Hadoop目录
- Hadoop3.3.1完全分布式部署(一)
- 1、HDFS
- 一、安装
- 1、基础安装
- 1.1、配置JDK-18
- 1.2、下载并解压hadoop安装包
- 本地运行模式测试 eg:
- 2、完全分布式运行模式
- 1、概要:
- 2、编写集群分发脚本,把1~4步安装的同步到其他服务器:
- 2.1、创建脚本`vim /var/opt/hadoopSoftware/hadoopScript/bin/xsync`,添加执行权限
- 2.2、开始同步JDK、Hdoop、环境变量
- 3、配置ssh免密
- 4、配置xml
- 4.1、集群部署规划如下:
- 4.2、所需配置文件
- 4.3、配置集群
- 1)核心配置文件
- 2)HDFS配置文件
- 3)YARN配置文件
- 4)MapReduce配置文件
- 5、启动整个集群
- 5.1、配置workers
- 5.2、启动集群
- 5.3、页面地址:
- 6、集群测试
- 6.1、上传文件到集群测试
- 6.2、上传大文件测试
- 6.3、hadoop集群测试
- 7、集群崩溃处理
- 1)先停止集群
- 2)删除每个集群上的
- 3)格式化集群
- 4)启动集群
- 8、配置历史服务器
- 8.1、配置mapred-site.xml
- 8.2、同步配置
- 8.3、在hadoop1上启动历史服务器
- 8.4、查看历史服务器是否启动
- 8.5、查看JobHistory
- 9、配置日志聚合功能
- 1)配置yarn-site.xml
- 2)同步配置
- 3)关闭重启NodeManager、ResourceManager、HistoryServer
- 10、集群启停总结:
- 1、整体启动停止(推荐)
- 1)整体启动、停止HDFS
- 2)整体启动体制YARN
- 3)启停historyserver
- 2、各个服务组件分别启/停
- 1)启/停HDFS组件
- 2)启/停YARN组件
- 3)启停historyserver
- 11、编写Hadoop集群常用脚本
- 1)批量启停`hadoop`服务
- 2)查看所有服务器Java进程脚本:jpsall
- 12、常用端口号
- 参考网站
Hadoop3.3.1完全分布式部署(一)
Hadoop 是一种分析和处理大数据的软件平台,是一个用 Java 语言实现的 Apache 的开源软件框架,在大量计算机组成的集群中实现了对海量数据的分布式计算。
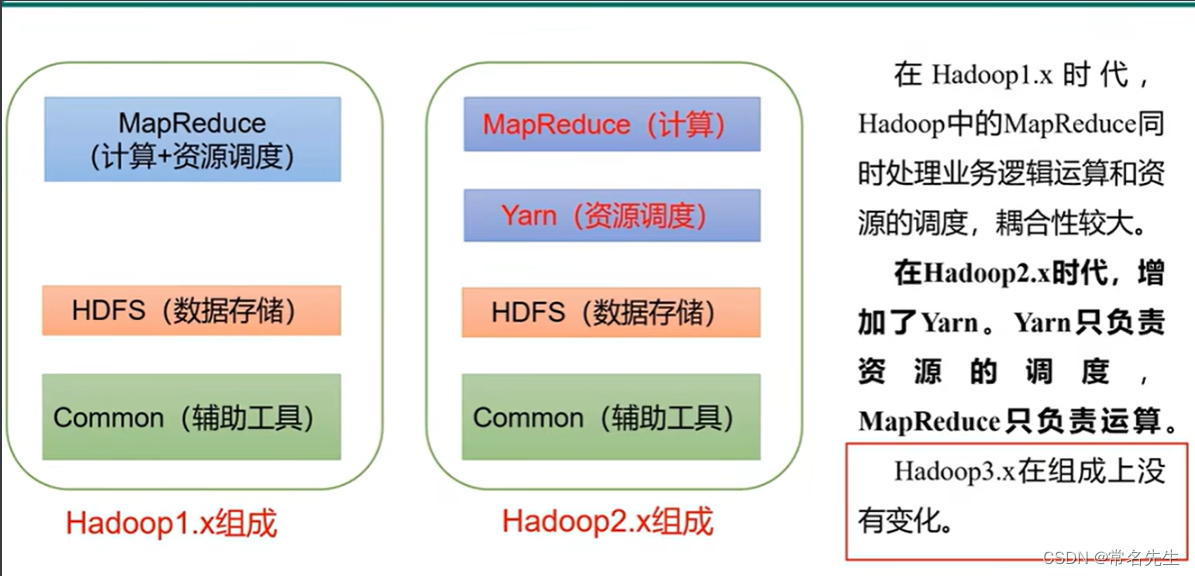
结构框架
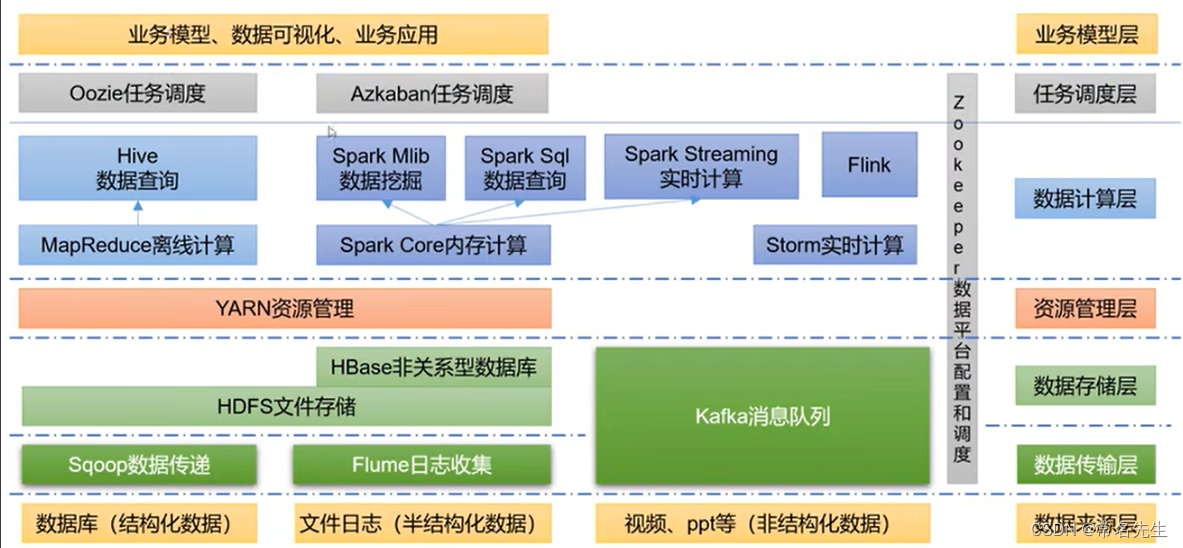
推荐架构
1、HDFS
一个提供高可用的获取应用数据的分布式文件系统。
从字面上来看,SecondaryNameNode 很容易被当作是 NameNode 的备份节点,其实不然。可以通过下图看 HDFS 中 SecondaryNameNode 的作用。
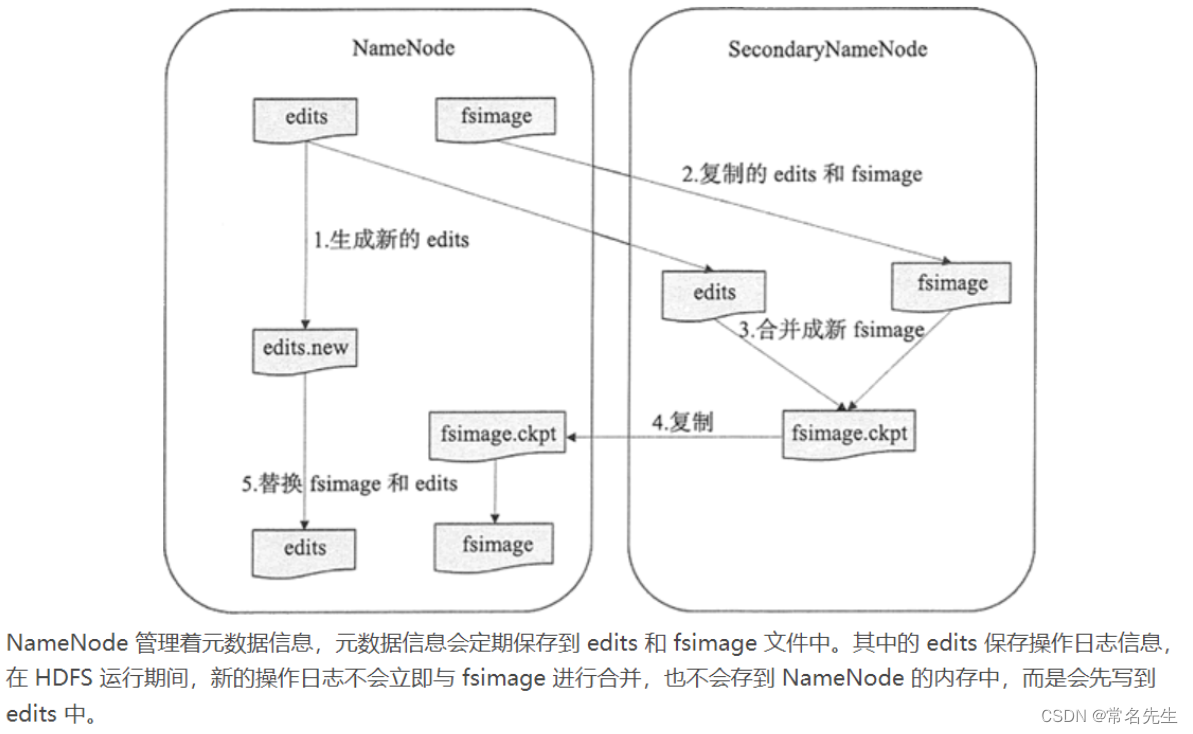
NameNode主要是用来保存HDFS的元数据信息,比如命名空间信息,块信息等。当它运行的时候,这些信息是存在内存中的。但是这些信息也可以持久化到磁盘上。
fsimage - 它是在NameNode启动时对整个文件系统的快照
edit logs - 它是在NameNode启动后,对文件系统的改动序列
Secondary NameNode就是来帮助解决上述问题的,它的职责是合并NameNode的edit logs到fsimage文件中。
- 它定时到NameNode去获取edit logs,并更新到自己的fsimage上。
- 一旦它有了新的fsimage文件,它将其拷贝回NameNode中。
- NameNode在下次重启时会使用这个新的fsimage文件,从而减少重启的时间。
一、安装
1、基础安装
$ yum install -y gcc vim wget
$ sudo yum install ssh
