文章目录
- 一、选择题
- 二、基本操作
- 三、简单应用
- 四、综合应用
声明:例题均来源于网络,仅供学习笔记,若涉侵权请联系删除。所属练题来源于《小黑课堂》
一、选择题
1、树的度为3,共有31个结点,但没有度为1和2的结点。则该树中度为3的结点数为______。
A.9
B.不可能有这样的树
C.10
D.1
【题目解析】
本题考查的知识点是树。 在树中,结点数为树中所有结点的度之和再加1。所以n00+n11+n22+n33+1=31,计算得出度为3的结点数n3=10。 所以本题答案是C。
2、下列各组算法中,最坏情况下其时间复杂度相同的是______。
A.冒泡排序与快速排序
B.直接插入排序与希尔排序
C.简单选择排序与堆排序
D.快速排序与希尔排序
【题目解析】
本题考查知识点是排序。 (1)冒泡排序法:是一种最简单的交换类排序法,它是通过相邻数据元素的交换逐步将线性表变成有序。假设线性表的长度为n,若初始序列为"正序"序列,则只需进行一趟排序,在排序过程中进行n-1次关键字间的比较,且不移动记录;反之,若初始序列为"逆序"序列,则需进行n-1趟排序,需进行n(n-1)/2次比较,并作等数量级的记录移动。因此冒泡排序总的时间复杂度为/。 (2)快速排序:通常,快速排序被认为是,所有同数量级(O(nlogn))的排序方法中,其平均性能最好。但是,若初始记录序列按关键字有序或基本有序时,快速排序将蜕化为起泡排序,其时间复杂度为/。 (3)堆排序法:堆排序的方法为:①首先将一个无序序列建成堆。②然后将堆顶元素(序列中的最大项)与堆中最后一个元素交换(最大项应该在序列的最后)。堆排序在最坏的情况下,其时间复杂度为O(nlogn)。 (4)希尔排序:将整个无序序列分割成若干小的子序列分别进行插入排序。在最坏情况下,希尔排序所需的比较次数为/。
3、下列叙述中正确的是______。
A.循环队列与循环链表都是线性结构
B.双向链表既能表示线性结构,又能表示非线性结构
C.顺序存储结构只能表示线性结构
D.具有多个指针域的链表肯定是非线性结构
【题目解析】
如果一个非空的数据结构满足下列两个条件:1)有且只有一个根结点;2)每一个结点最多有一个前件,也最多有一个后件。则称该数据结构为线性结构。如果一个数据结构不是线性结构,则称之为非线性结构。 循环队列是将队列存储空间的最后一个位置绕到第一个位置,形成逻辑上的环状空间,供队列循环使用。循环队列是队列的顺序存储结构,因此循环队列是线性结构。 循环链表是一种链式存储结构,它的最后一个结点指向头结点,形成一个环。因此,从循环链表中的任何一个结点出发都能找到任何其他结点。循环列表是线性结构。 所以本题答案是A。
4、假设栈和队列初始状态为空。首先,A,B,C,D依次入栈,X,Y,Z依次入队;然后先将栈中元素依次退栈,再将队中元素依次退队。则退出的所有元素依次为______。
A.X,Y,Z,D,C,B,A
B.D,C,B,A,X,Y,Z
C.A,B,C,D,X,Y,Z
D.A,B,C,D,Z,Y,X
【题目解析】
本题的考查知识点是栈和队列。 栈是一种特殊的线性表,这种线性表只能在固定的一端进行插入和删除操作,允许插入和删除的一端称为栈顶,另一端称为栈底。一个新元素只能从栈顶一端进入,删除时,只能删除栈顶的元素,即刚刚被插入的元素。这表明栈的运算规则是"先进后出"(或称"后进先出")。在栈顶进行插入运算,称为进栈(或入栈),在栈顶进行删除运算,称为退栈(或出栈)。 队列是指允许在一端进行插入、而在另一端进行删除的线性表。在队列这种数据结构中,最先插入的元素将最先能够被删除,反之,最后插入的元素将最后才能被删除。因此队列又称为先进先出或后进后出的线性表。 由题意可知,栈中元素有A,B,C,D,队中元素有X,Y,Z。依次退栈,输出结果为D,C,B,A;依次退队,输出结果为X,Y,Z。后输出结果为:D,C,B,A,X,Y,Z。所以B选项正确。 所以本题答案是B。
5、某二叉树有49个度为2的结点,4个度为1的结点,则______。
A.该二叉树共有103个结点
B.该二叉树的结点数不确定
C.该二叉树共有101个结点
D.不可能有这样的二叉树
【题目解析】
二叉树的性质3:在任意一棵二叉树中,度为0的结点(即叶子结点)总是比度为2的结点多一个。本题中度为2的结点数为49个,叶子结点数为50个。所以该二叉树总结点数为50+4+49=103。 所以本题答案是A。
