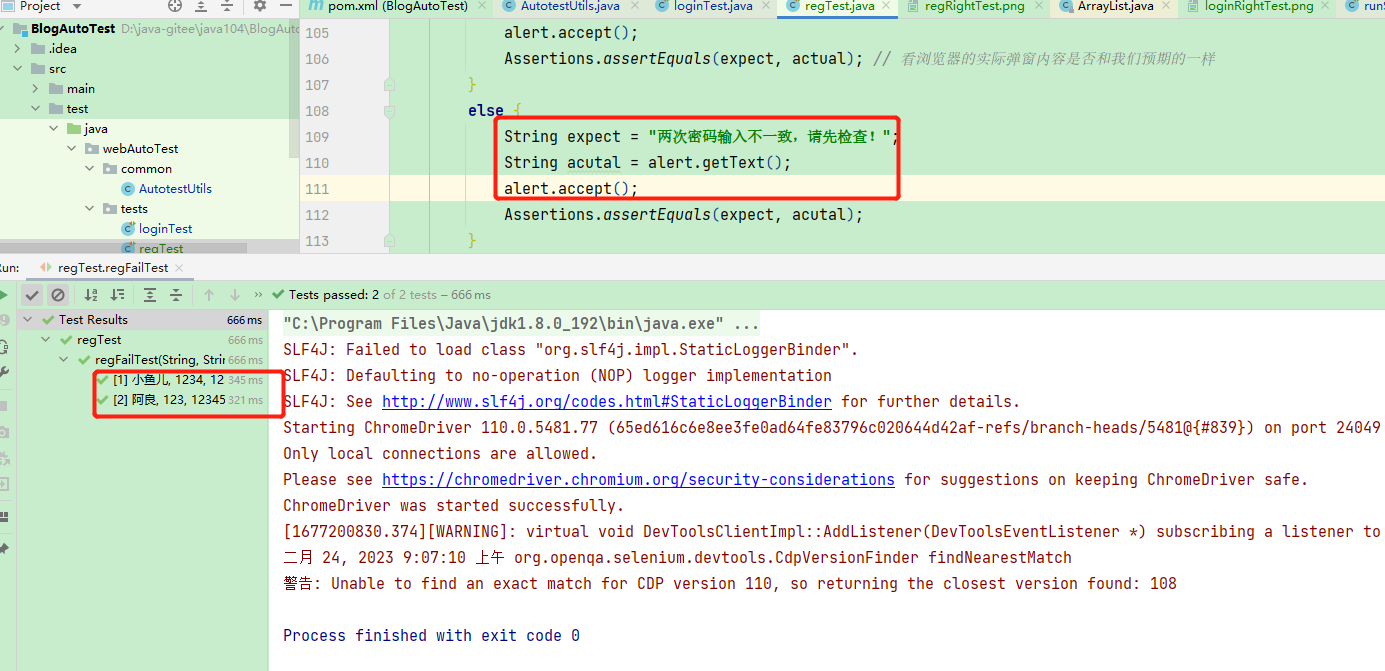
爬虫与反爬虫之间的斗争
爬虫 :对某个网站数据或图片感兴趣,开始抓取网站信息;
网站 :请求次数频繁,并且访问ip固定,user_agent也是python,开始限制访问;
爬虫 :通过设置user_agent,并添加代理ip请求;
网站 :压力过大,不符合常规现象,开始设置登陆访问;
爬虫 :注册账号,携带cookie获取数据;
网站 :发现网站单账号访问异常,限制账号权限;
爬虫 :构建cookie池,多个账号联合爬取数据;
网站 :压力还是很大,加大对访问频繁ip的封锁频率
爬虫 :开始模仿手动请求,限制爬取速度
网站 :设置验证码策略
爬虫 :打码平台介入,或者机器学习识别验证码
网站 :发现对HTML数据请求频繁,不请求js和css,开发人员将重要数据通过Ajax方式加载
爬虫 :通过selenium+phantomjs完全模拟浏览器操作
网站 :。。。。。。
认识selenium
--- Selenium是一个用于Web应用程序测试的工具。Selenium测试直接运行在浏览器中,就像真正的用户在操作一样。
-----支持的浏览器包括IE(7, 8, 9, 10, 11),Mozilla Firefox,Safari,Google,Chrome,Opera,Edge等
浏览器驱动
Selenium需要驱动程序与所选浏览器进行交互,下面是几种常见的驱动下载链接:
Chrome: http://chromedriver.storage.googleapis.com/index.html
Edge: https://developer.microsoft.com/en-us/microsoft-edge/tools/webdriver/
Firefox: https://github.com/mozilla/geckodriver/releases
Safari: https://webkit.org/blog/6900/webdriver-support-in-safari-10/
selenium入门
# 导入模块
fromseleniumimportwebdriver
# 使用谷歌浏览器
driver = webdriver.Chrome()
# 使用谷歌打开百度页面
driver.get("https://www.baidu.com")
# 窗口最大化
driver.maximize_window()
# 获取页面源代码
driver.page_source
# 获取所有cookie
driver.get_cookies()页面元素定位
fromseleniumimportwebdriver
fromselenium.webdriver.common.byimportBy
driver = webdriver.Chrome()
driver.get("https://www.baidu.com")
# 1、通过id值定位
driver.find_element(By.ID,"kw")
# 2、通过class值定位
driver.find_element(By.CLASS_NAME,"s_ipt")
# 3、通过name定位
driver.find_element(By.NAME,"wd")
# 4、通过tag_name定位
driver.find_element(By.TAG_NAME,"div")
# 说明:HTML本质就是由不同的tag(标签)组成,而每个tag都是指同一类,所以tag定位效率低,一般不建议使用;
# 5、通过XPATH语法定位
driver.find_element(By.XPATH,"//*[@id="kw"]")
# 6、通过css语法定位
driver.find_element(By.CSS,"#kw")
# 7、通过文本定位--精确定位
driver.find_element(By.LINK_TEXT,"在希望的田野上")
# 8、通过部分文本定位--模糊定位
driver.find_element(By.PARTIAL_LINK_TEXT,"田野上")操作表单元素
# 输入内容
send_keys("python")
# 清除输入框内容
clear()
# 鼠标单击
click() 行为链
在用selenium操作页面时,有时要分为很多步骤,那么这个时候可以用鼠标行为链类ActionChains来完成。
from selenium import webdriver
from selenium.webdriver.common.by importBy
#引入行为链ActionChains类
from selenium.webdriver.common.action_chains import ActionChains
driver = webdriver.Chrome()
driver.get("https://www.baidu.com")
#定位搜索框
inputtag = driver.find_element(By.ID,"kw")
#百度一下按钮
submittag = driver.find_element(By.ID,"su")
#建立行为链
actions =ActionChains(driver)
#给搜索框发送数据
