Spark Join大小表
- 无法广播
- 过滤后大
- 小表数据分布均匀
大小表 : 大小表尺寸相差 3 倍以上
- Join 优先考虑 BHJ
- 小表的数据量 > 广播阈值时,优先考虑 SHJ
无法广播
大表 100GB、小表 10GB,都远超广播变量阈值
- 当小表的尺寸 > 8GB时,创建广播变量,会中断任务执行,没有用 BHJ
以同维度组合统计日志中的访问量 :
- 小表大表都大,无法 BHJ ,只能选择 SMJ
//左连接查询语句
select t1.gender,
t1.age, t1.city, t1.platform,
t1.site, t1.hour,
coalesce(t2.payload, t1.payload)
from t1
left join t2 on t1.gender = t2.gender
and t1.age = t2.age
and t1.city = t2.city
and t1.platform = t2.platform
and t1.site = t2.site
and t1.hour = t2.hour;
背景:两张表的 Schema 完全一致 ,基于 Join Keys 生成 Hash Key:
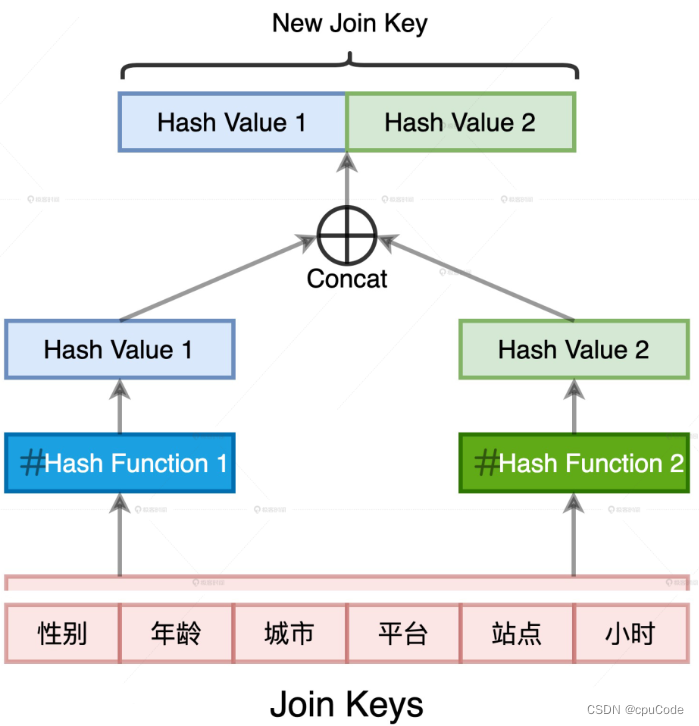
- 把所有 Join Keys 拼接在一起,把 性别-小时 拼接成字符串
- 用哈希算法 (MD5/SHA256 )对字符串做哈希,得出的哈希值 : Hash Key
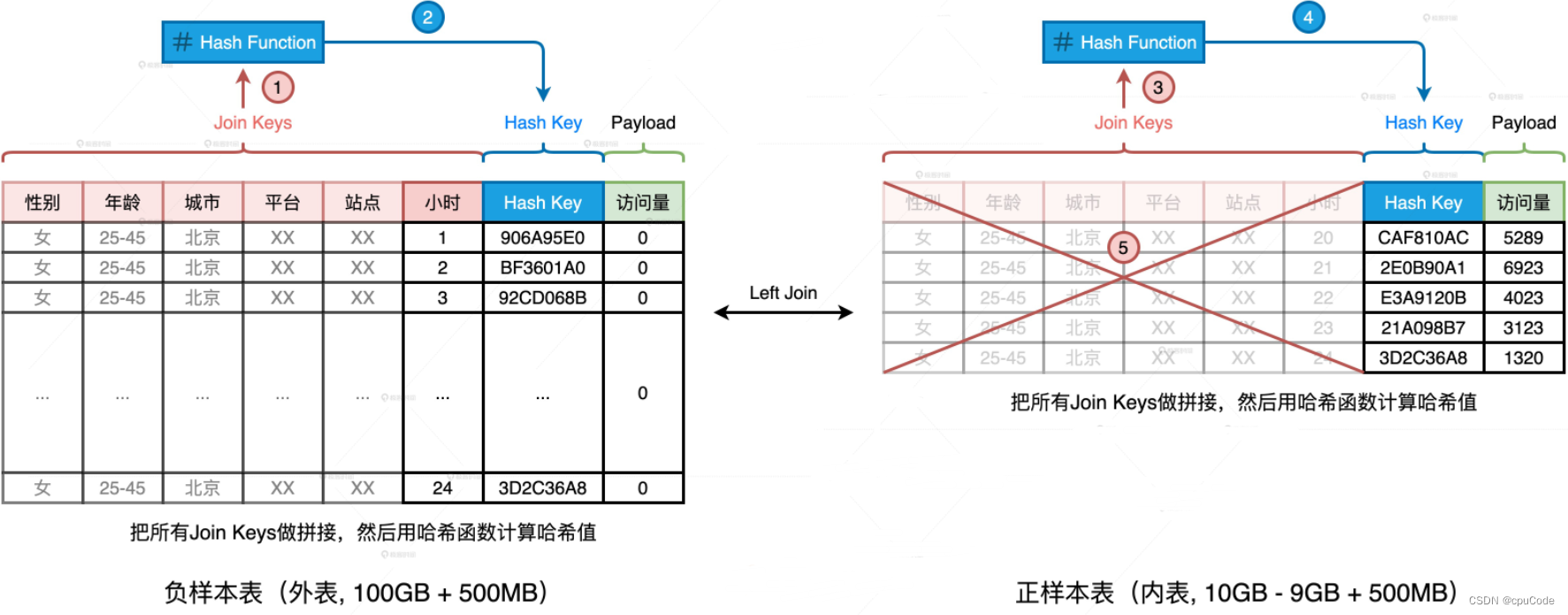
内表就能进行广播变量时,把 SMJ 转为 BHJ
-- 调整后的左连接查询语句
select t1.gender, t1.age,
t1.city, t1.platform,
t1.site, t1.hour,
coalesce(t2.payload, t1.payload)
from t1 left join t2
on t1.hash_key = t2. hash_key;
HashKey 是 Join Keys 哈希值。哈希运算,就要考虑哈希冲突
- 解决方法:二次哈希:用两种哈希算法来生成 Hash Key 数据列
过滤后大
统计所有头部用户贡献的营业额,并按营业额倒序排序
- 两张表都 > 广播阈值时,默认选择 SMJ
-- 查询语句,维表带过滤条件
select (orders.price * order.quantity) as revenue,
users.name
from orders
join users on orders.userId = users.id
where users.type = 'Head User'
group by users.name
order by revenue desc
