机器学习笔记之高斯网络——高斯贝叶斯网络
- 引言
- 回顾
- 高斯网络
- 贝叶斯网络:因子分解
- 高斯贝叶斯网络:因子分解
引言
上一节介绍了高斯网络及其条件独立性,本节将介绍高斯贝叶斯网络。
回顾
高斯网络
高斯网络最核心的特点是:随机变量集合中的随机变量均是连续型随机变量,并且均服从高斯分布:
已知某随机变量集合
X
\mathcal X
X中包含
p
p
p个特征,整个高斯网络中所有结点的联合概率分布服从多元高斯分布:
X
=
(
x
1
,
x
2
,
⋯
,
x
p
)
T
P
(
X
)
=
1
(
2
π
)
p
2
∣
Σ
∣
1
2
exp
[
−
1
2
(
x
−
μ
)
T
Σ
−
1
(
x
−
μ
)
]
\begin{aligned} \mathcal X & = (x_1,x_2,\cdots,x_p)^T \\ \mathcal P(\mathcal X) & = \frac{1}{(2\pi)^{\frac{p}{2}}|\Sigma|^{\frac{1}{2}}} \exp \left[-\frac{1}{2}(x - \mu)^T\Sigma^{-1}(x - \mu)\right] \end{aligned}
XP(X)=(x1,x2,⋯,xp)T=(2π)2p∣Σ∣211exp[−21(x−μ)TΣ−1(x−μ)]
其中期望
μ
\mu
μ,协方差矩阵
Σ
\Sigma
Σ表示如下:
μ
=
(
μ
1
μ
2
⋮
μ
p
)
p
×
1
σ
=
(
σ
11
,
σ
12
,
⋯
,
σ
1
p
σ
21
,
σ
22
,
⋯
,
σ
2
p
⋮
σ
p
1
,
σ
p
2
,
⋯
,
σ
p
p
)
p
×
p
\mu = \begin{pmatrix} \mu_1\\ \mu_2 \\ \vdots \\ \mu_p \end{pmatrix}_{p \times 1} \quad \sigma = \begin{pmatrix} \sigma_{11},\sigma_{12},\cdots,\sigma_{1p} \\ \sigma_{21},\sigma_{22},\cdots,\sigma_{2p} \\ \vdots \\ \sigma_{p1},\sigma_{p2},\cdots,\sigma_{pp} \\ \end{pmatrix}_{p \times p}
μ=⎝⎜⎜⎜⎛μ1μ2⋮μp⎠⎟⎟⎟⎞p×1σ=⎝⎜⎜⎜⎛σ11,σ12,⋯,σ1pσ21,σ22,⋯,σ2p⋮σp1,σp2,⋯,σpp⎠⎟⎟⎟⎞p×p
- 随机变量之间的边缘独立性:如果随机变量
x
i
,
x
j
(
i
,
j
∈
{
1
,
2
,
⋯
,
p
}
;
i
≠
j
)
x_i,x_j (i,j \in \{1,2,\cdots,p\};i\neq j)
xi,xj(i,j∈{1,2,⋯,p};i=j)对应协方差矩阵的结果
C
o
v
(
x
i
,
x
j
)
=
σ
i
j
=
0
Cov(x_i,x_j) = \sigma_{ij} = 0
Cov(xi,xj)=σij=0,那么称
x
i
,
x
j
x_i,x_j
xi,xj是不相关的。也称
x
i
,
x
j
x_i,x_j
xi,xj边缘独立或者绝对独立:
σ i j = 0 ⇒ x i ⊥ x j \sigma_{ij} = 0 \Rightarrow x_i \perp x_j σij=0⇒xi⊥xj - 随机变量之间的条件独立性:如果随机变量
x
i
,
x
j
(
i
,
j
∈
{
1
,
2
,
⋯
,
p
}
;
i
≠
j
)
x_i,x_j(i,j \in \{1,2,\cdots,p\};i \neq j)
xi,xj(i,j∈{1,2,⋯,p};i=j)对应精度矩阵(Precision Matrix)结果
λ
i
j
=
0
\lambda_{ij} = 0
λij=0,称给定除去
x
i
,
x
j
x_i,x_j
xi,xj之外其他结点的条件下,
x
i
,
x
j
x_i,x_j
xi,xj相互独立:
其中Λ = [ λ i j ] p × p \Lambda = [\lambda_{ij}]_{p \times p} Λ=[λij]p×p表示精度矩阵,它是协方差矩阵的‘逆矩阵’。
