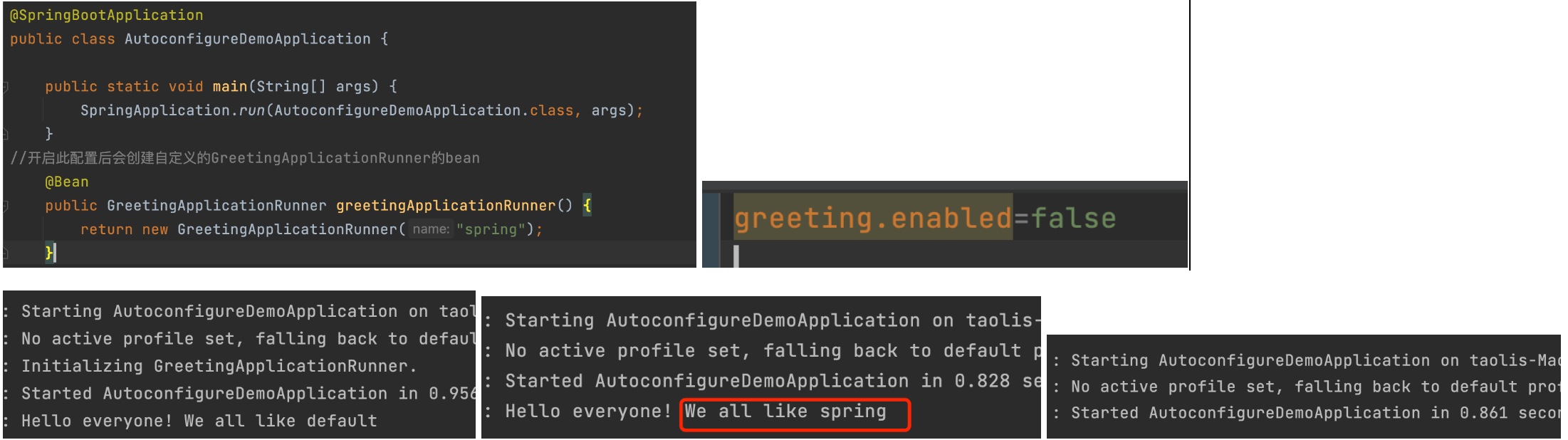
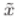贝叶斯公式
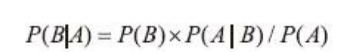
在A 条件成立下,B的概率等于B的概率*在B条件成立下,A的概率/A的概率,推导
假设一个学校中男生占总数的60%,女生占总数的40%。并且男生总是穿长裤,女生则一半穿长裤、一半穿裙子。
1.正向概率。随机选取一个学生,他(她)穿长裤和穿裙子的概率是多大?这就简单了,题目中已经
告诉大家男生和女生对于穿着的概率。
2.逆向概率。迎面走来一个穿长裤的学生,你只看得见他(她)穿的是否是长裤,而无法确定他
(她)的性别,你能够推断出他(她)是女生的概率有多大?
性别 | 长裤 | 裙子 |
男60% | 100% | 0% |
女40% | 50% | 50% |
假设总学生为U,穿长裤的男生的个数为:

=U*60%*100%
穿长裤的女生个数为:

=U*40%*50%
第2问的问题是:穿长裤的女生的概率,首先计算穿长裤的总人数
穿长裤的女生的概率:

合并得:
=

分母表示男生中穿长裤的人数和女生中穿长裤的人数的总和,就是P(Pants)
假设穿长裤用A表示,女生用B表示:



