目录
- 日志
- 错误日志
- 二进制日志
- 格式
- 查看
- 删除
- 查询日志
- 慢查询日志
- 主从复制
- 原理
- docker搭建
- 分库分表
- 拆分策略
- 垂直拆分
- 垂直分库
- 垂直分表
- 水平拆分
- 水平分库
- 水平分表
- 实现技术
- MyCat2
- mysql2对比mycat1.x
- docker运行mycat2
日志
错误日志
错误日志是 MySQL 中最重要的日志之一,它记录了当 mysqld 启动和停止时,以及服务器在运行过程中发生任何严重错误时的相关信息。当数据库出现任何故障导致无法正常使用时,建议首先查看此日志。
该日志是默认开启的,默认存放目录 /var/log/,默认的日志文件名为 mysqld.log 。查看日志位置:
show variables like '%log_error%';
二进制日志
二进制日志(BINLOG)记录了所有的 DDL(数据定义语言)语句和 DML(数据操纵语言)语句,但不包括数据查询(SELECT、SHOW)语句。
作用:
①. 灾难时的数据恢复;
②. MySQL的主从复制。
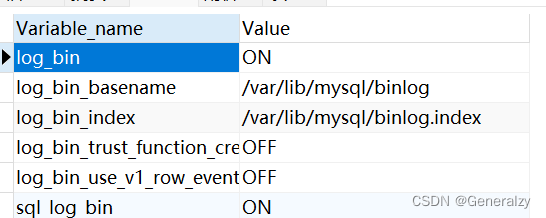
在MySQL8版本中,默认二进制日志是开启着的,涉及到的参数如下:
show variables like '%log_bin%';
参数说明:
-
log_bin_basename:当前数据库服务器的binlog日志的基础名称(前缀),具体的binlog文件名需要再该basename的基础上加上编号(编号从000001开始)。
-
log_bin_index:binlog的索引文件,里面记录了当前服务器关联的binlog文件有哪些。
格式
MySQL服务器中提供了多种格式来记录二进制日志,具体格式及特点如下:
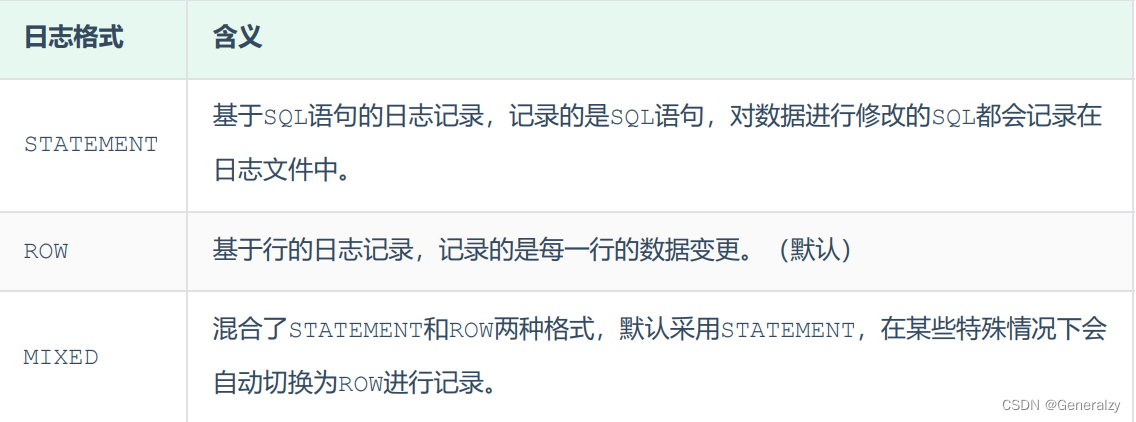
show variables like '%binlog_format%';
如果需要配置二进制日志的格式,只需要在 /etc/my.cnf 中配置 binlog_format 参数即可。
查看
由于日志是以二进制方式存储的,不能直接读取,需要通过二进制日志查询工具 mysqlbinlog 来查看,具体语法:
mysqlbinlog [ 参数选项 ] logfilename
参数选项:
-d 指定数据库名称,只列出指定的数据库相关操作。
-o 忽略掉日志中的前n行命令。
-v 将行事件(数据变更)重构为SQL语句
-vv 将行事件(数据变更)重构为SQL语句,并输出注释信息
删除
对于比较繁忙的业务系统,每天生成的binlog数据巨大,如果长时间不清除,将会占用大量磁盘空间。可以通过以下几种方式清理日志:
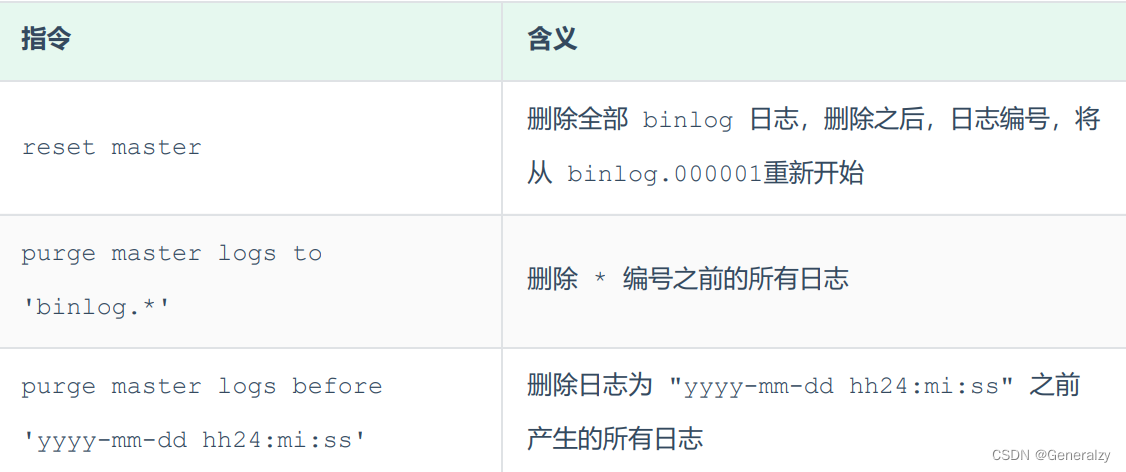
也可以在mysql的配置文件中配置二进制日志的过期时间,设置了之后,二进制日志过期会自动删除。
show variables like '%binlog_expire_logs_seconds%';
查询日志
查询日志中记录了客户端的所有操作语句,而二进制日志不包含查询数据的SQL语句。默认情况下,查询日志是未开启的。
如果需要开启查询日志,可以修改MySQL的配置文件 /etc/my.cnf 文件,添加如下内容:
#该选项用来开启查询日志 , 可选值 : 0 或者 1 ; 0 代表关闭, 1 代表开启
general_log=1
#设置日志的文件名 , 如果没有指定, 默认的文件名为 host_name.log
general_log_file=mysql_query.log
开启了查询日志之后,在MySQL的数据存放目录,也就是 /var/lib/mysql/ 目录下就会出现mysql_query.log 文件。之后所有的客户端的增删改查操作都会记录在该日志文件之中,长时间运行后,该日志文件将会非常大。
慢查询日志
慢查询日志记录了所有执行时间超过参数 long_query_time 设置值并且扫描记录数不小于min_examined_row_limit 的所有的SQL语句的日志,默认未开启。long_query_time 默认为10 秒,最小为 0, 精度可以到微秒。
如果需要开启慢查询日志,需要在MySQL的配置文件 /etc/my.cnf 中配置如下参数:
#慢查询日志
slow_query_log=1
#执行时间参数
long_query_time=2
默认情况下,不会记录管理语句,也不会记录不使用索引进行查找的查询。可以使用log_slow_admin_statements和 更改此行为 log_queries_not_using_indexes,如下所述:
#记录执行较慢的管理语句
log_slow_admin_statements =1
#记录执行较慢的未使用索引的语句
log_queries_not_using_indexes = 1
主从复制
主从复制是指将主数据库的 DDL 和 DML 操作通过二进制日志传到从库服务器中,然后在从库上对这些日志重新执行(也叫重做),从而使得从库和主库的数据保持同步。