6、下列各组算法中,最坏情况下其时间复杂度不同的是______。
A.快速排序与希尔排序
B.冒泡排序与直接插入排序
C.直接插入排序与简单选择排序
D.冒泡排序与快速排序
【题目解析】
对于长度为n的有序线性表,在最坏情况下,冒泡排序、快速排序、简单选择排序、直接插入排序的最坏时间复杂度是O(n^2);堆排序的时间复杂度为O(nlog2n);希尔排序的时间复杂度为O(n1.5)。所以本题答案是A。
7、假设栈和队列初始状态为空。首先,A,B,C,D依次入栈,X,Y,Z依次入队;然后先将队中元素依次退队,再将栈中元素依次退栈。则退出的所有元素依次为______。
A.A,B,C,D,Z,Y,X
B.D,C,B,A,X,Y,Z
C.A,B,C,D,X,Y,Z
D.X,Y,Z,D,C,B,A
【题目解析】
本题的考查知识点是栈和队列。 栈是一种特殊的线性表,这种线性表只能在固定的一端进行插入和删除操作,允许插入和删除的一端称为栈顶,另一端称为栈底。一个新元素只能从栈顶一端进入,删除时,只能删除栈顶的元素,即刚刚被插入的元素。这表明栈的运算规则是"先进后出"(或称"后进先出")。在栈顶进行插入运算,称为进栈(或入栈),在栈顶进行删除运算,称为退栈(或出栈)。 队列是指允许在一端进行插入、而在另一端进行删除的线性表。在队列这种数据结构中,最先插入的元素将最先能够被删除,反之,最后插入的元素将最后才能被删除。因此队列又称为先进先出或后进后出的线性表。 由题意可知,栈中元素有A,B,C,D,队中元素有X,Y,Z。依次退队,输出结果为X,Y,Z;依次退栈,输出结果为D,C,B,A。后输出结果为:X,Y,Z,D,C,B,A。所以D选项正确。 所以本题答案是D。
8、某二叉树的前序序列为ABDECFG,中序序列为DBEAFCG,则后序序列为______。
A.DEBFGCA
B.DBEFCGA
C.BDECFGA
D.DEFGBCA
【题目解析】
本题考查的是二叉树的遍历。 二叉树前序遍历顺序是DLR,即先访问根结点,然后遍历左子树,最后遍历右子树,并且遍历子树的时候也按照DLR的顺序递归遍历。中序遍历顺序是LDR,即左-根-右,而后序遍历是左-右-根。由题面二叉树的前序序列为ABDECFG,中序序列为DBEAFCG,可知A是根结点,BDE是左子树,CFG是右子树。前序序列的左子树为BDE,中序序列的左子树为DBE,说明B是A的左子树,D是B的左子树,E是B的右子树。前序序列的右子树为CFG,中序序列的右子树为FCG,说明C是A的右子树,F是C的左子树,G是C的右子树。故该二叉树的前序序列为DEBFGCA。 所以本题答案是A。
9、循环队列的存储空间为Q(1:50),初始状态为空。经过一系列正常的入队与退队操作后,front=25,rear=25。此时该循环队列中的元素个数为______。
A.0或50
B.0
C.50
D.25
【题目解析】
本题考查知识点是循环队列。 循环队列是将队列存储空间的最后一个位置绕到第一个位置,形成逻辑上的环状空间,供队列循环使用。循环队列的初始状态为空,经过一系列的入队操作和退队操作后,头指针(front=25)尾指针(rear=25)说明入队25次,退队25次,此时队列为空或满,即循环列中元素个数为0或50。 所以本题答案是A。
10、某二叉树的后序序列为DEBFGCA,中序序列为DBEAFCG,则前序序列为______。
A.ACFGBDE
B.ABCDEFG
C.ABDECFG
D.ADEBFGC
【题目解析】
本题考查的是二叉树的遍历。 二叉树前序遍历顺序是DLR,即先访问根结点,然后遍历左子树,最后遍历右子树,并且遍历子树的时候也按照DLR的顺序递归遍历。中序遍历顺序是LDR,即左-根-右,而后序遍历是左-右-根。由题面二叉树的后序序列为DEBFGCA,中序序列为DBEAFCG,可知A是根结点,BDE是左子树,CFG是右子树。后序序列的左子树为DEB,中序序列的左子树为DBE,说明B是A的左子树,D是B的左子树,E是B的右子树。后序序列的右子树为FGC,中序序列的右子树为FCG,说明C是A的右子树,F是C的左子树,G是C的右子树。故该二叉树的前序序列为ABDECFG。 所以本题答案是C.
