视频地址:YouTube
Why is Redis so fast? What fundamental design decisions did the developers make more than a decade ago that stood to test of time. Let’s take a look. Redis is a very popular in-memory database. It’s rock solid, easy to use, and fast. These attributes explain why it is one of the most loved databases according to the Stack Overflow’s annual developer survey.
The first reason Redis is fast is because it is an in-memory database. Memory access is several orders of magnitude faster than random disk I/O. Pure memory access provides high read and write throughput and low latency. The trade-off is that the dataset cannot be larger than memory.
Code-wise, in-memory data structures are also much easier to implement than the on-disk counterparts. This keeps the code simple, and it contributes to Redis’ rock solid stability.
Another reason Redis is fast is a bit unintuitive. It is primarily single threaded. Why would a single threaded design lead to high performance? Wouldn’t it be faster if it uses threads to leverage all the CPU cores? Multi-threaded applications require locks or other synchronization mechanisms. They are notoriously hard to reason about. In many applications, the added complexity is bug prone and sacrifices stability, making it difficult to justify the performance gain. In the case of Redis, the single threaded code path is easy to understand. How does a single threaded codebase handle many thousands of incoming requests and outgoing responses at the same time? Won’t the thread get blocked waiting for the completion of each request individually? Now, this is where I/O multiplexing comes into the picture. With I/O multiplexing, the operating system allows a single thread to wait on many socket connections simultaneously. Traditionally, this is done with the select or poll system calls. These system calls are not very performant when there are many thousands of connections. On linux, epoll is a performant variant of I/O multiplexing that supports many many thousands of connections in constant time. A drawback of this single threaded design is that it does not leverage all the CPU cores available in modern hardware. For some workloads, it is not uncommon to have several Redis instances running on a single server to utilize more CPU cores.
We alluded to the third reason why Redis is fast. Since Redis is an in-memory database, it could leverage several efficient low-level data structures without worrying about how to persist them to disk efficiently - linked list, skip list and hash table are some examples.
It is true that there are attempts at implementing new Redis compatible servers to squeeze more performance out of a single server. With Redis ease of use, rock solid stability, and performance, it is in our view that Redis still provides the best performance and stability tradeoff in the market. If you’d like to learn more about system design, check out our books and weekly newsletter. Please subscribe if you learned something new. Thank you so much, and we’ll see you next time.
专业词汇:
1)single-threaded:单线程的
2)in-memory database:内存数据库
3)memory access:内存访问
4)several orders of magnitude:几个数量级(大小的目录)(这里是adv)
5)high read and write throughput and low latency:高读写吞吐量和低延迟
6)code-wise:从代码的角度(wise作为后缀,翻译成从什么角度)
7)synchronization mechanisms:同步机制
8)sacrifices stability:牺牲稳定性
9)bug-prone:有bug倾向的
10)performance gain:性能增益
11)code path:代码路径
12)codebase:代码库
13)incoming requests and outgoing responses:传入的请求和传出的响应
14)I/O multiplexing:I/O多路复用
15)performant:性能好的
16)system calls:系统调用
17)in constant time:线性时间(O(n),也就是东西越多、越废时间)
18)workloads:工作负荷
19)linked list:链表
20)skip list:跳表
21)hash table:哈希表
22)squeeze more performance:榨取更多性能
23)out of …:从(数个)里、由于(原因,动机)、用…(材料)
好次积累:
1)stand the test of time:经受住时间的考验
2)rock soild:稳定的、可靠的
3)the most loved:最受欢迎的
4)trade-off:权衡
5)counterparts:类似that,替换前面的data structure
6)unintuitive:不直观的
7)leverage:利用
8)reason about:推断
9)notoriously hard:臭名昭著的困难
10)many thousands of:数以千计(many加不加都一样)
11)variant:变体
12)allude to:简介提到
13)weekly newsletter:每周的简讯
14)loop:循环
文章批注:
1)“Memory access is several orders of magnitude faster than random disk I/O.”
