文章目录
- 1. Java客户端数据生产流程解析
- 2. 消息发送方式
- 3. 序列化器
- 4. 分区器
- 5. 拦截器
- 6. 发送原理剖析
- 7. Kafka生产者参数配置
1. Java客户端数据生产流程解析
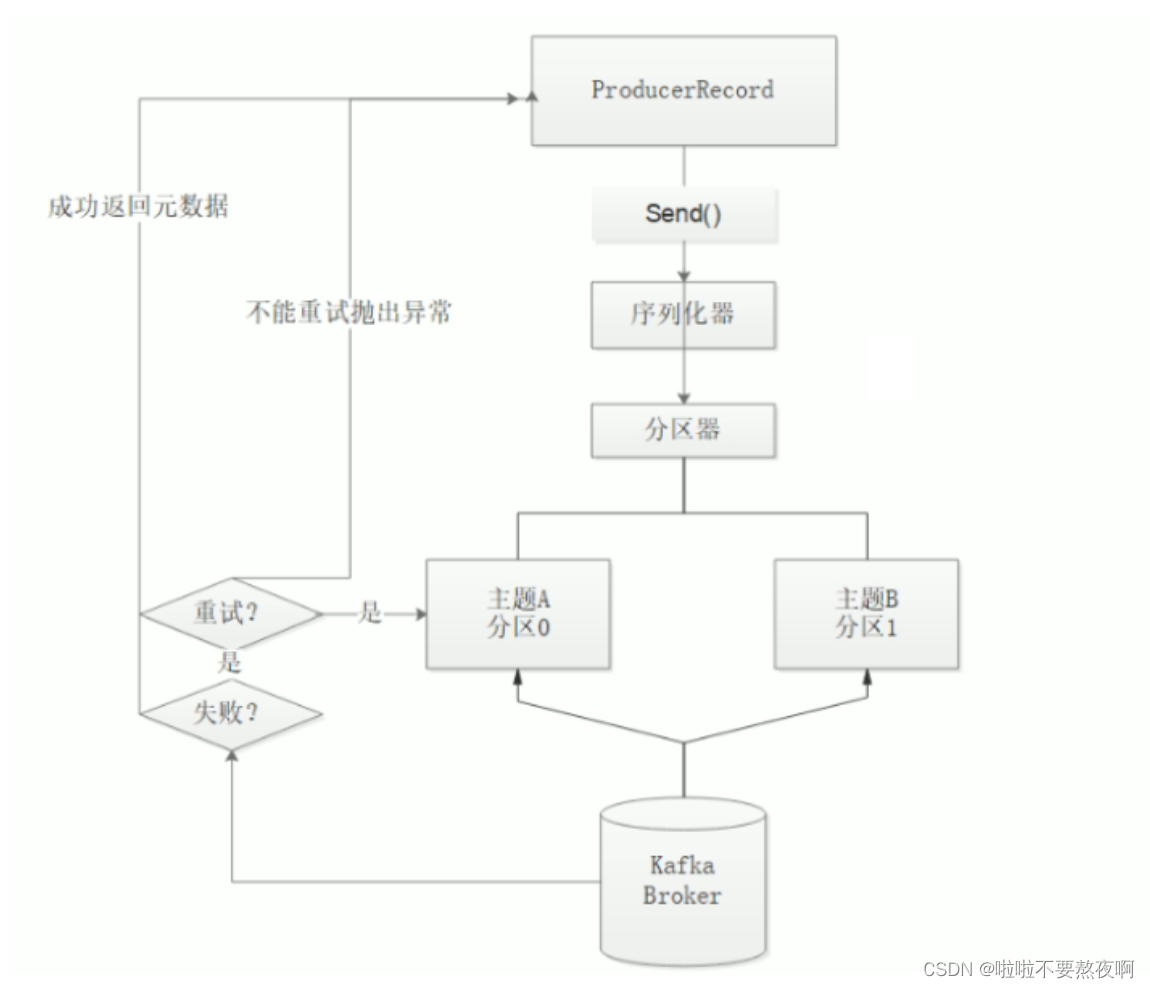
- 首先要构造一个 ProducerRecord 对象,该对象可以声明主题Topic、分区Partition、键 Key以及值 Value,主题和值是必须要声明的,分区和键可以不用指定。
- 调用send() 方法进行消息发送。
- 因为消息要到网络上进行传输,所以必须进行序列化,序列化器的作用就是把消息的 key 和value对象序列化成字节数组。
- 接下来数据传到分区器,如果之间的 ProducerRecord 对象指定了分区,那么分区器将不再做任何事,直接把指定的分区返回;如果没有,那么分区器会根据 Key 来选择一个分区,选择好分区之后,生产者就知道该往哪个主题和分区发送记录了。
- 接着这条记录会被添加到一个记录批次里面,这个批次里所有的消息会被发送到相同的主题和分区。会有一个独立的线程来把这些记录批次发送到相应的 Broker 上。
- Broker成功接收到消息,表示发送成功,返回消息的元数据(包括主题和分区信息以及记录在分区里的偏移量)。发送失败,可以选择重试或者直接抛出异常。
2. 消息发送方式
1. 异步发送不带返回值
public class CustomProducer01 {
public static void main(String[] args) {
// kafka生产者属性配置
Properties properties = new Properties();
properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,"192.168.38.22:9092");
properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,StringSerializer.class.getName());
// kafka生产者
KafkaProducer<String, String> kafkaProducer = new KafkaProducer<String, String>(properties);
ProducerRecord<String, String> producerRecord = new ProducerRecord<>("test", "hello,kafka");
// 发送消息:默认是异步发送方式
kafkaProducer.send(producerRecord);
// 关闭资源
kafkaProducer.close();
}
}
2. 异步发送带返回值
public class CustomProducer01 {
public static void main(String[] args) {
// kafka生产者属性配置
Properties properties = new Properties();
properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,"192.168.38.22:9092");
properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,StringSerializer.class.getName());
// kafka生产者
KafkaProducer<String, String> kafkaProducer = new KafkaProducer<String, String>(properties);
ProducerRecord<String, String> producerRecord = new ProducerRecord<>("test", "hello,kafka");
// 发送消息:默认是异步发送方式
kafkaProducer.send(producerRecord, new Callback() {
@Override
public void onCompletion(RecordMetadata metadata, Exception exception) {
// 说明消息发送成功
if(exception==null){
System.out.println("metadata.topic() = " + metadata.topic());
System.out.println("metadata.partition() = " + metadata.partition());
System.out.println("metadata.offset() = " + metadata.offset());
}
}
});
// 关闭资源
kafkaProducer.close();
}
}

3. 同步发送
public class CustomProducer01 {