λ i j = 0 ⇒ x i ⊥ x j ∣ x − i − j \lambda_{ij} = 0 \Rightarrow x_i \perp x_j \mid x_{-i-j} λij=0⇒xi⊥xj∣x−i−j
贝叶斯网络:因子分解
基于贝叶斯网络有向图的性质,针对随机变量集合
X
\mathcal X
X的联合概率分布
P
(
X
)
\mathcal P(\mathcal X)
P(X)进行表达。
已知随机变量集合
X
\mathcal X
X包含
p
p
p个维度特征,因而
X
\mathcal X
X的联合概率分布
P
(
X
)
\mathcal P(\mathcal X)
P(X)表示如下:
P
(
X
)
=
P
(
x
1
,
x
2
,
⋯
,
x
p
)
\mathcal P(\mathcal X) = \mathcal P(x_1,x_2,\cdots,x_p)
P(X)=P(x1,x2,⋯,xp)
针对联合概率分布求解,最朴素的方式是条件概率的链式法则(Chain Rule):
P
(
x
1
,
x
2
,
⋯
,
x
p
)
=
P
(
x
1
)
⋅
∏
i
=
2
p
P
(
x
i
∣
x
1
,
⋯
,
x
i
−
1
)
\mathcal P(x_1,x_2,\cdots,x_p) = \mathcal P(x_1) \cdot \prod_{i=2}^p \mathcal P(x_i \mid x_1,\cdots,x_{i-1})
P(x1,x2,⋯,xp)=P(x1)⋅i=2∏pP(xi∣x1,⋯,xi−1)
但如果随机变量集合
X
\mathcal X
X维度过高,这种链式法则计算代价很大。可以将对应的概率图模型视作完全图——任意两个特征之间都需要求解其关联关系。
而贝叶斯网络的条件独立性 可以极大程度地简化运算过程。给定贝叶斯网络的表达方式,可以直接写出各节点的联合概率分布:
P
(
x
1
,
x
2
,
⋯
,
x
p
)
=
∏
i
=
1
p
P
(
x
i
∣
x
p
a
(
i
)
)
\mathcal P(x_1,x_2,\cdots,x_p) = \prod_{i=1}^p \mathcal P(x_i \mid x_{pa(i)})
P(x1,x2,⋯,xp)=i=1∏pP(xi∣xpa(i))
其中
x
p
a
(
i
)
x_{pa(i)}
xpa(i)表示
x
i
x_i
xi结点的父节点组成的集合。
高斯贝叶斯网络:因子分解
已知贝叶斯网络中一共包含
p
p
p个结点,它的联合概率分布(因子分解)表示如下:
P
(
X
)
=
∏
i
=
1
p
P
(
x
i
∣
x
p
a
(
i
)
)
\mathcal P(\mathcal X) = \prod_{i=1}^p \mathcal P(x_i \mid x_{pa(i)})
P(X)=i=1∏pP(xi∣xpa(i))
从 全局模型(Global Model) 角度观察,高斯贝叶斯网络是基于线性高斯模型(局部模型(Local Model))的模型架构。
-
局部模型架构:对于线性高斯模型并不陌生,在卡尔曼滤波中对线性高斯模型又了一定认识。
从宏观角度认识线性高斯模型,即模型中某节点与父结点之间存在线性关系,并且噪声服从高斯分布:
可以理解为:高斯贝叶斯网络中的‘有向边’表示节点与父节点之间的‘具有高斯分布噪声的线性关系’。
这里已知 X , Y \mathcal X,\mathcal Y X,Y是两个随机变量集合, X \mathcal X X的边缘概率分布 P ( X ) \mathcal P(\mathcal X) P(X)和条件概率分布 P ( Y ∣ X ) \mathcal P(\mathcal Y \mid \mathcal X) P(Y∣X)表示如下:
{ P ( X ) ∼ N ( μ X , Σ X ) P ( Y ∣ X ) ∼ N ( A X + B , Σ Y ) \begin{cases} \mathcal P(\mathcal X) \sim \mathcal N(\mu_{\mathcal X},\Sigma_{\mathcal X}) \\ \mathcal P(\mathcal Y \mid \mathcal X) \sim \mathcal N(\mathcal A \mathcal X + \mathcal B,\Sigma_{\mathcal Y}) \end{cases} {P(X)∼N(μX,ΣX)P(Y∣X)∼N(AX+B,ΣY)
