第二章 MapReduce核心组件实战
2.1 MapReduce中分区组件
需求:根据单词的长度给单词出现的次数的结果存储到不同文件中,以便于在快速查询
思路:
1、定义Mapper逻辑
2、定义Reducer逻辑
3、自定义分区Partitioner
这个案例主要的逻辑在这个里面
4、主调度入口
2.2 MapReduce中排序组件与序列化
序列化 (Serialization) :结构化对象转化为字节流
反序列化 (Deserialization):把字节流转为结构化对象。
在进程间传递对象或持久化对象的时候,需要序列化对象成字节流, 反之当将接收到或从磁盘读取的字节流转换为对象,要进行反序列化
Java 的序列化是一个重量级序列化框架(Serializable),一个对象被序列化后,会附带很多额 外的信息(各种校验信息,header,继承体系等),不便于在网络中高效传输;所以,hadoop 自己开发了一套序列化机制(Writable),更加精简高效。
Hadoop 中的序列化框架已经对基本类型和 null 提供了序列化的实现了。分别是
| Java中 | Hadoop中 |
|---|---|
| byte | ByteWritable |
| short | ShortWritable |
| int | IntWritable |
| long | LongWritable |
| float | FloatWritable |
| double | DoubleWritable |
| String | Text |
| null | NullWritable |
另外 Writable 有一个子接口是 WritableComparable,WritableComparable 是既可实现序列化,也可以对key进行比较,我们这里可以通过自定义 Key 实现 WritableComparable 来实现我们的排序功能。
下面通过一个案例来看一下具体的排序组件功能
需求:数据格式如下,要求第一列按照字典顺序进行排列,第一列相同的时候, 第二列按照升序进行排列。
a 1
a 3
b 1
a 2
c 2
c 1
思路:
1、将 Mapper 端输出的<key,value>中的 key 和 value 组合成一个新的 key , value值不变,也就是新的key和value为:<(key,value),value>
2、在针对新的 key 排序的时候, 如果 key 相同, 就再对value进行排序
实现:根据思路编写即可
2.3 MapReduce中局部合并组件
1、什么是Combiner
Combiner 是 MapReduce 程序中 Mapper 和 Reducer 之外的一种组件,它的作用是在 maptask 之后给 maptask 的结果进行局部汇总,以减轻 reducetask 的计算负载,减少网络传输
2、如何使用Combiner
Combiner 和 Reducer 一样,编写一个类,然后继承 Reducer,reduce 方法中写具体的 Combiner 逻辑,然后在 job 中设置 Combiner 组件:job.setCombinerClass(MyCombiner.class)
3、 实现:根据思路编写即可
2.4 MapReduce项目实战
1、需求:流量统计经典案例
| 名称 | 字段 | 类型 |
|---|---|---|
| 时间戳 | ts | long |
| 手机号 | phone | String |
| 基站编号 | id | String |
| IP | Ip | String |
| URL | url | String |
| URL类型 | Type | String |
| 上行数据包 | upFlow | int |
| 下行数据包 | downFlow | int |
| 上行流量 | upCountFlow | int |
| 下行流量 | downCountFlow | int |
| 响应 | status | String |
