没错!办公自动化他来了!果然,代码都是懒人发明出来的。接下来让我们一起来看看这个批改作业的自动化脚本吧!学会了这种思想可以帮助我们高效解决许多重复性的工作,比如说批量修改文件的名称、类型、位置等等,快让我们通过一个案例一起学起来吧!
一、什么是办公自动化?
Python办公自动化主要是批量化、自动化、定制化解决数据问题,目前主要分为三大块:自动化office、自动化机器人、自动化数据服务。办公自动化(Office Automation,简称OA)是将现代化办公和计算机技术结合起来的一种新型的办公方式。办公自动化没有统一的定义,凡是在传统的办公室中采用各种新技术、新机器、新设备从事办公业务,都属于办公自动化的领域。 通过实现办公自动化,或者说实现数字化办公,可以优化现有的管理组织结构,调整管理体制,在提高效率的基础上,增加协同办公能力,强化决策的一致性 。
二、实战案例
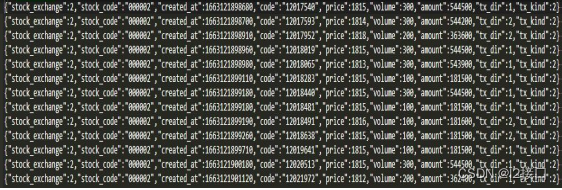
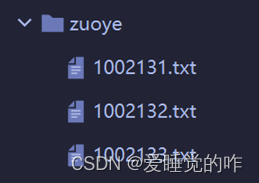
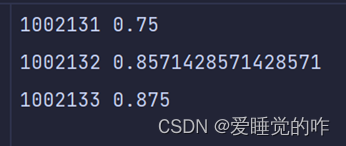
有一个子目录“zuoye”有若干文本文件,gbk编码。分别存储了每个学生提交上来的算术作业,文件名是学生的学号。算术作业包括+-*/,每行一道题设计一个自动批改程序,要求完成以下功能允许每个数前后可能有空白,允许结果为负数的情况,运算的数均为正整数。除法只考虑能整除的情况,要考虑可能有空白行,可能出现在文件的任意位置空白行不计入总题数,格式错误的题数计入总题数将批改结果保存到文件“results.txt“”,每一行记录学号,答对的百分比。
txt文件如下:
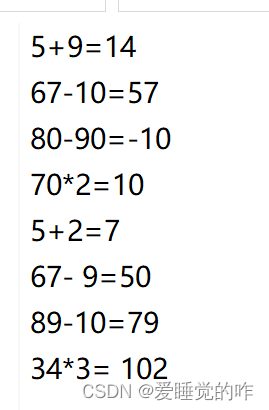
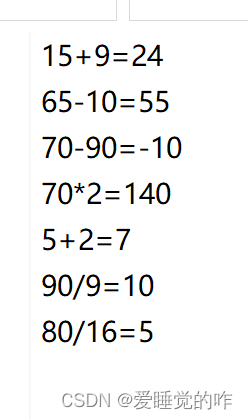
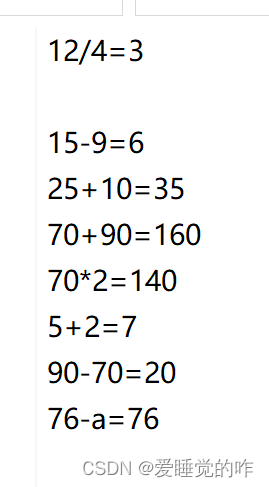
需要的结果如下:
三、思路描述
- 首先我们可以先对一个文件去操作,比如说学号为1002131的同学,我们通过读取这名称的文件,读取其中的每一行,再自定义一个函数,对其中的每一行进行判断,判断其是否计算正确,统计这个同学的正确率,用字典将姓名与正确率相关联。这样就可以得到这一位同学的正确率。
- 有了读取以为同学的思路,那么我们也可以通过读取一个文件夹,将文件夹中的每个同学进行操作,这样就可以得到这个文件夹下所有同学的正确率。同样我们用字典将学号与正确率相关联,便于最终输出。
- 经过前两步,我们已经得到一个字典,这个字典的键是每一位同学的序号,值是该同学的正确率。只要分行将对应结果输出到指定文件中就完成啦!