actions.move_to_element(inputtag)
actions.send_keys_to_element(inputtag,'python')
#选中提交按钮并提交
actions.move_to_element(submittag)
actions.click(submittag)
#统一执行
actions.perform()动作链
ActionChains方法列表
click(on_element=None) ——单击鼠标左键
click_and_hold(on_element=None) ——点击鼠标左键,不松开
context_click(on_element=None) ——点击鼠标右键
double_click(on_element=None) ——双击鼠标左键
drag_and_drop(source, target) ——拖拽到某个元素然后松开
key_down(value, element=None) ——按下某个键盘上的键
key_up(value, element=None) ——松开某个键
move_to_element(to_element) ——鼠标移动到某个元素
perform() ——执行链中的所有动作
release(on_element=None) ——在某个元素位置松开鼠标左键
send_keys(*keys_to_send) ——发送某个键到当前焦点的元素
send_keys_to_element(element, *keys_to_send) ——发送某个键到指定元素
鼠标移动
示例网站:http://sahitest.com/demo/mouseover.htm
# -*- coding:utf-8 -*-
fromseleniumimportwebdriver
fromselenium.webdriver.common.action_chainsimportActionChains
fromselenium.webdriver.common.byimportBy
importtime
driver = webdriver.Chrome()
driver.implicitly_wait(10)
driver.maximize_window()
driver.get('http://sahitest.com/demo/mouseover.htm')
# 鼠标移动到此元素,在下面的input框中会显示“Mouse moved”
write = driver.find_element(By.XPATH,'//input[@value="Write on hover"]')
# 鼠标移动到此元素,会清空下面input框中的内容
blank = driver.find_element(By.XPATH,'//input[@value="Blank on hover"]')
result = driver.find_element(By.NAME,'t1')
action = ActionChains(driver)
# 移动到write,显示“Mouse moved”
time.sleep(3)
# 移动到write上
action.move_to_element(write).perform()
# 移动到blank上,清空
time.sleep(3)
action.move_to_element(blank).perform()
# 移动到write上
time.sleep(3)
action.move_to_element(write).perform()
driver.quit()
鼠标拖拽
示例网站:http://sahitest.com/demo/dragDropMooTools.htm
fromseleniumimportwebdriver
fromselenium.webdriver.common.action_chainsimportActionChains
fromselenium.webdriver.common.byimportBy
fromtimeimportsleep
driver = webdriver.Chrome()
driver.implicitly_wait(10)
driver.maximize_window()
driver.get('http://sahitest.com/demo/dragDropMooTools.htm')
target = driver.find_element(By.ID,'dragger') # 被拖拽元素
item1 = driver.find_element(By.XPATH,'//div[text()="Item 1"]') # 目标1
item2 = driver.find_element(By.XPATH,'//div[text()="Item 2"]') # 目标2
item3 = driver.find_element(By.XPATH,'//div[text()="Item 3"]') # 目标3
item4 = driver.find_element(By.XPATH,'//div[text()="Item 4"]') # 目标4
action = ActionChains(driver)