11、以下关于程序设计语言的描述,错误的选项是______。
A.Python解释器把Python代码一次性翻译成目标代码,然后执行
B.机器语言直接用二进制代码表达指令
C.Python是一种通用编程语言
D.汇编语言是直接操作计算机硬件的编程语言
【题目解析】
解释是将源代码逐条转换成目标代码同时逐条运行目标代码的过程。执行解释的计算机程序成为解释器。本题选A。
12、以下关于Python程序语法元素的描述,正确的选项是______。
A.缩进格式要求程序对齐,增添了编程难度
B.所有的if、while、def、class语句后面都要用':'结尾
C.Python变量名允许以数字开头
D.true是Python的保留字
【题目解析】
一般代码不需要缩进,顶行编写且不留空白。当表示分支、循环、函数、类等程序含义时,在if、while、for、def、class等保留字所在完整语句后通过英文冒号结尾并在之后进行缩进,表明后续代码与紧邻无缩进语句的所属关系。代码编写中,缩进可以用Tab键实现,也可以用多个空格(一般是4个空格)实现,但两者不混用。不会增加编程难度。 Python采用大写字母、小写字母、数字、下划线和汉字等字符及其组合进行命名,但首字符不能是数字。 Python保留字是大小写敏感的,True是保留字,true不是。本题选B。
13、以下选项,不是Python保留字的选项是______。
A.None
B.from
C.finally
D.sum
【题目解析】
sum不是保留字,可以被当做变量使用。本题选D。
14、字符串tstr=‘television’,显示结果为vi的选项是______。
A.print(tstr[-6:6])
B.print(tstr[5:7])
C.print(tstr[4:7])
D.print(tstr[4:-2])
【题目解析】
对字符串中某个子串或区间的检索成为切片。切片的使用方式如下: <字符串或字符串变量>[N:M] 切片获取字符串从N到M(不包含M)的子字符串,其中,N和M为字符串的索引序号,可以混合使用正向递增序号和反向递减序号。反向从-1开始,正向从0开始。 tstr[-6:6]表示截取字符串反向第6个字符v到正向第7个字符s(不包括s)之间的字符,即vi。本题选A。
15、关于表达式id(‘45’)的结果的描述,错误的是______。
A.是一个字符串
B.可能是4539670688
C.是一个正整数
D.是’45’的内存地址
【题目解析】
id()函数是Python内置函数之一,作用是获取对象的内存地址,返回对象的内存地址(是一个正整数)。本题选A。
16、表达式divmod(40,3)的结果是______。
A.1
B.13,1
C.13
D.(13,1)
【题目解析】
divmod(x,y)函数同时返回两个值,分别是x和y的整数商和除法余数,输出为二元组形式(也称为元组类型)。本题选D。
17、以下关于字符串类型的操作的描述,正确的是______。
A.想获取字符串str的长度,用字符串处理函数len(str)
B.设x=‘aaa’,则执行x/3的结果是’a’
C.想把一个字符串str所有的字符都大写,用upper(str)
D.str.isnumeric()方法把字符串str中数字字符变成数字
【题目解析】
len(x):返回字符串x的长度,也可返回其他组合数据类型的元素个数。本题选A。
18、设str1=‘@python@’,语句print(str1[2:].strip(‘@’))的执行结果是______。
A.@python@
B.python*
C.python@*
D.python
【题目解析】
对字符串中某个子串或区间的检索成为切片。切片的使用方式如下: <字符串或字符串变量>[N:M] 切片获取字符串从N到M(不包含M)的子字符串,其中,N和M为字符串的索引序号,可以混合使用正向递增序号和反向递减序号。反向从-1开始,正向从0开始。 str1[2:]表示截取字符串正向第3个字符p到字符串末尾之间的字符,即’python@'。 str.strip(chars)表示从字符串str中去掉在其左侧和右侧chars中列出的字符。因为得到的子字符串’python@‘最左和最右都没有字符@,所以最后的结果依然为’python@*’。本题选C。
19、执行以下程序,输出结果是______。
y='中文'