需求一:统计每个手机号的数据包和流量总和
需求二:将需求一中结果按照upFlow流量倒排
需求三:手机号码分区
2.5 MapReduce中分组组件
1、定义
分组:分组是mapreduce中shuffle组件当中reduce端的一个功能组件,主要的作用是决定哪些数据作为一组。
我们可以自定义分组实现不同的key作为同一个组
2、需求
经典案例:求出每一个订单中成交金额最大的一笔交易(分组求TOPN)
示例数据如下:
| 订单编号 | 商品编号 | 金额 |
|---|---|---|
| order_001 | goods_001 | 100 |
| order_001 | goods_002 | 200 |
| order_002 | goods_003 | 300 |
| order_002 | goods_004 | 400 |
| order_002 | goods_005 | 500 |
| order_003 | goods_001 | 100 |
预期结果:
order_001 goods_002 200
order_002 goods_005 500
order_003 goods_001 100
实现:根据思路编写即可
第三章 MapReduce框架底层原理
首先看一张图片
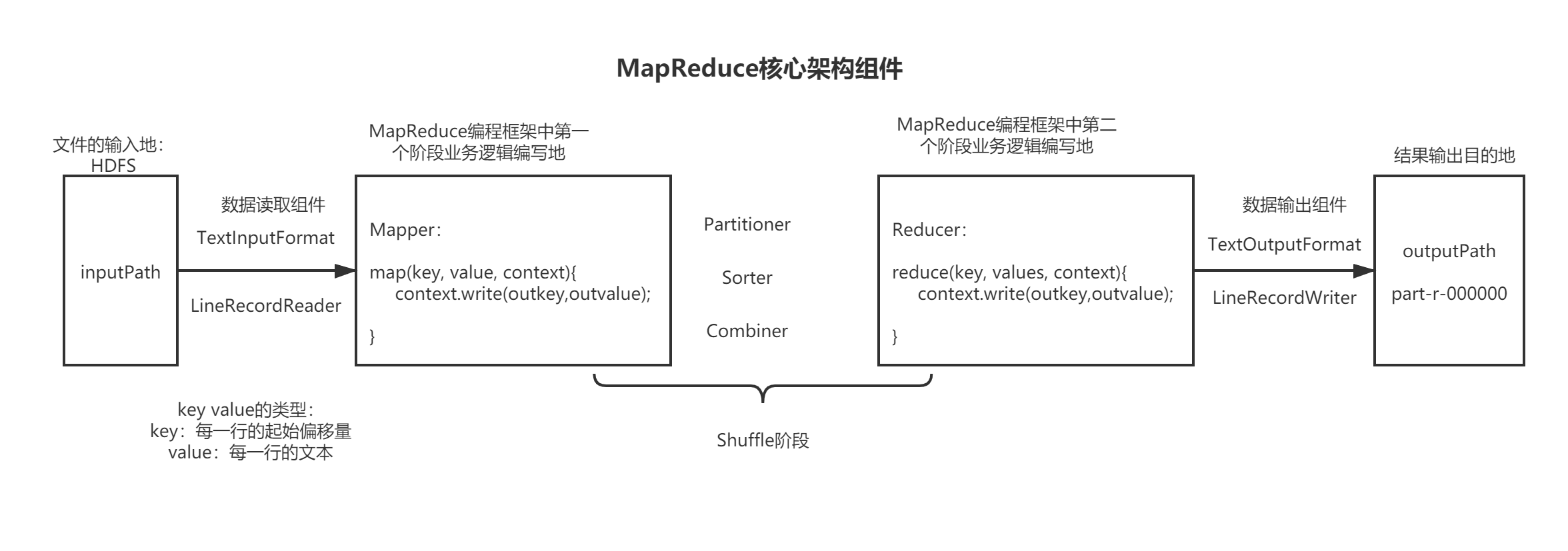
3.1 数据输入
3.1.1 数据切片机制
128m 一个任务,本质上是切片决定任务个数。
数据切片:只是在逻辑上对输入数据进行分片,并不会在磁盘上将其切分。数据切片是MapReduce程序计算输入数据的单位,一个切片会对应启动一个MapTask。
数据块:Block块是HDFS物理上把数据分成一块一块。数据块是HDFS存储单位。
1、切片的机制:
1、按照文件的内容的长度进行切片
2、默认情况下,切片的大小等于Block块的大小
3、切片的时候不是考虑整体上传的全文件,而是针对每个文件进行逻辑上切分。
2、示例
输入文件:
test1.txt 300M
test2.txt 50M
FileInputFormat切分之后:
split1 test1.txt 0-128M
split2 test1.txt 128-256M
split3 test1.txt 256-300M
ss1 test2.txt 0-50M
3、切片的个数的计算
3.1.2 计算切块大小源码
源码包路径:org.apache.hadoop.mapreduce.lib.input.FileInputFormat

说明:
mapreduce.input.fileinputformat.split.minsize=1 默认值为1
mapreduce.input.fileinputformat.split.maxsize= Long.MAXValue 默认值Long.MAXValue
所以可以得出来,默认情况下,切片大小=blocksize。
想修改切块的大小,调整minsize和maxsize的值就可以了。
你想给整个切片的大小调大,那么你需要去给minSize调大成你想调的切片的大小即可。
你想给整个切片的大小调小,那么你需要去给maxSize调小成你想调的切片的大小即可。
3.1.3 生成多少个切片的源码
源码包路径: org.apache.hadoop.mapreduce.lib.input.FileInputFormat
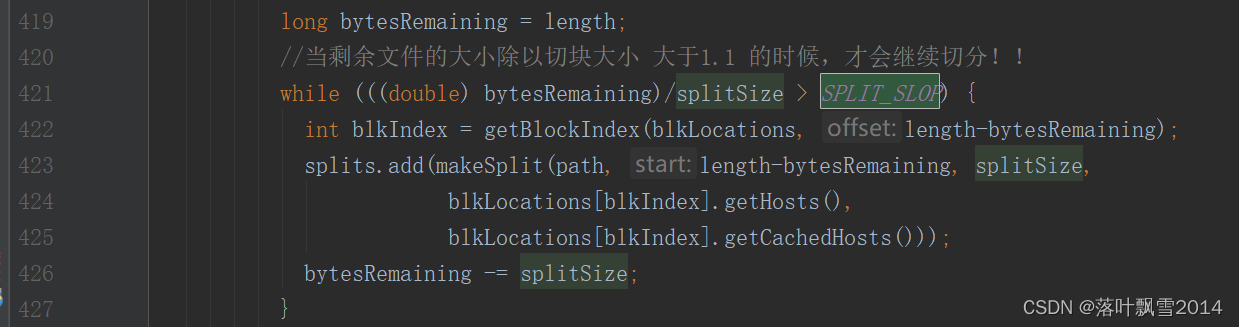
关键性参数:SPLIT_SLOP
//切片的关键性参数
private static final double SPLIT_SLOP = 1.1; // 10% slop
3.2 MapReduce工作流程
内存区域 默认 100M
数据往里面写,有可能写满,刷写到磁盘。什么时候刷写到磁盘上面?
1、全满了,才刷 100%
2、快满了,就刷 80%
2 空的 新数据写
8 满的 溢出
万一20%的空闲区域先写满了,而80%的内存区域还没有刷写完毕,这个时候让写线程阻塞。当慢的区域刷写完毕再唤醒阻塞的线程。