这里说的是随机I/O,也有顺序I/O,英文叫Sequential I/O。当读取第一个block时,要经历寻道,旋转延迟,传输三个步骤才能读取完这个block的数据。而对于下一个block,如果它在磁盘的某个位置,访问它会同样经历寻道,旋转,延时,传输才能读取完这个block的数据,我们把这种方式的IO叫做随机IO,但是如果这个block的起始扇区刚好在我刚才访问的block的后面,磁头就能立刻遇到,不需等待,直接传输,这种IO就叫顺序IO。
其中顺序I/O全面碾压随机I/O,是因为机械硬盘采用传统的磁头探针结构,随机读写时需要频繁寻道,也就需要磁头和探针频繁的转动,而机械结构的磁头和探针的位置调整是十分费时的,这就严重影响到硬盘的寻址速度,进而影响到随机写入速度。
2)“Pure memory access provides high read and write throughput and low latency.”
吞吐量是指系统在单位时间内处理请求的数量。因为纯内存访问响应的快,所以吞吐量大、延迟小。
为什么内存就快呢?内存直接由CPU控制,也就是CPU内部集成的内存控制器,所以说内存是直接与CPU对接,享受与CPU通信的最优带宽,然而硬盘则是通过主板上的桥接芯片(因为硬盘数据量太大,直接编址数据线成本太高,所以加了中间物)与CPU相连,所以说速度比较慢。
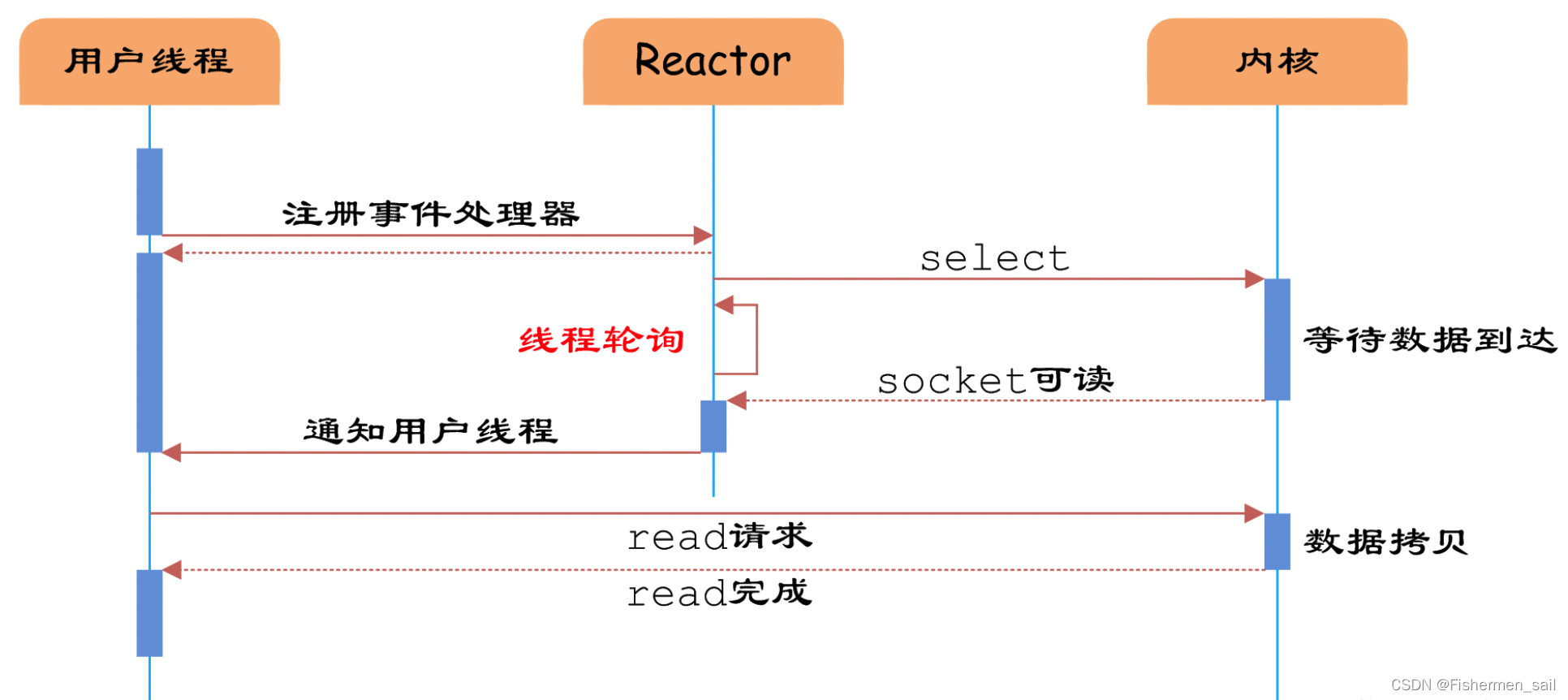
3)“With I/O multiplexing, the operating system allows a single thread to wait on many socket connections simultaneously.”