x='中文字'
print(x>y)
A.False
B.True
C.FalseorFalse
D.None
【题目解析】
字符串按位比较,x>y是成立的,所以输出True。本题选B。
20、以下关于"for <循环变量> in <循环结构>"的描述,错误的是______。
A.这个循环体语句中不能有break语句,会影响循环次数
B.<循环结构>采用[1,2,3]和[‘1’,‘2’,‘3’]的时候,循环的次数是一样的
C.使用range(a,b)函数指定for循环的循环变量取值是从a到b-1
D.foriinrange(1,10,2)表示循环5次,i的值是从1到9的奇数
【题目解析】
break是辅助循环控制的保留字,用来跳出最内层for或while循环,脱离该循环后程序从循环后的代码继续执行。本题选A。
21、执行以下程序,输入"fish520",输出结果是______。
w = input()
for x in w:
if '0'<= x <= '9':
continue
else:
w.replace(x,'')
print(w)
A.520
B.fish520
C.fish
D.520fish
【题目解析】
x in s:如果x是s的子串,返回True,否则返回False。 continue:用来结束当前当次循环,即跳出循环体中下面尚未执行的语句,但不跳出当前循环。 str.replace(old,new):返回字符串str的副本,所有old子串被替换为new。根据题目,改变的是字符串副本,字符串w本身的内容没有改变,所以最后还是输出fish520。本题选B。
22、执行以下程序,导致输出"输入有误"的输入选项是______。
try:
ls= eval(input())*2
print(ls)
except:
print('输入有误')
A.aa
B.‘12’
C.‘aa’
D.12
【题目解析】
eval()函数将去掉字符串最外侧的引号,并按照Python语句方式执行去掉引号后的字符内容,使用方式如下: <变量> = eval(<字符串>) 其中,变量用来保存对字符串内容进行Python运算的结果。输入aa时,Python语句将其解释为一个变量,由于之前没有定义过变量aa,因此解释器报错。输入数字,包括小数和复数,input()解析为字符串,经由eval()去掉字符串引号,将被直接解析为数字保存到变量中。本题选A。
23、以下关于组合类型的描述,正确的是______。
A.字典的items()函数返回一个键值对,并用元组表述空字典
B.可以用set创建集合,用中括号和赋值语句增加新元素
C.字典数据类型里可以用列表做键
D.可以通过大括号来创建空字典
【题目解析】
创建一个集合直接用{},set(x)函数将其他的组合数据类型变成集合类型,返回结果是一个无重复且排序任意的集合。使用大括号可以创建字典,特殊地,可以创建一个空字典。 d.items()返回字典中的所有键值对信息,返回结果是Python的一种内部数据类型dict_items。本题选D。
24、以下程序的输出结果是______。
s = 0
def fun(s,n):
for i in range(n):
s += i
print(fun(s,5))
A.None
B.10
C.0
D.UnboundLocalError
【题目解析】
函数fun()无返回值,所以最后输出None。本题选A。
25、以下关于函数的描述,正确的是______。
A.函数一定要有输入参数和返回结果
B.使用函数可以增加代码复用,还可以降低维护难度
C.在一个程序中,函数的定义可以放在函数调用代码之后
D.自己定义的函数名不能与Python内置函数同名
【题目解析】
使用函数主要有两个目的:降低编程难度和增加代码复用。函数可以在一个程序中多个位置使用,也可以用于多个程序,当需要修改代码时,只需要在函数中修改一次,所有调用位置的功能都更新了,这种代码复用降低了代码行数和代码维护难度。本题选B。
26、以下程序的输出结果是______。
def loc_glo( b = 2, a = 4):
global z
z += 3 * a +5 * b
return z
z = 10
print(z, loc_glo (4,2))
A.1036
B.3232
C.3636
D.1032
【题目解析】