3、双缓冲
3.3 Shuffle机制
图解。
3.4 数据输出
3.4.1 OutputFormat接口实现类
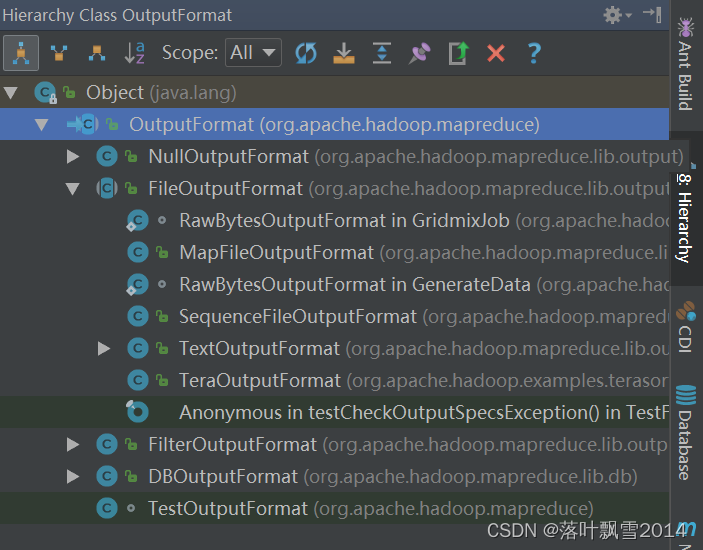
默认的是 TextOutputFormat
3.4.2 自定义OutputFormat输出案例
1、需求
有一份数据,在这份数据中找出 每一行包含 aa 的行放到一个地方去,其余的放到一个地方。
aa
bb
cc
dd
ee
ff
gg
hh
ii
jj
kk
ll
mm
nn
aa
aa
2、案例实现
3、具体的代码
LogMapper.java
package com.aa.mapreduce.output;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
/**
* @author LIAO
* Mapper<KEYIN, VALUEIN, KEYOUT, VALUEOUT>
* KEYIN: 偏移量 的类型
* VALUEIN: 一行文本 的类型
* KEYOUT: 一行文本 的类型
* VALUEOUT: 空 类型
*/
public class LogMapper extends Mapper<LongWritable, Text, Text, NullWritable> {
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
//不用做什么处理,直接往下写即可
context.write(value,NullWritable.get());
}
}
LogReducer.java
package com.aa.mapreduce.output;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
/**
* @author LIAO
* Reducer<KEYIN,VALUEIN,KEYOUT,VALUEOUT>
* KEYIN : Text
* VALUEIN : NullWritable
* KEYOUT : Text
* VALUEOUT : NullWritable
*/
public class LogReducer extends Reducer<Text,NullWritable,Text,NullWritable> {
@Override
protected void reduce(Text key, Iterable<NullWritable> values, Context context) throws IOException, InterruptedException {
//当多行有一样的数据的时候,迭代输出
for (NullWritable value : values) {
context.write(key,value);
}
}
}
LogOutputFormat.java
package com.aa.mapreduce.output;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.RecordWriter;
import org.apache.hadoop.mapreduce.TaskAttemptContext;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
/**
* @author LIAO
* FileOutputFormat<K, V>
* K : 上游传过来的key 的类型 Text
* V : 上游传过来的value 的类型 NullWritable
*/
public class LogOutputFormat extends FileOutputFormat<Text, NullWritable> {
@Override
