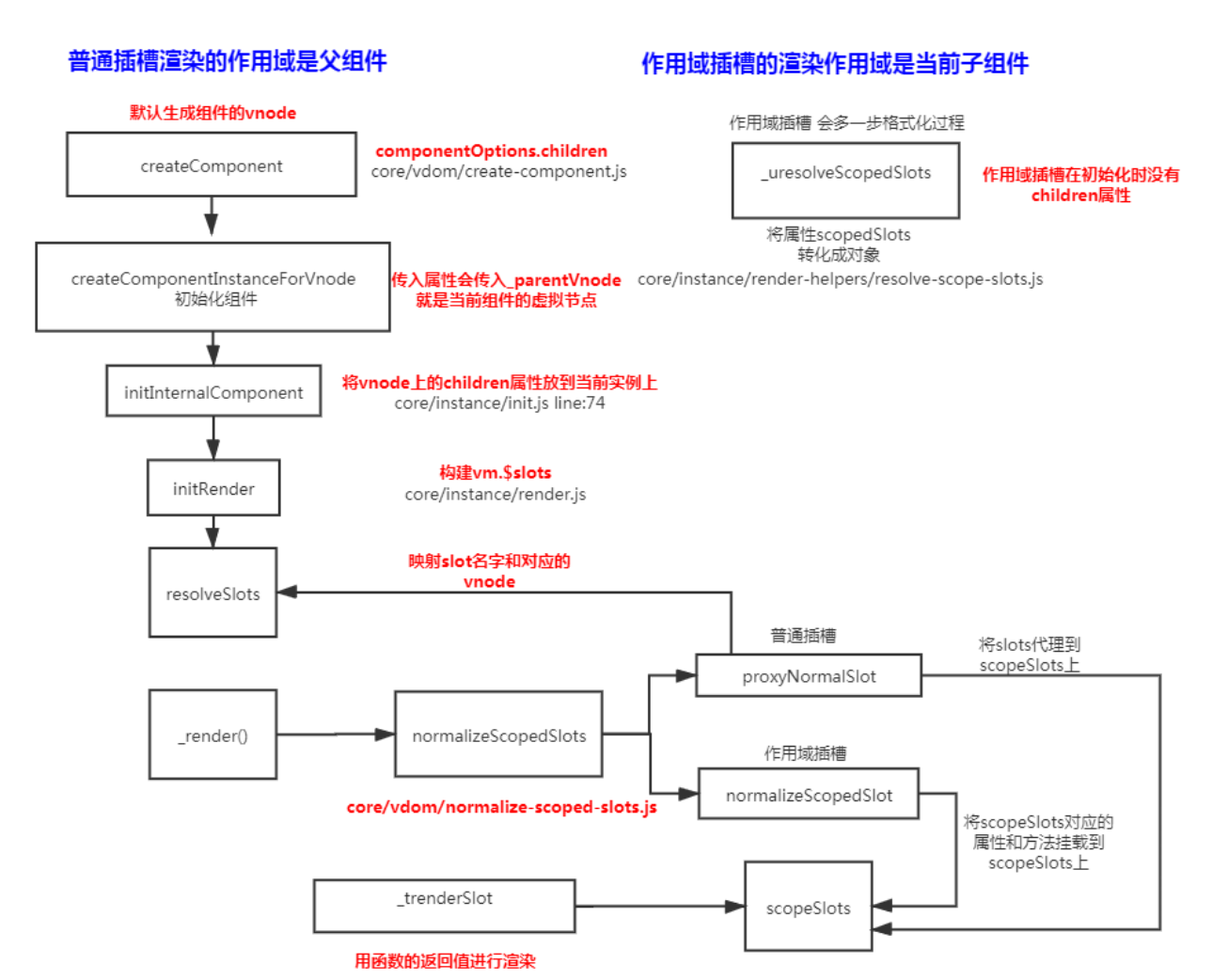
1.理论部分
随机森林(Random Forest),顾名思义,就是由很多决策树模型融合在一起的算法。
随机森林是一种运用了集成学习(ensemble learning)的决策树分类器。
- 随机森林是一种基于Bagging框架的模型融合算法,如图1.2所示。它通过多个基础的决策树模型进行训练,如何通过结合模块将多个分类器训练得到的结果进行融合最终得到预测结果
- 随机森林的“森林”指的就是它的弱模型是由决策树算法训练的(具体是CART算法),CART算法既能做分类也能做回归(CART算法详情可见上述决策树章节)
- 随机森林的“随机”指的是构造的若干个弱模型是有一定的“随机性”的
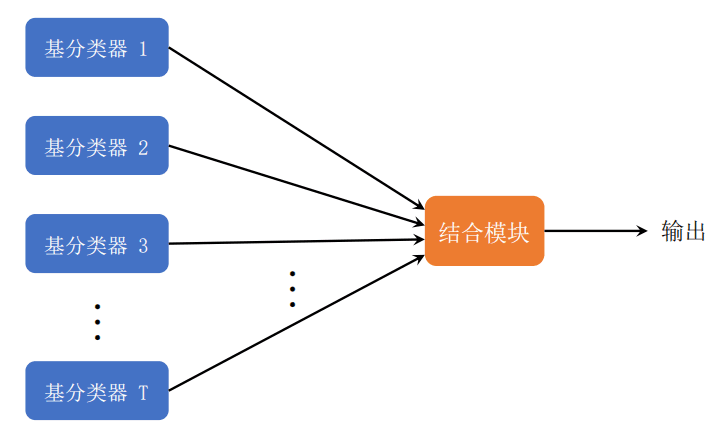
图1.2
1.1 随机森林的“随机”性体现在:
- 子模型的训练样本是随机抽取的
