目录
1.链表
1.1 链表的概念及结构
1.2 链表的分类
1. 单向或者双向
2. 带头或者不带头
3. 循环或者非循环
1.3实现一个单链表(无头单项非循环链表增删查改的实现)
1.链表结构的创建
2.创建一个节点
3.创建一个链表
4.打印链表
5.链表尾插
6.链表尾删
7.链表头插
8.链表头删
9.找链表节点
10.在pos位置后面插入一个节点x
11.在pos位置前面插入一个节点x
12.在pos位置删除后面的一个节点x
13.删除pos位置处的节点
2.完整单链表实现代码
2.1头文件代码(SList.h)
2.2函数定义代码(SList.c)
2.3测试代码(test.c)
问题1.为什么需要链表结构?
那先看看已有的顺序表的缺陷吧,顺序表空间不够的话,需要扩容
扩容是需要代价的,(尤其是异地扩容),消耗的连续空间更多,而且可能会造成空间浪费
扩容一般是扩充一倍,此时空间的大小就可能造成浪费,而且对于数组的增删查改需要挪动整个数组,效率低下。
由此就引出了链表结构
1.链表
1.1 链表的概念及结构
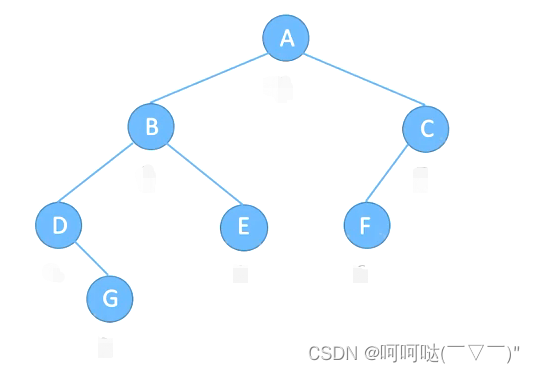
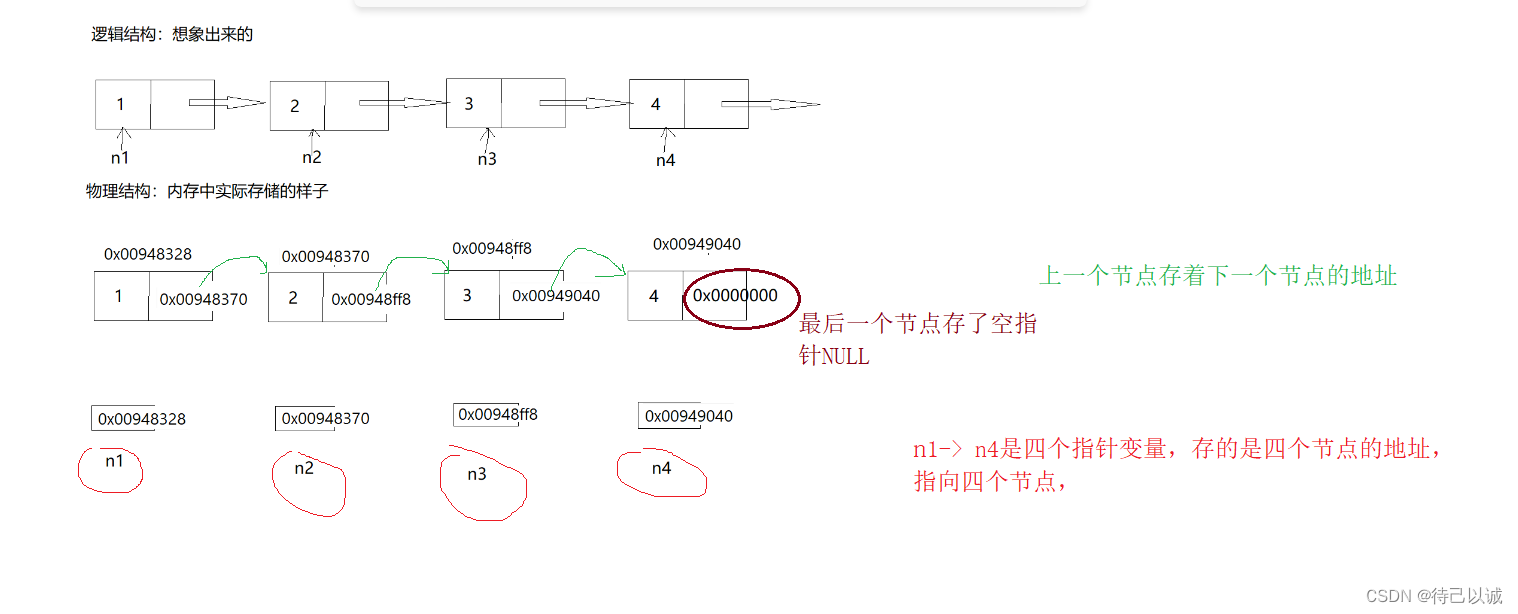
我的理解1:顺序表的本质是一个结构,里面存的是整体数据本身链表的本质也是一个结构,里面存的是一个链表节点的数据和下一个链接节点的地址,这样在空间上不连续,但是在逻辑上,上一个节点可以通过下一个节点的地址找到下一个节点,拿到下一个节点存的数据,(当然通过合理的存放地址,也可以从下一个节点访问到上一个节点,这里我们不做深究,先弄懂最基本的链式的原理)

PS:
1.由上图可知,链式结构在逻辑上是连续的,但是在物理上不一定连续
2.现实中的节点一般都是在堆(realloc malloc)上申请出来的
3.从堆上申请的空间是按照一定的策略分配的,两次申请的空间,可能连续,也可能不连续。
1.2 链表的分类
实际中链表的结构非常多样,只要具有链式逻辑的结构都可以纳入链表范畴
此文就以以下情况组合起来的8种链表结构探究:
1. 单向或者双向
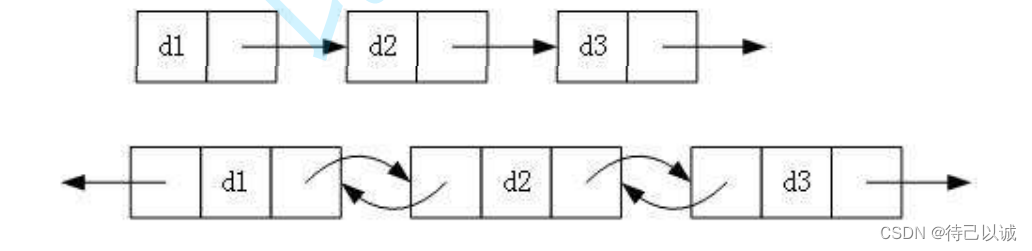
2. 带头或者不带头
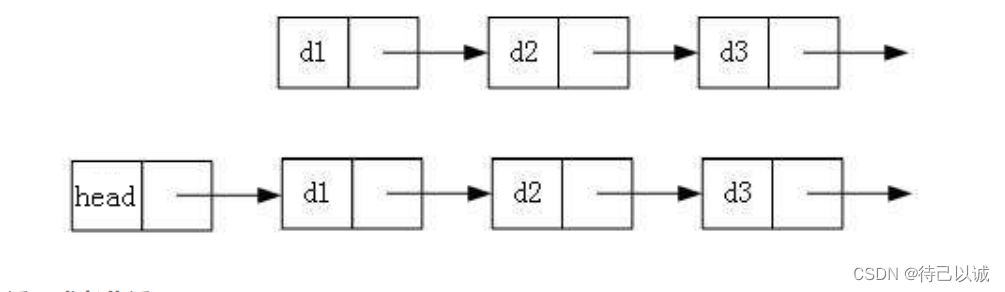
3. 循环或者非循环
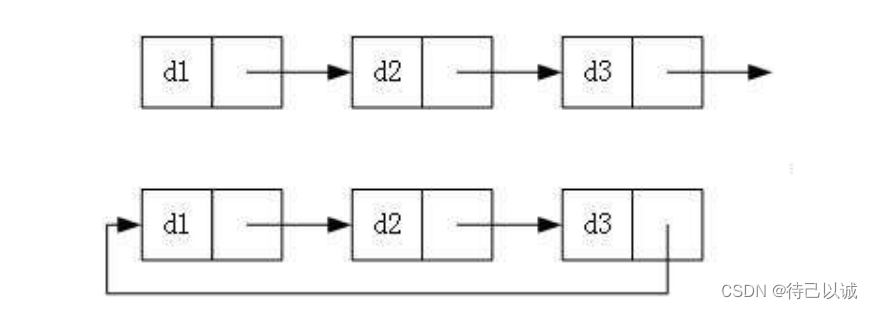
虽然有这么多的链表的结构,但是我们实际中最常用还是两种结构:
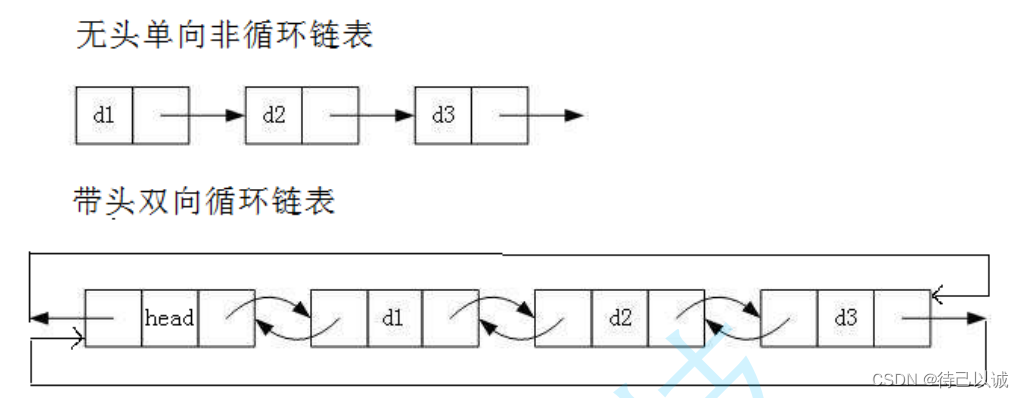