public RecordWriter<Text, NullWritable> getRecordWriter(TaskAttemptContext job) throws IOException, InterruptedException {
//自定义换一个输出流,然后返回
LogRecordWriter logRecordWriter = new LogRecordWriter(job);
return logRecordWriter;
}
}
LogRecordWriter.java
package com.aa.mapreduce.output;
import org.apache.hadoop.fs.FSDataOutputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IOUtils;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.RecordWriter;
import org.apache.hadoop.mapreduce.TaskAttemptContext;
import java.io.IOException;
/**
* @author LIAO
* 具体的自定义输出
*/
public class LogRecordWriter extends RecordWriter<Text, NullWritable> {
private FSDataOutputStream aaout;
private FSDataOutputStream otherout;
public LogRecordWriter(TaskAttemptContext job) {
//1、实例化一个FileSystem对象
try {
FileSystem fileSystem = FileSystem.get(job.getConfiguration());
//2、创建输入输出流
aaout = fileSystem.create(new Path("D://output//aa.txt"));
otherout = fileSystem.create(new Path("D://output//other.txt"));
} catch (IOException e) {
e.printStackTrace();
}
}
@Override
public void write(Text key, NullWritable value) throws IOException, InterruptedException {
//3、判断一行数据是否含有aa
if (key.toString().contains("aa")){
aaout.writeBytes(key.toString() + "\n");
}else {
otherout.writeBytes(key.toString() + "\n");
}
}
@Override
public void close(TaskAttemptContext context) throws IOException, InterruptedException {
//4、关闭流
IOUtils.closeStream(aaout);
IOUtils.closeStream(otherout);
}
}
JobMain.java
package com.aa.mapreduce.output;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import sun.rmi.runtime.Log;
import java.io.IOException;
/**
* @author LIAO
* 主类: 将Mapper 和 Reducer 两个阶段串联起来,提供程序运行的入口
*/
public class JobMain {
/**
* 程序入口
* 其中用一个Job类对象管理程序运行的很多参数
* 指定用哪个类作为mapper的业务逻辑类,指定哪个类作为Reducer的业务逻辑类
* .......
