目录
- 🌈前言
- 🌷1、缓冲区
- 🍡1.1、缓冲区的理解
- 🍢1.2、缓冲区在哪里?
- 🍣1.3、缓冲区的刷新策略
- 🍣1.4、模拟实现C库函数
- 🌸2、标准输出流与错误流的区别
- 🍤2.1、概念
- 🍥2.3、perror
- 🍤2.2、标准错误流的意义
🌈前言
本篇文章进行操作系统中缓冲区的学习!!!
🌷1、缓冲区
🍡1.1、缓冲区的理解
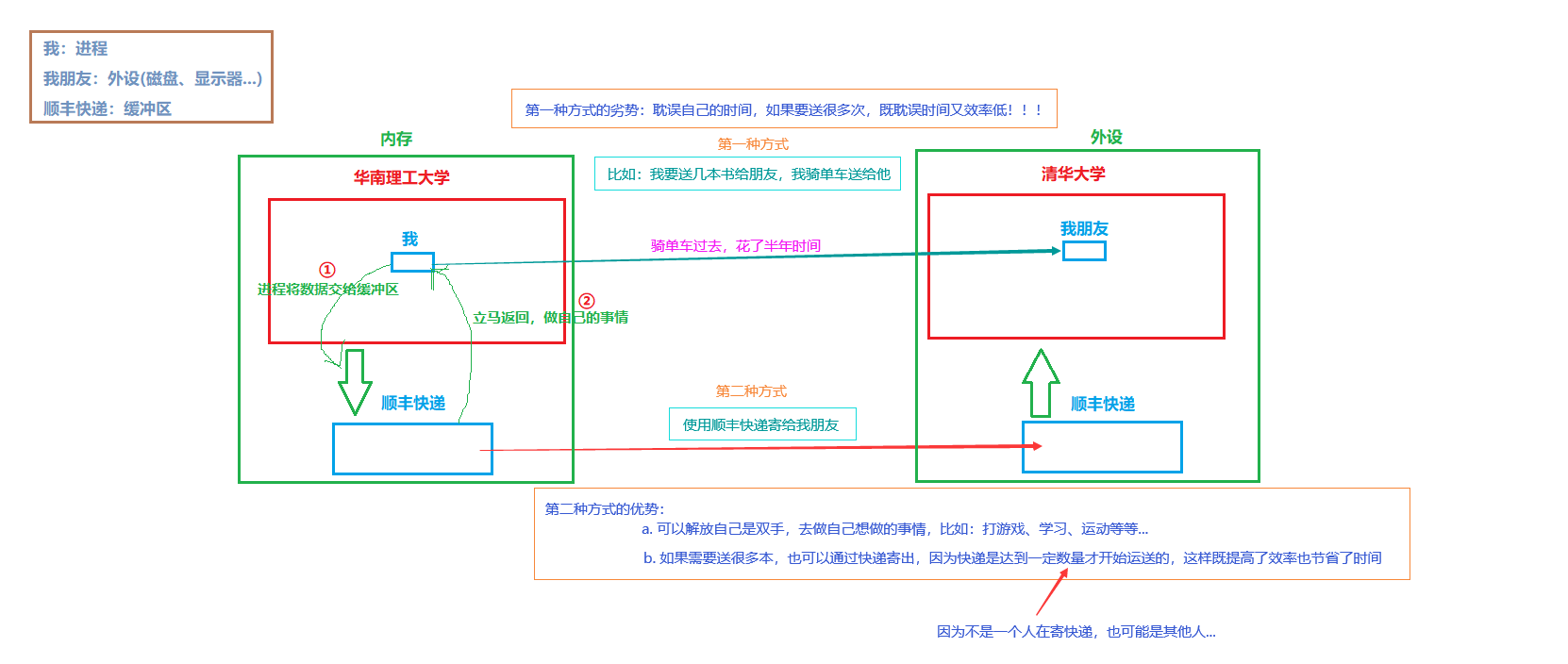
什么是缓冲区呢?
- 缓冲区的本质:就是一段内存
为什么要有缓冲区呢?
-
解放使用缓冲区的进程的时间(将数据放到缓冲区后,进程继续执行自己的代码)
-
缓冲区的存在可以集中处理数据刷新,减少I/O的次数,从而达到提高整机的效率!!!
🍢1.2、缓冲区在哪里?
代码验证:
字符串带‘\n’,会立即刷新到文件中,这是“行刷新”
[lyh_sky@localhost lesson20]$ cat cache.c
#include <stdio.h>
#include <string.h>
#include <unistd.h>
int main()
{
// stdout -> 1号文件描述符
printf("hello printf!!!\n");
const char* msg = "hello write!!!\n";
// 1号文件描述符 -> stdout
write(1, msg, strlen(msg));
return 0;
}
[lyh_sky@localhost lesson20]$ ./cache
hello printf!!!
hello write!!!