对比多线程,每有一个新的请求,就会创一个线程去解决,也就是并发的去解决请求,这样带来的问题,就像文中所说,线程之间的同步和加锁控制比较麻烦,增加代码的复杂度,而且一个进程出了问题可能会影响别的线程(因为线程不是进程,它们是共用内存的)。还有销毁线程时需要消耗内存资源以及占用CPU时间,也会带来线程切换的性能开销。
而I/O多路复用,就是说,多个IO的“路”复用一个“进程”。可以理解为,用单线程实现出多线程的效果。它的“多线程”,也只是针对处理网络请求过程采用了“多线程”,而数据的读写命令,仍然是单线程处理的。
具体说一下I/O多路复用,首先你要知道,所有的系统IO都分为两个阶段:等待就绪和操作。例如:读函数分为等待系统可读和真正的读;同理,写函数分为等待可写和真正的写。
传统的方式是当你调用read时,如果没有数据收到,也就是等待阶段,那么线程就会被挂起,直到收到数据(阻塞I/O)或者直接中断这个请求(非阻塞I/O);而使用I/O多路复用,比如有多个客户端发起了read,如果没有数据收到,需要等待,服务端就会对他们监听,然后一个一个进行轮巡,哪个好了,可以进入执行阶段,就让线程开始执行,然后最终返回给客户端。这样做的好处就是用更少的内存等资源来支持更高的并发数,节省资源。
而且因为采用单线程,避免了不必要的上下文切换(虚拟内存、栈、全局变量等用户空间的资源,单线程也会有,但没有多线程多、复杂)和竞争条件,不用考虑加锁释放锁和死锁的问题。
线程池(多线程)和I/O多路复用所以它俩到底谁更好?可以看看下面这篇文章,知乎文章:IO多路复用和线程池哪个效率更高,更有优势?。线程池其实就是升级版的多线程,线程池是在程序运行开始,创建好的n个线程,并且这n个线程挂起等待任务的到来。而多线程是在任务到来得时候进行创建,然后执行任务;线程池中的线程执行完之后不会回收线程,会继续将线程放在等待队列中,多线程程序在每次任务完成之后会回收该线程;由于线程池中线程是创建好的,所以在效率上相对于多线程会高很多;线程池也在高并发的情况下有着较好的性能不容易挂掉,多线程在创建线程数较多的情况下,很容易挂掉。
这篇文章也不错:解释了上面知乎呢篇文章,总之就是个有千秋,而且也能结合使用,让多线程中的每个线程都能管理一部分多路复用,既发挥了多核优势,又避免大量的线程切换。
下面这段话可能会让你有更深的理解:
线程池的诞生, 主要是为了减少进程频繁创建和回收带来的性能损失。但它本质上, 依然是一个CPU执行单元在请求的生命周期内, 只能服务这一个请求,是被一个请求独占的。线程创建是需要成本的,一般一个线程要耗掉1m左右的内存,当线程数达到一个界限时,cpu频繁调度线程进行上下文切换所带来的性能损耗, 将会非常可观,甚至可以让你的服务不可用。