* 其他各种需要的参数
* @param args
*/
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
//一、初始化一个Job对象
Configuration configuration = new Configuration();
Job job = Job.getInstance(configuration, "output");
//二、设置Job对象的相关的信息,里面包含了8个小步骤
//1、设置输入路径,让程序要找到源文件的位置
//job.setInputFormatClass(TextInputFormat.class);
TextInputFormat.addInputPath(job,new Path("D://input/custom_output.txt"));
//TextInputFormat.addInputPath(job,new Path("hdfs://192.168.22.136:8020/wordcount.txt"));
//2、设置Mapper的类型,并设置k2 v2
job.setMapperClass(LogMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(NullWritable.class);
//3 4 5 6 四个步骤, Shuffle阶段,现在使用默认的就可以。
//7、设置Reducer类型,并设置 k3 v3
job.setReducerClass(LogReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(NullWritable.class);
//8、设置输出路径,让结果数据放到某个地方去
job.setOutputFormatClass(LogOutputFormat.class);
//自定义的LogOutputFormat继承自FileOutputFormat。而FileOutputFormat需要输出一个_SUCCESS文件,所以在这里需要指定一个输出目录。
LogOutputFormat.setOutputPath(job,new Path("D://output//_success"));
//三、等待程序完成(任务的提交)
boolean b = job.waitForCompletion(true);
System.out.println(b);
System.exit(b ? 0 : 1);
}
}
3.5 一个有趣的问题
在MR切片的时候,一行文件被划分到两个不同的切片中,怎么处理呢?同学们可以一起来想想。
在物理上存储的时候,一个块是128M
1、切片是个逻辑信息(仅仅标记位置,并不是物理切割)
2、当MR程序开始执行时,会根据path路径构建一个流,定位到开始位置,然后开始读取数据。
在处理一个InputSplit(封装的切片对象)最后一行时候,若不是换行符,那么会继续读取下一个InputSplit的内容,直到读取到下一个InputSplit的第一个换行符。这样子就可以保证会得到一个完整的行了。
3、再想,当MapReduce在处理下一个InputSplit的时候,怎么判断上一个InputSplit有没有已经处理了这个InputSplit的第一行内容呢?
只需要检查一下前一个InputSplit的最后一个字符是不是换行符,如果是,那么当前Split的第一行还没有被处理;如果不是,表示当前Split的第一行已经被处理,处理的时候跳过这一行就可以了。
再次总结:
总结:其实就是按照换行符来进行切分,若是到了128m的时候,还没有读取到换行符,那么再往下读取下一个split的内容,直到读取到下一个split内容的第一个换行符位置。
再想一下: 到底哪种是特殊情况?