MySQL支持一台主库同时向多台从库进行复制, 从库同时也可以作为其他从服务器的主库,实现链状复制。
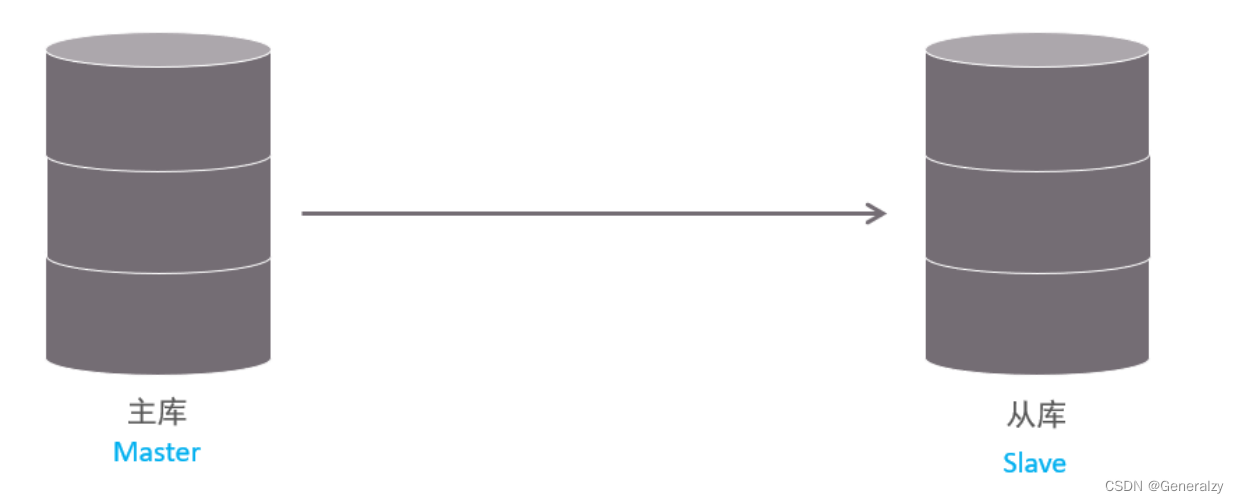
MySQL 复制的优点主要包含以下三个方面:
- 主库出现问题,可以快速切换到从库提供服务。
- 实现读写分离,降低主库的访问压力。
- 可以在从库中执行备份,以避免备份期间影响主库服务。
原理
MySQL主从复制的核心就是 二进制日志,具体的过程如下:
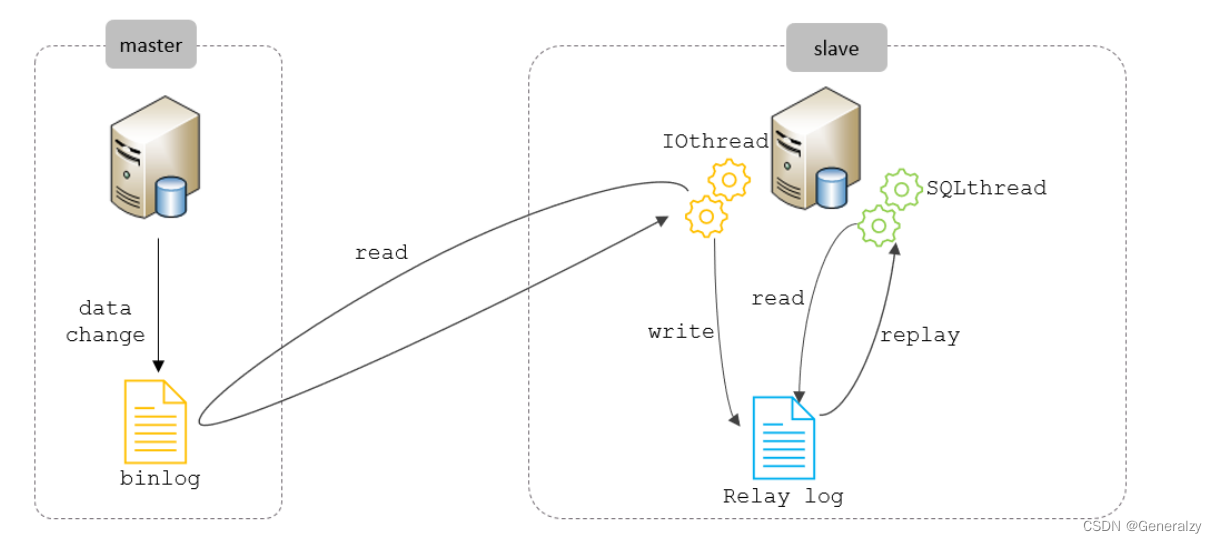
复制分成三步:
- Master 主库在事务提交时,会把数据变更记录在二进制日志文件 Binlog 中。
- 从库读取主库的二进制日志文件 Binlog ,写入到从库的中继日志 Relay Log 。
- slave重做中继日志中的事件,将改变反映它自己的数据。
docker搭建
- 主库配置
#mysql 服务ID,保证整个集群环境中唯一,取值范围:1 – 232-1,默认为1
server-id=1
#是否只读,1 代表只读, 0 代表读写
read-only=0
#忽略的数据, 指不需要同步的数据库
#binlog-ignore-db=mysql
#指定同步的数据库
#binlog-do-db=db01
- 重启MySQL服务器
docker restart mysql8 - 登录mysql,创建远程连接的账号,并授予主从复制权限
#创建itcast用户,并设置密码为`Root@123456`,该用户可在任意主机连接该MySQL服务
CREATE USER 'itcast'@'%' IDENTIFIED WITH mysql_native_password BY 'Root@123456';
#为 'itcast'@'%' 用户分配主从复制权限
GRANT REPLICATION SLAVE ON *.* TO 'itcast'@'%';
-
通过指令,查看二进制日志坐标
show master status ;
字段含义说明:
- file : 从哪个日志文件开始推送日志文件
- position : 从哪个位置开始推送日志
- binlog_ignore_db : 指定不需要同步的数据库
-
从库配置
#mysql 服务ID,保证整个集群环境中唯一,取值范围:1 – 2^32-1,和主库不一样即可
server-id=2
#是否只读,1 代表只读, 0 代表读写
read-only=1
- 登录mysql,设置主库配置
