文章目录
- 1.583两个字符串的删除操作
- 1.1.题目
- 1.2.解答
- 2.72编辑距离
- 2.1.题目
- 2.2.解答
1.583两个字符串的删除操作
参考:代码随想录,583两个字符串的删除操作;力扣题目链接
1.1.题目

1.2.解答
本题和 动态规划:115.不同的子序列 相比,其实就是两个字符串都可以删除了,情况虽说复杂一些,但整体思路是不变的。
这次是两个字符串可以相互删了,这种题目也知道用动态规划的思路来解,动规五部曲分析如下:
1.确定dp数组(dp table)以及下标的含义
dp[i][j]:以i-1为结尾的字符串word1,和以j-1位结尾的字符串word2,想要达到相等,所需要删除元素的最少次数。
注意:这里说的是删除元素的最小次数,也就是删谁都可以。另外注意,这里以i-1/j-1结尾并不是说最后匹配的字符串中就必须有最后这两个字符,因为最后这两个字符可能是不相等的,那么就必须进行删除其中的一些字符让他们相等。
2.确定递推公式
(1) 当word1[i - 1] 与 word2[j - 1]相同的时候,dp[i][j] = dp[i - 1][j - 1];。这个很好理解,因为此时两个字符串的最后一个字符是相等的, 所以在最后一个字符上他们谁都不需要删除字符。因此整个字符相等需要删除的个数就是除了最后一个字符之外的前面的字符串相等要删除的个数。
(2) 当word1[i - 1] 与 word2[j - 1]不相同的时候,有三种情况:
- 情况一:删
word1[i - 1],最少操作次数为dp[i - 1][j] + 1。也就是说用word1当前字符之前的子串和word2做匹配,就相当于把word1的当前字符删掉了,所以最后结果要在子串匹配的结果基础上+1。 - 情况二:删
word2[j - 1],最少操作次数为dp[i][j - 1] + 1。这个原理同上,只不过删word2的字符。 - 情况三:同时删
word1[i - 1]和word2[j - 1],操作的最少次数为dp[i - 1][j - 1] + 2。其实道理和上面也是一样的,就是全部都用前面的子串来匹配。
那最后当然是取最小值,所以当word1[i - 1] 与 word2[j - 1]不相同的时候,递推公式:dp[i][j] = min({dp[i - 1][j - 1] + 2, dp[i - 1][j] + 1, dp[i][j - 1] + 1});
因为dp[i - 1][j - 1] + 1等于 dp[i - 1][j] 或 dp[i][j - 1],所以递推公式可简化为:dp[i][j] = min(dp[i - 1][j] + 1, dp[i][j - 1] + 1);。注意:这里就是说,dp[i - 1][j - 1] + 2可以分解成dp[i - 1][j] + 1 或 dp[i][j - 1] +1,虽然具体是哪个不知道,但是已经在前两种情况之中了,所以最后我们直接比较前两种情况中的最小值就行了,因为第三种情况的值就是前两种情况中的其中一个。
3.dp数组如何初始化
从递推公式中,可以看出来,dp[i][0] 和 dp[0][j]是一定要初始化的。
-
dp[i][0]:word2为空字符串,以i-1为结尾的字符串word1要删除多少个元素,才能和word2相同呢,很明显dp[i][0] = i。 -
dp[0][j]的话同理。
所以代码如下:
vector<vector<int>> dp(word1.size() + 1, vector<int>(word2.size() + 1));
for (int i = 0; i <= word1.size(); i++) dp[i][0] = i;
for (int j = 0; j <= word2.size(); j++) dp[0][j] = j;
4.确定遍历顺序
从递推公式 dp[i][j] = min(dp[i - 1][j - 1] + 2, min(dp[i - 1][j], dp[i][j - 1]) + 1); 和dp[i][j] = dp[i - 1][j - 1]可以看出dp[i][j]都是根据左上方、正上方、正左方推出来的。
所以遍历的时候一定是从上到下,从左到右,这样保证dp[i][j]可以根据之前计算出来的数值进行计算。
5.举例推导dp数组
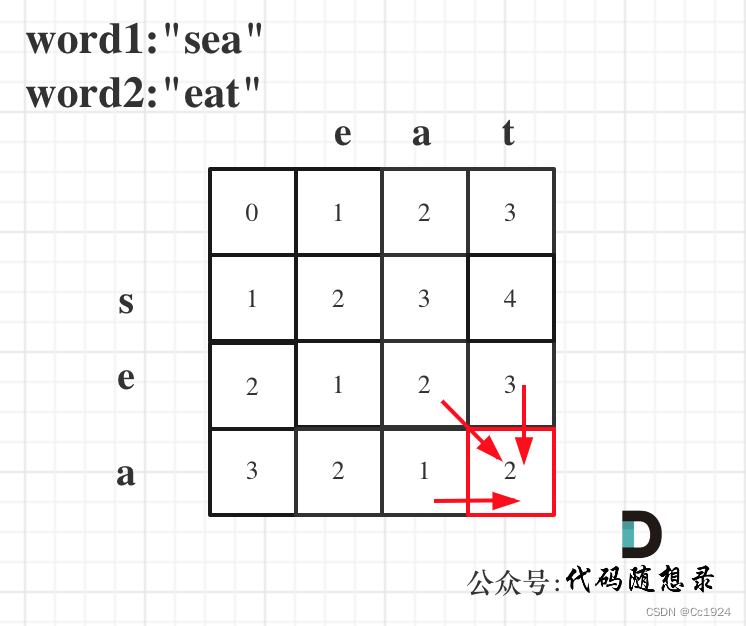
以word1:"sea",word2:"eat"为例,推导dp数组状态图如下:
最后给出代码如下:
int minDistance(string word1, string word2)
{
// 1.定义dp数组
vector<vector<int>> dp(word1.size()+1, vector<int>(word2.size()+1, 0));
// 2.初始化dp数组
for(int i = 0; i <= word1.size(); i++)
dp[i][0] = i;
for(int j = 0; j <= word2.size(); j++)
dp[0][j] = j;
// 3.动态规划:使用递推公式开始递推