其实一个切片的结尾正好是换行符才是特殊情况。
源码入口:
src/main/java/org/apache/hadoop/mapreduce/lib/input/FileInputFormat.java
第四章 高级应用与源码
4.1 reduce join 应用与实战
4.1.1 需求
帮商品信息表中的对应的数据合并到订单信息表中。
将关联条件作为Map输出的key,将两个表满足Join条件的数据(携带数据来源)信息,发往同一个ReduceTask,在Reduce端进行数据的join。
1、订单信息表
orders表
订单id 商品id 数量
orderid productid amount
00001 0001 2
00002 0002 4
00003 0003 6
00004 0004 8
00005 0005 1
00006 0001 3
00007 0002 5
00008 0003 7
00009 0004 9
2、商品信息表
product表
商品id 商品名字
productid productname
0001 美的冰箱
0002 海尔冰箱
0003 TCL冰箱
0004 容声冰箱
0005 奥克斯冰箱
3、拟求出的结果表
00001 0001 2 美的冰箱
00002 0002 4 海尔冰箱
00003 0003 6 TCL冰箱
00004 0004 8 容声冰箱
00005 0005 1 奥克斯冰箱
00006 0001 3 美的冰箱
00007 0002 5 海尔冰箱
00008 0003 7 TCL冰箱
00009 0004 9 容声冰箱
4.1.2 代码实现
4.2 map join 应用与实战
4.2.1 需求
大小表关联
使用的数据还是reduce join的数据
1、适合的场景
Map Join适合一张表十分小、一张表大的场景,也就是大小表关联的时候。
因为需要给小表缓冲到内存中。
其实就是解决Reduce端过多数据情况。
2、代码逻辑
采用DistributedCache
(1)在Mapper的 setup 阶段,将文件读取到缓存集合中;
(2)在JobMain驱动类中加载缓存。
4.2.2 具体代码

4.3 数据压缩
4.3.1 基本概念
1、概念
压缩是一种通过特定的算法来减小计算机文件大小的机制。这种机制是一种很方便的发明,尤其是对网络用户,因为它可以减小文件的字节总数,使文件能够通过较慢的互联网连接实现更快传输,此外还可以减少文件的磁盘占用空间。
2、优缺点
压缩优点:减少磁盘IO、减少磁盘存储空间。
压缩缺点:增加CPU开销,也就是需要大量的计算能力去解压缩。
3、原则
(1)运算密集型任务(经常需要计算),少用压缩
(2)IO密集型任务(经常需要输入输出,也就是需要传输),多用压缩
4.3.2 hadoop中的压缩编码
1、常见的压缩编码
| 压缩编码 | Hadoop是否自带 | 算法 | 文件扩展名 | 是否支持切片 | 换压缩格式后,原程序是否需要修改 |
|---|---|---|---|---|---|
| DEFLATE | 是,直接使用 | DEFLATE | .deflate | 否 | 和文本处理一样,不需要修改 |
| Gzip | 是,直接使用 | DEFLATE | .gz | 否 | 和文本处理一样,不需要修改 |
| bzip2 | 是,直接使用 | bzip2 | .bz2 | 是 | 和文本处理一样,不需要修改 |
| LZO | 否,需要安装 | LZO | .lzo | 是 | 需要建索引,还需要指定输入格式 |
| Snappy | 是,直接使用 | Snappy | .snappy | 否 | 和文本处理一样,不需要修改 |
2、部分性能对比
| 压缩算法 | 原文件大小 | 压缩之后文件大小 | 压缩速度 | 解压速度 |
|---|---|---|---|---|
| gzip | 8.3GB | 1.8GB | 17.5MB/s | 58MB/s |
| bzip2 | 8.3GB | 1.1GB | 2.4MB/s | 9.5MB/s |
| LZO | 8.3GB | 2.9GB | 49.3MB/s | 74.6MB/s |
注: 数据来源于网络。
再来一个Snappy的。链接: http://google.github.io/snappy/
Snappy is a compression/decompression library. It does not aim for maximum compression, or compatibility with any other compression library; instead, it aims for very high speeds and reasonable compression. For instance, compared to the fastest mode of zlib, Snappy is an order of magnitude faster for most inputs, but the resulting compressed files are anywhere from 20% to 100% bigger. On a single core of a Core i7 processor in 64-bit mode, Snappy compresses at about 250 MB/sec or more and decompresses at about 500 MB/sec or more.