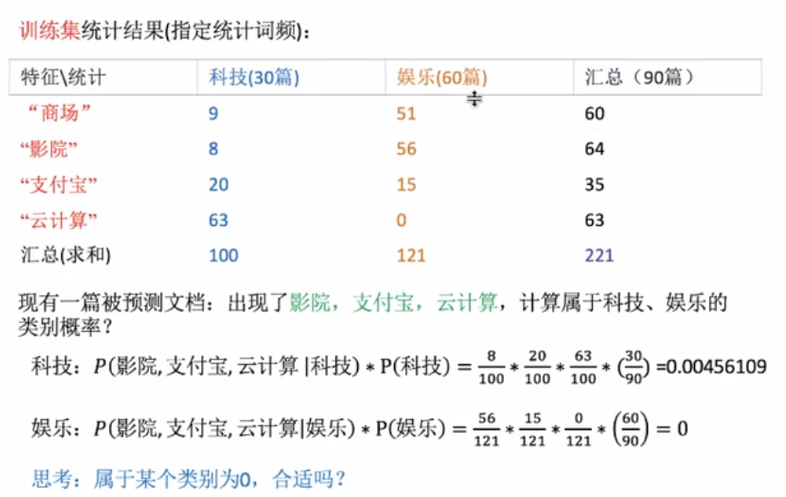



伯努利朴素贝叶斯API
sklearn.naive_bayes.BernoulliNB
高斯朴素贝叶斯API
sklearn.naive_bayes.GuassianNB
多项式朴素贝叶斯API
sklearn.naive_bayes.MultinomialNB

实例
1、处理鸢尾花数据,为连续性数据,应使用高斯朴素贝叶斯
from sklearn.naive_bayes import MultinomialNB,BernoulliNB,GaussianNB
import pandas as pd
from sklearn.model_selection import train_test_split
#读取数据
path = r'D:\python\2023\机器学习\分类data\iris.csv'
df = pd.read_csv(path)
df.columns = ['type1','type2','type3','type4','target']
#df = load_iris()
#print(df)
#取出目标值及特征值
y = df['target']
x = df.drop('target',axis=1)
print(x)
#将数据进行分为训练集及测试集
x_train,x_test,y_train,y_test = train_test_split(x,y,train_size=0.25)
#特征工程
#数据建模算法
bys = GaussianNB()
bys.fit(x_train,y_train)
y_predict = bys.predict(x_test)
print('预测结果:',y_predict)
print('高斯朴素贝叶斯的正确率为:',bys.score(x_test,y_test))
若用多项式朴素贝叶斯
from sklearn.naive_bayes import MultinomialNB,BernoulliNB,GaussianNB
import pandas as pd
from sklearn.model_selection import train_test_split
#读取数据
path = r'D:\python\2023\机器学习\分类data\iris.csv'
df = pd.read_csv(path)
df.columns = ['type1','type2','type3','type4','target']
#df = load_iris()
#print(df)
#取出目标值及特征值
y = df['target']
x = df.drop('target',axis=1)
print(x)
#将数据进行分为训练集及测试集
x_train,x_test,y_train,y_test = train_test_split(x,y,train_size=0.25)
#特征工程
#数据建模算法
bys = MultinomialNB()#默认alpha=1.0
bys.fit(x_train,y_train)
y_predict = bys.predict(x_test)
print('预测结果:',y_predict)
print('多项式朴素贝叶斯的正确率为:',bys.score(x_test,y_test))
2、多项式朴素贝叶斯处理新闻数据
from sklearn.datasets import fetch_20newsgroups
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.naive_bayes import MultinomialNB
from sklearn.model_selection import train_test_split
news = fetch_20newsgroups(subset='all')
#数据分割
x_train,x_test,y_train,y_test = train_test_split(news.data,news.target,test_size=0.25)
#特征抽取
tf = TfidfVectorizer()
#以训练集当中的词的列表进行每篇文章重要性统计
x_train = tf.fit_transform(x_train)
print(tf.get_feature_names())
x_test = tf.transform(x_test)
#进行多项式朴素贝叶斯预测
mlt = MultinomialNB(alpha=1.0)
print(x_train)
mlt.fit(x_train,y_train)
y_predict = mlt.predict(x_test)
print('预测文章类别是:',y_predict)
print('准确率是:',mlt.score(x_test,y_test))