public static void main(String[] args) throws ExecutionException, InterruptedException {
// kafka生产者属性配置
Properties properties = new Properties();
properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,"192.168.38.22:9092");
properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,StringSerializer.class.getName());
// kafka生产者
KafkaProducer<String, String> kafkaProducer = new KafkaProducer<String, String>(properties);
ProducerRecord<String, String> producerRecord = new ProducerRecord<>("test", "hello,kafka");
// 发送消息
// 通过send()发送完消息后返回一个Future对象,然后调用Future对象的get()方法等待kafka响应
// 如果kafka正常响应,返回一个RecordMetadata对象,该对象存储消息的偏移量
// 如果kafka发生错误,无法正常响应,就会抛出异常,我们便可以进行异常处理
RecordMetadata recordMetadata = kafkaProducer.send(producerRecord).get();
System.out.println("recordMetadata.topic() = " + recordMetadata.topic());
System.out.println("recordMetadata.partition() = " + recordMetadata.partition());
System.out.println("recordMetadata.offset() = " + recordMetadata.offset());
// 关闭资源
kafkaProducer.close();
}
}

3. 序列化器
消息要到网络上进行传输,必须进行序列化,而序列化器的作用就是如此。Kafka 提供了默认的字符串序列化器(org.apache.kafka.common.serialization.StringSerializer),还有整型(IntegerSerializer)和字节数组(BytesSerializer)序列化器,这些序列化器都实现了接(org.apache.kafka.common.serialization.Serializer)基本上能够满足大部分场景的需求。
@Data
@Builder
public class Company {
private String name;
private String address;
}
@Data
public class CustomSerializer implements Serializer<Company> {
@Override
public void configure(Map<String, ?> configs, boolean isKey) {
Serializer.super.configure(configs, isKey);
}
@Override
public byte[] serialize(String topic, Company data) {
if (data == null) {
return null;
}
byte[] name, address;
try {
if (data.getName() != null) {
name = data.getName().getBytes("UTF-8");
} else {
name = new byte[0];
}
if (data.getAddress() != null) {
address = data.getAddress().getBytes("UTF-8");
} else {
address = new byte[0];
}
ByteBuffer buffer = ByteBuffer.allocate(4 + 4 + name.length + address.length);
buffer.putInt(name.length);
buffer.put(name);
buffer.putInt(address.length);
buffer.put(address);
return buffer.array();
} catch (UnsupportedEncodingException e) {
e.printStackTrace();
}
return new byte[0];
}
@Override
public byte[] serialize(String topic, Headers headers, Company data) {