4.3.3 多种压缩方式优缺点及适用场景
压缩方式选择时考虑的几个方面:解、压缩速度、压缩率、压缩文件是否可以支持切片。
1、Gzip压缩
优点:压缩率较高
缺点:不支持Split切片;解、压缩 速度一般
2、Bzip2压缩
优点:压缩率高,支持Split切片
缺点:解、压缩速度慢
3、Lzo压缩
优点:解、压缩速度比较快,支持Split切片
缺点:压缩率一般,想支持切片需要额外创建索引
4、Snappy压缩
优点:解、压缩速度快
缺点:不支持Split切片,压缩率一般
4.3.4 压缩的位置
1、Map前(输入端)
无须显示指定使用的解压缩编码方式。Hadoop自动检查文件扩展名,如果扩展名能够匹配,就会用适当的编解码方式对文件压缩和解压。
选择因素:
(1)数据量小于块大小,考虑压缩和解压缩速度比较快的Snappy/LZO
(2)数据量非常大,考虑支持切片的Bzip2/LZO
2、Map到Reduce中间
在两者中间,肯定要要传输数据,为了减少MapTask和ReduceTask之间的网络IO。
就可以考虑压缩和解压缩快的压缩编码,比如Snappy、LZO。
3、Reduce后(输出端)
这个时候选择要考虑具体需求:
(1)若数据永久保存,考虑压缩率较高的 Bzip2 / Gzip。
(2)若作为下一个MapReduce输入,要考虑数据量大小和是否支持切片。
4.3.5 参数配置
1、Hadoop引入编码/解码器来支持多种压缩/解压缩算法
| 压缩格式 | 对应的编码/解码器 |
|---|---|
| DEFLATE | org.apache.hadoop.io.compress.DefaultCodec |
| gzip | org.apache.hadoop.io.compress.GzipCodec |
| bzip2 | org.apache.hadoop.io.compress.BZip2Codec |
| LZO | com.hadoop.compression.lzo.LzopCodec |
| Snappy | org.apache.hadoop.io.compress.SnappyCodec |
2、Hadoop中启用压缩,可以通过如下参数进行配置
| 参数 | 默认值 | 阶段 | 参考建议 |
|---|---|---|---|
| io.compression.codecs (在core-site.xml中配置) | 无。需要在命令行输入hadoop checknative查看 | 输入压缩 | Hadoop使用文件扩展名判断是否支持某种编解码器 |
| mapreduce.map.output.compress(在mapred-site.xml中配置) | false | Mapper输出 | 这个参数设为true启用压缩 |
| mapreduce.map.output.compress.codec(在mapred-site.xml中配置) | org.apache.hadoop.io.compress.DefaultCodec | Mapper输出 | 企业多使用LZO或Snappy编解码器在此阶段压缩数据 |
| mapreduce.output.fileoutputformat.compress(在mapred-site.xml中配置) | false | Reducer输出 | 这个参数设为true启用压缩 |
| mapreduce.output.fileoutputformat.compress.codec(在mapred-site.xml中配置) | org.apache.hadoop.io.compress.DefaultCodec | Reducer输出 | 使用标准工具或者编解码器,如gzip和bzip2 |
4.3.6 来个案例
1、Mapper输出端压缩设置

//开启Mapper端输出压缩
configuration.setBoolean("mapreduce.map.output.compress", true);
//设置Mapper端输出压缩方式
configuration.setClass("mapreduce.map.output.compress.codec", BZip2Codec.class, CompressionCodec.class);
2、Reducer输出端压缩设置

//设置Reducer端输出压缩开启
TextOutputFormat.setCompressOutput(job, true);
//设置具体的压缩方式
TextOutputFormat.setOutputCompressorClass(job, BZip2Codec.class);
后面补个源码。Job。
声明:
文章中代码及相关语句为自己根据相应理解编写,文章中出现的相关图片为自己实践中的截图和相关技术对应的图片,若有相关异议,请联系删除。感谢。转载请注明出处,感谢。
By luoyepiaoxue2014
微博地址: http://weibo.com/luoyepiaoxue2014 点击打开链接