$ sudo yum install pdsh -y
1.1、配置JDK-18
JDK地址
安装参考
# JDK17
#wget https://download.oracle.com/java/17/archive/jdk-17_linux-x64_bin.tar.gz -P /var/opt/hadoopSoftware
# JDK19
#wget https://download.oracle.com/java/19/latest/jdk-19_linux-x64_bin.tar.gz -P /var/opt/hadoopSoftware
# JDK18(本文所选,但是需要ORACLE账号才可以下载)
tar -zxvf /var/opt/hadoopSoftware/jdk-8u361-linux-x64.tar.gz -C /var/opt/hadoopSoftware
配置环境变量,在profile.d下创建hadoop所需的环境变量
cat >> /etc/profile.d/my_env.sh <<Leo
# JAVA_HOME
export JAVA_HOME=/var/opt/software/jdk1.8.0_361
export PATH=\$PATH:\$JAVA_HOME/bin
Leo
使配置生效
source /etc/profile
1.2、下载并解压hadoop安装包
wget https://dlcdn.apache.org/hadoop/common/hadoop-3.3.1/hadoop-3.3.1.tar.gz -P /var/opt/hadoopSoftware
tar -zvxf /var/opt/hadoopSoftware/hadoop-3.3.1.tar.gz -C /var/opt/hadoopSoftware
配置环境变量
cat >> /etc/profile.d/my_env.sh <<Leo
# HADOOP_HOME
export HADOOP_HOME=/var/opt/hadoopSoftware/hadoop-3.3.1
export PATH=\$PATH:\$HADOOP_HOME/bin
export PATH=\$PATH:\$HADOOP_HOME/sbin
# Hadoop run need add
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
Leo
生效
source /etc/profile
- 查看配置的全局环境变量
echo $PATH
hadoop目录介绍
bin:和hdfs yarn mapred
sbin:启动停止相关的命令
share:一些参考
(Hadoop参考)
官网
本地运行模式测试 eg:
mkdir -p /var/opt/hadoopSoftware/hadoop-3.3.1/tinput
cat >> /var/opt/hadoopSoftware/hadoop-3.3.1/tinput/word.txt <<Leo
aa
bb
cc
cc
Leo
测试计算每个单词出现的次数(输入路径:tinput/ 输出路径:./timport)
hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.1.jar wordcount tinput/ ./toutput
toutput]# cat part-r-00000
aa 1
bb 1
cc 2
2、完全分布式运行模式
1、概要:
前提:
1、准备三台server(关闭防火墙、静态ip、主机名)
2、安装JDK
3、安装Hadoop
4、配置环境变量
所需其他配置:
5、配置集群
6、单点启动
7、配置ssh
8、测试集群
2、编写集群分发脚本,把1~4步安装的同步到其他服务器:
mkdir -p /var/opt/hadoopSoftware/hadoopScript/bin
mkdir -p /var/opt/hadoopSoftware/hadoopScript/config