# 1.移动dragger到目标1
action.drag_and_drop(target, item1).perform()
sleep(2)
# 2.效果与上句相同,也能起到移动效果
action.click_and_hold(target).release(item2).perform()
sleep(2)
# 3.效果与上两句相同,也能起到移动的效果
action.click_and_hold(target).move_to_element(item3).release().perform()
sleep(2)
action.click_and_hold(target).move_to_element(item4).release().perform()
sleep(2)
driver.quit()点击操作
示例网站:http://sahitest.com/demo/clicks.htm
fromseleniumimportwebdriver
fromselenium.webdriver.common.action_chainsimportActionChains
fromselenium.webdriver.common.byimportBy
fromtimeimportsleep
driver = webdriver.Chrome()
driver.implicitly_wait(10)
driver.maximize_window()
driver.get('http://sahitest.com/demo/clicks.htm')
# 单击按钮
click_left = driver.find_element(By.XPATH,'//input[@value="click me"]')
# 双击按钮
doubleclick_btn = driver.find_element(By.XPATH,'//input[@value="dbl click me"]')
# 右键单击按钮
click_right = driver.find_element(By.XPATH,'//input[@value="right click me"]')
# 链式用法
ActionChains(driver).click(click_left).double_click(doubleclick_btn).context_click(click_right).perform()
sleep(2)
driver.quit()页面等待
--- 当selenium打开一个页面要进行操作,但是浏览器还处于加载状态,所以需要等待加载完毕之后再操作
显式等待
显式等待是您定义的代码,用于等待特定条件发生,然后再继续执行代码。这种情况的极端情况是 time.sleep(),它将条件设置为要等待的确切时间段。提供了一些方便的方法来帮助您编写只等待所需时间的代码。WebDriverWait 与 ExpectedCondition 结合使用是实现此目的的一种方式。
fromseleniumimportwebdriver
fromselenium.webdriver.common.byimportBy
fromselenium.commonimportTimeoutException
fromselenium.webdriver.support.uiimportWebDriverWait
fromselenium.webdriver.supportimportexpected_conditionsasEC
driver = webdriver.Chrome()
driver.get("http://somedomain/url_that_delays_loading")
defsearch():
try:
element = WebDriverWait(driver, 10).until(
EC.presence_of_element_located((By.ID, "myDynamicElement"))
)
exceptTimeoutException:
returnsearch()在上面的代码中,Selenium 将等待最多 10 秒以找到匹配给定条件的元素。如果在那段时间内没有找到任何元素,则抛出 TimeoutException。捕获到异常后写一个递归操作,这样10秒之后就会继续等待10秒,知道元素加载完毕
隐式等待
隐式等待告诉 WebDriver 在尝试查找任何不立即可用的元素(或多个元素)时轮询 DOM 一段时间。默认设置为 0(零)。设置后,将为 WebDriver 对象的生命周期设置隐式等待。
fromseleniumimportwebdriver
driver = webdriver.Firefox()
driver.implicitly_wait(10) # seconds
driver.get("http://somedomain/url_that_delays_loading")
myDynamicElement = driver.find_element_by_id("myDynamicElement")

![[神经网络]基干网络之VGG、ShuffleNet](https://img-blog.csdnimg.cn/016b3d8eeea54eca8f4c50c1a2a8b691.png)