1.3实现一个单链表(无头单项非循环链表增删查改的实现)
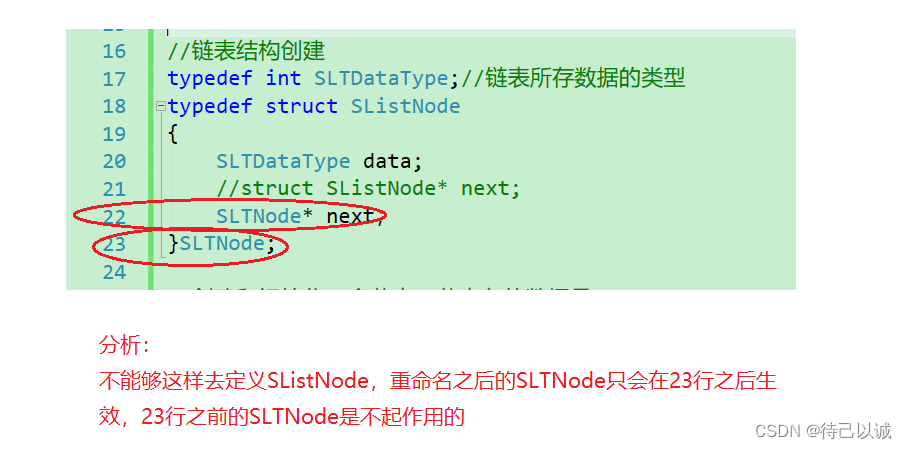
1.链表结构的创建
//链表结构创建
typedef int SLTDataType;//链表所存数据的类型
typedef struct SListNode
{
SLTDataType data;
struct SListNode* next;//下个同类型结构体的地址,以便于找到下一个节点
}SLTNode;
PS:
链表结构创建的误区如下:
2.创建一个节点
//申请一个节点
SLTNode* BuySLTNode(SLTDataType x)
{
SLTNode* newnode = (SLTNode*)malloc(sizeof(SLTNode));
if (newnode == NULL)
{
perror("malloc fail");
exit(-1);
}
newnode->data = x;
newnode->next = NULL;
return newnode;
}测试代码如下:
void TestSList0()
{
//创建一个个没有联系的节点
SLTNode* n1 = BuySLTNode(1);
SLTNode* n2 = BuySLTNode(2);
SLTNode* n3 = BuySLTNode(3);
SLTNode* n4 = BuySLTNode(4);
//前一个节点里面的next指针存的是下一个节点的地址
//因此可以达到通过第一个节点就(像链条一样)能找到后面所有节点的效果
//此种数据存储的方式为----单链表
n1->next = n2;
n2->next = n3;
n3->next = n4;
n4->next = NULL;
//这样链接节点太废代码
//可以将链接节点封装成一个函数
}分析如下:
但是用这种方法把节点链接起来太低效了。
3.创建一个链表
//创建一个链表,链表里面有n个节点
SLTNode* CreateSList(int n)
{
SLTNode* phead = NULL;//链表头
SLTNode* ptail = NULL;//链表尾
int x = 0;
for (int i = 0; i < n; ++i)
{
//scanf("%d", &x);
//SLTNode* newnode = BuySLTNode(x);
SLTNode* newnode = BuySLTNode(i);
//链接节点
if (phead == NULL)