创建需要同步的服务器地址
cat /var/opt/hadoopSoftware/hadoopScript/config/hadoop_hosts
hadoop2
hadoop3
2.1、创建脚本vim /var/opt/hadoopSoftware/hadoopScript/bin/xsync,添加执行权限
#!/bin/bash
# 判断参数个数
if [ $# -lt 1 ]
then
echo Not Enough Argument!
exit;
fi
# 遍历所有的服务器
#for host in hadoop1 hadoop2 hadoop3
for host in `cat /var/opt/hadoopSoftware/hadoopScript/config/hadoop_hosts`
do
echo =======================$host=======================
# 遍历所有目录
for file in $@
do
# 判断文件是否存在
if [ -e $file ]
then
# 获取父目录名,例如有软连接他会cd到真正的数据目录
pdir=$(cd -P $(dirname $file); pwd)
# 获取当前文件名称
fname=$(basename $file)
ssh $host "mkdir -p $pdir"
rsync -av $pdir/$fname $host:$pdir
else
echo $file dose not exists!
fi
done
done
目前xsync只能同步当前目录下的文件,用法xsync bin/,如果同步根目录需要写xsync脚本的绝对路径/var/opt/hadoopSoftware/hadoopScript/bin/xsync
2.2、开始同步JDK、Hdoop、环境变量
2.2.1、开始同步(选用):
# 全局调用使用绝对路径
sudo /var/opt/hadoopSoftware/hadoopScript/bin/xsync /var/opt/hadoopSoftware
sudo /var/opt/hadoopSoftware/hadoopScript/bin/xsync /etc/profile.d/my_env.sh
- 注:每台服务器都需要重新刷新环境变量
source /etc/profile(根据自身需求,后期可以使用ansible-playbook)
2.2.2、配置环境变量同步(本文选用如下方法):
或:如果想要应用这个脚本到全局可以进行如下环境变量设置(根据自身情况进行设置,仅参考):
cat >> /etc/profile.d/my_env.sh <<Leo
# hadoopScript_home
export HSCRIPT_HOME=/var/opt/hadoopSoftware/hadoopScript
export PATH=$PATH:$HSCRIPT_HOME/bin
Leo
同步开始:
xsync /var/opt/hadoopSoftware
xsync /etc/profile.d/my_env.sh
3、配置ssh免密
参考配置
配置hadoop1和hadoop2免密登录hadoop[1,2,3]
4、配置xml
官网参考:[Apache Hadoop 3.3.4 – Hadoop Cluster Setup]
4.1、集群部署规划如下:
| hadoop1 | hadoop2 | hadoop3 | |
|---|---|---|---|
| HDFS | NameNode DataNode | DataNode | SecondaryNameNode DataNode |
| YARN | NodeManager | NodeManager ResourceManager | NodeManager |
注:NameNode、 NodeManager、 SecondaryNameNode最好放在不同的服务器上。
4.2、所需配置文件
1)默认配置文件:
| 默认文件名 | 文件存放路径(cd $HADOOP_HOME) |
|---|---|
| core-default.xml | $HADOOP_HOME/share/doc/hadoop/hadoop-project-dist/hadoop-common/core-default.xml |
| hdfs-default.xml | $HADOOP_HOME/share/doc/hadoop/hadoop-project-dist/hadoop-hdfs/hdfs-default.xml |
| yarn-default.xml | $HADOOP_HOME/share/doc/hadoop/hadoop-yarn/hadoop-yarn-common/yarn-default.xml |
| mapred-default.xml | $HADOOP_HOME/share/doc/hadoop/hadoop-mapreduce-client/hadoop-mapreduce-client-core/mapred-default.xml |
2)自定义配置文件:
文件位置$HADOOP_HOME/etc/hadoop
- core-site.xml
- hdfs-site.xml
- yarn-site.xml
- mapred-site.xml
4.3、配置集群
1)核心配置文件
cat $HADOOP_HOME/etc/hadoop/core-site.xml
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!-- 指定NameNode地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop1:8082</value>
</property>
<!-- 指定hadoop数据存储目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/var/opt/hadoopSoftware/hadoop-3.3.1/data</value>
</property>
<!-- 配置hadoop网页登录使用的静态用户为leojiang -->
<property>
<name>hadoop.http.staticuser.user</name>
<value>root</value>
</property>
</configuration>
2)HDFS配置文件
cat $HADOOP_HOME/etc/hadoop/hdfs-site.xml
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!-- Put site-specific property overrides in this file. -->
<configuration>
<!-- nn web 端访问地址 -->
<property>
<name>dfs.namenode.http-address</name>
<value>hadoop1:9870</value>
</property>
<!-- 2nn web 端访问地址 -->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hadoop3</value>
</property>
<property>
<name>dfs.datanode.http.address</name>
<value>0.0.0.0:9864</value>
<description>
The datanode http server address and port.
</description>
</property>
<!-- 如果为true(默认值),则namenode要求连接datanode的地址必须解析为主机名。如有必要,将执行反向DNS查找。所有从不可解析地址注册datanode的尝试都将被拒绝。建议保留该设置,以防止在DNS中断期间意外注册由excluded文件中hostname列出的datanode。只有在没有基础设施支持反向DNS查找的环境中,才将此设置为false。-->