z为全局变量,所以值不变,最后输出仍为10。函数中,返回值为:10+32+54=36。本题选A。
27、以下程序的输出结果是______。
l1=['aa',[2,3,3.0]]
print(l1.index(2))
A.2
B.3.0
C.3
D.ValueError
【题目解析】
索引序号从0开始,不能超过列表的元素范围。l1列表中只有两个元素,l1.index(2)表示取列表中第三个元素,会出错。本题选D。
28、以下程序的输出结果是______。
for i in "Nation":
for k in range(2):
if i == 'n':
break
print(i, end="")
A.aattiioo
B.NNaattiioo
C.Naattiioon
D.aattiioonn
【题目解析】
range(start, stop[, step])表示计数从start开始,到stop结束,但不包括stop,步长默认为1。start默认从0开始,range(2)等价于range(0,2),则k的取值范围为0、1。 break用来跳出最内层循环,脱离该循环后程序从循环后的代码继续执行。第1次循环,i=N,k=0,if判断条件不成立,输出i的值为N。第2次循环,i=N,k=1,if判断条件不成立,输出i的值为N。第3次循环,i=a,k=0,if判断条件不成立,输出i的值为a。第4次循环,i=a,k=1,if判断条件不成立,输出i的值为a。 …… 第11次循环,i=n,k=0,if判断条件成立,跳出内层循环。第12次循环,i=n,k=1,if判断条件成立,跳出内层循环。最后输出为NNaattiioo。本题选B。
29、以下程序的输出结果是______。
x = [90,87,93]
y = ("Aele", "Bob","lala")
z = {}
for i in range(len(x)):
z[i] = list(zip(x,y))
print(z)
A.{0:[(90,'Aele'),(87,'Bob'),(93,'lala')],1:[(90,'Aele'),(87,'Bob'),(93,'lala')],2:[(90,'Aele'),(87,'Bob'),(93,'lala')]}
B.{0:(90,‘Aele’),1:(87,‘Bob’),2:(93,‘lala’)}
C.{0:[90,‘Aele’],1:[87,‘Bob’],2:[93,‘lala’]}
D.{0:([90,87,93],(‘Aele’,‘Bob’,‘lala’)),1:([90,87,93],(‘Aele’,‘Bob’,‘lala’)),2:([90,87,93],(‘Aele’,‘Bob’,‘lala’))}
【题目解析】
len(ls):列表ls的元素个数(长度)。 range(start, stop[, step])表示计数从start开始,到stop结束,但不包括stop,步长默认为1。start默认从0开始,range(len(x))等价于range(0,3),则i的取值范围为0、1、2。 zip():将对象中对应的元素打包成一个个元组,然后返回由这些元组组成的列表。由题面可知,每个键值对的值都是一样的。本题选A。
30、以下程序的输出结果是______。
ss = set("htslbht")
sorted(ss)
for i in ss:
print(i,end = '')
A.tsblth
B.htslbht
C.hlbst
D.hhlstt
【题目解析】
set(x)函数将其他的组合数据类型变成集合类型,返回结果是一个无重复且排序任意的集合。4个选项中只有hlbst符合无重复的要求。本题选C。
31、以下程序的输出结果是______。
ls1=[1,2,3,4,5]
ls2=ls1
ls2.reverse()
print(ls1)
A.[5,4,3,2,1]
B.[1,2,3,4,5]
C.5,4,3,2,1
D.1,2,3,4,5
【题目解析】
ls.reverse():将列表ls中的元素进行逆序反转。对于列表类型,使用等号无法实现真正的赋值,不能产生新列表。ls2 = ls1语句并不是拷贝ls1中的元素给变量ls2,而是新关联了一个引用,即增加一个别名,ls1和ls2所指向的是同一套内容,所以修改了ls2的内容,ls1也是随之改变的。本题选A。
