也不知道大家目前都用的java编程软件有哪些,毕竟在应用程序中,未读和已读消息的设计取决于应用程序的需求和目标。下面是一些常见的设计模式:
一、简单的未读/已读标记
简单的未读/已读标记:这是最常见的设计,用户打开应用程序后,未读消息会用一个特殊的标记(通常是未读计数器)标识出来。当用户查看这些消息时,它们会被标记为已读,未读计数器会减少。这种设计对于大多数应用程序来说是最直观的,并且易于使用。它被广泛应用于各种应用程序和用户界面中,以显示用户已读和未读的内容。该模式通常包括以下元素:

该模式的主要优点是它可以帮助用户更好地组织和管理他们的内容,使他们能够更轻松地找到未读的内容。此外,该模式还可以提高用户体验,因为用户可以清楚地了解哪些内容是新的,并且可以在需要时快速的找到它们。
在应用程序中实现未读已读设计模式时,需要考虑以下问题:
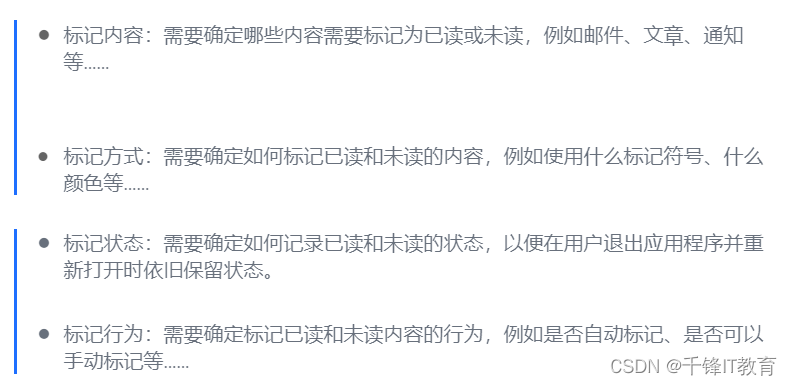
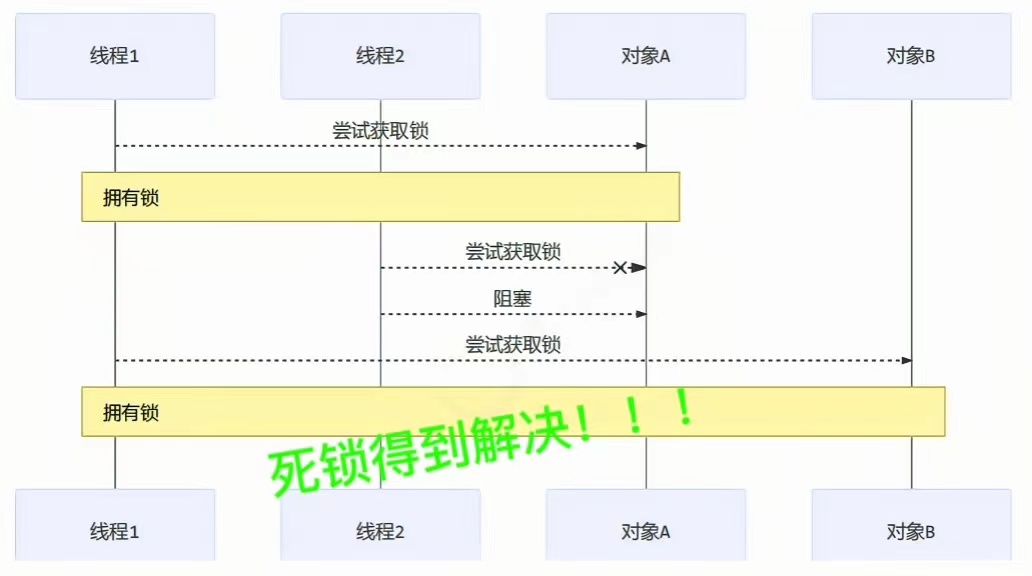
综上所述,未读/已读设计模式是一种非常重要的用户界面设计模式,它可以帮助用户更好地管理和查找他们的内容,并提高用户体验。通常我们在处理处理已读未读状态的数据的时候都会选用Redis处理。
Redis处理已读未读状态的好处:

综上所述,Redis是一个非常适合处理已读未读状态的数据的数据库,它可以提供快速、可扩展、可靠、灵活和高效的解决方案。
二、滑动标记为已读
滑动标记为已读:在这种设计中,用户可以在消息列表中向左或向右滑动消息来将其标记为已读。这种设计可以更快地标记消息为已读,但需要用户在每个消息上进行手动操作。
滑动标记为已读这种设计的优点:

滑动标记为已读这种设计的缺点:
● 误操作:滑动标记消息为已读操作可能会被误触发,尤其是当用户需要滑动屏幕查看消息时。
● 可能会遗漏未读消息:如果用户对某个未读消息进行了滑动标记为已读,但之后忘记对该消息进行回复或处理,就可能会遗漏该消息。
● 可能会干扰用户体验:如果滑动标记的方向和其他操作冲突,可能会干扰用户的正常使用体验。
当然滑动标记为已读是一个常见的用户体验需求,可以通过多种技术实现。

无论使用哪种技术,需要注意保证标记为已读消息这种的操作的准确性和安全性,避免意外的数据丢失或误操作。同时,需要进行测试和优化,确保用户体验良好,并且在不同的设备和浏览器上都能正常工作。
三、自动标记为已读
自动标记为已读:这种设计会自动将已经出现在用户屏幕上的消息标记为已读。例如,当用户向下滚动消息列表时,应用程序可以自动将屏幕上的所有消息标记为已读。这种设计可以提高用户效率,但可能会导致一些消息被忽略。
自动标记为已读这种设计的优点:

自动标记为已读这种设计的缺点:

实现自动标记的技术可以有很多种,具体使用哪种技术取决于数据类型、任务类型、标记方式等因素。以下列举几种常用的技术:

实现自动标记的开发工具取决于具体的技术选择和任务需求。以下列举几种常用的开发工具:
● Python:Python是一种通用编程语言,具有丰富的机器学习、自然语言处理、python实现简单爬虫功能、图像处理等,可以用于实现自动标记任务。
● R语言:R语言也是一种常用的数据分析和统计编程语言,拥有许多机器学习、自然语言处理等库和工具包,可以用于自动标记任务。
● TensorFlow:TensorFlow是谷歌开源的深度学习框架,可以用于实现自动标记任务中的神经网络模型。
● PyTorch:PyTorch是Facebook开源的深度学习框架,也可以用于实现自动标记任务中的神经网络模型。
● OpenCV:OpenCV是一个开源的计算机视觉库,可以用于实现自动标记任务中的图像处理技术。
● Keras:Keras是一个高级神经网络API,可以以TensorFlow或者Theano作为后端,可以用于实现自动标记任务中的神经网络模型。
● RapidMiner:RapidMiner是一种商业的数据科学平台,可以进行机器学习、自然语言处理、图像处理等任务,并且有可视化界面,易于使用。
总的来说,选择何种开发工具取决于具体的任务和技术,需要根据自己的需求选择最适合的开发工具。
当然这些设计模式可以组合使用,以提供更好的用户体验。例如,可以使用简单的未读/已读标记,但允许用户通过滑动来更快地将消息标记为已读。无论如何,最终的设计应该依赖于应用程序的需求和用户的使用情况。