numatune是什么
numatune是libvirt的一个参数,可以用在numa架构的host上,以控制子机的内存访问策略。
使用方法如下,参考libvirt文档
<domain> ... <numatune> <memory mode="strict" nodeset="1-4,^3"/> <memnode cellid="0" mode="strict" nodeset="1"/> <memnode cellid="2" mode="preferred" nodeset="2"/> </numatune> ... </domain>
numatune的mode选项有:
- strict:默认的策略,如果值指定的node上无法分配内存,则虚拟机分配内存失败,即无法启动
- interleave:通过轮询方式,在指定的多个node上分配内存
- preferred:优先在指定node上分配内存,如果内存不足,允许在其他node上分配内存
在了解了numatune之后,接下来我们将讨论numatune的影响以及哪些场景需要使用numatune
numatune对性能有多大影响
从libvirt和redhat的文档看,numatune会对虚拟机的性能大概会有10%或者更高的影响,为了评估numatune的影响,我们进行了详细的测试。
redhat文档
Combining vCPU pinning with
numatunecan avoid NUMA misses. The performance impacts of NUMA misses are significant, generally starting at a 10% performance hit or higher. vCPU pinning andnumatuneshould be configured together.
测试环境
虚拟机配置:
cpu:32c
内存:128GB
网络方式:DPDK
虚拟机cpu分为两个node,并且分别绑定在host的两个node上
<cputune> <vcpupin vcpu="0" cpuset="1-22,49-70"/> …… <vcpupin vcpu="26" cpuset="25-46,73-94"/> </cputune>
物理机配置:
cpu:96c
内存:256GB
使用hugetlbfs,以实现子机DPDK
虚拟化方式:kvm(内核版本3.10.0-693)+qemu(2.6.0)
测试用例
CPU性能测试:speccpu2017 unixbench linpack
内存性能测试:stream mlc
测试结论
- speccpu测得fpspeed和fprate分别有12%和25%的提升
- stream测得内存带宽有78%以上的提升
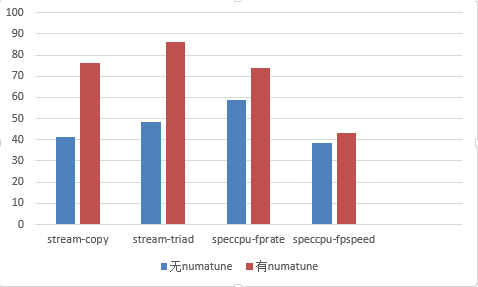
性能对比.png
从测试结果看,numatune对虚拟机的性能有非常大的影响,接下来我们分析一下为什么会有这么大的影响。
分析
对内存带宽有如此大的影响,猜测应该是出现跨numa访问导致,用intel-cmt-cat看下内存的分布情况。
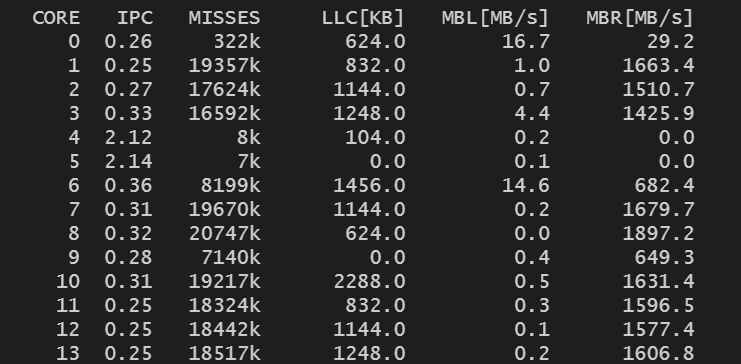
numa miss.png
从上图可以看到,在stream测试过程中,子机cpu出现了访问remote memory,即子机的cpu node0绑定在host的node0上,但是访问的内存却是在host的numa1上。因为内存的跨numa访问,导致cpu性能有大幅下降,就很容易理解了。
为什么会出现跨numa访问
从qemu的源码看,主要完成子机内存绑定的代码位于hostmem.c的host_memory_backend_memory_complete函数。
if (mbind(ptr, sz, backend->policy, maxnode ? backend->host_nodes : NULL, maxnode + 1, flags)) { if (backend->policy != MPOL_DEFAULT || errno != ENOSYS) { error_setg_errno(errp, errno, "cannot bind memory to host NUMA nodes"); return; } }#endif /* Preallocate memory after the NUMA policy has been instantiated. * This is necessary to guarantee memory is allocated with * specified NUMA policy in place. */ if (backend->prealloc) { os_mem_prealloc(memory_region_get_fd(&backend->mr), ptr, sz, smp_cpus, &local_err); if (local_err) { goto out; } }
mbind函数首先设置NUMA内存的访问策略,接着调用prealloc进行内存预分配。
如果没有设置numatune,backend->policy为默认值MPOL_DEFAULT,表示在运行当前分配逻辑cpu node对应的NUMA上分配内存,即如果当前程序运行的node1上,那子机所有的node都会在numa1上分配内存。
The system-wide default policy allocates pages on the node of the CPU that triggers the allocation. For MPOL_DEFAULT, the nodemask and maxnode arguments must be specify the empty set of nodes.
如果设置了numatune,看到qemu的参数会多出来host-nodes=1,policy=preferred,执行backend->policy为MPOL_PREFERRED,会优先从host_nodes上分配内存。

numatune.png
接下来的prealloc()函数就是按照上面的设置的numa策略,进行预分配。
从上文可以看到,在使用hugetlbfs进行prealloc()内存的情况下,numatune可以实现numa透传的目的。
哪些场景需要添加numatune
- 如上文介绍,如果使用hugetlbfs,对虚拟机进行内存预分配的情况需要使用numatune
- 没有使用内存预分配,但使用vfio+透明巨页,同样可能出现内存需要使用numatune vfio的流程中也会去设置内存亲和性,如果没有numatune,同样会出现跨numa访问的问题,后续会有更详细的分析
- 其他情况下,加numatune效果不明显
其他情况下,虽然有mbind操作,但因为没有预分配,最终分配内存时仍然优先在最近的numa分配内存
原文链接:https://cloud.tencent.com/developer/article/1452341
(免费订阅,永久学习)学习地址: Dpdk/网络协议栈/vpp/OvS/DDos/NFV/虚拟化/高性能专家-学习视频教程-腾讯课堂
更多DPDK相关学习资料有需要的可以自行报名学习,免费订阅,永久学习,或点击这里加qun免费
领取,关注我持续更新哦! !