32、为以下程序填空,使得输出结果是{20:‘yingyu’,30:‘shuxue’,40:‘yuwen’}的选项是______。
tb = {'yingyu':20, 'shuxue':30, 'yuwen':40}
stb = {}
for it in tb.items():
print(it)
________________
print(stb)
A.stb[it[1]]=tb[it[0]]
B.stb[it[1]]=stb[it[0]]
C.stb[it[1]]=tb[it[1]]
D.stb[it[1]]=it[0]
【题目解析】
{}用于生成一个空字典,d.items()返回所有的键值对。在本题中,变量it中每一次循环存储一对键值对。题面要求将每一对键值对的键和值交换位置,使用语句stb[it[1]] = it[0]。
33、以下关于文件的描述,错误的是______。
A.当文件以二进制方式打开的时候,是按字节流方式读写
B.open()打开文件后,返回一个文件对象,用于后续的文件读写操作
C.open()打开一个文件,同时把文件内容载入内存
D.write(x)函数要求x必须是字符串类型,不能是int类型
【题目解析】
采用二进制方式打开文件,文件被解析成为字节流。 Python通过open()函数打开一个文件,并返回一个操作这个文件的变量。 f.write(s):向文件写入一个字符串或字节流。本题选C。
34、给以下程序填空,使得输出到文件a.txt里的内容是’90’,‘87’,'93’的选项是______。
y = ['90', '87', '93']
l = ''
with open("a.txt",'w') as fo:
for z in y:
_______________
fo.write(l.strip(','))
A.l+=“‘{}’”.format(z)
B.l+="'{}'".format(z)+','
C.l=‘,’.join(y)
D.l+=‘{}’.format(z)+‘,’
【题目解析】
格式化方法.format()用于解决字符串和变量同时输出时的格式安排问题,使用方式如下: <模板字符串>.format(<逗号分隔的参数>) 其中,模板字符串是一个由字符串和槽组成的字符串,用来控制子串和变量的显示结果。槽用大括号({})表示,对应format()方法中逗号分隔的参数。程序中使用strip()方法去掉数据尾部的逗号,所以程序填空处应该重新加上逗号,所以选项A错误。选项C中使用了中文状态下的引号(若将引号修改为英文状态,输出到文件的内容也与题意不符),所以选项C错误。使用选项D中的代码输出到文件中的内容与题意不符,所以选项D错误。本题选B。
35、以下程序的输出结果是______。
img1 = [12,34,56,78]
img2 = [1,2,3,4,5]
def modi():
img1 = img2
print(img1)
modi()
print(img1)
A.[1,2,3,4,5] [12,34,56,78]
B.[1,2,3,4,5] [1,2,3,4,5]
C.[12,34,56,78] [12,34,56,78]
D.[12,34,56,78] [1,2,3,4,5]
【题目解析】
对于列表类型,使用等号无法实现真正的赋值,不能产生新列表。img1 = img2语句并不是拷贝img2中的元素给变量img1,而是新关联了一个引用,即增加一个别名,img1和img2所指向的是同一套内容,所以调用函数modi()后,输出的img1,指向的是img2的内容,即[1,2,3,4,5]。在函数外部,img1内容不变,所以输出的是[12,34,56,78]。本题选A。
36、以下关于数据维度的描述,错误的是______。
A.二维数据可以看成是多条一维数据的组合形式
B.JSON格式可以表示比二维数据还复杂的高维数据
C.列表的索引值是大于0小于列表长度的整数
D.csv文件既能保存一维数据,也能保存二维数据
【题目解析】
列表的索引值由0开始。本题选C。
37、以下不属于Python的pip工具命令的选项是______。
A.install
B.-V
C.show
D.download
【题目解析】
pip常用的子命令有: install、download、uninstall、freeze、list、show、search、wheel、hash、completion、help。本题选B。