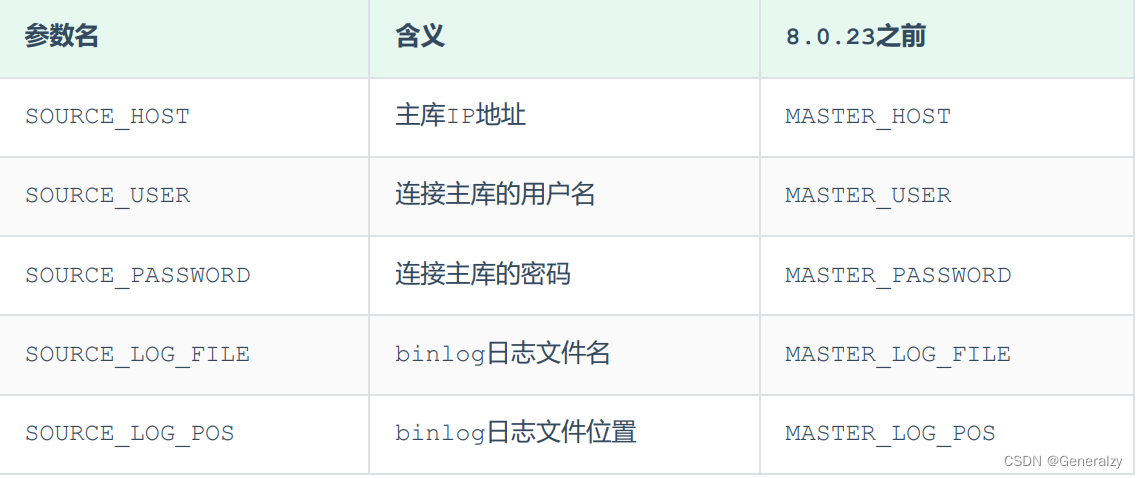
# 8.0.23
CHANGE REPLICATION SOURCE TO SOURCE_HOST='192.168.200.200', SOURCE_USER='itcast',
SOURCE_PASSWORD='Root@123456', SOURCE_LOG_FILE='binlog.000004',
SOURCE_LOG_POS=663;
# 8.0.23之前
CHANGE MASTER TO MASTER_HOST='192.168.200.200', MASTER_USER='itcast',
MASTER_PASSWORD='Root@123456', MASTER_LOG_FILE='binlog.000004',
MASTER_LOG_POS=663;
- 开启同步操作
start replica ; #8.0.22之后
start slave ; #8.0.22之前
-
查看主从同步状态
show replica status ; #8.0.22之后 show slave status ; #8.0.22之前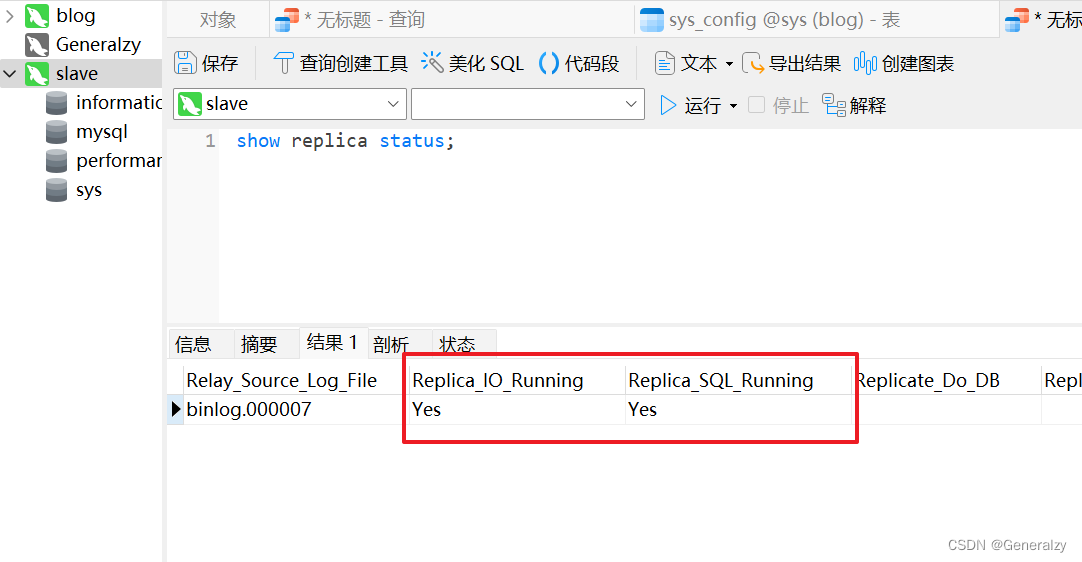
-
在主库上创建数据库、表,并插入数据
create database db01;
use db01;
create table tb_user(
id int(11) primary key not null auto_increment,
name varchar(50) not null,
sex varchar(1)
)engine=innodb default charset=utf8mb4;
insert into tb_user(id,name,sex) values(null,'Tom', '1'),(null,'Trigger','0'),
(null,'Dawn','1');
- 在从库中查询数据,验证主从是否同步
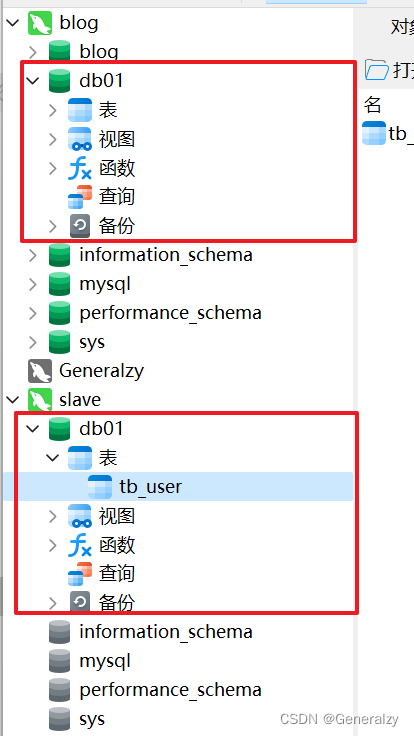
分库分表
随着互联网及移动互联网的发展,应用系统的数据量也是成指数式增长,若采用单数据库进行数据存储,存在以下性能瓶颈:
- IO瓶颈:热点数据太多,数据库缓存不足,产生大量磁盘IO,效率较低。 请求数据太多,带宽不够,网络IO瓶颈。
- CPU瓶颈:排序、分组、连接查询、聚合统计等SQL会耗费大量的CPU资源,请求数太多,CPU出现瓶颈。
为了解决上述问题,我们需要对数据库进行分库分表处理。
