由NYUv2生成边界GT(1)可知,我们每张GT图片都生成一个对应的.bin文件。存放在D:\datasets\data_proc\train\edge_labels_40文件夹下,下一步我们需要生成.png文件,即需要使用convert_bin_to_png.py。
# -*- coding: utf-8 -*-
import numpy as np
import torch
from PIL import Image
import cv2
import os
import shutil
import imageio
imsave = imageio.imsave
def convert_num_to_bitfield(label_data, h, w,root_folder,name,cls_num=40):
label_list = list(label_data)
all_bit_tensor_list = []
for n in label_list: # Iterate in each pixel
# Convert a value to binary format in each bit.
bitfield = np.asarray([int(digit) for digit in bin(n)[2:]])#用二进制表示n,从2开始因为前两个是符号0b
bit_tensor = torch.from_numpy(bitfield)
actual_len = bit_tensor.size()[0]
padded_bit_tensor = torch.cat((torch.zeros(cls_num - actual_len).byte(), bit_tensor.byte()), dim=0)
all_bit_tensor_list.append(padded_bit_tensor)
y = list(set(all_bit_tensor_list))
all_bit_tensor_list = torch.stack(all_bit_tensor_list).view(h, w, cls_num)#(307200,40)
y_y = torch.unique(all_bit_tensor_list)#(0,1)
label_png_dir = os.path.join("label_img",name) # eg: label_img/label_img_test_2008_002687
pixel = torch.unique(all_bit_tensor_list)
print("label_png_dir:{0}".format(label_png_dir))
print(pixel)
if not os.path.exists(os.path.join(root_folder, label_png_dir)):
os.makedirs(os.path.join(root_folder, label_png_dir))
for cls_idx in range(cls_num):
imsave(os.path.join(root_folder, label_png_dir, str(cls_idx) + '.png'),
all_bit_tensor_list[:, :, cls_idx].numpy())
if __name__ == "__main__":
f = open('D:/datasets/data_orig/train.txt', 'r')
lines = f.readlines()
edge_label_root_folder = 'D:/datasets/data_proc/train/edge_labels_40'
rgb_root_folder = 'D:/datasets/data_proc/train/rgb'
root_folder = 'D:/datasets/data_proc/train'
cnt = 0
for ori_line in lines:#'0003\n'
cnt += 1
line = ori_line.splitlines()
name = line[0]
img_path = os.path.join(rgb_root_folder, name + '.png')
img = Image.open(img_path).convert('RGB')
w, h = img.size
label_path = os.path.join(edge_label_root_folder, name + '.bin')
label_data = np.fromfile(label_path, dtype=np.uint64)
convert_num_to_bitfield(label_data, h, w,root_folder,name,cls_num=40)
# w, h = 640,480
# label_path = os.path.join(edge_label_root_folder,'0003.bin')
# label_data = np.fromfile(label_path, dtype=np.uint64)
# convert_num_to_bitfield(label_data, h, w,root_folder)
1:首先从if name == “main”:开始,打开train.txt,其实生成的.bin文件有自己的txt文件,但是我觉得和rgb的train.txt一样,就直接使用train.txt是一样的。
2:读取每一行的内容,在python中使用f.readlines()读取,则lines 里面共有七百多个数值对应七百多张训练图片。
3:找到edge_label_root_folder ,rgb_root_folder ,分别存放的边界gt,.bin文件,rgb,.png文件。这里给出root_folder是因为需要在root_folder 文件夹下生成一个新的文件夹label_img来存放由.bin转换为.png的边界GT。
4:遍历 lines ,同时添加一个计数的,注这里因为lines会产生’0003\n’,需要将\n去掉,所以添加了.splitlines(),然后会生成一个[‘0003’],需要通过索引将’0003’取出来。
5:我们有路径,也有路径下对应的name,就可以找到对应的rgb文件下的.png文件。打开,转换为RGB,并获得对应.png文件的大小。
6:接着我们获得edge_label_root_folder文件下对应的.bin文件。
7:通过np.fromfile载入二进制文件,注:这里dtype=np.uint64,只有uint64可以存放下2的40次方这么大的数据,原来SBD数据集只有20个类别,所以dtype=np.uint32是可以的,但是NYUv2有40个类别,采用dtype=np.uint64会导致错误,生成的通道该有的边缘没有,最后一个通道甚至包含了全部的类别,上个星期没发现这个错误,导致生成的边界是错误的,被老师发现狠狠地批评了一顿。
载入文件后,输出的是(480x640,1)的array。
8:接着将标签数据进行转换:
8.1:将label转换为一个list,然后逐个进行处理。将n转换为二进制,然后取第二位之后的数字,因为数字转换为二进制后,前两个数字是0b。
8.2:将其转换为tensor,然后获取数据的长度。
8.3:生成一个(cls_num - actual_len)大小的0矩阵,和经过tensor转换后的二进制长度拼接在一起。这个地方就关系到之前的2的num_class次方,通过对不同的像素,即不同的类进行‘编码’,在这里对编码的数字进行解码。这样生成的数据就为当前像素值的二进制编码,从左往右第一个1开始,前面全部补0,直到总共40位。
8.4:然后将concat之后的数字堆叠在一起,每一个是长度为40,共有480x640个。然后转换为(h, w, cls_num)大小。每一个像素都有40位,那么reshape之后,假设第一个像素40位中位于第几位等于1,就转换为40个通道中位于第几个通道为1。即为该通道对应的类别。

8.5:接着执行label_png_dir,生成root_folder/label_png_dir路径。
8.6:逐个通道进行遍历,将每个通道保存到root_folder/label_png_dir路径下,执行40次。

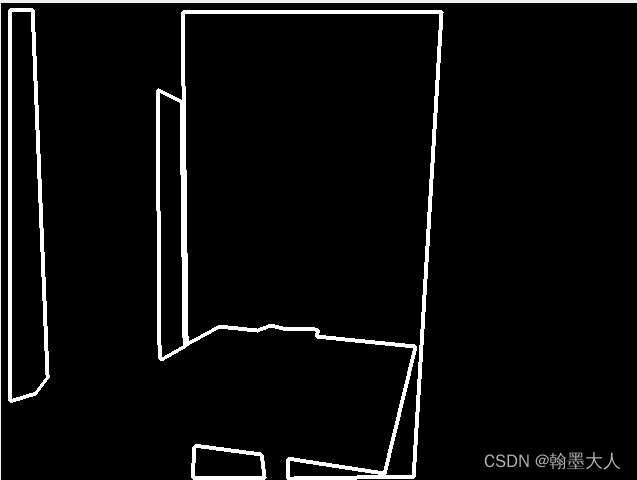
9:对每一个通道可视化:以0003.bin转换后为例: