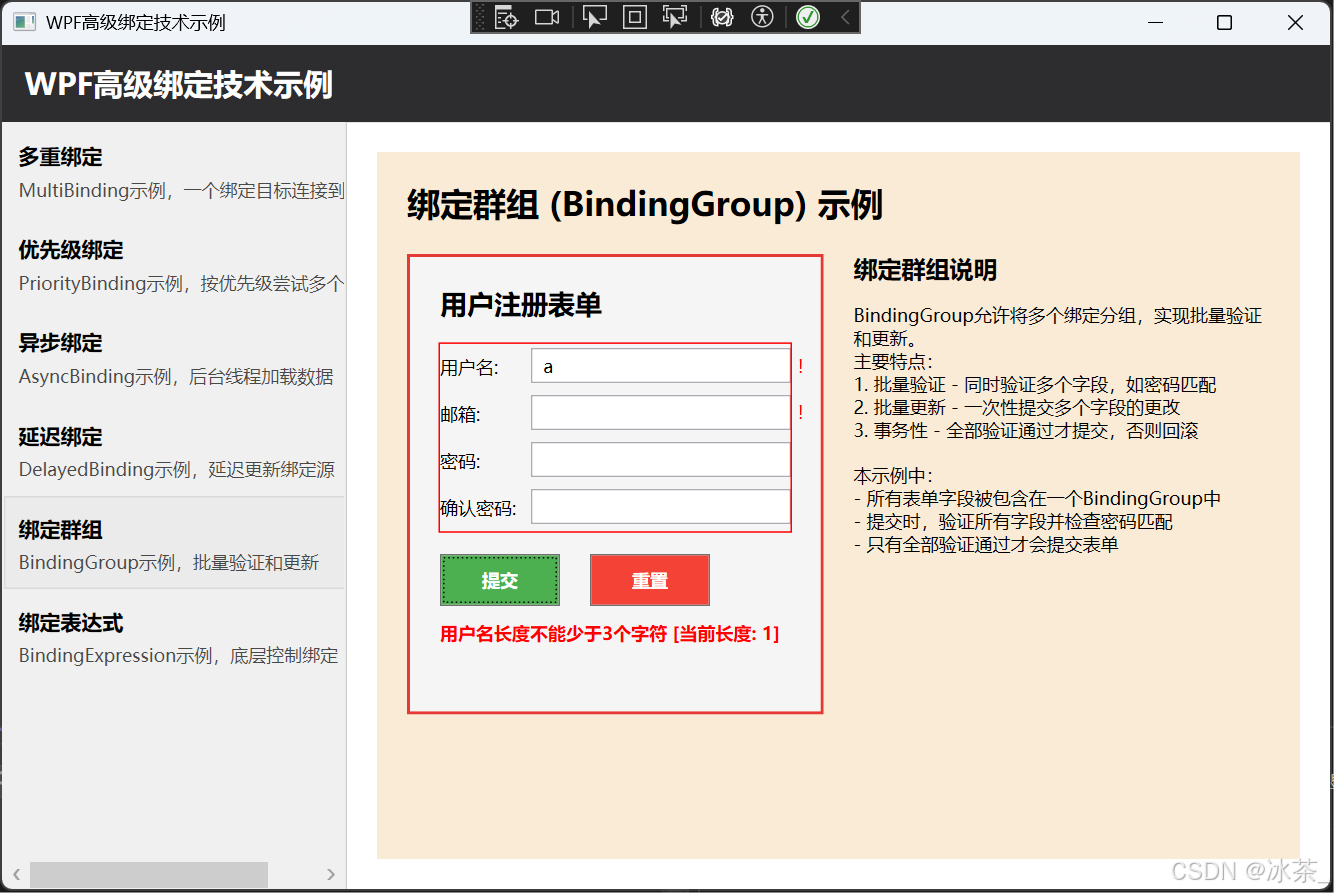
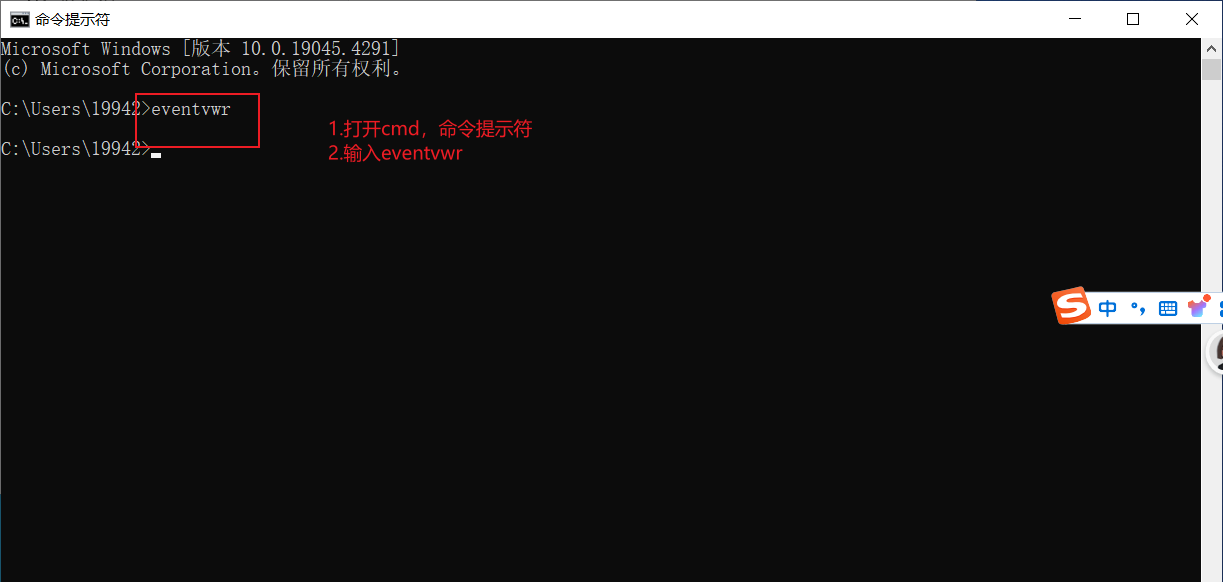
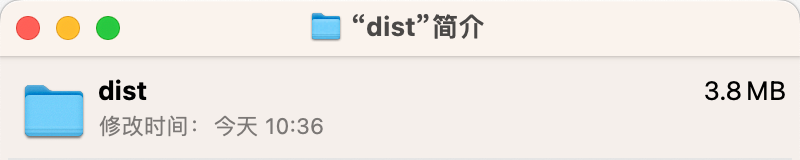
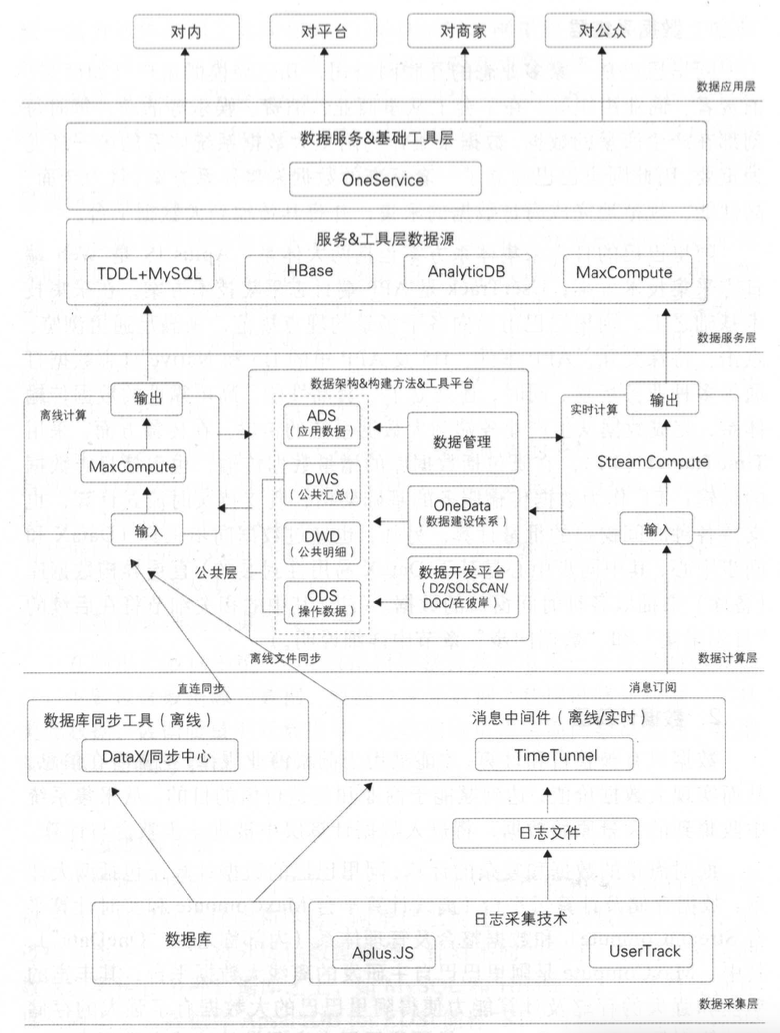
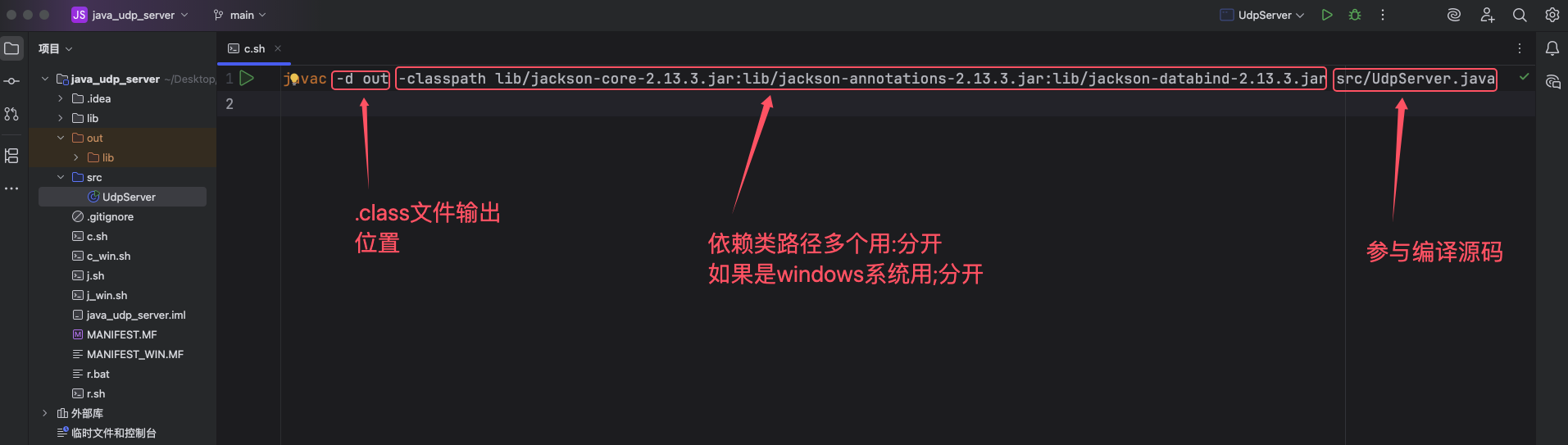
大规模预训练指在巨量无标注数据上,通过自监督学习训练大参数量的基础模型,使其具备通用的表征与推理能力。其重要作用如下:
一 跨任务泛化
单一模型可在微调后处理多种NLP(自然语言处理)、CV(计算机视觉)任务。
1.1大规模预训练模型的核心目标
在大量无标签文本上学习语言的通用模式,形成高维语义向量空间。
实现方法:
(1)词汇层面:通过词嵌入(如WordPiece)捕捉词汇间关系(如语义、句法相似性)。
(2)上下文层面:利用Transformer的自注意力机制建模长距离依赖关系。
(3)知识层面:通过跨领域数据隐式存储常识和领域知识(如时间序列、因果关系)。
1.2模型架构的适应性
(1)Transformer的灵活性:通过自注意力机制和层级堆叠(低层捕捉语法,高层捕捉语义和逻辑)
(2)任务适配能力:通过调整顶层结构(如添加分类头、序列标注层、生成解码器),同一模型可适配不同任务.
1.3 参数迁移与微调策略
(1)参数高效迁移:作为任务无关的高质量初始化,覆盖95%以上的模型参数。
(2)微调时更新:仅调整顶层结构和小部分底层参数即可(如最后3-4层)。(实验表明:底层参数对通用特征敏感,高层参数更需适应任务特性)
大规模预训练模型通过通用表示学习和灵活架构设计,实现了从训练数据到下游任务的高效迁移。微调的本质是通过局部参数调整,将通用知识映射到具体任务空间。
二 上下文学习
无需参数更新,仅通过Prompt(提示)即可适配新任务(如GPT-3)。
其本质是为模型输入结构化引导信息,通过特定模板或指示,激发表征空间中预存的通用知识,使其能够在不更新参数的情况下适应新任务。
核心价值:
(1)无需微调:Zero-shot/Few-Shot场景下快速部署。
(2)人机对齐:通过自然语言直观引导模型行为
(3)知识蒸馏:将复杂任务简化为预训练已知的模式
| 方法 | 数据需求 | 模型改动 | 应用场景 |
|---|---|---|---|
| 全量微调 | 数千-百万样本 | 调整全部参数 | 专一任务 |
| Prompt | 0-数十样本 | 仅修改输入 | 多任务快速切换 |
2.1Prompt基本结构
prompt_template = """
任务指令:{instruction} #指令:明确任务类型
输入内容:{input} #输入:待处理的实际内容
示例参考:{examples} #示例:少量示范
模型回答:
"""
2.2 Prompt类型对比
| 类型 | 示例 | 适用场景 |
|---|---|---|
| 完形填空式 | “中国的首都是[MASK]。” | 知识推理(如BERT) |
| 指令驱动式 | “请将以下英文翻译为中文:{text}” | 文本生成(如GPT系列) |
| 思维链(CoT) | “问题:X。逐步推理过程:首先…因此答案是…” | 复杂推理任务 |
| 元模板式 | “假设你是一名律师,请回答:…” | 角色设定类任务 |
2.3Prompt设计方法论
2.3.1人工设计准则
(1)词汇兼容性:使用模型预训练时常见的表达(如“翻译”、“总结”)
(2)逻辑连贯性:示例与任务保持严格一致性(避免歧义)
(3)位置敏感性:关键指令放开头(因Transformer对前128词关注度更高)
Bad vs Good Prompt对比:
# Bad(模糊指令)
"处理这段文本:{text}"
# Good(明确指向)
"请对以下中文评论进行情感分析(正向/负向),输出结果:
评论:{text}
情感标签:"
2.3.2 自动生成技术
(1)AutoPrompt:通过梯度搜索找到使目标标签概率最大化的词序列。
(其中 ⊕\oplus⊕ 表示提示连接操作)
(2)Prompt Tuning:训练可学习的软提示向量(Soft Prompt)
# 示例代码:软提示嵌入
soft_prompt = nn.Parameter(torch.randn(10, hidden_dim)) # 10个可学习向量
inputs = torch.cat([soft_prompt, text_embeddings], dim=1)
2.3.3实际应用案例
多语言翻译:Prompt设计
prompt = """
将英文翻译为中文:
Example 1:
Input: "Hello, how are you?" → Output: "你好,最近怎么样?"
Example 2:
Input: "The quick brown fox jumps over the lazy dog" → Output: "敏捷的棕色狐狸跳过了懒狗"
现在翻译:
Input: "Large-scale pretraining requires massive computing resources."
Output:
"""
Prompt技术通过语义空间导航激活模型的隐式知识,已成为大规模预训练模型的核心交互范式。未来将向多模态、自动化、可解释方向发展,同时需解决提示注入攻击、评估量化等挑战。
三 数据效率
相比传统监督学习,微调所需标注数据减少90%以上,其本质源于通用知识预存储与参数高效迁移机制的结合。
其核心逻辑为:
知识压缩:预训练阶段将海量无标注数据的信息压缩至模型参数中。
知识检索:微调通过轻量级参数调整,激活与任务相关的知识子集。
3.1知识预存储:预训练阶段的隐含知识泛化
3.1.1通用语义表征学习
(1)预训练数据覆盖性:模型在万亿级跨领域文本(网页、书籍、代码)中学习,涵盖词汇、语法、逻辑关系、常识和领域知识,形成高度抽象的通用语义空间。
(2)数学视角:预训练通过语言建模损失(如MLM、自回归预测),强制模型编码文本的条件概率分布:
这种优化使得隐藏层表示 成为与任务无关的“语言特征蒸馏器”。
3.1.2知识的参数化存储
参数冗余设计:大模型(如175B参数的GPT-3)通过过参数化架构,将多样化知识分布在神经网络的多个层级。例如:
浅层网络:捕捉语法结构(如句法树)
中层网络:编码语义角色(如主谓宾关系)
深层网络:存储逻辑推理模式(如因果关系、类比联想)
3.2参数高效迁移:微调阶段的关键技术机制
3.2.1参数冻结策略
| 策略 | 可调参数占比 | 典型应用场景 |
|---|---|---|
| 全量微调 | 100% | 数据充足(>10,000样本) |
| 部分层微调 | 5%-20% | 中小规模数据(100-1k样本) |
| 适配器/软提示 | 0.5%-3% | 极小样本(<100样本) |
科学依据:底层参数承载通用特征(词嵌入、句法分析),高层参数更侧重任务适配(如情感极性分类),因此仅微调最后3-4层即可适配大多数任务。
3.2.2 梯度更新约束
通过低秩适应(LoRA)等技术减少梯度更新维度:
其中秩r通常设为8-64,使参数更新量仅为原模型的0.01%级别。
LoRA的核心思想:在微调时,冻结原始模型参数,仅通过低秩分解的增量矩阵来适应下游任务。
数学表达:
对于预训练权重矩阵 ,LoRA将其更新量约束为低秩矩阵:
微调后的权重为:
其中:
:低秩的维度(通常设为8-64)
:缩放系数(控制增量幅度)
LoRA的工作原理
实现步骤:
(1)冻结原参数:保持预训练权重 W 不变,避免灾难性遗忘
(2)引入可训练低秩矩阵:向模型插入旁路矩阵 B 和 A,梯度仅更新这两个小矩阵
(3)前向传播合并:在计算时动态叠加 ,不影响推理速度
技术原理:
(1)过参数化假设:大规模神经网络中存在大量冗余参数,真正有效更新存在于低维子空间
(2)秩的物理意义:秩 r 约束了模型变化的自由度,实验表明 r=8 足以覆盖大多数任务需求
import torch
import torch.nn as nn
class LoRALayer(nn.Module):
def __init__(self, in_dim, out_dim, rank=8):
super().__init__()
self.rank = rank
# 原始权重(冻结)
self.W = nn.Parameter(torch.randn(out_dim, in_dim), requires_grad=False)
# LoRA旁路参数
self.B = nn.Parameter(torch.zeros(out_dim, rank))
self.A = nn.Parameter(torch.zeros(rank, in_dim))
def forward(self, x):
# 前向计算:Wx + (B A^T)x = (W + B A^T)x
return x @ (self.W + (self.B @ self.A)).T
# 使用示例:替换Transformer的FFN层
class TransformerFFNWithLoRA(nn.Module):
def __init__(self, d_model, d_ff, rank=8):
super().__init__()
self.fc1 = LoRALayer(d_model, d_ff, rank)
self.fc2 = LoRALayer(d_ff, d_model, rank)
3.2.3任务相似性补偿
当下游任务与预训练任务的语义空间重叠度较高时(如情感分析 vs 预训练的文本理解),模型只需微调任务专属特征,而非重建整个语义体系。
量化指标:任务相似性 S 的计算公式:
当 S>0.7 时,仅需1%的标注数据即可达到全量训练90%的性能。
3.2.4与传统监督学习的对比机制
| 维度 | 传统监督学习 | 预训练+微调 | 效率差异来源 |
|---|---|---|---|
| 初始化状态 | 随机初始化的白板模型 | 携带语言结构和知识的“专家”模型 | 预训练模型具备任务无关的强先验 |
| 数据依赖 | 需覆盖所有可能的特征组合 | 仅需补充任务特有的特征差异 | 通过知识蒸馏避免从头学习 |
| 参数更新量 | 全参数空间搜索 | 局部子空间优化(<10%参数) | 维数灾难(Curse of Dimensionality)的缓解 |
| 过拟合风险 | 高(需正则化、早停等强干预) | 低(通用表征提供正则化效果) | 隐式正则化提升小数据泛化能力 |
四 基础架构对比
| 架构类型 | 代表模型 | 预训练目标 | 典型应用领域 |
|---|---|---|---|
| 自回归型 | GPT系列 | 语言建模(从左到右) | 文本生成、问答 |
| 自编码型 | BERT | 掩码语言模型 | 文本分类、实体识别 |
| 混合架构 | T5 | 文本到文本转换 | 翻译、摘要生成 |
| 多模态融合 | CLIP、GPT-4 | 图文对齐损失 | 跨模态检索、生成 |