{
ptail = phead = newnode;
}
else
{
//next存的下一个节点的地址
//下一个节点成为新的尾
ptail->next = newnode;
ptail = newnode;
}
}
//ptail->next = NULL;
return phead;
}4.打印链表
//打印链表
void SLTPrint(SLTNode* phead)
{
SLTNode* cur = phead;
while (cur != NULL)
{
//printf("[%d|%p]->", cur->data, cur->next);
printf("%d->", cur->data);
cur = cur->next;//节点往链表后走
}
printf("NULL\n");
}测试如下:
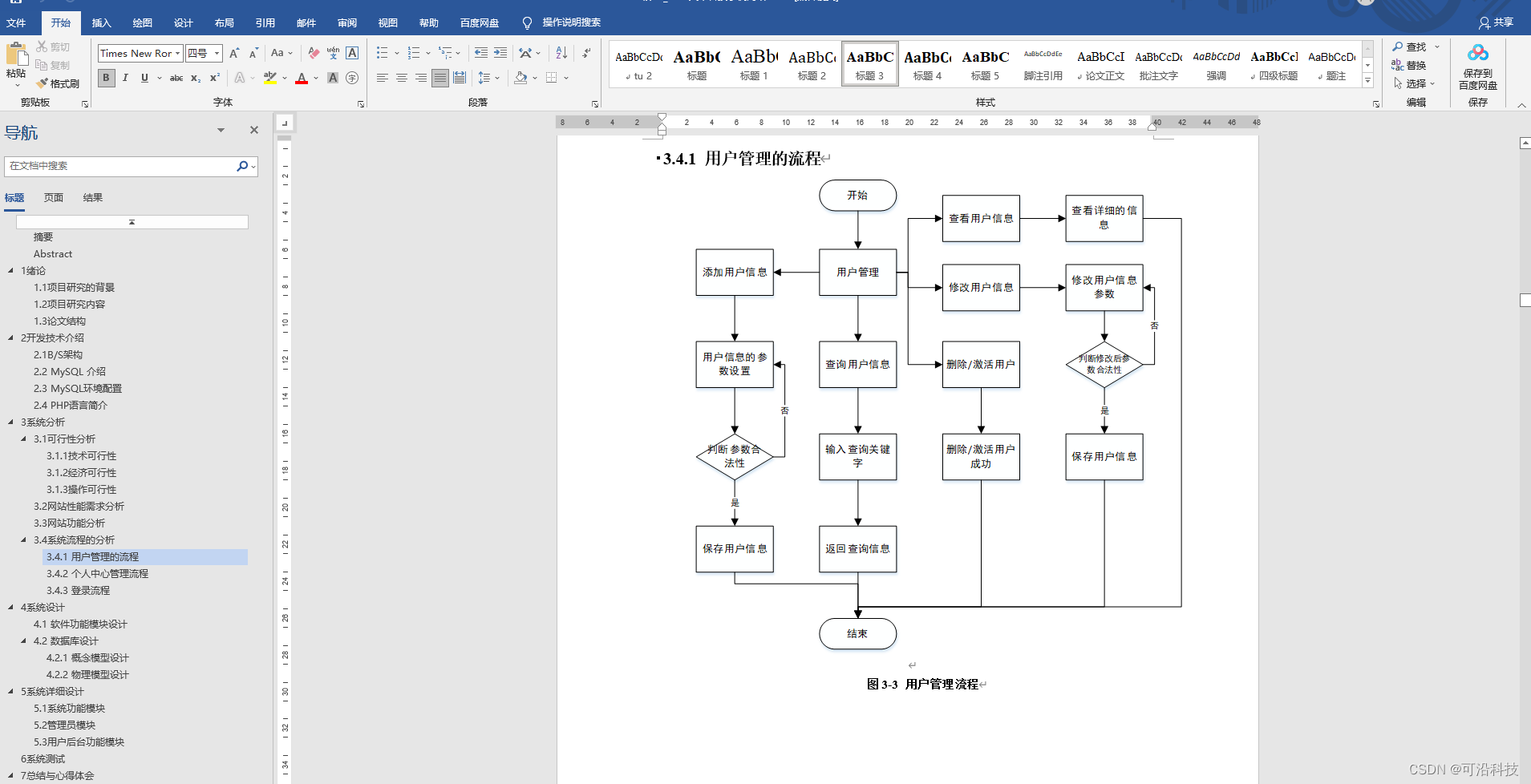
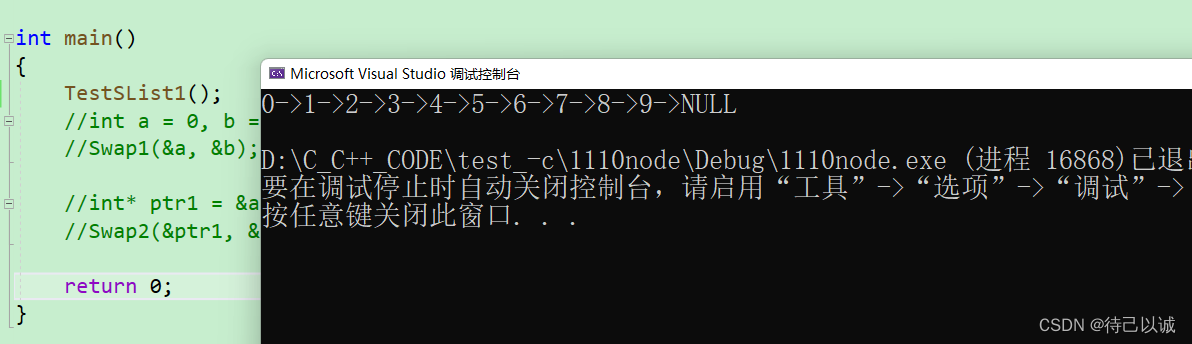
void TestSList1() { SLTNode* plist = CreateSList(10); SLTPrint(plist); } int main() { TestSList1(); //int a = 0, b = 1; //Swap1(&a, &b); //int* ptr1 = &a, *ptr2 = &b; //Swap2(&ptr1, &ptr2); return 0; }如图:
5.链表尾插
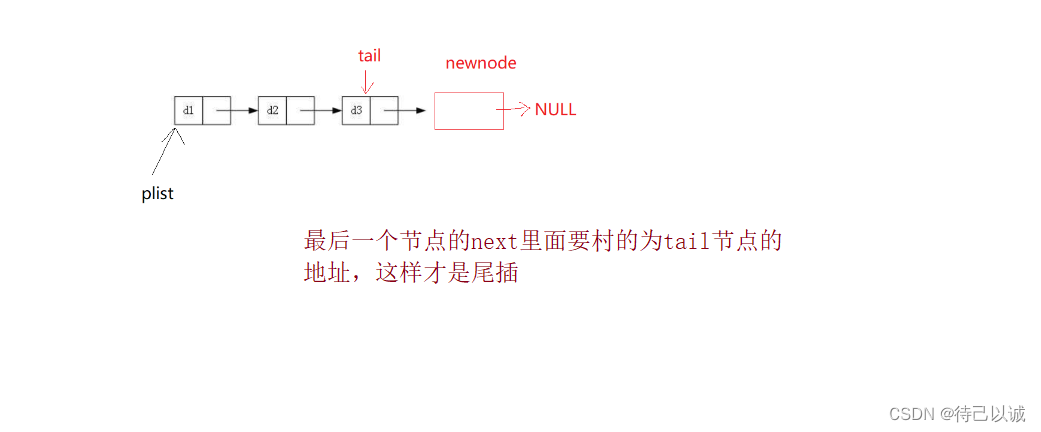
//尾插
void SLTPushBack(SLTNode** pphead, SLTDataType x)
{
SLTNode* newnode = BuySLTNode(x);
//尾插的时候没有节点
if (*pphead == NULL)
{
*pphead = newnode;
}
//尾插的时候已经有节点
else
{
SLTNode* tail = *pphead;
// 找尾
while (tail->next)
{
tail = tail->next;
}
tail->next = newnode;
}
}总结:

6.链表尾删
void SLTPopBack(SLTNode** pphead)
{
// 暴力的检查
assert(*pphead);
// 温柔的检查
//if (*pphead == NULL)
// return;
//只有一个节点的尾删
if ((*pphead)->next == NULL)