四、完整代码
import os
import re
name_list = []
allname_list = []
result_dic = {}
target = os.walk("zuoye")
for root, ds, fs in target:
for f in fs:
allname_list.append(f)
name_list.append(f[:7:])
def calculator(expression):
if "+" in expression:
sign = "+"
elif "-" in expression:
sign = "-"
elif "*" in expression:
sign = "*"
else:
sign = "/"
num_list_1 = []
num_list_2 = []
split_list_1 = re.split("[=]", expression)
split_list_2 = re.split("[*,=,+,/,-]", expression)
for i in split_list_1:
num_list_1.append(i.replace(" ", ""))
if int(num_list_1[-1]) < 0:
for i in split_list_2:
num_list_2.append(i.replace(" ", ""))
num_1 = num_list_2[0]
num_2 = num_list_2[1]
num_3 = num_list_2[-1]
try:
int(num_1) * int(num_2) * int(num_3)
except ValueError:
return 0
else:
if -int(num_3) == eval(f"{num_1}{sign}{num_2}"):
return 1
else:
return 0
else:
for i in split_list_2:
num_list_2.append(i.replace(" ", ""))
num_1 = num_list_2[0]
num_2 = num_list_2[1]
num_3 = num_list_2[2]
try:
int(num_1) * int(num_2) * int(num_3)
except ValueError:
return 0
else:
if int(num_3) == eval(f"{num_1}{sign}{num_2}"):
return 1
else:
return 0
def func(num):
r = open("zuoye"+'\\{0}'.format(allname_list[num]),encoding="GBK")
tem_list = []
result_list =[]
line = r.readline()
while line:
# isspace()方法判断当该行是空行时,跳过该行
if line.isspace():
line = r.readline()
else:
line = line.strip('\n') #去掉列表中每一个元素的换行符
tem_list.append(line)
line = r.readline()
for i in tem_list:
result_list.append(calculator(i))
result_dic[name_list[num]] = sum(result_list)/len(result_list)
Note = open('result.txt',mode='w')
for i in range(0,len(allname_list)):
func(i)
Note.writelines([str(list(result_dic.keys())[i])," ",str(list(result_dic.values())[i]),"\n"]) #\n 换行符
五、代码讲解
- 首先我们读取指定的文件夹,即“zuoye”文件夹,用target = os.walk("zuoye"),返回三个对象,最后一个即为所有文件的名称列表,所有我们只用对最后一个fs进行遍历就可以。将所有文件名添加到一个列表中,并另外用字符串切片的方式取出.txt。
- 接下来就是最关键的判断函数,这个函数的作用即判断输入的一个表达式是否正确,首先要确定符号,用if elif和else判断输入的到底是加减乘除什么类型表达式。再用正则表达式,用[*,=,+,/,-]对表达式进行切分,这里注意,如果有负数的情况,负数前面也会有-号,所以这里要用一个if语句进行判断。
- 将切割的结果赋值给三个变量,并且注意要用i.replace(" ", "")去除空格,要不然后面没办法用int转化。这样我们就拿到了三个数,以及他们的运算符号,我们用if int(num_3) == eval(f"{num_1}{sign}{num_2}")判断这个表达式是否正确既可以啦,如果正确返回1,如果错误返回0,即做对得1分,做错得0分。
- 之后,再读取文件夹里面的每一个文件,读取每一个文件的每一行,如果读到空行就跳过,不统计在里面,将读取的每一行用上面的自定义函数进行判断,统计每一个文件的总得分率,与文件总行数(去除空行)相除得到正确率。最后通过字典将该同学的学号和正确率关联起来。
- 最后,通过Note.writelines([str(list(result_dic.keys())[i])," ",str(list(result_dic.values())[i]),"\n"])将所得结果写入到result文件中,这样我们完成啦!



![[java/初学者/GUI编程]GUI界面设计——界面组件类](https://img-blog.csdnimg.cn/0f109c4b12104ee29dfc4fc48d551f3c.png)