因此,要解决这个问题,有两个路子可走,一,能否做到一个线程同时(交叉)处理多个请求,不被—个请求独占。二,换比线程更细小的执行单元。
而lO多路复用,就是要让一个CPU执行单元同时服务n个请求。这与多进程、多线程、线程池以同步IO的形式处理请求有本质上的区别了。原理上,它是让内核进程去批量管理多个请求的IO事件,在lO事件就绪后通知用户进程/线程处理IO事件,或者提供接口(系统调用,如select)给用户进程/线程去查询就绪的lO事件,避免用户进程/线程在某一个请求上干等,这样一个用户进程/线程就可以交叉处理多个请求了,而不是被一个请求独占。
但lO多路复用不是独立的,往往是跟线程池结合使用的。像redis那样单线程处理请求的软件真的是少数,最近听说redis也开发多线程版本了,每一个线程依然是多路复用的。这几年有个比较火的概念,就是协程,这是语言层面实现的更轻粒度的执行单元,比线程更节省资源,跟用线程替代进程处理服务的一个性质,就是换更小的执行单元。
总结一下:
如果并发量不是特别大,机器资源充足,基于线程池的server处理高并发就足够了,开发简单,容易维护。
如果并发量非常大,公司比较重视机器成本,那可以考虑开发基于IO多路复用的server。缺点就是开发难度高,维护成本高。
文章末尾说IO多路复用难度大,应该指的是多线程+IO多路复用结合的方式。
4)“Traditionally, this is done with the select or poll system calls. These system calls are not very performant when there are many thousands of connections. On linux, epoll is a performant variant of I/O multiplexing that supports many many thousands of connections in constant time.”
比较高级,简单说明:
- select:服务端一直在轮询、监听如果有客户端链接上来就创建一个连接放到数组A中,继续轮询这个数组,如果在轮询的过程中有客户端发生IO事件就去处理;select只能监视1024个连接(一个进程只能创建1024个文件);而且存在线程安全问题。
- poll:在select做了许多修复,比如不限制监测的连接数;但是也有线程安全问题。
- epoll:也是监测IO事件,但是如果发生Io事件,它会告诉你是哪个连接发生了事件,就不用再轮询访问。而且它是线程安全的,但是只有linux平台支持。
总结
-
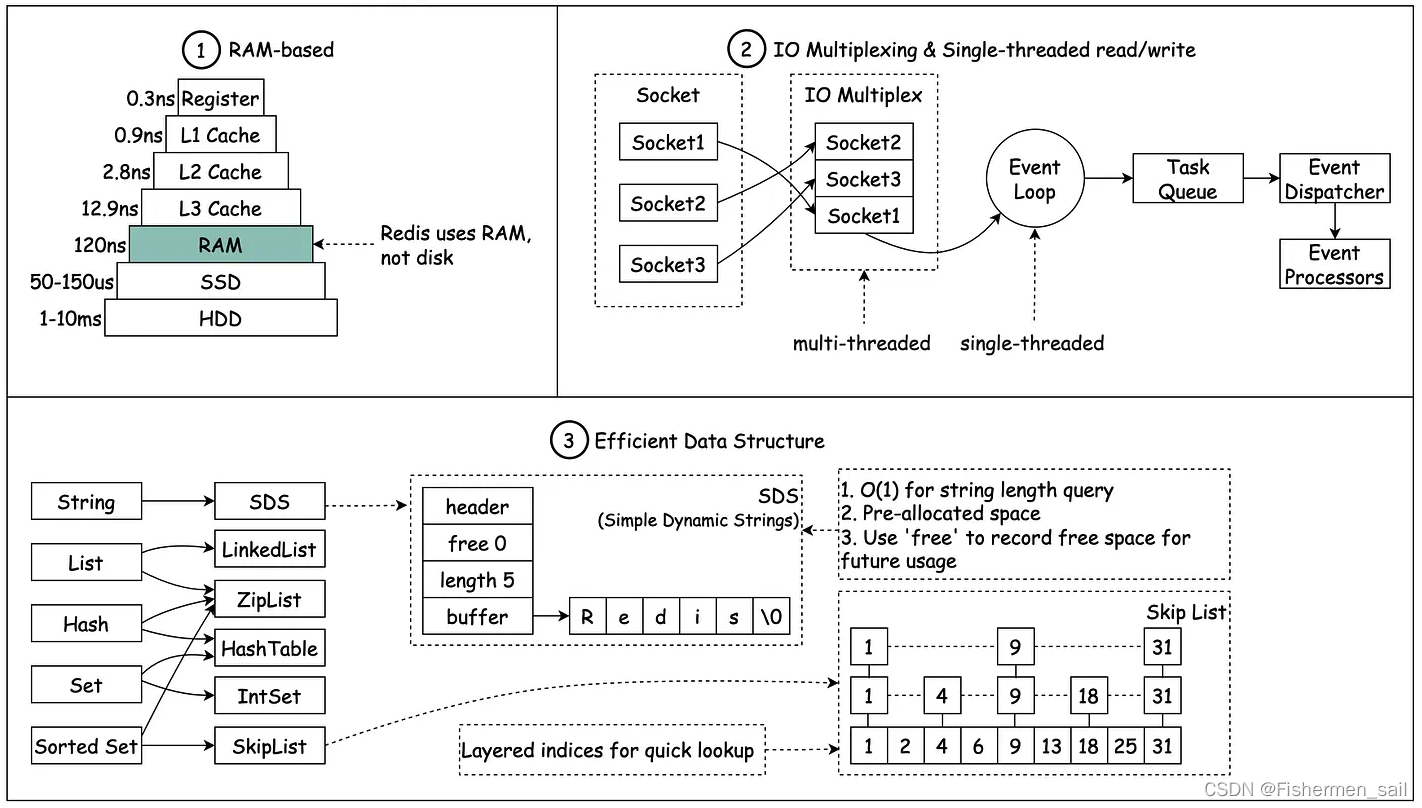