<!--
<property>
<name>dfs.namenode.datanode.registration.ip-hostname-check</name>
<value>false</value>
</property>
-->
</configuration>
3)YARN配置文件
cat $HADOOP_HOME/etc/hadoop/yarn-site.xml
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!-- 指定MR走shutffle -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 指定ResourceManager的地址 -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop2</value>
</property>
<!-- 环境变量的继承 3.1.3需要配置HADOOP_MAPRED_HOME。3.2以上修复了就不用配置了-->
<property>
<name>yarn.nodemanager.env-whitelist</name>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_HOME,HADOOP_MAPRED_HOME</value>
</property>
</configuration>
4)MapReduce配置文件
cat $HADOOP_HOME/etc/hadoop/mapred-site.xml
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!-- 指定MapReduce程序运行在Yarn上 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
修改完成后同步到所有服务器
xsync $HADOOP_HOME/etc/hadoop
5、启动整个集群
5.1、配置workers
# 注意: 不允许有任何空格、空行
vim $HADOOP_HOME/etc/hadoop/workers
hadoop1
hadoop2
hadoop3
同步文件到所有服务器
xsync $HADOOP_HOME/etc/hadoop/workers
5.2、启动集群
前提添加写权限否则会出现namenode无法启动的状况
chmod -R a+w $HADOOP_HOME
1、初始化文件系统(第一次运行,格式化集群)
hadoop1 $ hdfs namenode -format
可以查看下生成的版本号
cat $HADOOP_HOME/data/dfs/name/current/VERSION
2、启动集群NameNode和DataNode守护进程:
启动:
hadoop1 $ $HADOOP_HOME/sbin/start-dfs.sh
查看启动的服务jps
3、启动ResourceManager (注意要在ResourceManager 的服务器上启动)
hadoop2 $ $HADOOP_HOME/sbin/start-yarn.sh
5.3、页面地址:
# hdfs的NameNode
http://hadoop1:9870
# YARN的ResourceManager
http://hadoop2:8088
6、集群测试
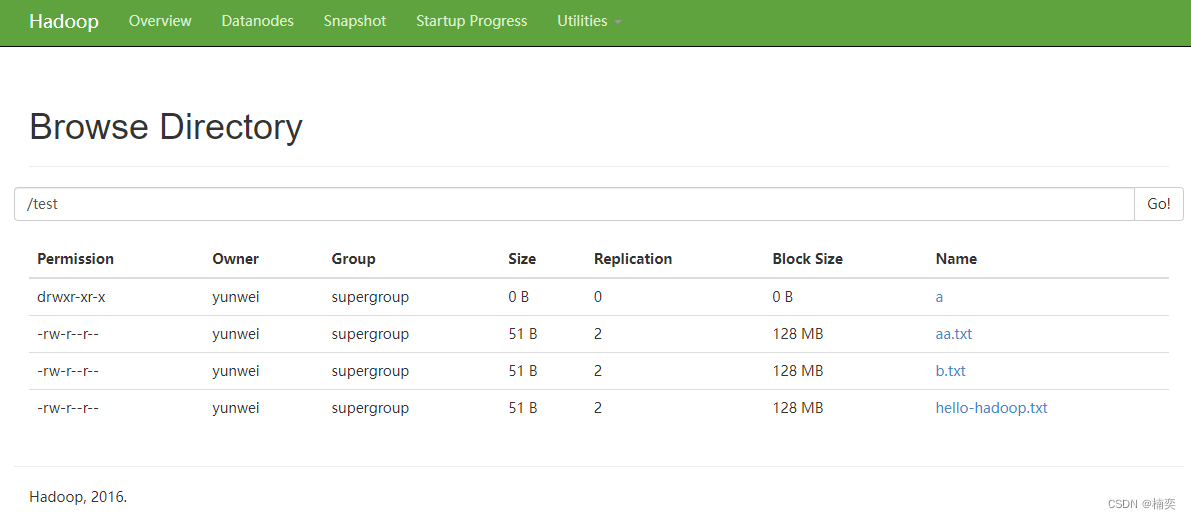
6.1、上传文件到集群测试
# 先在hadoop上创建目录
hadoop fs -mkdir /tinput
# 上传…….txt文件
hadoop fs -put tinput/word.txt /tinput
6.2、上传大文件测试
