Confidence Regularized Self-Training
领域自适应研究的最新进展表明,深度自训练是实现无监督领域自适应的有效手段。这些方法通常涉及到一个迭代过程,即在目标域上进行预测,然后将自信的预测作为伪标签进行再训练。然而,由于伪标签可能是嘈杂的,自我训练可能会将过度自信的标签信念放在错误的类中,从而导致带有传播错误的偏离解决方案。为了解决这个问题,我们提出了一个自信正则化自我训练(CRST)框架,它被表述为正则化自我训练。我们的方法将伪标签视为通过交替优化共同优化的连续潜在变量。我们提出了两种置信度正则化:标签正则化(LR)和模型正则化(MR)。CRST-LR生成软伪标签,而CRST-MR促进网络输出的平滑性。大量的图像分类和语义分割实验表明,crst以最先进的性能优于非正则化的crst。这项工作的代码和模型可在https://github.com/yzou2/CRST上获得。
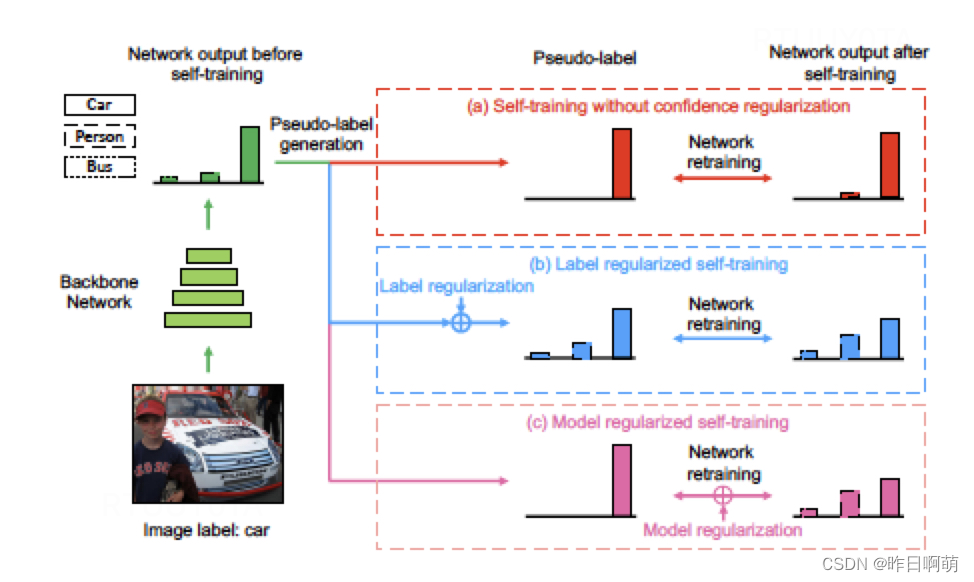
简单来说就是相比于传统自训练中引入了两种正则化的方法。
0、传统自训练的步骤
主要有两步,第一步是获得伪标签,第二步是训练模型,两步交替进行。

1、label侧的正则化
传统获得伪标签的方式如下:
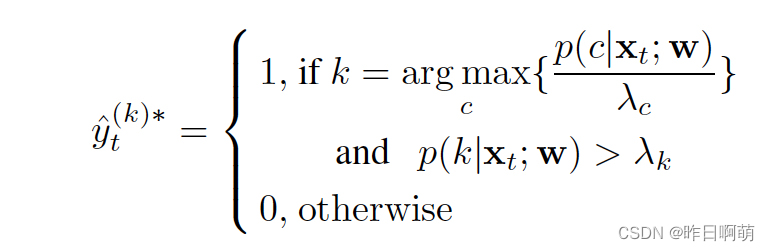
白话来说就是如果模型预测类别为c的概率最大,且这个概率大于我们设置的阈值(比如0.6),那么我们就选择这个样本的伪标签为c
