存放 64 个页,这时如果跨页读数据时,大概率都在附近的地址,可以大幅减少碰头移动;
提示: 我们学习的主要是解决问题的思路,大家要搞懂为什么要有区以及区解决了什么问题,至于区的固定大小不用刻意去记,现阶段是1MB,以后的版本会不会改变也说不好。同时,如果频繁的读取某个区中的页,可以把整个区都读取出来放入内存中,减少后续查询对磁盘的访问次数,进一步提升效率,如图所示
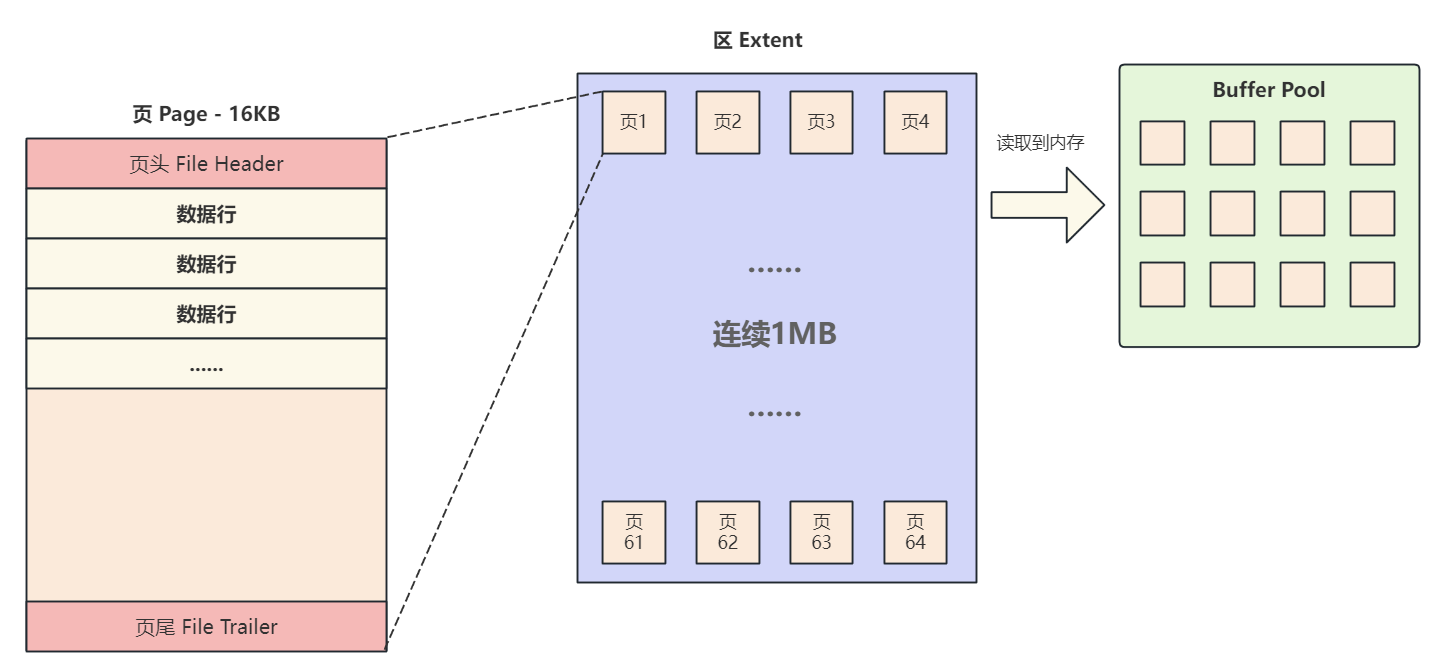
通过对问题的分析,我们了解到 InnoDB 中用来组织页的数据结构–区,并且每个区固定大小为1MB ,可以包含64个连续的页,查询的数据超过一页大小时,可能会有以下几种情况:
页在区内是相邻的: 磁盘顺序I/0,可以大幅提升效率页在区内但不是相邻的: 可以大幅减少碰头移动,可以提升效率页在不同的区: 还是要发生随机I/0,不能提升效率
那么又有一个问题来了,新创建表时没有数据,或者说有的表只有很少的数据,1MB的空间用不完,那不是就存在空间浪费的问题吗?