return Serializer.super.serialize(topic, headers, data);
}
@Override
public void close() {
Serializer.super.close();
}
}
使用自定义的序列化器:
public class CustomProducer01 {
public static void main(String[] args) throws ExecutionException, InterruptedException {
// kafka生产者属性配置
Properties properties = new Properties();
properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,"192.168.38.22:9092");
// 使用自定义序列化器
properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, CustomSerializer.class.getName());
properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,CustomSerializer.class.getName());
// kafka生产者
KafkaProducer<String, Company> kafkaProducer = new KafkaProducer<String, Company>(properties);
Company company = Company.builder().name("俏江南").address("全国").build();
ProducerRecord<String, Company> producerRecord = new ProducerRecord<String,Company>("test",company);
kafkaProducer.send(producerRecord).get();
// 关闭资源
kafkaProducer.close();
}
}

4. 分区器
本身kafka有自己的分区策略的,如果未指定,就会使用默认的分区策略:
Kafka根据传递消息的key来进行分区的分配,即 hash(key) % numPartitions。如果Key相同的话,那么
就会分配到同一分区。
public class DefaultPartitioner implements Partitioner {
private final StickyPartitionCache stickyPartitionCache = new StickyPartitionCache();
public void configure(Map<String, ?> configs) {}
public int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster) {
return partition(topic, key, keyBytes, value, valueBytes, cluster, cluster.partitionsForTopic(topic).size());
}
public int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster,int numPartitions) {
if (keyBytes == null) {
return stickyPartitionCache.partition(topic, cluster);
}
// hash the keyBytes to choose a partition
return Utils.toPositive(Utils.murmur2(keyBytes)) % numPartitions;
}
public void close() {}
public void onNewBatch(String topic, Cluster cluster, int prevPartition) {
stickyPartitionCache.nextPartition(topic, cluster, prevPartition);
}
}
自定义分区器:
public class DefinePartitioner implements Partitioner {
private final AtomicInteger counter = new AtomicInteger(0);
@Override
public int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster) {
List<PartitionInfo> partitionInfos = cluster.availablePartitionsForTopic(topic);
int size = partitionInfos.size();
if(null==keyBytes){