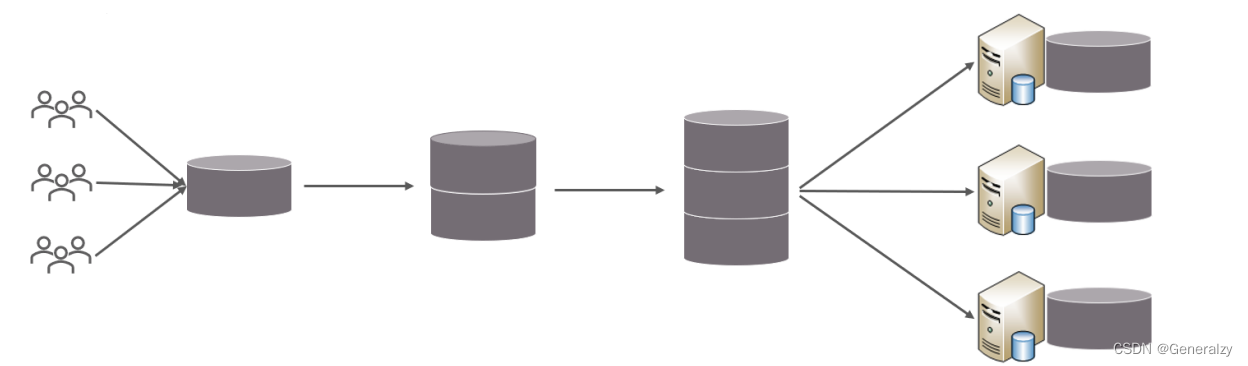
分库分表的中心思想都是将数据分散存储,使得单一数据库/表的数据量变小来缓解单一数据库的性能问题,从而达到提升数据库性能的目的。
拆分策略
分库分表的形式,主要是两种:垂直拆分和水平拆分。而拆分的粒度,一般又分为分库和分表,所以组成的拆分策略最终如下:
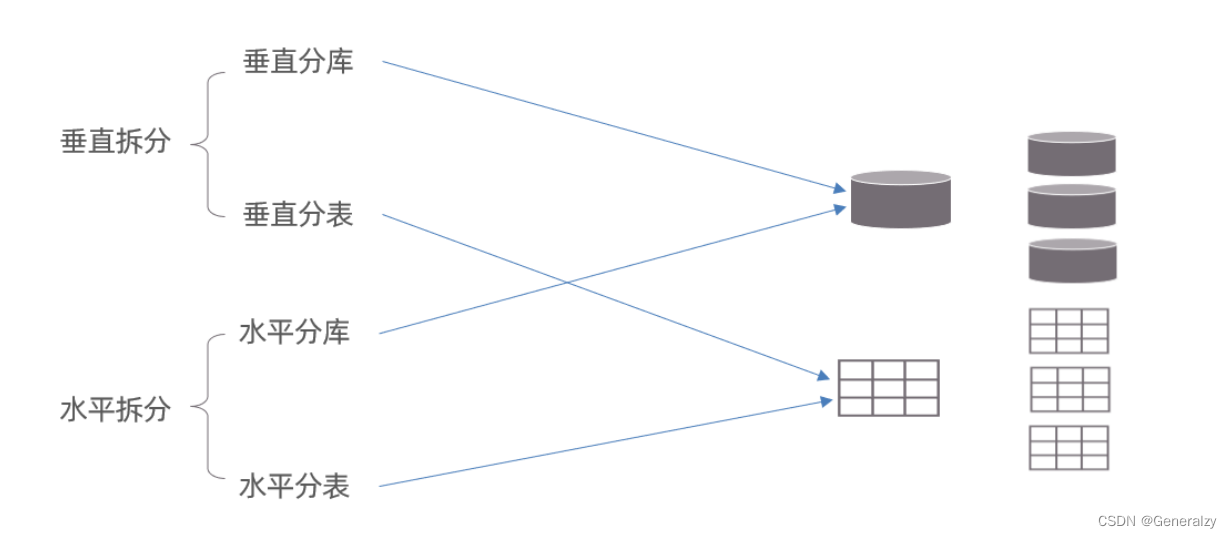
垂直拆分
垂直分库
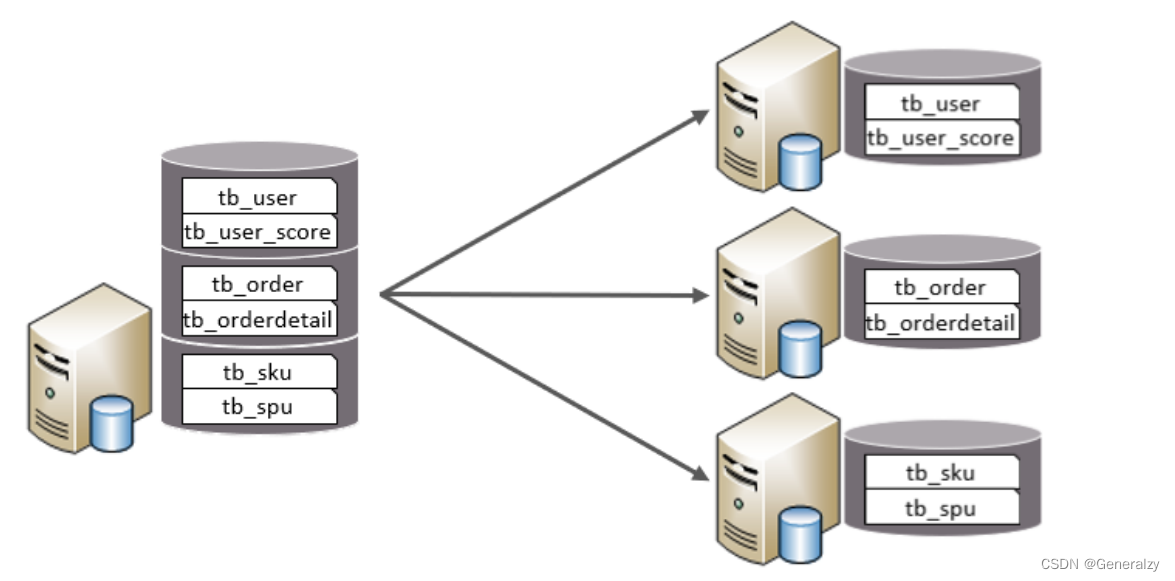
垂直分库:以表为依据,根据业务将不同表拆分到不同库中。
特点:
- 每个库的表结构都不一样。
- 每个库的数据也不一样。
- 所有库的并集是全量数据。
垂直分表
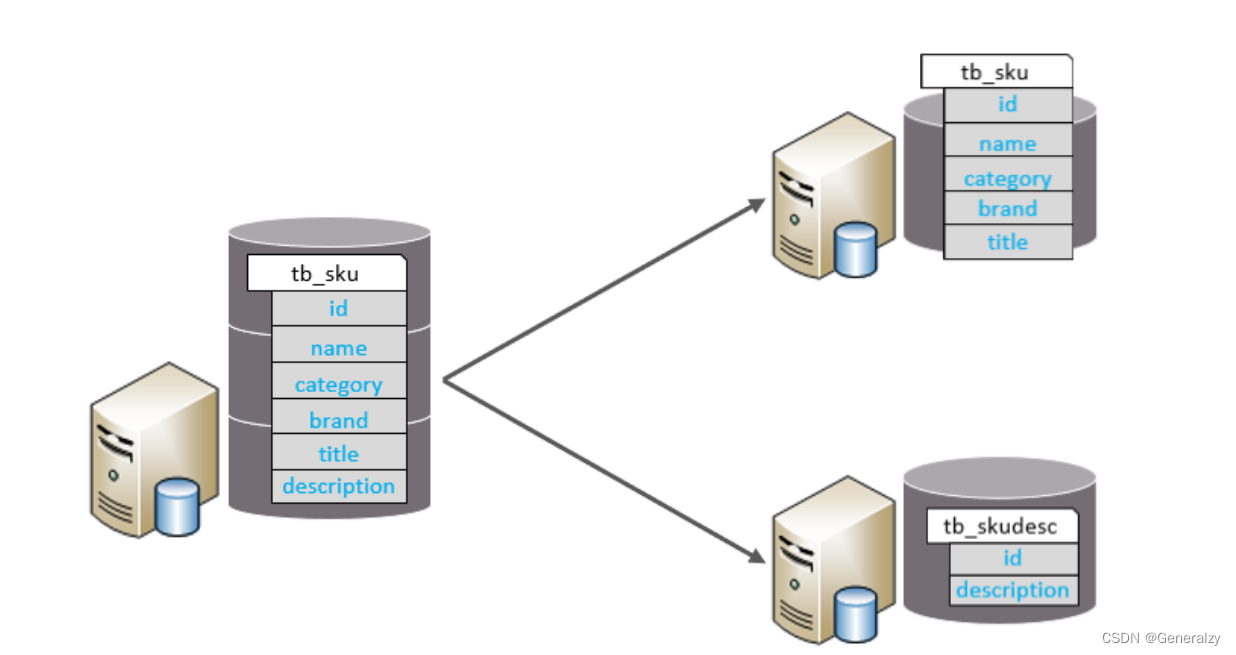
垂直分表:以字段为依据,根据字段属性将不同字段拆分到不同表中。
特点:
- 每个表的结构都不一样。
- 每个表的数据也不一样,一般通过一列(主键/外键)关联。
- 所有表的并集是全量数据。
水平拆分
水平分库
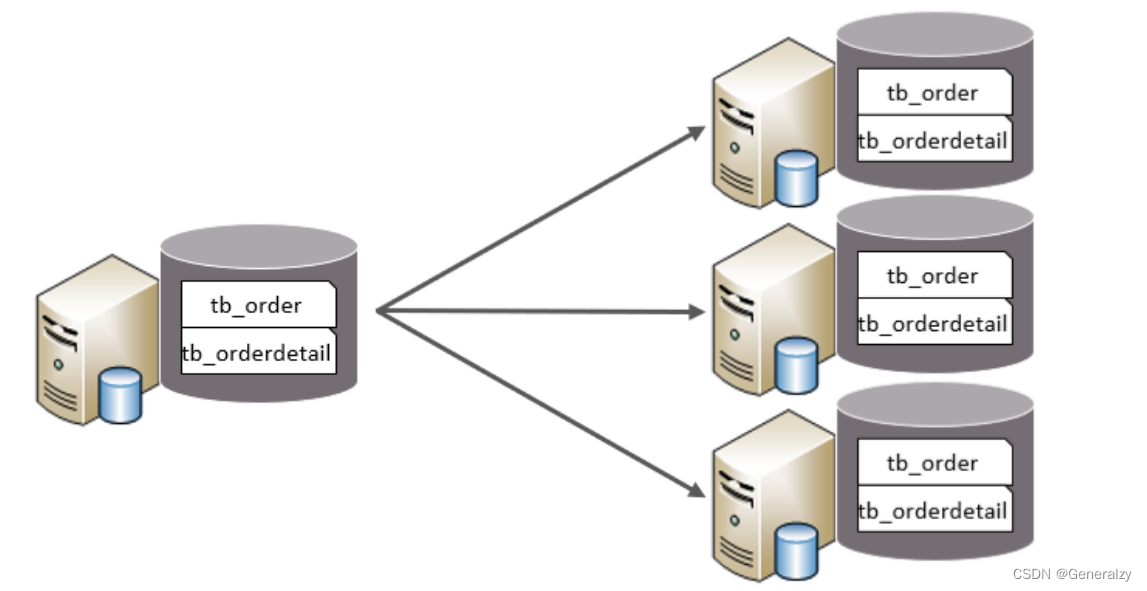
水平分库:以字段为依据,按照一定策略,将一个库的数据拆分到多个库中。
特点:
- 每个库的表结构都一样。
- 每个库的数据都不一样。
- 所有库的并集是全量数据。
水平分表
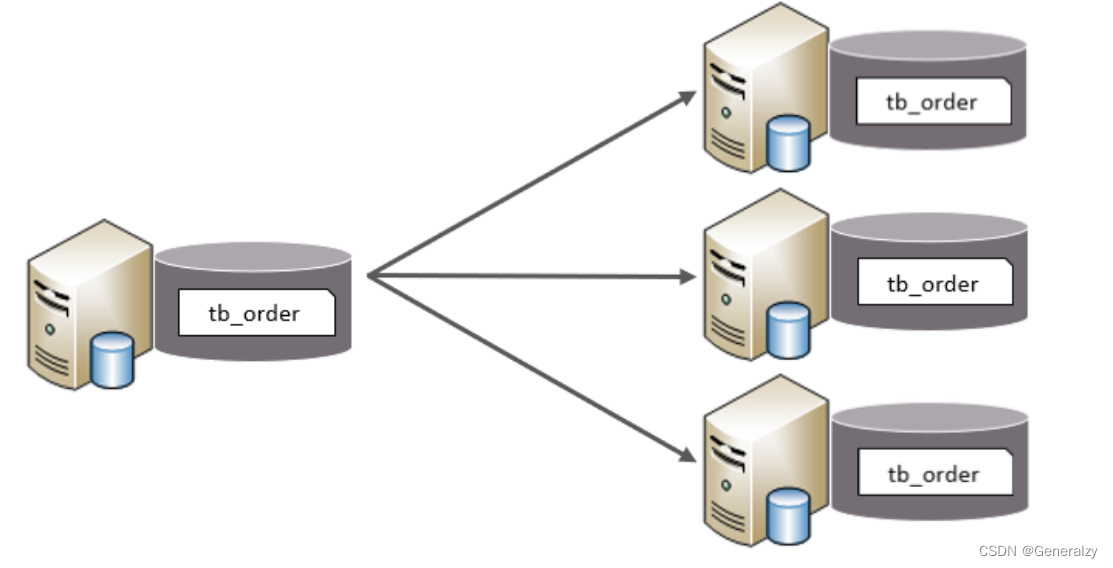
水平分表:以字段为依据,按照一定策略,将一个表的数据拆分到多个表中。
特点:
- 每个表的表结构都一样。
- 每个表的数据都不一样。
- 所有表的并集是全量数据。
在业务系统中,为了缓解磁盘IO及CPU的性能瓶颈,到底是垂直拆分,还是水平拆分;具体是分库,还是分表,都需要根据具体的业务需求具体分析。
实现技术
-
shardingJDBC:基于AOP原理,在应用程序中对本地执行的SQL进行拦截,解析、改写、路由处
理。需要自行编码配置实现,只支持java语言,性能较高。 -
MyCat:数据库分库分表中间件,不用调整代码即可实现分库分表,支持多种语言,性能不及前
者。
We are go developers…通过MyCat中间件来完成分库分表操作。
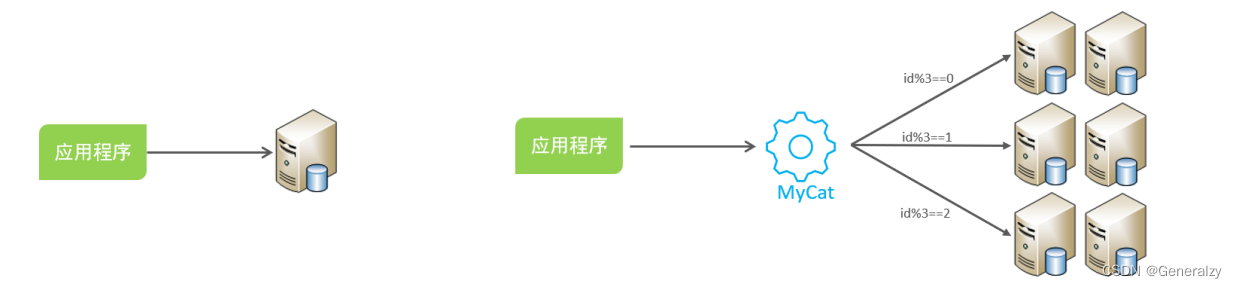
MyCat2
-
Mycat是开源的、活跃的、基于Java语言编写的MySQL数据库中间件。可以像使用mysql一样来使用mycat,对于开发人员来说根本感觉不到mycat的存在。
