Hive系列
第七章 内部表外部表和分区表分桶表
7.1 内部表和外部表
7.1.1 内部表和外部表的区别
1、创建的时候外部表加上external
2、删除表的时候,内部表会删除元数据信息和真实数据信息,外部表只会删除描述信息
7.1.2 内部表和外部表的应用场景
1、如果数据已经存储在hdfs上,然后使用hive去进行分析,并且还有可能有其他的计算引擎使用到这份数据,那么请你创建外部表。
2、如果一份数据仅仅是hive使用来进行分析,可以创建内部表。
推荐:
1、创建内部表的时候,建议大家用默认的路径
2、创建外部表的时候,指定location的路径。
经验
7.2 分区表
7.2.1 理论
分区表对应一个 HDFS 文件系统上的独立的文件夹,该文件夹下是该分区所有的数据文件。Hive 中的分区就是分数据目录,把一个大的数据集根据业务需要分割成小的数据集。在查询时通过 WHERE 子句中的表达式可以选择查询所需的分区,这样的查询效率会提高很多。
7.2.2 实践
// 创建只有一个分区字段的分区表:
create table student_ptn(id int, name string, sex string, age int, department string) partitioned by (city string comment "partitioned field") row format delimited fields terminated by ",";
表类型 : Table Type: MANAGED_TABLE
load data local inpath "/home/data/student.txt" into table student_ptn; XXXXXXX
hive> load data local inpath "/home/data/student.txt" into table student_ptn;
FAILED: SemanticException [Error 10062]: Need to specify partition columns because the destination table is partitioned
老的版本报上面的错。
但是3.1.2的版本,不支持使用local,走hdfs上面的对应的路径下面去复制对应的数据到hive的默认的city=__HIVE_DEFAULT_PARTITION__ 分区文件夹下面。
// 把数据导入到一个不存在的分区,它会自动创建该分区
load data local inpath "/home/data/student.txt" into table student_ptn partition(city="beijing"); √√√√
// 把数据导入到一个已经存在的分区
alter table student_ptn add partition (city="chongqing");
load data local inpath "/home/data/student.txt" into table student_ptn partition(city="chongqing");
// 创建有多个分区字段的分区表:
create table student_ptn_date(id int, name string, sex string, age int, department string) partitioned by (city string comment "partitioned field", dt string) row format delimited fields terminated by ",";
// 往分区中导入数据:
load data local inpath "/home/data/student.txt" into table student_ptn_date partition(city="beijing"); //报错
load data local inpath "/home/data/student.txt" into table student_ptn_date partition(city="beijing", dt='2012-12-12'); //正确
问题是:city分区和dt分区是并列关系还是父子级别关系?
平级并列关系 0
父子目录关系 1
// 不能在导入数据的时候指定多个分区定义
load data local inpath "/home/data/student.txt" into table student_ptn_date partition(city="beijing", dt='2012-12-14') partition (city="beijing" , dt='2012-12-13'); XXXXXX
// 添加分区
alter table student_ptn_date add partition(city="beijing", dt='2012-12-14') partition (city="beijing" , dt='2012-12-13'); √√√√√√√√
