文章目录
- 前置知识
- 数据库的出现
- Redis
- memcache与redis的区别
前置知识
首先需要知道的一个常识就是:数据是存放在磁盘里面的。
而磁盘有两个指标:
- 寻址:表示找到对应的数据所需要的时间,ms
- 带宽:表示单位时间可以有多少个字节流入流出,G/M
相对于内存,内存寻址的速度一般为ns级别。
也就是如果数据在内存中,那么找到它的速度比在磁盘中快了十万倍。
而内存的带宽,以DDR3 1600的速度为12.8G/s,如果构成的是双通道,那么就是25.6G/s。所以内存的带宽是非常大的。
还有一个就是I/O buffer:他考虑的是一个成本问题,我们知道磁盘是有磁道和扇区的,而一个扇区有512Byte,目前大部分电脑的磁盘大小512G,那么就会有特别多的扇区(大约是10^6个),而如果扇区特别多,想要找到一个数据所需要的索引就得跟着变大,因为如果操作系统的查找文件的索引还没有扇区多,那么就会出现找不到某些索引的数据,因此操作系统的索引所占的字节数也要跟着变大。那么就会造成一部分的空间被浪费在索引上。
因此为了解决这个问题,操作系统在查找文件的时候都是以4k为一个标准的,因此无论我们读多大的数据,都是以4k大小去读取的。这样子所需要的索引大小就少了。
这也就是为什么我们再写程序的时候如果设定一个缓冲区大小不是1k的倍数就是4k的倍数。
数据库的出现
上面已经知道操作系统读取数据的时候都是以4k为基础大小去读取的。
而我们的数据一般都存放在文件中,如果我们要读取一个非常大的文件,那么打开这个文件其实就会需要非常多的时间,因为此时磁盘的速度就已经成为了不可逾越的瓶颈了。
而为了解决这种问题,数据库就出现了。
数据库中有一个东西叫做data page(数据页),它的大小是4k,和我们操作系统缓冲区大小一样。
而数据库中是可以有很多的data page的,因此数据库中存储数据只要把数据放在不同的data page中,那么刚刚好每次OS读取的大小都是4k,那么就能很快的就读取到数据了。
而读取文件就不行,因为读取文件,一个文件可能就几十几百M,那么OS就得一次性都把这些数据读出来之后才能展示给你,因此这就是为什么如果你有一个非常大的文本文件,你要打开它会导致系统卡顿一段时间。
但是此时这些数据只是散布在了这些data page中,如果你想要查询对应的数据,还是需要把这些所有的数据都先读取到内存中,也就是把这些data page一页一页的读取到内存中,那么其实和读取文本文件一样,都是全量IO,都是要全部读取完毕,那么就没有速度优势了不是吗?
所以,数据库中有一个很特殊的东西就派上用场了-----索引
索引本身也是数据,他们类似于data page中数据的身份证一样。
我们在创建关系型数据库的时候,要求必须给出schema,也就是必须给出表的每一个列以及每一个列的约束,类型。那么当你设计完毕一张表之后,其中每一个列的字节宽度就已经确定了。
这样做的好处是,即使我们向数据库表插入数据的时候有些字段没有给他数据,那么他也会用默认数据去占位,这么做的好处就在于,下次进行数据修改等操作的时候,不需要去移动磁盘中的空间,而是直接把那个占位的数据给他覆盖掉,这样子就减少了移动空间的开销。
这也就是为什么数据库中存储数据的时候倾向于行级存储。
而我们的内存中,其实存放了一个指向了所有所有的B+树,这个B+树的树干存放在我们的内存中,当我们的SQL语句要进行查询的时候,如果SQL语句中的where条件中能命中某一个索引,那么此时B+树去查找的时候就会去查找我们之前所说的身份证(索引),然后根据这个索引我们就能找到对应的数据了。
前面说过索引本身也是数据,而内存又不够大,因此我们只会把B+树存放在内存中,而不会把索引也放入内存中。
而常见的面试题就是,对于一个非常大的数据库,其速度是否变慢,为什么?