如果不带回车有什么现象呢?
[lyh_sky@localhost lesson20]$ cat cache.c
#include <stdio.h>
#include <string.h>
#include <unistd.h>
int main()
{
// stdout -> 1号文件描述符 -- 底层封装了write
printf("hello printf!!!");
const char* msg = "hello write!!!";
// 1号文件描述符 -> stdout
write(1, msg, strlen(msg));
sleep(3);
return 0;
}
[lyh_sky@localhost lesson20]$ ./cache
hello write!!!hello printf!!![lyh_sky@localhost lesson20]$
-
printf底层封装了write却没有立即刷新的原因,是因为有缓冲区的存在
-
write系统调用是立即刷新缓冲区的
-
这个缓冲区一定不在write内部!我们曾经所说的缓冲区,不是内核级别的缓冲区!
-
那么这个缓冲区只能是语言级别的,由C语言提供
FILE是一个结构体,结构体里封装了很多属性,其中必定包含fd、对应语言级别的缓冲区
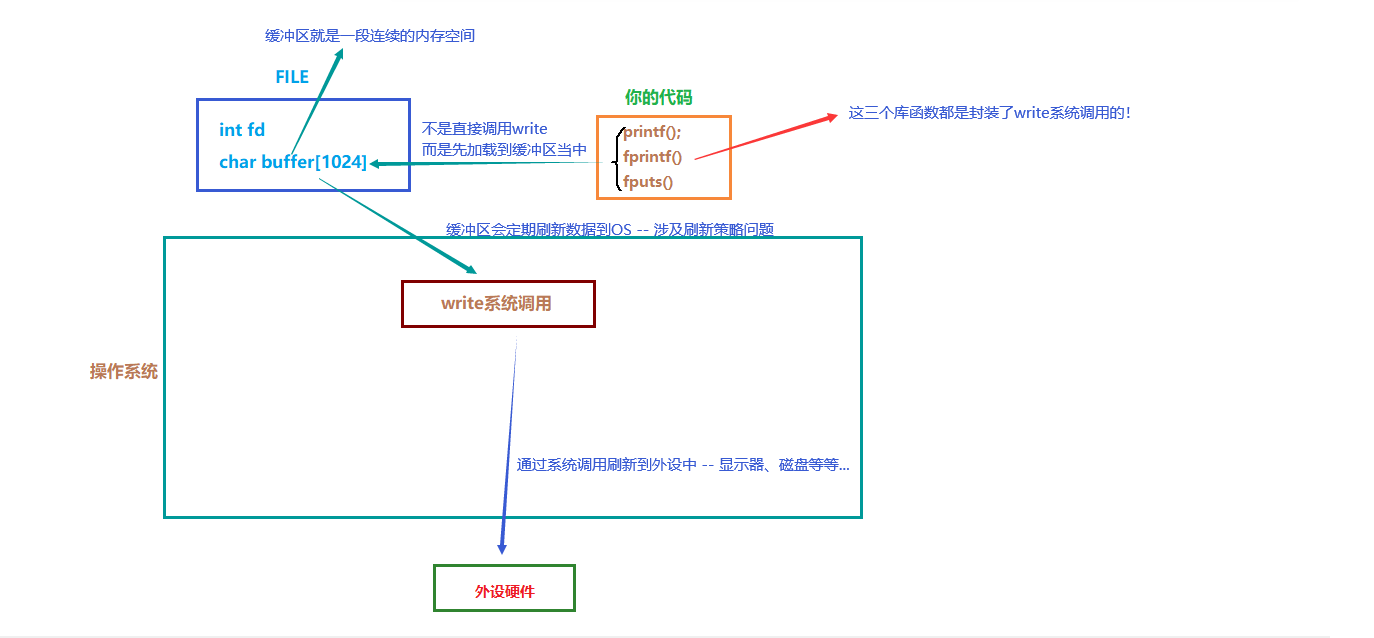
-
既然缓冲区在FILE内部,在C语言中,我们每打开一个文件,都有一个FILE*文件指针返回
-
意味着,我们没打开一个文件,都有一个fd和属于自己的对应语言级别的缓冲区!!!
🍣1.3、缓冲区的刷新策略
缓冲区的刷新策略分为三种:
-
无缓冲:数据立即刷新到外设当中 – write()
-
行缓冲:数据遇到回车换行(‘\n’)后,刷新到外设当中 – 逐行刷新
-
全缓冲:缓冲区满了后,就刷新到外设当中 – 块设备对应的文件,磁盘文件
注意:全缓冲不一定是要缓冲区满了才会刷新,进程退出和用户强制刷新也会刷新缓冲区!!!