- 是的,的确是这样,InnoDB在设计时也考虑到了这个问题,我们继续提出问题,然后再来解决。
5.4 当表中的数据很少时如何避免空间浪费?
通过 零散页 和 碎片区 避免空间浪费的问题
- 当创建表时,并不知道当前表的数据量级
- 为了节省空间,最初只创建7个初始页(在MySQL5.7中创建6个初始页),而不是一个完整的区,可以通过以下SOL查看:
mysql> select * FROM information_schema.INNODB_TABLESPACES WHERE name = 'test_db/student'\G
*************************** 1. row ***************************
SPACE: 9
NAME: test_db/student
FLAG: 16417
ROW_FORMAT: Dynamic
PAGE_SIZE: 16384 # 页大小
ZIP_PAGE_SIZE: 0
SPACE_TYPE: Single
FS_BLOCK_SIZE: 4096
FILE_SIZE: 114688 # 数据文件初始大小
ALLOCATED_SIZE: 114688
AUTOEXTEND_SIZE: 0
SERVER_VERSION: 8.0.42
SPACE_VERSION: 1
ENCRYPTION: N
STATE: normal
1 row in set (0.00 sec)
# 根据数据文件大小和每页大小计算出页数
# 114688 / 16348 = 7 个数据页
这些零散页会放在表空间中一个叫碎片区的区域,随着数据量的增加,会申请新的页来存储数据,当碎片区达到 32个页 的时候,后续每次都会申请 一个完整的区 来存储更多的数据