但是这样存在的 问题是,模型可能过度自信的选择了错误的选项,这种过度自信的选择会影响后续的学习,造成和真实分布情况的偏差。
因此作者考虑使用一种标签正则化的方式做个软化。
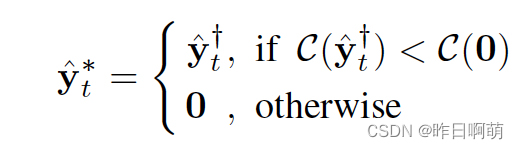
只要计算的一个损失函数比类别0(未识别/识别置信度太低)的下,就选择这个标签,标签也并未是01离散值,而是对应预测的概率值。
这个损失函数计算如下
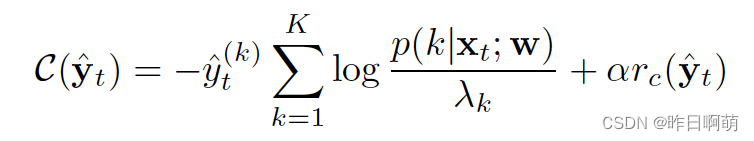
同时,我们也需要调整一下我们在训练伪标签时的损失函数
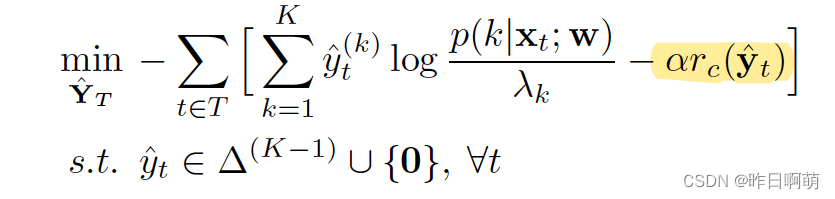
2、mdel正则化
第一步获得伪标签和之前完全一样,在第二步训练模型的时候在loss中增加正则项。
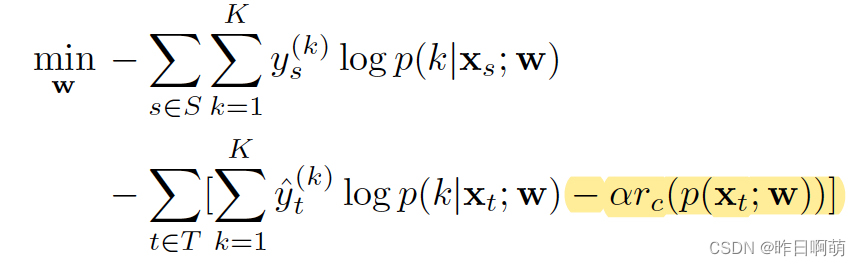
对于
r
c
(
p
)
r_c(p)
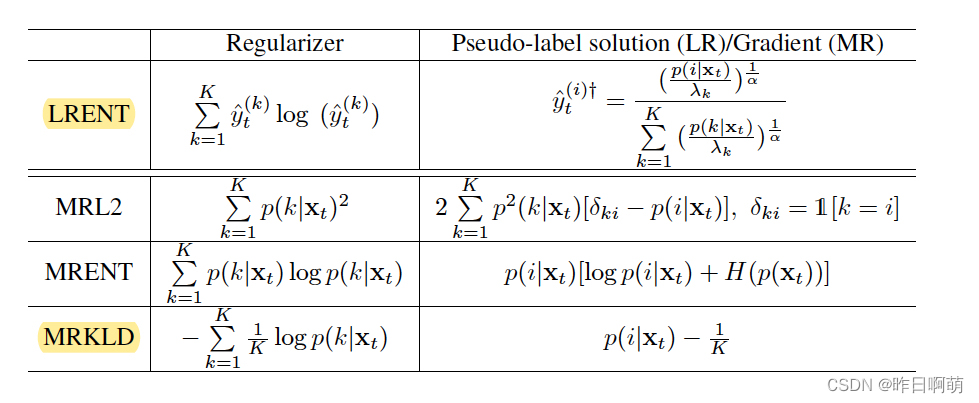
rc(p)的定义,可见下表,作者将label正则称作LRENT,将model正则称作MRKLD
3、实现
作者在github上公布了他们的代码,后续补充

![[MMDetection]生成测试集预测的test.bbox.json文件](https://img-blog.csdnimg.cn/8b5fbd0145b34823a9a2f5b578e4c4b7.png)