维表带过滤条件 ,利用 AQE 在运行时动态地调整 Join ,把 SMJ 转为 BHJ ( spark.sql.adaptive.enabled 打开)
- 注意:根据过滤后的维表的大小,调整广播阈值
spark.sql.autoBroadcastJoinThreshold,AQE 才能 SMJ 转为 BHJ
用动态 Join , 中途会引发 Shuffle 的数据分发
- 解决办法:DPP,减少事实表的扫描量,提升性能
用 DPP 的条件:
- DPP 仅支持等值 Joins,不支持大于或小于这种不等值关联
- 维表过滤后的数据集,要小于广播阈值,配置项:
spark.sql.autoBroadcastJoinThreshold - 事实表必须是分区表,且分区字段 (可多个) 必须包含 Join Key
将 orders 做成分区表
- 创建新的订单表 orders_new,并指定 userId 为分区键
- 把原订单表 orders 的数据,灌进到 orders_new
//查询语句
select (orders_new.price * orders_new.quantity) as revenue,
users.name
from orders_new
join users on orders_new.userId = users.id
where users.type = 'Head User'
group by users.name
order by revenue desc
利用 DPP,在做数仓规划时,要结合常用查询与典型场景,提前设计好表结构,如: Schema、分区键、存储格式
小表数据分布均匀
当不满足 BHJ 时,会先选 SMJ 。但 Join 的两张表尺寸相差小,数据分布均匀时,SHJ 比 SMJ 更高效
统计所有用户贡献的营业额 :
-- 查询语句
select (orders.price * order.quantity) as revenue,
users.name
from orders
join users on orders.userId = users.id
group by users.name
order by revenue desc
用 Join Hints 选择 SHJ
-- Join hints 后的查询语句
select /*+ shuffle_hash(orders) */
(orders.price * order.quantity) as revenue,
from orders
join users on orders.userId = users.id
group by users.name
order by revenue desc
SHJ 要成功完成计算、不抛 OOM 异常,需要保证小表的每个数据分片能放进内存