前言
整个文章都是以精华部分为主,主要分文2个部分:
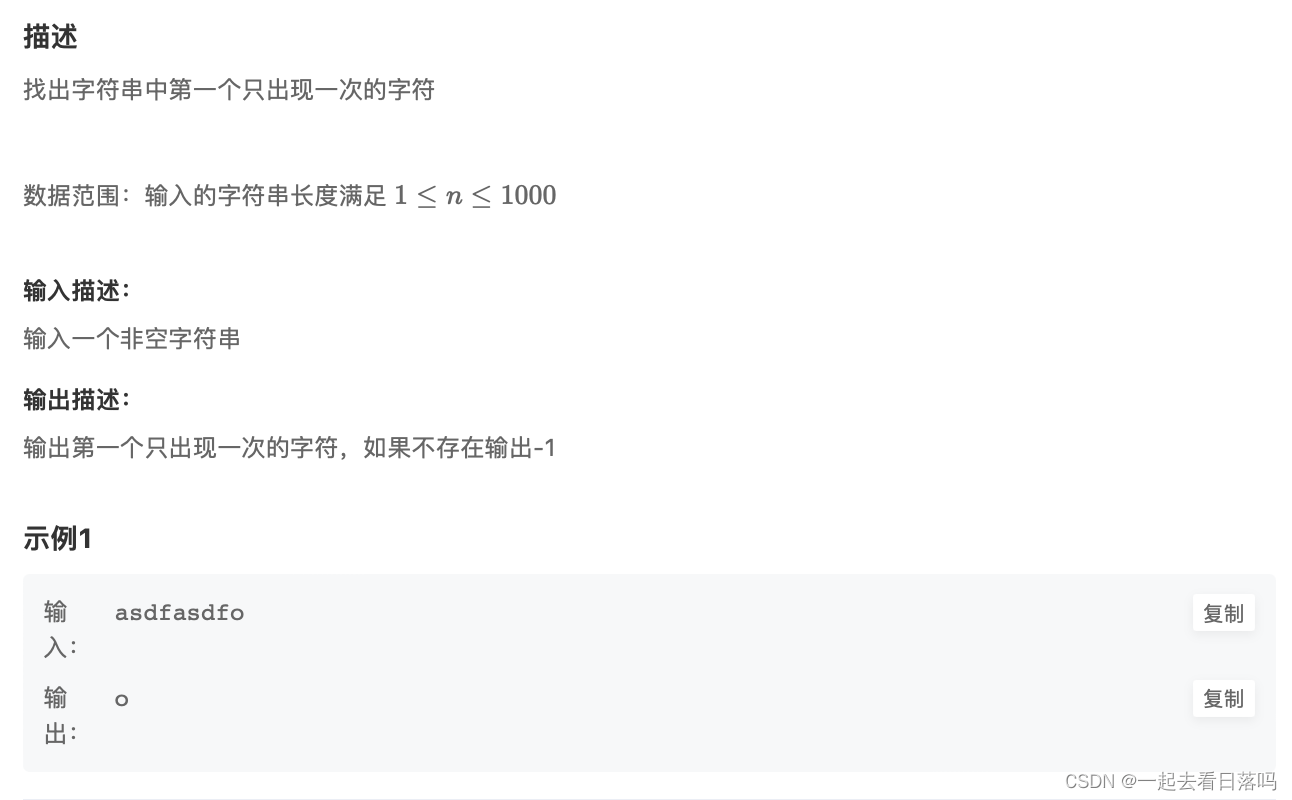
1、python的【re】正则表达式使用方法。
2、【re】正则表达式以及对应的demo。
第一部分让你知道【re】的几个函数的区别,更好的匹配项目中的需求。
第二部分让你快速的匹配具体需要的正则表达式可用拼写方法。
一、python【re】的用法
通用函数:
| 函数名 | 作用 |
| span() | 获取匹配字符串下标范围,返回元组。 |
| group() | 返回匹配字符串结果,返回字符串。 |
1、re.match函数·单一匹配-推荐指数【★★】
re.match 尝试从字符串的起始位置匹配一个模式,如果不是起始位置匹配成功的话,match()就返回none。
函数语法:
re.match(pattern, string, flags=0)
pattern:正则表达式字符串。
string:需要匹配的字符串。
第三个flags是控制正则的严谨度,例如是否区分大小写【re.I】什么的,咱们这里不做深入讨论。
示例:
注:re.match弊端:只能匹配是否以某字符串为开头的内容,所以很多场合不合适。
import re
'''
re.match弊端:只能匹配是否以某字符串为开头的内容
'''
result1 = re.match(r'I', 'i Have A Dream!', re.I) # 在起始位置匹配,不区分大小写
result2 = re.match(r'Dream', 'I Have A dream!', re.I) # 不在起始位置匹配,不区分大小写