局部模型描述结点之间的关联关系 表示如下:
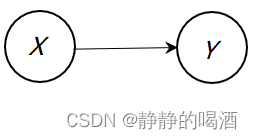
同理,关于结点 Y \mathcal Y Y的边缘概率分布 P ( Y ) \mathcal P(\mathcal Y) P(Y)以及 P ( X ) , P ( Y ∣ X ) \mathcal P(\mathcal X),\mathcal P(\mathcal Y \mid \mathcal X) P(X),P(Y∣X)的推断结果 P ( X ∣ Y ) \mathcal P(\mathcal X \mid \mathcal Y) P(X∣Y)同样服从高斯分布。具体结果表示如下:
推导过程详见:高斯分布——推断任务之边缘概率分布与条件概率分布
P ( Y ) ∼ N ( A μ + B , A Σ X A T + Σ Y ) P ( X ∣ Y ) ∼ N ( Σ { A T Σ Y − 1 ( Y − B ) + A μ } , Σ ) Σ = Σ X − 1 + A T Σ Y − 1 A − 1 \begin{aligned} \mathcal P(\mathcal Y) & \sim \mathcal N(\mathcal A \mu + \mathcal B,\mathcal A\Sigma_{\mathcal X}\mathcal A^T + \Sigma_{\mathcal Y}) \\ \mathcal P(\mathcal X \mid \mathcal Y) & \sim \mathcal N(\Sigma\left\{\mathcal A^T\Sigma_{\mathcal Y}^{-1}(\mathcal Y - \mathcal B) + \mathcal A \mu\right\},\Sigma) \quad \Sigma = \Sigma_{\mathcal X}^{-1} + \mathcal A^T \Sigma_{\mathcal Y}^{-1}\mathcal A^{-1} \end{aligned} P(Y)P(X∣Y)∼N(Aμ+B,AΣXAT+ΣY)∼N(Σ{ATΣY−1(Y−B)+Aμ},Σ)Σ=ΣX−1+ATΣY−1A−1
实际上,卡尔曼滤波(Kalman Filter)自身就是一个特殊的高斯贝叶斯网络。它的概率图模型表示如下:
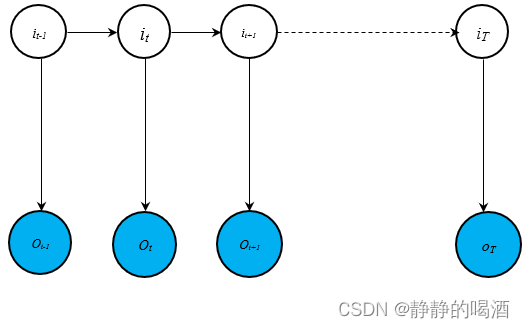
由于齐次马尔可夫假设、观测独立性假设的约束,概率图中无论是观测变量
O
=
{
o
1
,
⋯
,
o
T
}
\mathcal O = \{o_1,\cdots,o_T\}
O={o1,⋯,oT}还是隐变量
I
=
{
i
1
,
⋯
,
i
T
}
\mathcal I = \{i_1,\cdots,i_T\}
I={i1,⋯,iT},它们均仅有一个父节点:
- 基于齐次马尔可夫假设,相邻隐变量
i
t
,
i
t
−
1
i_t,i_{t-1}
it,it−1之间的条件概率表示为:
P ( i t ∣ i t − 1 ) ∼ N ( A ⋅ i t − 1 + B , Q ) \mathcal P(i_t \mid i_{t-1}) \sim \mathcal N(\mathcal A \cdot i_{t-1} + \mathcal B,\mathcal Q) P(it∣it−1)∼N(A⋅it−1+B,Q) - 基于观测独立性假设,隐变量
i
t
i_t
it与对应时刻观测变量
o
t
o_t
ot之间的条件概率表示为:
P ( o t ∣ i t ) ∼ N ( C ⋅ i t + D , R ) \mathcal P(o_t \mid i_t) \sim \mathcal N(\mathcal C\cdot {i_t} + \mathcal D,\mathcal R) P(ot∣it)∼N(C⋅it+D,R)
基于上述假设,对随机变量之间关联关系的表示(Representation)描述为:
之所以将噪声均值设置为0 -> 均值偏差可以归纳到对应偏置项
B
,
D
\mathcal B,\mathcal D
B,D中。
{
i
t
=
A
⋅
i
t
−
1
+
B
+
ϵ
ϵ
∼
N
(
0
,
Q
)
o
t
=
C
⋅
i
t
+
D
+
δ
δ
∼
N
(
0
,
R
)
\begin{cases} i_t = \mathcal A \cdot i_{t-1} + \mathcal B + \epsilon \quad \epsilon \sim \mathcal N(0,\mathcal Q) \\ o_t = \mathcal C \cdot i_t + \mathcal D + \delta \quad \delta \sim \mathcal N(0,\mathcal R) \end{cases}
{it=A⋅it−1+B+ϵϵ∼N(0,Q)ot=C⋅it+D+δδ∼N(0,R)
相比之下,高斯贝叶斯网络并没有假设约束,结点中可能存在多个父节点组成的集合。
给定一个高斯贝叶斯网络的局部图如下:
这里仅讨论
x
i
x_i
xi与其父节点们之间的关系,其余部分略掉了。
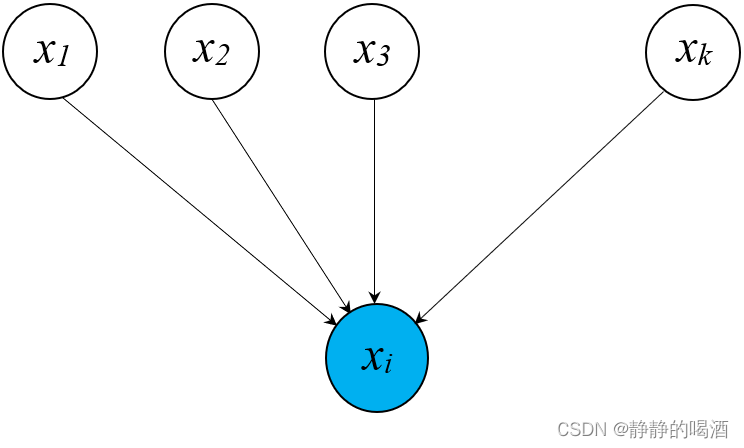
很明显:
x
1
,
x
2
,
⋯
,
x
k
x_1,x_2,\cdots,x_k
x1,x2,⋯,xk均是
x
i
x_i
xi的父节点,将局部模型延伸到一个更大的局部模型。
这里
x
1
,
x
2
,
⋯
,
x
k
x_1,x_2,\cdots,x_k
x1,x2,⋯,xk以及
x
i
x_i
xi均是一维随机变量:
-
假设 x i x_i xi的父节点集合中仅包含一个随机变量( x 1 x_1 x1为例),那么 P ( x i ∣ x p a ( i ) ) \mathcal P(x_{i} \mid x_{pa(i)}) P(xi∣xpa(i))可表示为:
P ( x i ∣ x p a ( i ) ) → P ( x i ∣ x 1 ) ∼ N ( w i 1 ⋅ x 1 , σ i 2 ) \mathcal P(x_{i} \mid x_{pa(i)}) \to \mathcal P(x_i \mid x_1) \sim \mathcal N(w_{i1} \cdot x_1,\sigma_{i}^2) P(xi∣xpa(i))→P(xi∣x1)∼N(wi1⋅x1,σi2)
对应 x i , x 1 x_i,x_1 xi,x1随机变量之间关联关系的表示 为:
x i = μ i + w i 1 ⋅ ( x 1 − μ 1 ) + σ i ⋅ ϵ i ϵ ∼ N ( 0 , 1 ) x_i = \mu_i + w_{i1} \cdot (x_1 - \mu_1) + \sigma_{i}\cdot \epsilon_i \quad \epsilon \sim \mathcal N(0,1) xi=μi+wi1⋅(x1−μ1)+σi⋅ϵiϵ∼N(0,1)
关于上述公式的一些个人理解:多出来的μ i , μ 1 \mu_i,\mu_1 μi,μ1是哪来的:为了简化运算,通常对‘随机变量的分布’进行平移’,就是去中心化。因而上述式子可以表示为:
x i − μ i = w i 1 ⋅ ( x 1 − μ 1 ) + σ i ⋅ ϵ i x_i - \mu_i = w_{i1} \cdot (x_1 - \mu_1) + \sigma_i \cdot \epsilon_{i} xi−μi=wi1⋅(x1−μ1)+σi⋅ϵi执行线性运算之后,方差必然会发生变化。应变化为w i 1 2 ⋅ σ i 2 w_{i1}^2 \cdot \sigma_i^2 wi12⋅σi2,但是P ( x i ∣ x 1 ) \mathcal P(x_i \mid x_1) P(xi∣x1)并没有变化,依旧是σ i 2 \sigma_i^2 σi2:方差变化是x i x_i xi的边缘概率分布P ( x i ) \mathcal P(x_i) P(xi),而不是P ( x i ∣ x 1 ) \mathcal P(x_i \mid x_1) P(xi∣x1),这也是线性高斯模型的假设方式。偏置项去哪了:最终都需要‘去中心化’,将分布的均值(中心)回归零点,因而被省略掉了,或者也可理解为‘合并到’μ i \mu_i μi中。