{
free(*pphead);
*pphead = NULL;
}
//多个节点的尾插
else
{
//写法1
/*SLTNode* prev = NULL;
SLTNode* tail = *pphead;
while (tail->next)
{
prev = tail;
tail = tail->next->next;
}
free(tail);
prev->next = NULL;*/
//写法2
//其实tail->next相当于写法1的prev,tail->next->next相当于代码1中的tail->next->next
//也即是说两次指向的next可以代替掉代码1的prev
SLTNode* tail = *pphead;
while (tail->next->next)
{
tail = tail->next;
}
free(tail->next);
tail->next = NULL;
}
}分析:
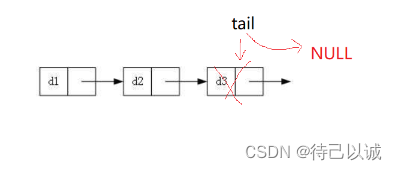
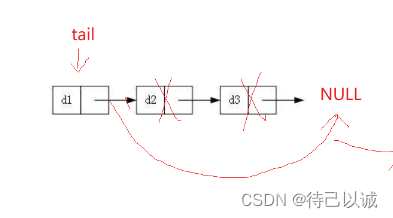
1.多个节点的尾删
2.一个节点的尾删
只有一个节点的话,就直接free掉就行了
7.链表头插
void SLTPushFront(SLTNode** pphead, SLTDataType x)
{
SLTNode* newnode = BuySLTNode(x);
newnode->next = *pphead;
*pphead = newnode;
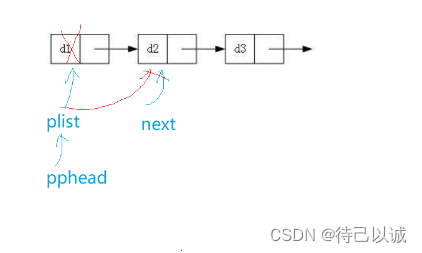
}分析:
只需要创建一个节点指向原来的第一个节点
并且把指向原来头节点的指针指向新的节点就行
8.链表头删
void SLTPopFront(SLTNode** pphead)
{
assert(*pphead);
SLTNode* next = (*pphead)->next;
free(*pphead);
*pphead = next;
}PS:
单链表最大的优势是头插和头删,这两个很快,但是尾插和尾删慢(因为要遍历链表)
9.找链表节点
SLTNode* SLTFind(SLTNode* phead, SLTDataType x)
{
SLTNode* cur = phead;
while (cur)
{
if (cur->data == x)
{
return cur;
}
cur = cur->next;
}
return NULL;
}分析:找到就返回结点的地址,没找到就继续往下找。
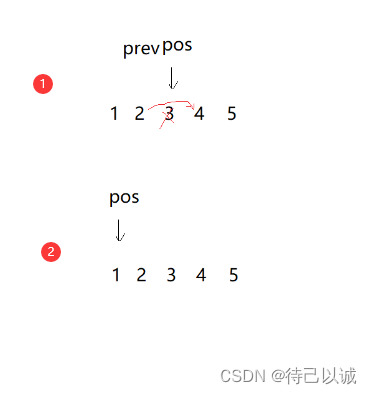
10.在pos位置后面插入一个节点x
void SLTInsertAfter(SLTNode* pos, SLTDataType x)
{
assert(pos);
/*if (pos == NULL)
{
return;
}*/
SLTNode* newnode = BuySLTNode(x);
newnode->next = pos->next;
pos->next = newnode;
}注意
newnode->next = pos->next;
pos->next = newnode;
这两句代码的位置,如果顺序想法,会导致死循环。
11.在pos位置前面插入一个节点x
// 在pos之前插入x
void SLTInsert(SLTNode** pphead, SLTNode* pos, SLTDataType x)
{
assert(pos);
if (*pphead == pos)
{
SLTPushFront(pphead, x);
}
else
{
SLTNode* prev = *pphead;
while (prev->next != pos)
{
prev = prev->next;
}
SLTNode* newnode = BuySLTNode(x);
prev->next = newnode;
newnode->next = pos;
}
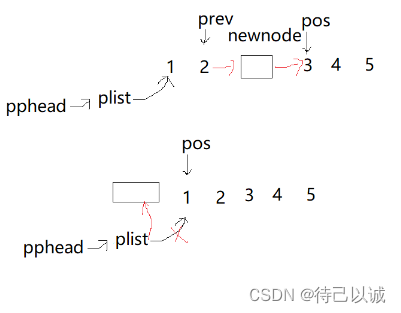
}有两种情况
第一种情况是头插
第二种情况是非头插
12.在pos位置删除后面的一个节点x
void SLTEraseAfter(SLTNode* pos)
{
assert(pos);
if (pos->next == NULL)//删最后一个
{
return;
}
else
{
// 错的
/*free(pos->next);
pos->next = pos->next->next;*/
SLTNode* nextNode = pos->next;
//pos->next = pos->next->next;
pos->next = nextNode->next;
free(nextNode);
//nextNode = NULL;
}
}13.删除pos位置处的节点
// 删除pos位置
void SLTErase(SLTNode** pphead, SLTNode* pos)
{
assert(pos);
assert(*pphead);