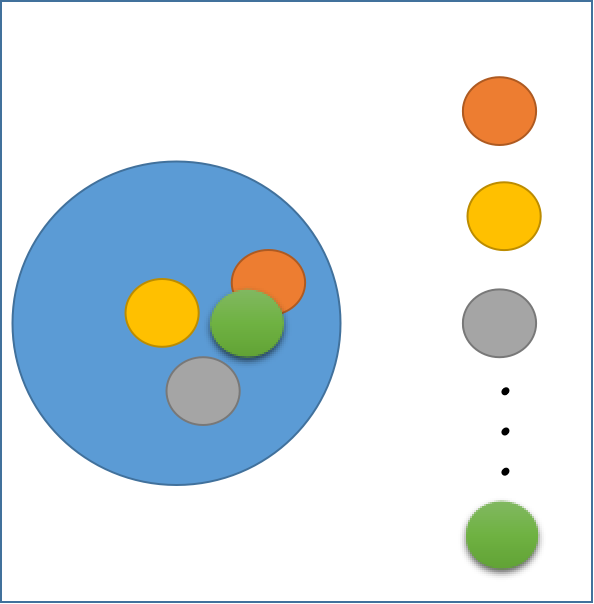
图1.3
对于包含 n 个样本的数据集,我们先分n次随机有放回地采样出n个样本,组成采样集。由于是 n次有放回地采样,来自初始数据集的样本在这个采样集中,有的样本出现了多次,有的样本则从未出现(通过证明可得约有 63.2%的样本出现在采样




![E 排队(排列组合)[牛客小*白月赛61]](https://img-blog.csdnimg.cn/56faf4516fb442d39457b204ee2f42be.png)


![[附源码]Python计算机毕业设计jspm郫县兼职信息系统](https://img-blog.csdnimg.cn/60b7e503478642ecaa6f4e8a85eb2c5c.png)

![[附源码]Python计算机毕业设计爱行无忧旅游票务管理系统](https://img-blog.csdnimg.cn/e0d03184cf99429ab9a8eaaa38f1b848.png)