alter table student_ptn_date add partition(city="chongqing", dt='2012-12-14') partition (city="chongqing" , dt='2012-12-13'); √√√√√√√√
// 查询一个分区表有那些分区
show partitions student_ptn;
show partitions student_ptn_date;
show partitions student; //不是分区表的话,查询的时候会给你报错。
7.3 分桶表
7.3.1 理论
1、分区提供一个隔离数据和优化查询的便利方式。但并非所有的数据集都可形成合理的分区。
2、对于一张表或者分区,Hive 可以进一步组织成桶,也就是更为细粒度的数据范围划分。
3、分桶是将数据分解成更容易管理的若干部分的另一个技术。
4、分区针对的是数据的存储路径,分桶针对的是数据文件。
7.3.2 实践
7.3.2.1 load方式导入
1、创建一个bucket文件,并在里面对应的数据
vim bucket.txt
0001 liuyi
0002 chener
0003 zhangsan
0004 lisi
0005 wangwu
0006 zhaoliu
0007 sunqi
0008 zhouba
0009 wujiu
0010 zhengshi
0011 zhangsan2
0012 lisi2
2、创建分桶表
create table stu_bucket(id int, name string)
clustered by(id)
into 3 buckets
row format delimited fields terminated by '\t';
3、看看表结构
hive (mydb)> desc formatted stu_bucket;
4、load方式导入数据
load data local inpath '/home/data/bucket.txt' into table stu_bucket;
注意,不可以从linux本地导入,导入的时候报错说找不到路径,实际上本地是有的。
需要先给上传到hdfs上面,然后从hdfs上面导入,也就是使用下面的语句。不加local
load data inpath '/home/data/bucket.txt' into table stu_bucket;
5、查看分桶的结果
hive (mydb)> select * from stu_bucket;
OK
stu_bucket.id stu_bucket.name
12 lisi2
9 wujiu
6 zhaoliu
3 zhangsan
10 zhengshi
7 sunqi
4 lisi
1 liuyi
11 zhangsan2
8 zhouba
5 wangwu
2 chener
Time taken: 0.1 seconds, Fetched: 12 row(s)
注意分桶规则:
Hive 的分桶采用对分桶字段的值进行哈希,然后除以桶的个数求余的方式决定对应记录存放在哪个桶当中。
6、去HDFS上面查看一下结果如下:
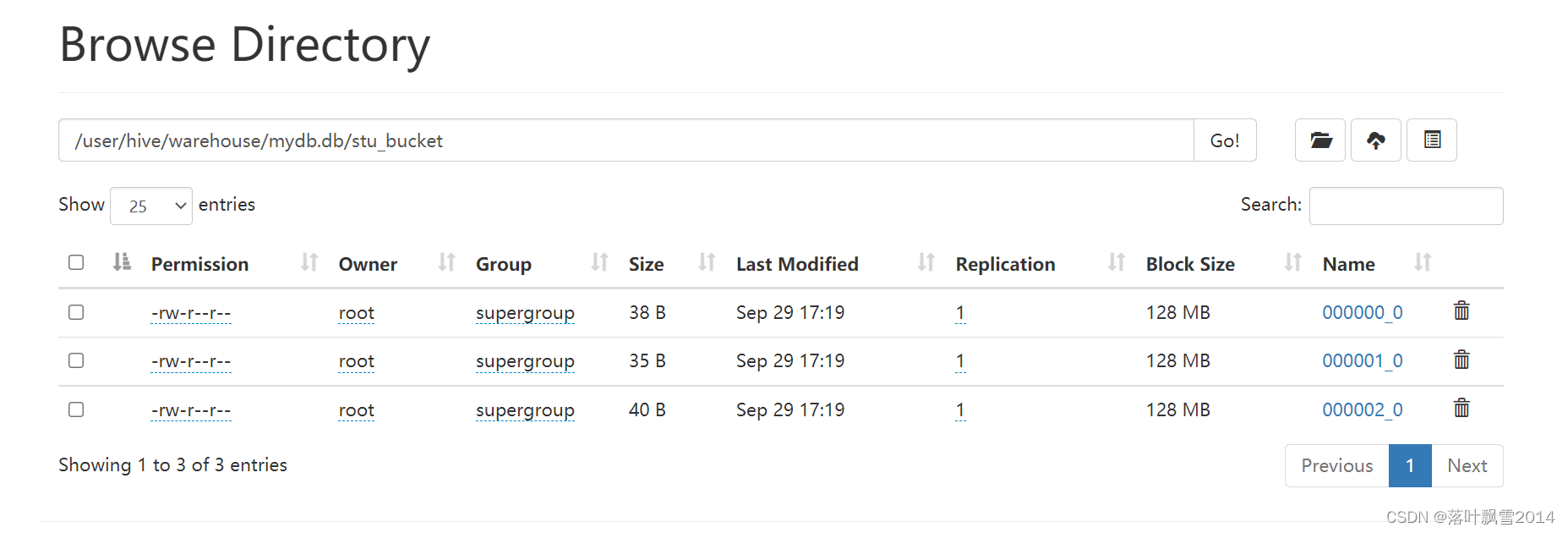
7.3.2.2 insert 方式将数据导入分桶表
1、先创建分桶表
create table stu_bucket2(id int, name string)
clustered by(id)
into 3 buckets
row format delimited fields terminated by '\t';
2、创建一个中间测试表student_test
create table student_test(id int, name string)
row format delimited fields terminated by '\t';
3、往中间测试表里面放数据
load data local inpath '/home/data/bucket.txt' into table student_test;
4、insert 方式将数据导入分桶表
insert into table stu_bucket2 select * from student_test;
5、查看结果
hive (mydb)> select * from stu_bucket2;
OK
stu_bucket2.id stu_bucket2.name
12 lisi2
9 wujiu
6 zhaoliu
3 zhangsan
10 zhengshi
7 sunqi
4 lisi
1 liuyi
11 zhangsan2
8 zhouba
5 wangwu
2 chener
Time taken: 0.12 seconds, Fetched: 12 row(s)
声明:
文章中代码及相关语句为自己根据相应理解编写,文章中出现的相关图片为自己实践中的截图和相关技术对应的图片,若有相关异议,请联系删除。感谢。转载请注明出处,感谢。
By luoyepiaoxue2014
微博地址: http://weibo.com/luoyepiaoxue2014 点击打开链接