if (pos == *pphead)
{
SLTPopFront(pphead);
}
else
{
SLTNode* prev = *pphead;
while (prev->next != pos)
{
prev = prev->next;
}
prev->next = pos->next;
free(pos);
//pos = NULL;
}
}分析:
第一种情况pos节点是头节点
第二种情况pos节点是非头节点
2.完整单链表实现代码
2.1头文件代码(SList.h)
#define _CRT_SECURE_NO_WARNINGS 1
#pragma once
#include <stdio.h>
#include <stdlib.h>
#include <assert.h>
//链表结构创建
typedef int SLTDataType;//链表所存数据的类型
typedef struct SListNode
{
SLTDataType data;
struct SListNode* next;//下个同类型结构体的地址,以便于找到下一个节点
}SLTNode;
链表结构创建(错误的创建方法)
//typedef int SLTDataType;//链表所存数据的类型
//typedef struct SListNode
//{
// SLTDataType data;
// //struct SListNode* next;
// SLTNode* next;
//}SLTNode;
//创建和初始化一个节点,节点存的数据是x
SLTNode* BuySLTNode(SLTDataType x);
//创建一个链表,链表里面有n个节点
SLTNode* CreateSList(int n);
//打印链表,链表的起始地址是phead
void SLTPrint(SLTNode* phead);
//单链表尾插
void SLTPushBack(SLTNode** pphead, SLTDataType x);
//单链表尾删
void SLTPopBack(SLTNode** pphead);
//单链表头插
void SLTPushFront(SLTNode** pphead, SLTDataType x);
//单链表头删
void SLTPopFront(SLTNode** pphead);
SLTNode* SListFind(SLTNode* plist, SLTDataType x);
// 单链表在pos位置之后插入x
// 分析思考为什么不在pos位置之前插入?