🏳️🌈六、如果访问的数据跨区了怎么办? - 区组
MySQL使用
Extent(区)这个结构来管理页,规定每个区固定大小为 1MB ,可以存放 64 个页
不同的区在磁盘上大概率是不连续的,那么这个问题其实是InnoDB如何高效的的管理区?
- 当表中的数据越来越多,为了有效的管理区,定义了 区组 的结构,每个区组固定管理
256个区即256MB,通过区组可以在物理结构层面非常高效的管理和定位到每个区
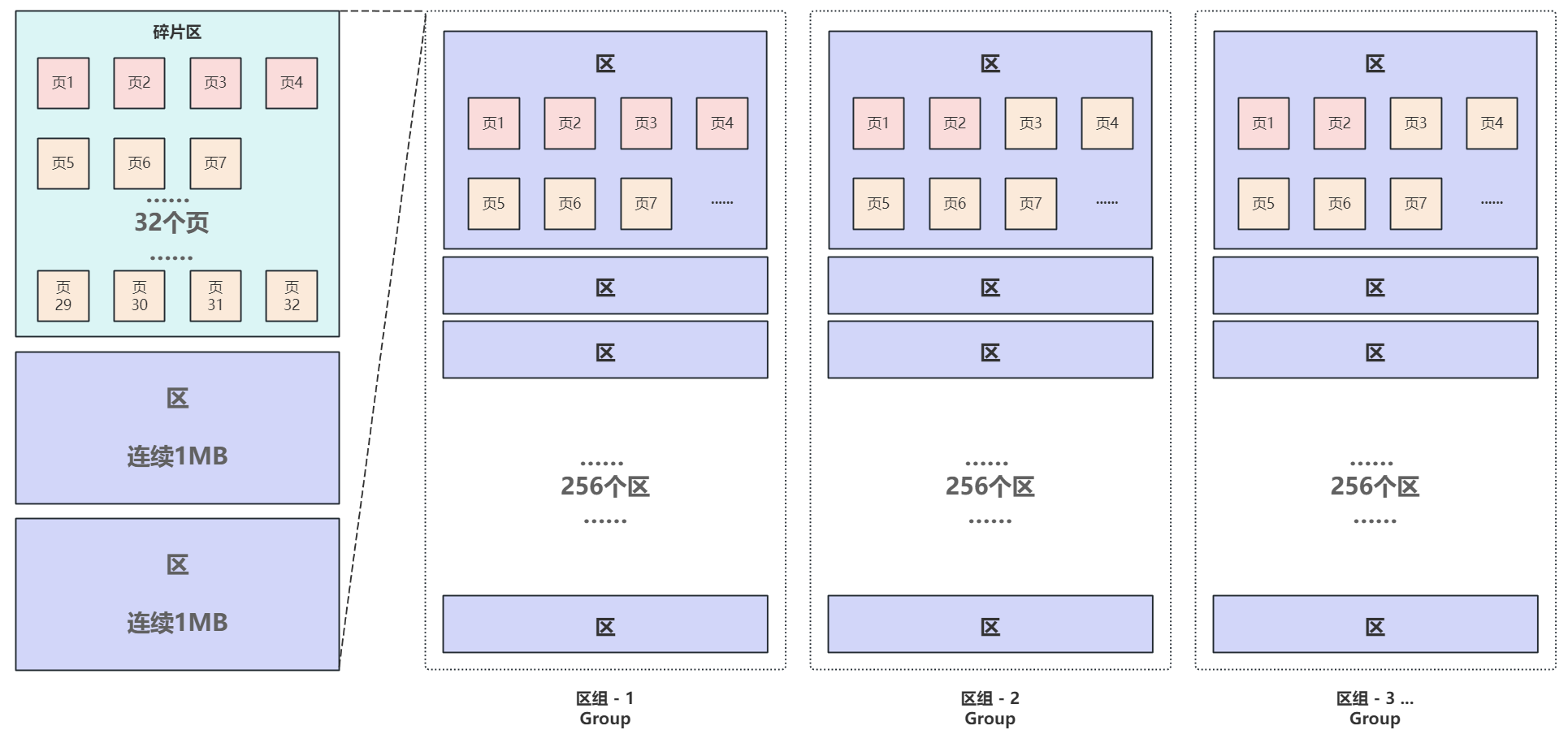
第一个区组中的首个区的前四页比特殊,也就是初始页中的前4页,分别是
File Space Header: 表空间和区组中条目信息。Insert Buffer Bitmap: Change Buffer相关信息。File Segmentinode: 段信息。B-tree Node: 索引根信息。- 其他为空闲页用来存储真实的数据
其他区组中首个区的结构都一样,前两个页分别是:
Extent Descriptor(XDES): 区组条目信息Insert Buffer Bitmap: Change Buffer相关信息
使用 区组 结构有效的管理区,每个区组固定管理256个区即256MB,区组条目信息 中会记录每个区的偏移并用双向链表连接。
🏳️🌈七、以上这些数据结构还有优化的空间吗? - 段
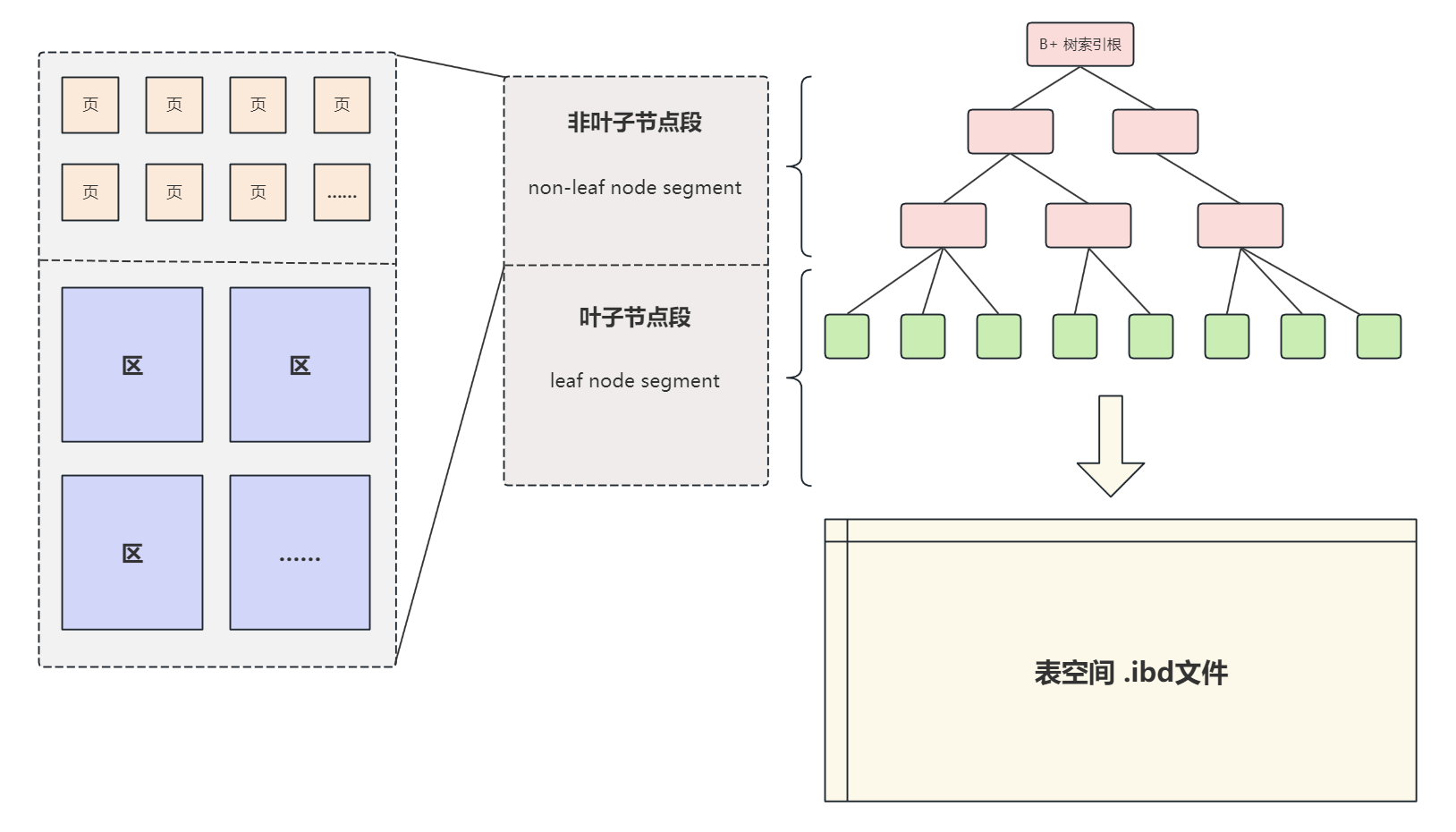
当然是有的,InnoDB使用"
段"这个逻辑结构区分不同功能的区和在碎片区中的页,并按功能分为"叶子节点段"和"非叶子节点段",做为B+树索引中的叶子、非叶子节点,从而进一步提升查询效怒。
以上讲到的区、区组还有页这种都是物理结构