-
开发人员只需要连接MyCat即可,而具体底层用到几台数据库,每一台数据库服务器里面存储了什么数据,都无需关心。 具体的分库分表的策略,只需要在MyCat中配置即可。
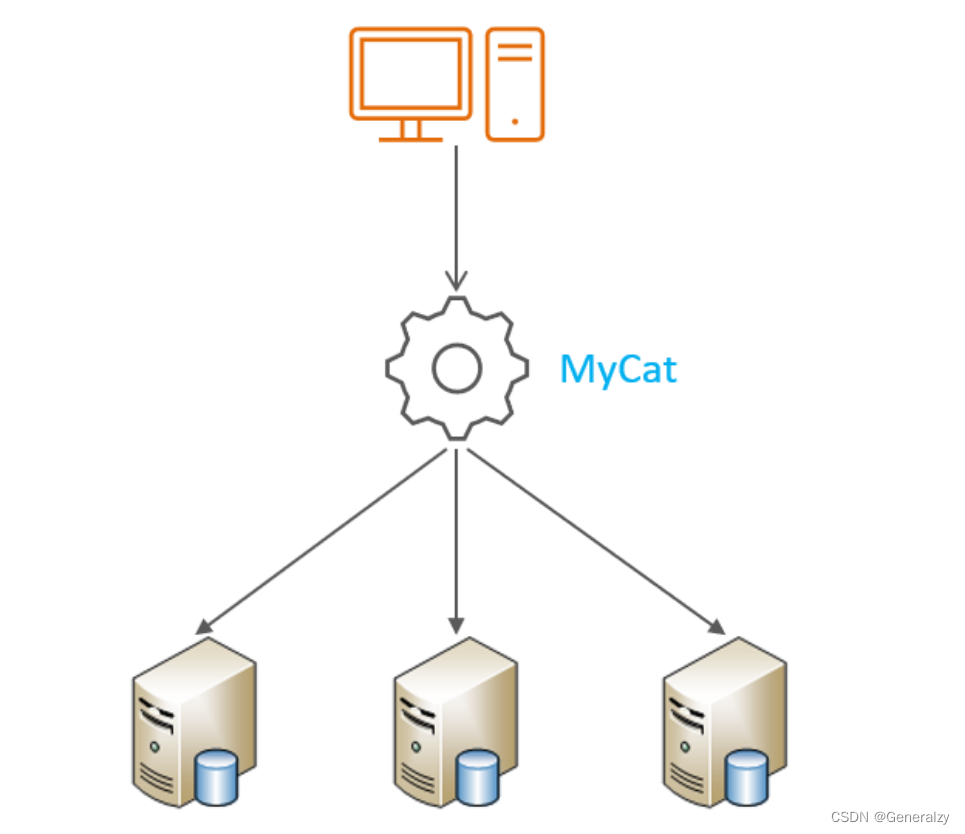
优势:
- 性能可靠稳定
- 强大的技术团队
- 体系完善
- 社区活跃
似乎,mycat1.6.x版本已经凉凉了,连官网都没了,有言论说mycat是伪集群,大厂在生产环境使用mycat的也寥寥无几。
偶然看到了mycat2,大佬说mycat2是另外一个产品,独立的,代码与mycat1没有关系,配置文件也变成了json,以官网为准,继续学习。
mysql2对比mycat1.x
|
功能
|
1.6
|
2
|
|
多语句
|
不支持
|
支持
|
|
blob值
|
支持一部分
|
支持
|
|
全局二级索引
|
不支持
|
支持
|
|
任意跨库join(包含复杂查询)
|
catlet支持
|
支持
|
|
分片表与分片表JOIN查询
|
ER表支持
|
支持
|
|
关联子查询
|
不支持
|
支持一部分
|
|
分库同时分表
|
不支持
|
支持
|
|
存储过程
|
支持固定形式的
|
支持更多
|
|
支持逻辑视图
|
不支持
|
支持
|
|
支持物理视图
|
支持
|
支持
|
|
批量插入
|
不支持
|
支持
|
|
执行计划管理
|
不支持
|
支持
|
|
路由注释
|
支持
|
支持
|
|
集群功能
|
支持
|
支持更多集群类型
|
|
自动hash分片算法
|
不支持
|
支持
|
|
支持第三方监控
|
支持mycat-web
|
支持普罗米斯,kafka日志等监控
|
|
流式合拼结果集
|
支持
|
支持
|
|
范围查询
|
支持
|
支持
|
|
单表映射物理表
|
不支持
|
支持
|
|
XA事务
|
弱XA
|
支持,事务自动恢复
|
|
支持MySQL8
|
需要更改mysql8的服务器配置支持
|
支持
|
|
虚拟表
|
不支持
|
支持
|
|
joinClustering
|
不支持
|
支持
|
|
union all语法
|
不支持
|
支持
|
|
BKAJoin
|
不支持
|
支持
|
|
优化器注释
|
不支持
|
支持
|
|
ER表
|
支持
|
支持
|
|
全局序列号
|
支持
|
支持
|
|
保存点
|
不支持
|
支持
|
|
离线迁移
|
支持
|
支持(实验)
|
|
增量迁移
|