hadoop fs -put ../jdk-8u361-linux-x64.tar.gz /tinput
数据在datanode下存储
# 查看datanode存储的数据可以使用如下方式还原,每一台服务器存储的都一样
cd data/dfs/data/current/BP-12……/current/finalized/subdir0/subdir0/blk……/……
# word.txt
cat blk_1073741825
# 还原 jdk-8u361-linux-x64.tar.gz
cat blk_1073741826 >>tmp.tar.gz
cat blk_1073741827 >>tmp.tar.gz
# 解压后可以发现这个就是我们之前导入的jdk压缩包
tar -zxvf tmp.tar.gz
6.3、hadoop集群测试
hadoop jar $HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.1.jar wordcount /tinput /toutput
7、集群崩溃处理
1)先停止集群
hadoop2 $ $HADOOP_HOME/sbin/stop-yarn.sh
hadoop1 $ $HADOOP_HOME/sbin/stop-dfs.sh
2)删除每个集群上的
rm -rf $HADOOP_HOME/data/ $HADOOP_HOME/logs/
3)格式化集群
hadoop1 $ hdfs namenode -format
4)启动集群
hadoop1 $ $HADOOP_HOME/sbin/start-dfs.sh
hadoop2 $ $HADOOP_HOME/sbin/start-yarn.sh
8、配置历史服务器
8.1、配置mapred-site.xml
文件中添加如下配置
hadoop1$ vim $HADOOP_HOME/etc/hadoop/mapred-site.xml
<configuration>
<!-- 配置历史服务器端地址 -->
<property>
<name>mapreduce.jobhistory.address</name>
<value>hadoop1:10020</value>
</property>
<!-- 配置历史服务web端地址 -->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>hadoop1:10888</value>
</property>
</configuration>
8.2、同步配置
hadoop1 $ xsync $HADOOP_HOME/etc/hadoop/mapred-site.xml
8.3、在hadoop1上启动历史服务器
如果yarn启动需要关闭重启yarn
hadoop2 $ $HADOOP_HOME/sbin/stop-yarn.sh
hadoop2 $ $HADOOP_HOME/sbin/start-yarn.sh
启动历史服务器
hadoop1 $ mapred --daemon start historyserver
8.4、查看历史服务器是否启动
hadoop1 $ jps
8.5、查看JobHistory
# 先在hadoop上创建目录
hadoop fs -mkdir /tinput
# 上传…….txt文件
hadoop fs -put tinput/word.txt /tinput
hadoop jar $HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.1.jar wordcount /tinput /toutput2
9、配置日志聚合功能
功能:将程序运行日志信息上传到HDFS系统上
- 注:开启日志聚合功能,需要重启NodeManager、ResourceManager、HistoryServer。
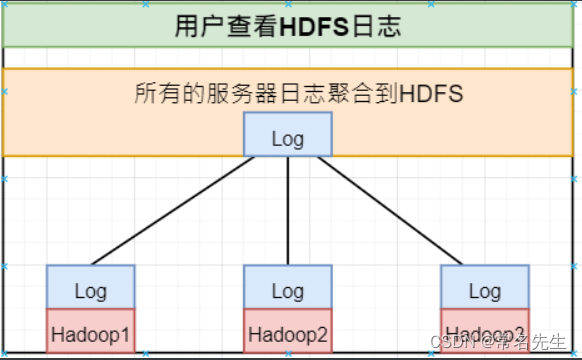
1)配置yarn-site.xml