void SLTInsertAfter(SLTNode* pos, SLTDataType x);
// 单链表删除pos位置之后的值
// 分析思考为什么不删除pos位置?
void SLTEraseAfter(SLTNode* pos);
// 在pos之前插入x
void SLTInsert(SLTNode** pphead, SLTNode* pos, SLTDataType x);
// 删除pos位置
void SLTErase(SLTNode** pphead, SLTNode* pos, SLTDataType x);
//单链表的释放
void SLTDestroy(SLTNode** pphead)2.2函数定义代码(SList.c)
#define _CRT_SECURE_NO_WARNINGS 1
#include "SList.h"
//申请一个节点
SLTNode* BuySLTNode(SLTDataType x)
{
SLTNode* newnode = (SLTNode*)malloc(sizeof(SLTNode));
if (newnode == NULL)
{
perror("malloc fail");
exit(-1);
}
newnode->data = x;
newnode->next = NULL;
return newnode;
}
//创建一个链表,链表里面有n个节点
SLTNode* CreateSList(int n)
{
SLTNode* phead = NULL;//链表头
SLTNode* ptail = NULL;//链表尾
int x = 0;
for (int i = 0; i < n; ++i)
{
//scanf("%d", &x);
//SLTNode* newnode = BuySLTNode(x);
SLTNode* newnode = BuySLTNode(i);
//链接节点
if (phead == NULL)
{
ptail = phead = newnode;
}
else
{
ptail->next = newnode;
ptail = newnode;
}
}
//ptail->next = NULL;
return phead;
}
//打印链表
void SLTPrint(SLTNode* phead)
{
SLTNode* cur = phead;
while (cur != NULL)
{
//printf("[%d|%p]->", cur->data, cur->next);
printf("%d->", cur->data);
cur = cur->next;//节点往链表后走
}
printf("NULL\n");
}
//尾插
void SLTPushBack(SLTNode** pphead, SLTDataType x)
{
SLTNode* newnode = BuySLTNode(x);
//尾插的时候没有节点
if (*pphead == NULL)
{
*pphead = newnode;
}
//尾插的时候已经有节点
else
{
SLTNode* tail = *pphead;
// 找尾
while (tail->next)
{
tail = tail->next;
}
tail->next = newnode;
}
}
//错误的尾删
//void SLTPopBack(SLTNode* phead)
//{
// SLTNode* tail = phead;
// while (tail->next)
// {
// tail = tail->next;
// }
// free(tail);
// tail = NULL;
//}
void SLTPopBack(SLTNode** pphead)
{
// 暴力的检查
assert(*pphead);
// 温柔的检查
//if (*pphead == NULL)
// return;
//只有一个节点的尾删
if ((*pphead)->next == NULL)
{
free(*pphead);
*pphead = NULL;
}
//多个节点的尾插
else
{
//写法1
/*SLTNode* prev = NULL;
SLTNode* tail = *pphead;
while (tail->next)
{
prev = tail;
tail = tail->next->next;
}
free(tail);
prev->next = NULL;*/
//写法2
//其实tail->next相当于写法1的prev,tail->next->next相当于代码1中的tail->next->next
//也即是说两次指向的next可以代替掉代码1的prev
SLTNode* tail = *pphead;
while (tail->next->next)
{
tail = tail->next;
}
free(tail->next);
tail->next = NULL;
}
}
void SLTPushFront(SLTNode** pphead, SLTDataType x)
{
SLTNode* newnode = BuySLTNode(x);
newnode->next = *pphead;
*pphead = newnode;
}
void SLTPopFront(SLTNode** pphead)
{
assert(*pphead);
SLTNode* next = (*pphead)->next;
free(*pphead);
*pphead = next;
}
SLTNode* SLTFind(SLTNode* phead, SLTDataType x)
{
SLTNode* cur = phead;
while (cur)
{
if (cur->data == x)
{
return cur;
}
cur = cur->next;
}
return NULL;
}
void SLTInsertAfter(SLTNode* pos, SLTDataType x)
{
assert(pos);
/*if (pos == NULL)
{
return;
}*/
SLTNode* newnode = BuySLTNode(x);
newnode->next = pos->next;
pos->next = newnode;
}
// 在pos之前插入x
void SLTInsert(SLTNode** pphead, SLTNode* pos, SLTDataType x)
{
assert(pos);
if (*pphead == pos)
{
SLTPushFront(pphead, x);
}
else
{
SLTNode* prev = *pphead;
while (prev->next != pos)
{
prev = prev->next;
}
SLTNode* newnode = BuySLTNode(x);
prev->next = newnode;
newnode->next = pos;