print(result1)
print("匹配位置:", result1.span())
print("匹配字符串:", result1.group())
print(result2)
结果中我们能看到是否以字符串开头进行字符串匹配的区别,虽然都含有,但是不是开头的字符串就不匹配。
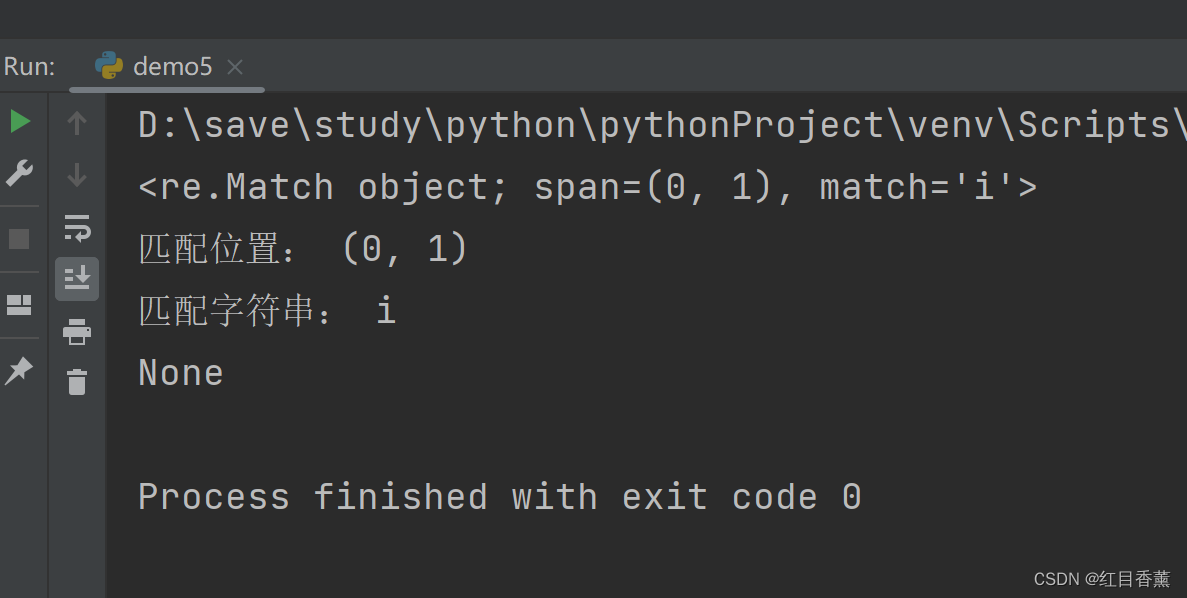
2、re.search函数·单一匹配-推荐指数【★★★★★】
注:re.search函数无论在哪里都能匹配字符串。
函数语法与re.match函数一样。
import re
'''
re.search:无论在哪里都能匹配
'''
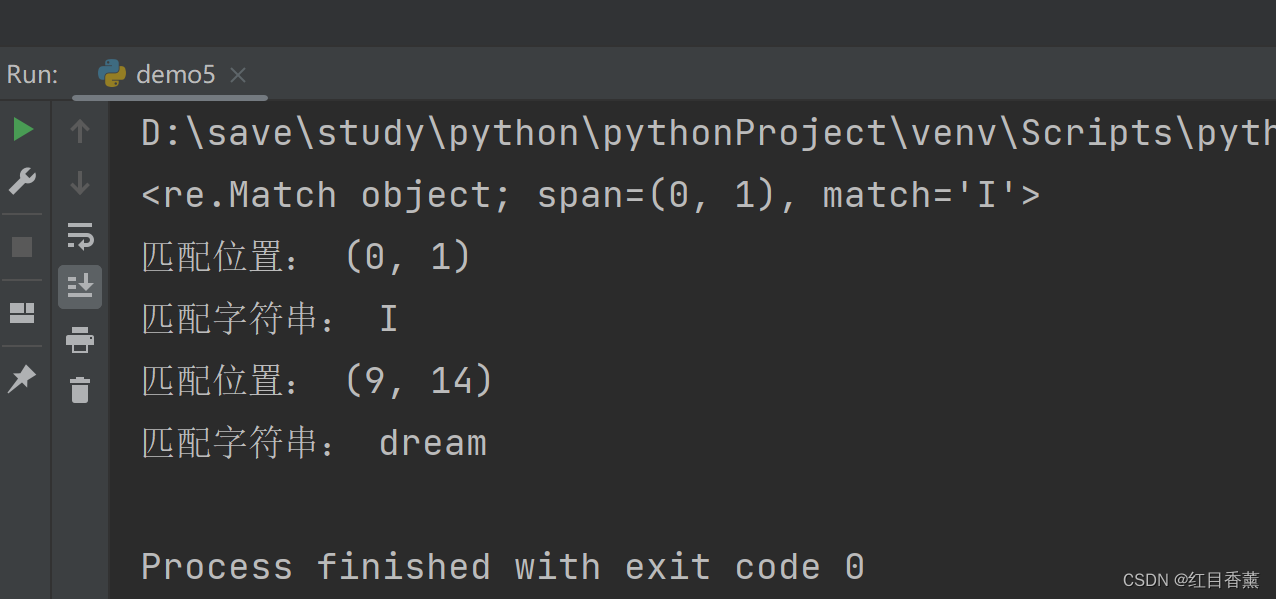
result1 = re.search(r'I', 'I Have A Dream!', re.I) # 不区分大小写
result2 = re.search(r'Dream', 'I Have A dream!dream', re.I) # 不区分大小写
print(result1)
print("匹配位置:", result1.span())
print("匹配字符串:", result1.group())
print("匹配位置:", result2.span())
print("匹配字符串:", result2.group())
在结果中我们可以清晰的看到匹配到匹配到的位置。