答:
在有索引的情况下,增删改操作变慢,因为这些操作对数据进行改变之后,索引也是需要跟着改变的,而修改索引是需要时间开销的。
而对于查询,则不一定,分为两种情况:
-
如果是一个或者少量的查询,那么查询在命中索引之后将数据读入到内存中依旧很快。
-
在高并发情况或者SQL语句十分复杂的情况下,由于在同一时间到达了许多的SQL语句,那么就会导致不止一个data page需要写入到内存中,并且如果这些语句查询的都是不同的data page,那么就会导致每一个data page都需要挨个写入到内存中,因此就会导致后面的data page需要等待前面的data page,此时影响速度的就是磁盘的带宽了。这就会导致后来的SQL语句就需要进行等待。
也就是答题的时候不仅仅是寻址速度的问题,还有带宽大小的问题。
而对于数据越来越大的数据库,除了分库分表操作,也就只有一种方式了,就是将尽可能多的数据放入到内存中,但是这个价格非常昂贵。
因此出现了一个内存与磁盘的中间人,那就是缓存,将少量的数据放入到缓存中,缓存的速度非常的快,尽可能的接近了内存,因为他们的材质是一样的。
所以提到了缓存,那么就引入了今天的主角,Redis。
Redis
Redis在数据库世界中的含金量
memcache与redis的区别
Redis 是一个开源(BSD许可)的,内存中的数据结构存储系统,它可以用作数据库、缓存和消息中间件。
它支持多种类型的数据结构,如 字符串(strings), 散列(hashes), 列表(lists), 集合(sets), 有序集合(sorted sets) 与范围查询, bitmaps, hyperloglogs 和 地理空间(geospatial) 索引半径查询。
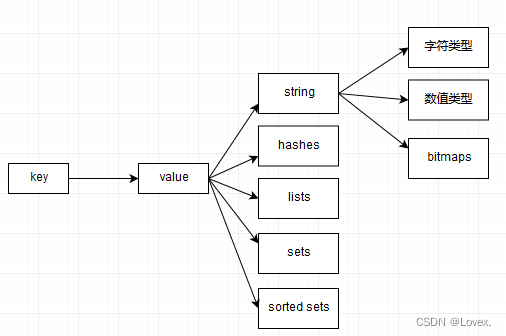
Redis 内置了 复制(replication),LUA脚本(Lua scripting), LRU驱动事件(LRU eviction),事务(transactions) 和不同级别的 磁盘持久化(persistence), 并通过 Redis哨兵(Sentinel)和自动 分区(Cluster)提供高可用性(high availability)。
在redis之前已经有一个技术,这个技术叫做memcache,它也是键值对,key-value的,那么redis是kv的,然后memcach是kv的,那么redis的出来之后,反而要取代memcach生存的地位。那么为什么它会取代memcach的?
如果稍微一查资料就会知道,memcache当中它的value没有类型的概念,但是redis value具有类型的概念了,这是两个的一个最本质的区别。
redis说他有value,有类型,然后我们开始没有类型,然后当时我大脑条件反射第一个东西是啥?json(因为你的所有数据都能用json表示出来),为什么要条件反射json那个东西,因为肯定开始没有redis。那么如果假设世界上只有这种键值对,然后value没有类型,那么我们使用这个技术的时候可不可以存一些复杂的东西?那么这时候你的条件反射是json对不对?json它可以表示很复杂的的数据结构。首先如果你条件反射想起这个知识,那么你会得出一个间接结论,也就是说你value有没有类型?好像是无所谓的,因为我memcache只要有键值对了,我的value里是不是也可以放一个json,然后来代表有数组,这边你有list,我这边是不是也可以用json表示一个list?你这边有hashes这种键值对的,我这边是不是也可以放?
当这个理论你明白之后,也就是说其实我可以不用redis,我用memcache的它的value也可以存很复杂的东西,但是注意了,你要再逆推一件事情,那么他们的成本,value的类型的意义是什么?
如果注意听下面一个很重要的一句话描述,你就知道为什么你要学redis。
如果我的客户端想通过一个缓存系统,而且是kv的缓存器系统当中取回value当中的某一个元素,也就是memcach当中value里面存了一个数组,然后你用redis中的value当中存了一个list。
那么这时候如果想取回其中的数据,使用memcache的话就是获取它在json里面的某一个元素,而使用redis则是直接取回有类型的这个list中的某一个元素的话。
很明显他们的成本就不一样了。相对memcache来说的话,memcache怎么去做的?你需要返回value所有的数据到 client段。那么memcach这台服务器如果很多人都这么获取的话,网卡I/O就是最大的瓶颈,这是第一个,第二个就是client端要有你实现的代码去解码,解码你的json,把json当中数据解码出来,也就是说有两个复杂度,但是如果换成redis的话,因为它有类型了,类型是什么意思?类型其实并不是太重要的,重要的是redis Server中对每种类型都有自己的方法,也就是说其实他可能给你提供了一个什么?基于index(),让你给出一个索引下标,或者lpop怎么怎么样,也就是你的客户端只需要向对方调一个我取value的某一个元素,或者左边或右边弹出一个元素,那么这个时候其实他就规避了上面的问题,你客户端不需要写很多的,因为他不需要把全量数据取走,你的redis Serve网卡就ok,然后你客户端的代码也比较轻盈。
就比如使用过redistemplate的,都知道其返回值是直接对应了某种具体的类型了,就不再需要我们自己手动编写某种方式去解析从memcache那里面取出来的json了。这也就是为什么Redis渐渐取代了memcache的原因。