return counter.getAndIncrement() % size;
}else{
return Utils.toPositive(Utils.murmur2(keyBytes) % size);
}
}
@Override
public void close() {
}
@Override
public void configure(Map<String, ?> configs) {
}
}
使用自定义分区器:
public class CustomProducer01 {
public static void main(String[] args) throws ExecutionException, InterruptedException {
// kafka生产者属性配置
Properties properties = new Properties();
properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,"192.168.38.22:9092");
// 使用自定义序列化器
properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, CustomSerializer.class.getName());
properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,
CustomSerializer.class.getName());
// 使用自定义分区器
properties.put(ProducerConfig.PARTITIONER_CLASS_CONFIG,
DefinePartitioner.class.getName());
// kafka生产者
KafkaProducer<String, Company> kafkaProducer = new KafkaProducer<String, Company>(properties);
Company company = Company.builder().name("俏江南").address("全国").build();
ProducerRecord<String, Company> producerRecord = new ProducerRecord<String,Company>("test",company);
kafkaProducer.send(producerRecord).get();
// 关闭资源
kafkaProducer.close();
}
}

5. 拦截器
Producer 拦截器 (interceptor) 是个相当新的功能,它和 consumer 端 interceptor 是在 Kafka 0.10 版本被引入的,主要用于实现 clients 端的定制化控制逻辑。
生产者拦截器可以用在消息发送前做一些准备工作,使用场景:
1、按照某个规则过滤掉不符合要求的消息
2、修改消息的内容
3、统计类需求
自定义拦截器:
public class CustomProducerInterceptor implements ProducerInterceptor<String, String> {
private volatile long sendSuccess = 0;
private volatile long sendFailure = 0;
@Override
public ProducerRecord onSend(ProducerRecord record) {
String modifiedValue = "prefix1-" + record.value();
return new ProducerRecord<>(
record.topic(),
record.partition(),
record.timestamp(),
record.key(),
modifiedValue,
record.headers()
);
}
@Override
public void onAcknowledgement(RecordMetadata metadata, Exception exception) {
if (exception == null) {
sendSuccess++;
} else {
sendFailure++;
}
}
@Override
public void close() {
double successRatio = (double) sendSuccess / (sendFailure + sendSuccess);
System.out.println("[INFO] 发送成功率=" + String.format("%f", successRatio * 100) + "%");
}
@Override
public void configure(Map<String, ?> configs) {
}
}
使用自定义拦截器:
public class CustomProducer01 {
public static void main(String[] args) throws ExecutionException, InterruptedException {