在物理结构的基础上,定义了一个逻辑上的概念,也就是"段";
"段"并不对应表空间中的连续的物理区域,可以看做是"区"和"页"的一个附加标注信息,段的主要作用是区分不同功能的区和在碎片区中的页,主要分为"叶子节点段"和"非叶子节点段"等,这两个段和我们常说的B+树索引中的叶子、非叶子节点对应,
可以简单的理解为
- “
非叶子节点段” 存储和管理索引树 - “
叶子节点段” 存储和管理实际数据
从逻辑上讲,最终由"叶子节点段"和"非叶子节点段"等段构成了表空间 .ibd 文件,如下图所示:
🏳️🌈八、延伸问题
8.1 上面讲的所有操作是在哪里进行的?
- 所有的数据库操作都是在
内存中进行的,最终会把修改结果刷回磁盘中对应的页中。
8.2 查询数据时 MySQL 会一次把表空间中的数据全部加载到内存吗?
- 当然不是,使用
InnoDB存储引擎创建表,在查询数据时会根据表空间内部定义的数据结构(一般为索引),定位到目标数据行所在的页,只把符合查询要求的页加载到内存。
8.3 每查询一条数据都要进行一次磁盘I/0吗?
- 不一定,每次查询都会把磁盘中数据行对应的数据页加载到内存中,如果当前查询的数据行已经在内存中,则直接从内存中返回结果,从而提高查询效率。
👥总结
本篇博文对 【MySQL】表空间结构 - 从何为表空间到段页详解 做了一个较为详细的介绍,不知道对你有没有帮助呢
觉得博主写得还不错的三连支持下吧!会继续努力的~
![[特殊字符] 免税商品优选购物商城系统 | Java + SpringBoot + Vue | 前后端分离实战项目分享](https://i-blog.csdnimg.cn/direct/54982aae52634d5aaf6a6eaa6806fc85.png)