以上两种都只能匹配一次,那么很多时候我们是一个超级大的字符串,或甚至是整个【H5】网页,那么,我们需要多个匹配的时候就不能使用这两个函数了。
3、re.findall函数·多项匹配-推荐指数【★★★★★】
在字符串中找到正则表达式所匹配的所有子串,并返回一个列表,如果有多个匹配模式,则返回元组列表,如果没有找到匹配的,则返回空列表。个人喜欢用列表所以五星推荐。
注:这里通上面的两个函数的本质却别就出来了,我们可以匹配一个大字符串中所有符合正则表达式的字符串。
示例:
import re
'''
re.findall:匹配所有符合正则表达式的字符串
'''
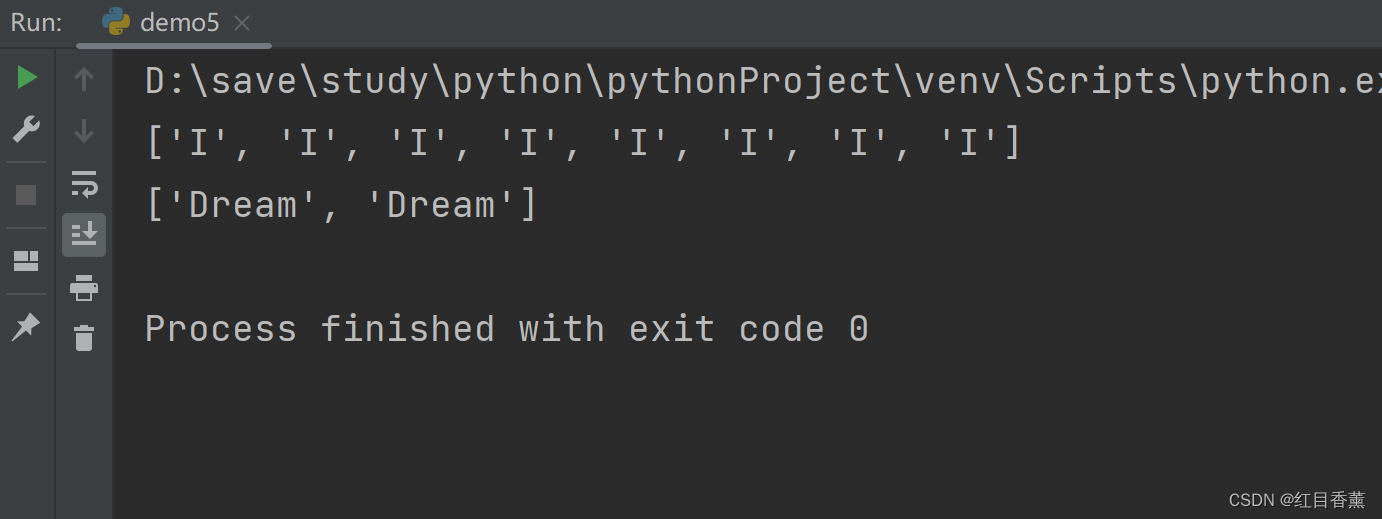
result1 = re.findall(r'I', 'I Have A Dream!I I I I I I I') # 在起始位置匹配
result2 = re.findall(r'Dream', 'I Have A Dream!Dream') # 不在起始位置匹配
print(result1)
print(result2)
结果中我们能看到所有符合的字符串都返回到了列表中,没有去重操作。
4、re.finditer函数·多项匹配-推荐指数【★★★★】
在字符串中找到正则表达式所匹配的所有子串,并把它们作为一个迭代器返回。个人不太喜欢用迭代器,故而推荐指数四颗星。
注:这里我与findall做了个对比,喜欢使用迭代器的可以使用这个函数啊。
import re
content = '''email:372699828@qq.com
email:feng8403000@163.com