欢迎小伙伴们交流讨论。 -
同理,父结点集合中包含多个随机变量,将父结点集合看成向量形式,因而 x p a ( i ) x_{pa(i)} xpa(i)以及对应权重信息 W i \mathcal W_i Wi表示如下:
x p a ( i ) = ( x 1 , x 2 , ⋯ , x k ) k × 1 T W i = ( w i 1 , w i 2 , ⋯ , w i k ) k × 1 T \begin{aligned} x_{pa(i)} = (x_1,x_2,\cdots,x_k)_{k \times 1}^T \\ \mathcal W_i = (w_{i1},w_{i2},\cdots,w_{ik})_{k \times 1}^T \end{aligned} xpa(i)=(x1,x2,⋯,xk)k×1TWi=(wi1,wi2,⋯,wik)k×1T
至此, P ( x i ∣ x p a ( i ) ) \mathcal P(x_i \mid x_{pa(i)}) P(xi∣xpa(i))表示如下:
P ( x i ∣ x p a ( i ) ) = N ( W i T x p a ( i ) , σ i 2 ) = N ( x 1 ⋅ w i 1 + ⋯ + x k ⋅ w i k , σ i 2 ) \begin{aligned} \mathcal P(x_i \mid x_{pa(i)}) & = \mathcal N(\mathcal W_i^T x_{pa(i)},\sigma_i^2) \\ & = \mathcal N(x_1 \cdot w_{i1} + \cdots + x_k \cdot w_{ik},\sigma_i^2) \end{aligned} P(xi∣xpa(i))=N(WiTxpa(i),σi2)=N(x1⋅wi1+⋯+xk⋅wik,σi2)
因而 x i , x p a ( i ) x_i,x_{pa(i)} xi,xpa(i)随机变量之间的关联关系表示为:
x i − μ i = W i T ( x p a ( i ) − μ p a ( i ) ) + σ i ⋅ ϵ i = ( w i 1 , w i 2 , ⋯ , w i k ) 1 × k [ ( x 1 x 2 ⋮ x k ) − ( μ 1 μ 2 ⋮ μ k ) ] k × 1 + σ i ⋅ ϵ i = ∑ j ∈ x p a ( i ) w i j ( x j − μ j ) + σ i ⋅ ϵ i \begin{aligned} x_i - \mu_i & = \mathcal W_i^T (x_{pa(i)} - \mu_{pa(i)}) + \sigma_i \cdot \epsilon_i \\ & = \begin{pmatrix}w_{i1},w_{i2},\cdots,w_{ik}\end{pmatrix}_{1 \times k} \left[\begin{pmatrix}x_1 \\ x_2 \\ \vdots \\ x_k \end{pmatrix} - \begin{pmatrix}\mu_1 \\ \mu_2 \\ \vdots \\ \mu_k \end{pmatrix}\right]_{k \times 1} + \sigma_i \cdot \epsilon_i\\ & = \sum_{j \in x_{pa(i)}} w_{ij}(x_j - \mu_j) + \sigma_i \cdot \epsilon_i \end{aligned} xi−μi=WiT(xpa(i)−μpa(i))+σi⋅ϵi=(wi1,wi2,⋯,wik)1×k⎣⎢⎢⎢⎡⎝⎜⎜⎜⎛x1x2⋮xk⎠⎟⎟⎟⎞−⎝⎜⎜⎜⎛μ1μ2⋮μk⎠⎟⎟⎟⎞⎦⎥⎥⎥⎤k×1+σi⋅ϵi=j∈xpa(i)∑wij(xj−μj)+σi⋅ϵi
下一节将介绍:高斯马尔可夫随机场。
相关参考:
机器学习-高斯网络(2)-高斯贝叶斯网络







![[附源码]java毕业设计英语知识竞赛报名系统](https://img-blog.csdnimg.cn/1162f49c4cb841b5b2824ad2c68d978c.png)