CRC32算法支持
|
BINLOG追平(实验)
|
|
安全停机
|
不支持
|
支持(实验)
|
|
HAProxy协议
|
不支持
|
支持
|
|
会话粘滞
|
update后select会粘滞
|
update后select会粘滞且支持设置时间
|
|
全局表插入支持全局序列号
|
不支持
|
支持
|
|
全局表插入支持主表插入自增结果作为序列号
|
不支持
|
支持
|
|
外部调用的分片算法
|
不支持但可定制
|
支持
|
docker运行mycat2
- 编写Dockerfile
FROM docker.io/adoptopenjdk/openjdk8:latest
ENV AUTO_RUN_DIR ./mycat2
ENV DEPENDENCE_FILE mycat2-1.22-release-jar-with-dependencies-2022-5-12.jar
ENV TEMPLATE_FILE mycat2-install-template-1.21.zip
RUN sed -i "s@http://.*archive.ubuntu.com@http://mirrors.aliyun.com@g" /etc/apt/sources.list
RUN sed -i "s@http://.*security.ubuntu.com@http://mirrors.aliyun.com@g" /etc/apt/sources.list
RUN buildDeps='procps wget unzip' \
&& apt-get update \
&& apt-get install -y $buildDeps
RUN wget -P $AUTO_RUN_DIR/ http://dl.mycat.org.cn/2.0/1.22-release/$DEPENDENCE_FILE \
&& wget -P $AUTO_RUN_DIR/ http://dl.mycat.org.cn/2.0/install-template/$TEMPLATE_FILE
RUN cd $AUTO_RUN_DIR/ \
&& unzip $TEMPLATE_FILE \
&& ls -al . \
&& mv $DEPENDENCE_FILE mycat/lib/ \
&& chmod +x mycat/bin/* \
&& chmod 755 mycat/lib/* \
&& mv mycat /usr/local
#copy mycat /usr/local/mycat/