}
}
void SLTEraseAfter(SLTNode* pos)
{
assert(pos);
if (pos->next == NULL)
{
return;
}
else
{
// 错的
/*free(pos->next);
pos->next = pos->next->next;*/
SLTNode* nextNode = pos->next;
//pos->next = pos->next->next;
pos->next = nextNode->next;
free(nextNode);
//nextNode = NULL;
}
}
// 删除pos位置
void SLTErase(SLTNode** pphead, SLTNode* pos)
{
assert(pos);
assert(*pphead);
if (pos == *pphead)
{
SLTPopFront(pphead);
}
else
{
SLTNode* prev = *pphead;
while (prev->next != pos)
{
prev = prev->next;
}
prev->next = pos->next;
free(pos);
//pos = NULL;
}
}
void SLTDestroy(SLTNode** pphead)
{
SLTNode* cur = *pphead;
while (cur)
{
SLTNode* next = cur->next;
free(cur);
cur = next;
}
*pphead = NULL;
}2.3测试代码(test.c)
#include "SList.h"
void TestSList0()
{
//创建一个个没有联系的节点
SLTNode* n1 = BuySLTNode(1);
SLTNode* n2 = BuySLTNode(2);
SLTNode* n3 = BuySLTNode(3);
SLTNode* n4 = BuySLTNode(4);
//前一个节点里面的next指针存的是下一个节点的地址
//因此可以达到通过第一个节点就(像链条一样)能找到后面所有节点的效果
//此种数据存储的方式为----单链表
n1->next = n2;
n2->next = n3;
n3->next = n4;
n4->next = NULL;
//这样链接节点太废代码
//可以将链接节点封装成一个函数
}
void TestSList1()
{
SLTNode* plist = CreateSList(10);
SLTPrint(plist);
}
void TestSList2()
{
SLTNode* plist = CreateSList(5);
SLTPushBack(&plist, 100);
SLTPushBack(&plist, 200);
SLTPushBack(&plist, 300);
SLTPrint(plist);
}
void TestSList3()
{
SLTNode* plist = NULL;
SLTPushBack(&plist, 100);
SLTPushBack(&plist, 200);
SLTPushBack(&plist, 300);
SLTPrint(plist);
SLTPopBack(&plist);
SLTPrint(plist);
SLTPopBack(&plist);
SLTPrint(plist);
SLTPopBack(&plist);
SLTPrint(plist);
//SLTPopBack(&plist);
//SLTPrint(plist);
}
void TestSList4()
{
SLTNode* plist = NULL;
SLTPushFront(&plist, 100);
SLTPushFront(&plist, 200);
SLTPushFront(&plist, 300);
SLTPushFront(&plist, 400);
SLTPrint(plist);
SLTPopFront(&plist);
SLTPrint(plist);
SLTPopFront(&plist);
SLTPrint(plist);
SLTPopFront(&plist);
SLTPrint(plist);
SLTPopFront(&plist);
SLTPrint(plist);
}
void Swap1(int* p1, int* p2)
{
int tmp = *p1;
*p1 = *p2;
*p2 = tmp;
}
void Swap2(int** pp1, int** pp2)
{
int* tmp = *pp1;
*pp1 = *pp2;
*pp2 = tmp;
}
void TestSList5()
{
SLTNode* plist = NULL;
SLTPushBack(&plist, 1);
SLTPushBack(&plist, 2);
SLTPushBack(&plist, 3);
SLTPushBack(&plist, 4);
SLTPushBack(&plist, 5);
SLTPrint(plist);
SLTNode* p = SLTFind(plist, 3);
SLTInsertAfter(p, 30);
//p = SLTFind(plist, 300);
//SLTInsertAfter(p, 30);
p = SLTFind(plist, 2);
SLTInsert(&plist, p, 20);
/*if (p)
{
SLTInsertAfter(p, 30);
printf("ҵ\n");
}
else
{
printf("Ҳ\n");
}*/
SLTPrint(plist);
}
void TestSList6()
{
SLTNode* plist = NULL;
SLTPushBack(&plist, 1);
SLTPushBack(&plist, 2);
SLTPushBack(&plist, 3);
SLTPushBack(&plist, 4);
SLTPushBack(&plist, 5);
SLTPrint(plist);
SLTNode* p = SLTFind(plist, 3);
SLTEraseAfter(p);
SLTPrint(plist);
p = SLTFind(plist, 3);
SLTErase(&plist, p);
p = NULL;
SLTPrint(plist);
SLTDestroy(&plist);
//野指针
SLTPrint(plist);
}
int main()
{
TestSList4();
//int a = 0, b = 1;
//Swap1(&a, &b);
//int* ptr1 = &a, *ptr2 = &b;
//Swap2(&ptr1, &ptr2);
return 0;
}

![[附源码]java毕业设计基于Web留学管理系统](https://img-blog.csdnimg.cn/6478a442555045d4ab0416d9ce874621.png)