for(int i = 1; i <= word1.size(); i++)
{
for(int j = 1; j <= word2.size(); j++)
{
if(word1[i-1] == word2[j-1])
dp[i][j] = dp[i-1][j-1];
else
dp[i][j] = min(dp[i-1][j-1]+2, min(dp[i-1][j]+1, dp[i][j-1]+1));
}
}
// 最后返回结果
return dp[word1.size()][word2.size()];
}
2.72编辑距离
参考:代码随想录,72编辑距离;力扣题目链接
2.1.题目

2.2.解答
注意:这道题目和上一道题目非常相似,简直可以说是一模一样。题目的关键在于如何理解在word1中增加一个字符,要把它等价转化为在word2中删除一个字符,具体如何理解看下面自己的解释。
编辑距离是用动规来解决的经典题目,这道题目看上去好像很复杂,但用动规可以很巧妙的算出最少编辑距离。接下来依然使用动规五部曲,对本题做一个详细的分析:
1.确定dp数组(dp table)以及下标的含义
dp[i][j] 表示以下标i-1为结尾的字符串word1,和以下标j-1为结尾的字符串word2,最近编辑距离为dp[i][j]。
2.确定递推公式
在确定递推公式的时候,首先要考虑清楚编辑的几种操作,整理如下:
if (word1[i - 1] == word2[j - 1])
不操作
if (word1[i - 1] != word2[j - 1])
增
删
换
(1) 当前字符相等,if (word1[i - 1] == word2[j - 1]), 那么说明不用任何编辑,dp[i][j] 就应该是 dp[i - 1][j - 1],即dp[i][j] = dp[i - 1][j - 1];
(2) 当前字符不相等,if (wor*d1[i - 1] != word2[j - 1]),此时就需要编辑了,需要对word1选择增 或 删 或 改 其中一个操作:
-
操作一:替换元素,把
word1的当前元素替换成和word2的当前元素相等的,这里首先有一个替换操作,记录1次。然后此时剩下的编辑次数就是 以下标i-2为结尾的word1与j-2为结尾的word2的最近编辑距离,也就是word1和word2前面的子串进行匹配需要的最小编辑次数。因此使用替换元素的操作,最后操作次数为dp[i][j] = dp[i - 1][j - 1] + 1; -
操作二:
word1删除一个元素,那么就是以下标i - 2为结尾的word1与j-1为结尾的word2的最近编辑距离 再加上一个操作。即dp[i][j] = dp[i - 1][j] + 1; -
操作三:
word1增加一个元素,此时等价于word2删除一个元素,那么就是以下标i - 1为结尾的word1与j-2为结尾的word2的最近编辑距离 再加上一个操作。即dp[i][j] = dp[i][j - 1] + 1;
注意:其实这里从word1中增加一个字符,等价于从word2中删除一个字符,理解如下:此时的大前提是word1和word2的当前字符已经不相等了,所以我需要编辑word1的字符,让它和word2的当前字符相等。并且现在我们选择的是在word1的当前位置插入一个字符,自然我们插入的就是word2的当前字符,因为我们插入字符的目的就是让word1和word2的最后一个字符相等。插入字符之后,相当于word2的最后一个字符已经确定和插入后新的word1的最后一个字符匹配了,那么我们要统计的修改次数就是word2的前面的子串 和 插入后新的word1的前面的子串(也就是原来未插入的word1) 之间匹配的最小次数。
比如原先word1 = "abcde",word2 = "abcfg",此时发现word2的最后一个字符g和word1的最后一个字符e不匹配,所以我们就在word1的最后插入一个g,结果word1 = "abcdeg",word2 = abcfg。显然此时word1和word2的最后一个字符g已经匹配上了,所以剩下的匹配要编辑的次数就是word1的前面的子串abcde和word2的前面的子串abcf之间进行匹配。可以发现,此时其实就是保持word1不动,而从word2中删除最后一个元素。
综上,当 if (word1[i - 1] != word2[j - 1]) 时取最小的,即:dp[i][j] = min({dp[i - 1][j - 1], dp[i - 1][j], dp[i][j - 1]}) + 1;
递归公式代码如下:
if (word1[i - 1] == word2[j - 1]) {
dp[i][j] = dp[i - 1][j - 1];
}
else {
dp[i][j] = min({dp[i - 1][j - 1], dp[i - 1][j], dp[i][j - 1]}) + 1;
}
3.dp数组如何初始化
再次回顾dp数组的定义:dp[i][j] 表示以下标i-1为结尾的字符串word1,和以下标j-1为结尾的字符串word2,最近编辑距离为dp[i][j]。
那么dp[i][0] 和 dp[0][j] 表示什么呢?