hadoop1 $ vim $HADOOP_HOME/etc/hadoop/yarn-site.xml
<configuration>
<!-- 开启日志聚合功能 -->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<!-- 设置日志聚合服务器地址 -->
<property>
<name>yarn.log.server.url</name>
<value>http://hadoop1:19888/jobhistory/logs</value>
</property>
<!-- 设置日志保留时间为7天 -->
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>
</configuration>
2)同步配置
hadoop1 $ xsync $HADOOP_HOME/etc/hadoop/yarn-site.xml
3)关闭重启NodeManager、ResourceManager、HistoryServer
关闭
hadoop1 $ mapred --daemon stop historyserver
hadoop2 $ $HADOOP_HOME/sbin/stop-yarn.sh
重启
hadoop2 $ $HADOOP_HOME/sbin/start-yarn.sh
hadoop1 $ mapred --daemon start historyserver
10、集群启停总结:
1、整体启动停止(推荐)
1)整体启动、停止HDFS
hadoop1 $ $HADOOP_HOME/sbin/stop-dfs.sh
hadoop1 $ $HADOOP_HOME/sbin/start-dfs.sh
2)整体启动体制YARN
hadoop2 $ $HADOOP_HOME/sbin/stop-yarn.sh
hadoop2 $ $HADOOP_HOME/sbin/start-yarn.sh
3)启停historyserver
hadoop1 $ $HADOOP_HOME/bin/mapred --daemon stop historyserver
hadoop1 $ mapred --daemon start historyserver
2、各个服务组件分别启/停
1)启/停HDFS组件
[hdfs]$ $HADOOP_HOME/bin/hdfs --daemon stop namenode
[hdfs]$ $HADOOP_HOME/bin/hdfs --daemon stop datanode
[hdfs]$ $HADOOP_HOME/bin/hdfs --daemon start namenode
[hdfs]$ $HADOOP_HOME/bin/hdfs --daemon start datanode
2)启/停YARN组件
[yarn]$ $HADOOP_HOME/bin/yarn --daemon stop resourcemanager
[yarn]$ $HADOOP_HOME/bin/yarn --daemon stop nodemanager
[yarn]$ $HADOOP_HOME/bin/yarn --daemon start resourcemanager
[yarn]$ $HADOOP_HOME/bin/yarn --daemon start nodemanager
3)启停historyserver
[mapred]$ $HADOOP_HOME/bin/mapred --daemon stop historyserver
[mapred]$ $HADOOP_HOME/bin/mapred --daemon start historyserver
11、编写Hadoop集群常用脚本
1)批量启停hadoop服务
hadoop1 $ vim $HSCRIPT_HOME/bin/myhadoop
cat myhadoop
#!/bin/bash
if [ $# -lt 1 ]
then
echo "No Args Input..."