38、用Pyinstaller工具打包Python源文件时-F参数的含义是______。
A.指定所需要的第三方库路径
B.在dist文件夹中只生成独立的打包文件
C.指定生成打包文件的目录
D.删除生成的临时文件
【题目解析】
Pyinstaller命令的常用参数: -h,–help:查看帮助 --clean:清理打包过程中的临时文件 -D,–onedir:默认值,生成dist目录 -F,–onefile:在dist文件夹中只生成独立的打包文件 -i<图标文件名.ico>:指定打包程序使用的图标(icon)文件本题选B。
39、第三方库Beautifulsoup4的功能是______。
A.解析和处理HTML和XML
B.支持web应用程序框架
C.支持webservices框架
D.处理http请求
【题目解析】
Beautifulsoup4库,也称为Beautiful Soup库或bs4库,用于解析和处理HTML和XML。本题选A。
40、以下关于turtle库的描述,错误的是______。
A.seth(x)是setheading(x)函数的别名,让画笔旋转x角度
B.home()函数设置当前画笔位置到原点,方向朝上
C.可以用import turtle来导入turtle库函数
D.在import turtle之后,可以用turtle.circle()语句画一个圆圈
【题目解析】
home()设置当前画笔位置为原点,朝向东。本地选B。本题选B。
二、基本操作

s = input()
print("{:\"^30x}".format(eval(s)))
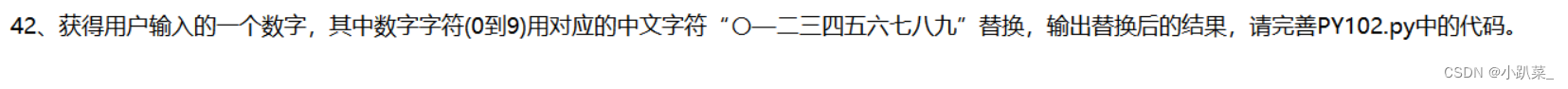
n = input()
s = "〇一二三四五六七八九"
for c in "0123456789":
n = n.replace(c,s[int(c):int(c)+1])
print(n)

a, b, c = eval(input())
ls = []
for i in range(c):
ls.append(str(a*(b**i)))
print(",".join(ls))
三、简单应用

import turtle
turtle.pensize(2)
for i in range(4):
turtle.fd(200)
turtle.left(90)
turtle.left(-45) # 向下转45度
turtle.circle(100*pow(2,0.5)) # 画圆

while True:
s = input("请输入不带数字的文本:")
j = 0
for i in s:
if "0"<=i<="9":
j += 1
if j == 0:
break
print(len(s))
四、综合应用

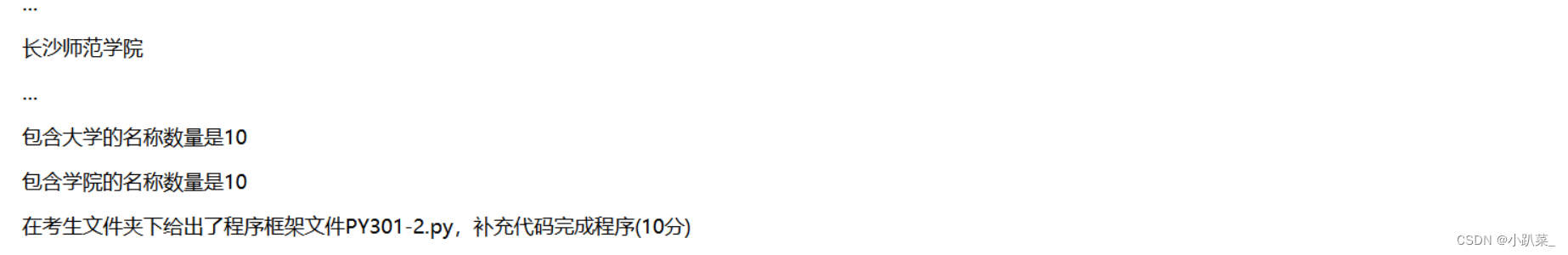
问题1:
fr = open("data.txt","r")
lines=fr.readlines() # 读取全部行
fr.close()
f = open("univ.txt", "w")
for line in lines:
if "alt" in line: # 判断在学校段的alt字符
ls = line.split("alt=")[-1].split('"')[1]
f.write("{}\n".format(ls))
f.close()
问题2:
n = 0
m = 0
f = open("univ.txt", "r")
lines = f.readlines()
f.close()
for line in lines:
if "大学生" in line:
continue
elif "大学" in line:
print("{}".format(line))
n += 1
elif "学院" in line:
print("{}".format(line))
m += 1
print("包含大学的名称数量是{}".format(n))
print("包含学院的名称数量是{}".format(m))
![[附源码]SSM计算机毕业设计中青年健康管理监测系统JAVA](https://img-blog.csdnimg.cn/a7a2b4462a574ce286ba4f4c11316374.png)