// kafka生产者属性配置
Properties properties = new Properties();
properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,"192.168.38.22:9092");
properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,StringSerializer.class.getName());
// 使用自定义分区器
properties.put(ProducerConfig.PARTITIONER_CLASS_CONFIG,DefinePartitioner.class.getName());
// 使用自定义拦截器
properties.put(ProducerConfig.INTERCEPTOR_CLASSES_CONFIG,CustomProducerInterceptor.class.getName());
// kafka生产者
KafkaProducer<String, String> kafkaProducer = new KafkaProducer<String, String>(properties);
ProducerRecord<String, String> producerRecord = new ProducerRecord<String,String>("test","hello,kafka");
kafkaProducer.send(producerRecord).get();
// 关闭资源
kafkaProducer.close();
}
}


6. 发送原理剖析
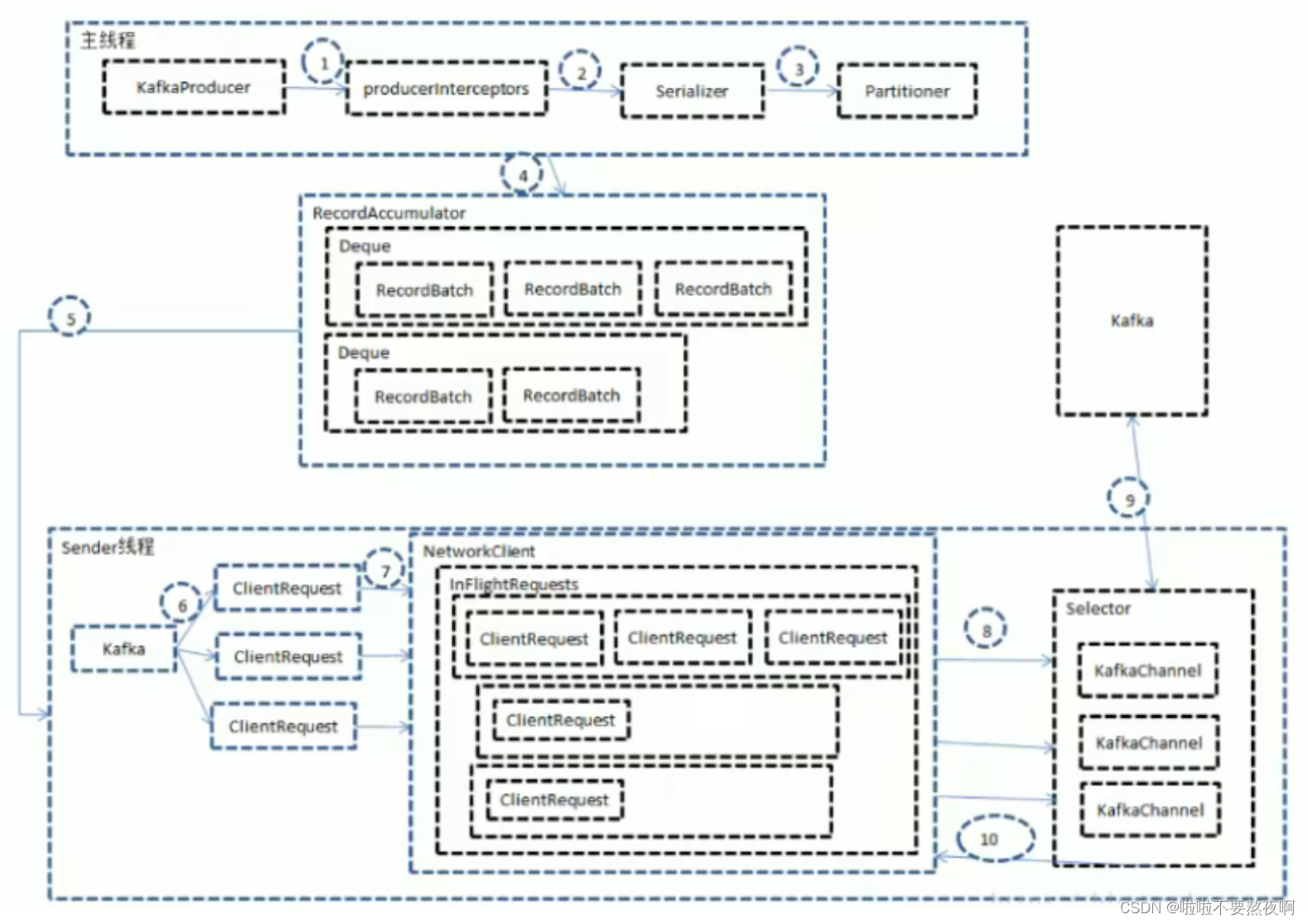
消息发送的过程中,涉及到两个线程协同工作,主线程首先将业务数据封装成 ProducerRecord 对象,之后调用 send() 方法将消息放入 RecordAccumulator 消息收集器,也可以理解为主线程与 Sender 线程直接的缓冲区)中暂存,Sender 线程负责将消息信息构成请求,并最终执行网络I/O的线程,它从 RecordAccumulator 中取出消息并批量发送出去,需要注意的是,KafkaProducer 是线程安全的,多个线程间可以共享使用同一个 KafkaProducer 对象。
7. Kafka生产者参数配置
acks:
这个参数用来指定分区中必须有多少个副本收到这条消息,之后生产者才会认为这条消息时写入成功的。acks是生产者客户端中非常重要的一个参数,它涉及到消息的可靠性和吞吐量之间的权衡。
- ack=0, 生产者在成功写入消息之前不会等待任何来自服务器的相应。如果出现问题生产者是感知不到的,消息就丢失了。不过因为生产者不需要等待服务器响应,所以它可以以网络能够支持的最大速度发送消息,从而达到很高的吞吐量。
- ack=1,默认值为1,只要集群的首领节点收到消息,生产这就会收到一个来自服务器的成功响应。如果消息无法达到首领节点(比如首领节点崩溃,新的首领还没有被选举出来),生产者会收到一个错误响应,为了避免数据丢失,生产者会重发消息。但是,这样还有可能会导致数据丢失,如果收到写成功通知,此时首领节点还没来的及同步数据到follower节点,首领节点崩溃,就会导致数据丢失。
- ack=-1, 只有当所有参与复制的节点都收到消息时,生产这会收到一个来自服务器的成功响应,这种模式是最安全的,它可以保证不止一个服务器收到消息。
注意:acks参数配置的是一个字符串类型,而不是整数类型,如果配置为整数类型会抛出异常
retries:
生产者从服务器收到的错误有可能是临时性的错误(比如分区找不到首领)。在这种情况下,如果达到了 retires 设置的次数,生产者会放弃重试并返回错误。默认情况下,生产者会在每次重试之间等待100ms,可以通过 retry.backoff.ms 参数来修改这个时间间隔。
batch.size:
当有多个消息要被发送到同一个分区时,生产者会把它们放在同一个批次里。该参数指定了一个批次可以使用的内存大小,按照字节数计算,而不是消息个数。当批次被填满,批次里的所有消息会被发送出去。不过生产者并不一定都会等到批次被填满才发送,半满的批次,甚至只包含一个消息的批次也可能被发送。所以就算把 batch.size 设置的很大,也不会造成延迟,只会占用更多的内存而已,如果设置的太小,生产者会因为频繁发送消息而增加一些额外的开销。
max.request.size:
该参数用于控制生产者发送的请求大小,它可以指定能发送的单个消息的最大值,也可以指单个请求里所有消息的总大小。 broker 对可接收的消息最大值也有自己的限制( message.max.size ),所以两边的配置最好匹配,避免生产者发送的消息被 broker 拒绝




![[附源码]SSM计算机毕业设计社区医院管理系统JAVA](https://img-blog.csdnimg.cn/79122deac32a44b48043143dffc7b612.png)