exit ;
fi
case $1 in
"start")
echo "=============== 启动 hadoop 集群 ==============="
echo "--------------- 启动 hdfs ---------------"
ssh hadoop1 "$HADOOP_HOME/sbin/start-dfs.sh"
echo "--------------- 启动 yarn ---------------"
ssh hadoop2 "$HADOOP_HOME/sbin/start-yarn.sh"
echo "--------------- 启动 historyserver ---------------"
ssh hadoop1 "$HADOOP_HOME/bin/mapred --daemon start historyserver"
;;
"stop")
echo "=============== Shutdown hadoop 集群 ==============="
echo "--------------- 停止 historyserver ---------------"
ssh hadoop1 "$HADOOP_HOME/bin/mapred --daemon stop historyserver"
echo "--------------- 停止 yarn ---------------"
ssh hadoop2 "$HADOOP_HOME/sbin/stop-yarn.sh"
echo "--------------- 停止 hdfs ---------------"
ssh hadoop1 "$HADOOP_HOME/sbin/stop-dfs.sh"
;;
*)
echo "Input Args Error.."
;;
esac
使用:
# 赋权
hadoop1 $ chmod +x $HSCRIPT_HOME/bin/myhadoop
# 启动
hadoop1 $ myhadoop start
# 停止
hadoop1 $ myhadoop stop
2)查看所有服务器Java进程脚本:jpsall
hadoop1 $ vim $HSCRIPT_HOME/bin/jpsall
创建所需查看服务器的host地址
cat /var/opt/hadoopSoftware/hadoopScript/config/all_hadoop_hosts
hadoop1
hadoop2
hadoop3
cat jpsall
#!/bin/bash
for host in `cat /var/opt/hadoopSoftware/hadoopScript/config/all_hadoop_hosts`
do
echo ======== $host ========
ssh $host jps
echo -e "\n"
done
运行:
# 赋权
hadoop1 $ chmod +x $HSCRIPT_HOME/bin/jpsall
# 执行检查
hadoop1 $ jpsall
12、常用端口号
| 端口名称 | Hadoop3.x |
|---|---|
| NameNode 内部通信端口 | 8020、9000、9820 |
| NameNode HTTP UI | 9870 |
| MapReduce 查看执行任务端口 | 8088 |
| 历史服务器通信端口 | 19888 |
参考网站
Hadoop官网:http://hadoop.apache.org/
Hadoop下载:https://www.apache.org/dyn/closer.cgi/hadoop/common/
Hadoop历史版本下载:http://archive.apache.org/dist/hadoop/core/
Hadoop文档:http://hadoop.apache.org/docs/
Hive官网:http://hive.apache.org/
Hive下载:http://mirror.bit.edu.cn/apache/hive/
Hive历史版本下载:http://archive.apache.org/dist/hive/
Hive文档:https://cwiki.apache.org/confluence/display/Hive
HBase官网:http://hbase.apache.org/
HBase下载:http://mirrors.sonic.net/apache/hbase/
HBase历史版本下载:http://archive.apache.org/dist/hbase/
HBase文档:http://hbase.apache.org/book.html
HBase中文文档:http://abloz.com/hbase/book.html
Spark官网:http://spark.apache.org/
Spark下载:http://spark.apache.org/downloads.html
Spark文档:http://spark.apache.org/docs/latest/
Zookeeper官网:http://zookeeper.apache.org/
Zookeeper下载:http://zookeeper.apache.org/releases.html#download
Flume官网:http://flume.apache.org/
Flume下载:http://flume.apache.org/download.html
Flume文档:http://flume.apache.org/documentation.html
Mahout官网:http://mahout.apache.org/
Mahout下载:http://mahout.apache.org/general/downloads.html
Tez官网:http://tez.apache.org/
cdh5版本:
下载地址:http://archive.cloudera.com/cdh5/cdh/5/
文档地址:http://archive.cloudera.com/cdh5/cdh/5/