VOLUME /usr/local/mycat/conf
VOLUME /usr/local/mycat/logs
EXPOSE 8066 1984
CMD ["/usr/local/mycat/bin/mycat", "console"]
- 创建images
docker build -t mycat.org.cn/mycat2:20220513 .
- 创建配置文件conf
wget http://dl.mycat.org.cn/2.0/install-template/mycat2-install-template-1.21.zip
unzip mycat2-install-template-1.21.zip
mv mycat/conf/ ./conf && rm -rf mycat
- 修改mycat的conf下prototype的配置,修改其中对应的user(用户),password(密码),url中的ip
{
"dbType":"mysql",
"idleTimeout":60000,
"initSqls":[],
"initSqlsGetConnection":true,
"instanceType":"READ_WRITE",
"maxCon":1000,
"maxConnectTimeout":3000,
"maxRetryCount":5,
"minCon":1,
"name":"prototypeDs",
"password":"123456",
"type":"JDBC",
"url":"jdbc:mysql://169.254.212.3:3306/mysql?useUnicode=true&serverTimezone=Asia/Shanghai&characterEncoding=UTF-8",
"user":"mycat",
"weight":0
}
- 启动镜像
docker run --name mycat8 --restart=always \
-p 8066:8066 \
-p 1984:1984 \
-v /data/mycat2/conf:/usr/local/mycat/conf \
-v /data/mycat2/logs:/usr/local/mycat/logs \
-d --privileged=true \
mycat.org.cn/mycat2:20220513
- 测试连接
# 没错,就是用mysql客户端连接
mysql -uroot -p123456 -h 192.168.71.130 -P 8066