-
dp[i][0]:以下标i-1为结尾的字符串word1,和空字符串word2,最近编辑距离为dp[i][0]。那么dp[i][0]就应该是i,对word1里的元素全部做删除操作,即:dp[i][0] = i; -
同理
dp[0][j] = j;,就是对word1里面的元素全部做添加操作。
代码如下:
for (int i = 0; i <= word1.size(); i++) dp[i][0] = i;
for (int j = 0; j <= word2.size(); j++) dp[0][j] = j;
4.确定遍历顺序
从如下四个递推公式:
dp[i][j] = dp[i - 1][j - 1]
dp[i][j] = dp[i - 1][j - 1] + 1
dp[i][j] = dp[i][j - 1] + 1
dp[i][j] = dp[i - 1][j] + 1
可以看出dp[i][j]是依赖左方,上方和左上方元素的,所以要从上往下、从左往右遍历。
代码如下:
for (int i = 1; i <= word1.size(); i++) {
for (int j = 1; j <= word2.size(); j++) {
if (word1[i - 1] == word2[j - 1]) {
dp[i][j] = dp[i - 1][j - 1];
}
else {
dp[i][j] = min({dp[i - 1][j - 1], dp[i - 1][j], dp[i][j - 1]}) + 1;
}
}
}
5.举例推导dp数组
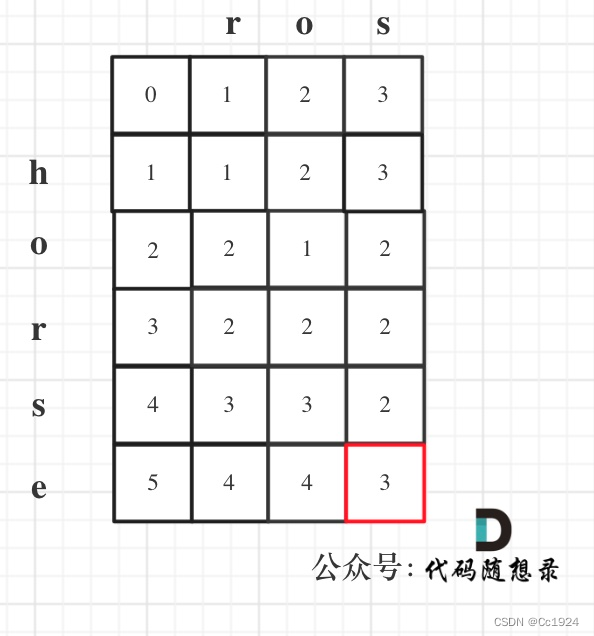
以示例1为例,输入:word1 = "horse", word2 = "ros"为例,dp矩阵状态图如下:
最后给出代码如下:
int minDistance(string word1, string word2)
{
// 1.dp数组定义
vector<vector<int>> dp(word1.size()+1, vector<int>(word2.size()+1, 0));
// 2.dp数组初始化
for(int i = 0; i <= word1.size(); i++)
dp[i][0] = i; // word2是空,只能是word1一直在删除
for(int j = 0; j <= word2.size(); j++)
dp[0][j] = j; // word1是空,只能是word1一直在添加
// 3.动态规划:使用递推公式开始递推
for(int i = 1; i <= word1.size(); i++)
{
for(int j = 1; j <= word2.size(); j++)
{
// 1.word1字符等于word2字符,则不需要对word1当前位置做任何增删改操作
if(word1[i-1] == word2[j-1])
dp[i][j] = dp[i-1][j-1];
// 2.否则对word1有增删改三种情况,取他们操作的最小值:
// (1)word1修改当前字符,让当前字符变成和word2的当前字符相等,那么此时匹配的最小修改次数
// 就相当于word1/2都是用前面的子串进行匹配的次数,结果是dp[i-1][j-1]+1
// (2)word1删除当前字符,即word1之前的子串匹配当前位置的word2,结果是dp[i-1][j]+1
// (3)word1增加一个字符,其实这等效于把Word2删除当前字符,从而再与word1匹配,所以和(1)
// 非常相似,只不过是删除word2中当前位置的字符,结果是dp[i][j-1]+1
else
dp[i][j] = min(dp[i-1][j-1], min(dp[i-1][j], dp[i][j-1])) + 1;
}
}
// 最后返回结果
return dp[word1.size()][word2.size()];
}






![[R]第二节 对象介绍与赋值运算](https://img-blog.csdnimg.cn/img_convert/503ef4cdf5d769cc9c3aeda4a2989a4e.png)