email:qwe8403000@126.com
'''
result_findall = re.findall(r"\d+@\w+.com", content)
print("迭代器类型:", type(result_findall))
# 返回list
result_findall
for i in result_findall:
print(i)
print("-" * 20)
result_finditer = re.finditer(r"\d+@\w+.com", content)
# 返回iterator
print("list列表类型:", type(result_finditer))
for i in result_finditer:
print(i.group())
5、re.sub函数·替换函数-推荐指数【★★★★】
这个函数用的相对来说不是很多,一般正则梳理好的字符串就直接使用字符串的处理方法来搞定了。但是这个函数还是很方便的,只是我不推荐替换原内容。
示例:
import re
'''
re.sub:替换匹配字符串
'''
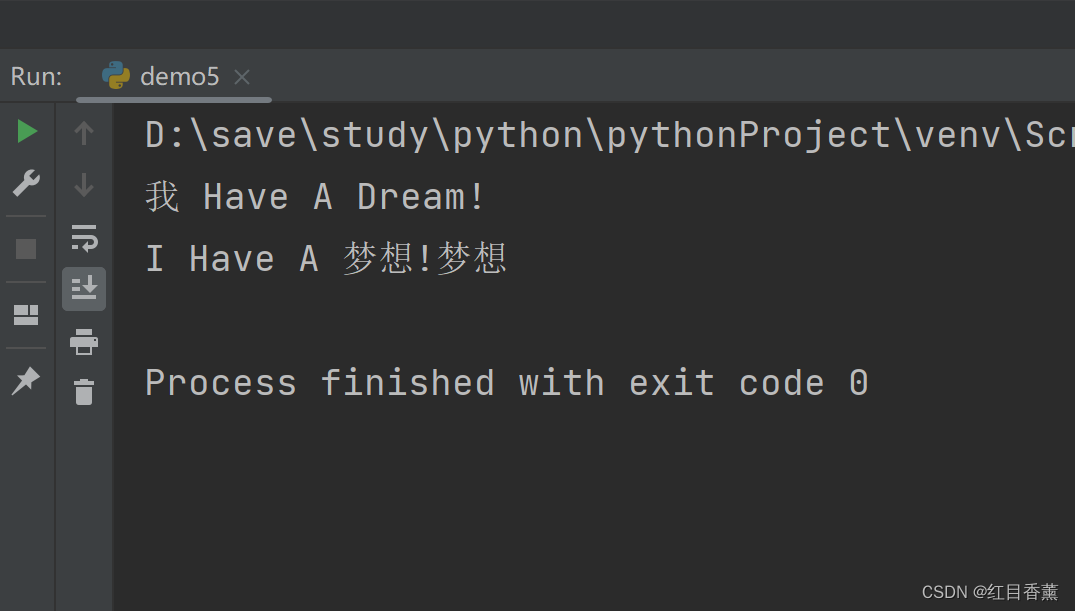
result1 = re.sub(r'I', '我', 'I Have A Dream!')
result2 = re.sub(r'Dream', '梦想', 'I Have A Dream!Dream')
print(result1)
print(result2)
结果中可以看到,这个替换匹配是默认多个匹配的。