Redis is a RAM-based database. RAM access is at least 1000 times faster than random disk access.
-
Redis leverages IO multiplexing and single-threaded execution loop for execution efficiency.
-
Redis leverages several efficient lower-level data structures.
简单来讲,快的三个原因:
1)Redis是基于内存存储的数据库,比传统的硬盘存储访问速度更快。这是因为基于内存的访问,直接受CPU调控,比起需要桥接芯片的硬盘访问,会有更大的吞吐量和更低的延迟。
2)Redis利用I/O多路复用,实现类多线程的效果。一方面Redis的操作基本都是基于内存的,CPU资源根本就不是Redis的性能瓶颈,没必要多线程。
多线程会带来锁、同步机制等,让代码变得更复杂,使得发生bug的可能性增大、降低稳定性。
使用单线程模型,可维护性更高,开发,调试和维护的成本更低。并且上下文切换带来的开销更小,更节约资源。
并且利用linux中的epoll,在单线程同时去等待许多个scoket请求,可以实现更高的性能。
在多路复用的IO模型中,在处理网络请求时,调用 select (其他函数同理)的过程是阻塞的(看上面那张图)(因为是单线程),也就是说这个过程会阻塞线程,如果并发量很高,此处可能会成为瓶颈。
如果能采用多线程,使得网络处理的请求并发进行,就可以大大的提升性能。多线程除了可以减少由于网络 I/O 等待造成的影响,还可以充分利用 CPU 的多核优势。
所以Redis 6.0中也是使用了多线程,但是只有在网络请求的接收和解析,以及请求后的数据通过网络返回给时,使用了多线程。而数据读写操作还是由单线程来完成的。
这篇讲Redis为什么不用多线程也可以看看。
3)Redis由于利用了内存存储和I/O多路复用,使得代码逻辑更加简单,可以利用简单且高效的数据结构(因为多线程的话,你得使用更复杂的、线程安全的那种数据结构,肯定会降低性能),并且进行了重新设计(看那张图,比如List,是由LinkedList和ZipList结合实现的),从而使得性能快速而稳定。





![[附源码]java毕业设计英语知识竞赛报名系统](https://img-blog.csdnimg.cn/1162f49c4cb841b5b2824ad2c68d978c.png)




![[附源码]java毕业设计影院售票系统](https://img-blog.csdnimg.cn/1c5dc151d3c746f79cd0b02b84c8f64d.png)