特殊的刷新策略:
-
进程退出,刷新缓冲区 – 程序退出、exit()
-
用户强制刷新 – fflush函数
[lyh_sky@localhost lesson20]$ cat cache.c
#include <stdio.h>
#include <string.h>
#include <unistd.h>
int main()
{
// stdout -> 1号文件描述符 -- 底层封装了write
printf("hello printf!!!");
const char* msg = "hello write!!!";
fflush(stdout); // 强制刷新输出缓冲区
// 1号文件描述符 -> stdout
write(1, msg, strlen(msg));
sleep(3);
return 0;
}
[lyh_sky@localhost lesson20]$ ./cache
hello printf!!!hello write!!![lyh_sky@localhost lesson20]$
如果在刷新之前,关了fd会怎么样呢???
[lyh_sky@localhost lesson20]$ cat cache.c
#include <stdio.h>
#include <string.h>
#include <unistd.h>
int main()
{
printf("hello printf!!!"); // stdout -> 1
const char* msg = "hello write!!!"; // 1 -> stdout
// 刷新之前关闭1号文件描述符
write(1, msg, strlen(msg));
close(1);
return 0;
}
// 只打印了write写入的数据 -- write是立即刷新缓冲区
hello write!!![lyh_sky@localhost lesson20]$ ./cache
为什么没有回显内容呢?
-
因为数据一开始被写入到缓冲区中,但是1号文件描述符已经关闭了
-
当进程退出后,刷新缓冲区,调用write就失败了!!!所以没有回显到显示器当中!
-
printf fwrite 库函数会自带缓冲区,而 write 系统调用没有带缓冲区
-
另外,我们这里所说的缓冲区,都是用户级缓冲区
-
其实为了提升整机性能,OS也会提供相关内核级缓冲区
FILE结构体源码
typedef struct _IO_FILE FILE; 在/usr/include/stdio.h
在/usr/include/libio.h
struct _IO_FILE {
int _flags; /* High-order word is _IO_MAGIC; rest is flags. */
#define _IO_file_flags _flags
//缓冲区相关
/* The following pointers correspond to the C++ streambuf protocol. */
/* Note: Tk uses the _IO_read_ptr and _IO_read_end fields directly. */
char* _IO_read_ptr; /* Current read pointer */
char* _IO_read_end; /* End of get area. */
char* _IO_read_base; /* Start of putback+get area. */
char* _IO_write_base; /* Start of put area. */
char* _IO_write_ptr; /* Current put pointer. */
char* _IO_write_end; /* End of put area. */
char* _IO_buf_base; /* Start of reserve area. */
char* _IO_buf_end; /* End of reserve area. */
/* The following fields are used to support backing up and undo. */
char *_IO_save_base; /* Pointer to start of non-current get area. */
char *_IO_backup_base; /* Pointer to first valid character of backup area */
char *_IO_save_end; /* Pointer to end of non-current get area. */
struct _IO_marker *_markers;
struct _IO_FILE *_chain;
int _fileno; //封装的文件描述符
#if 0
int _blksize;
#else
int _flags2;
#endif
_IO_off_t _old_offset; /* This used to be _offset but it's too small. */
#define __HAVE_COLUMN /* temporary */
/* 1+column number of pbase(); 0 is unknown. */
unsigned short _cur_column;
signed char _vtable_offset;
char _shortbuf[1];
/* char* _save_gptr; char* _save_egptr; */
_IO_lock_t *_lock;
#ifdef _IO_USE_OLD_IO_FILE
};
综合测试题:
[lyh_sky@localhost lesson20]$ cat cache.c
#include <stdio.h>
#include <string.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <unistd.h>
int main()
{
const char* str1 = "hello printf\n";
const char* str2 = "hello fprintf\n";
const char* str3 = "hello fputs\n";
const char* str4 = "hello write\n";
// C库函数
printf(str1);
fprintf(stdout, str2);
fputs(str3, stdout);
// 系统调用
write(1, str4, strlen(str4));
// 创建子进程 -- 执行上面的代码后子进程才开始执行
fork();
return 0;
}
[lyh_sky@localhost lesson20]$ ls
cache cache.c makefile
[lyh_sky@localhost lesson20]$ ./cache
hello printf
hello fprintf
hello fputs
hello write
// 重定向到写入到log.txt文件
[lyh_sky@localhost lesson20]$ ./cache > log.txt
[lyh_sky@localhost lesson20]$ ls
cache cache.c log.txt makefile
[lyh_sky@localhost lesson20]$ cat log.txt
hello write
hello printf
hello fprintf
hello fputs
hello printf
hello fprintf
hello fputs
为什么重定向后除了write系统接口,其他C库函数都回显了二次呢???
理论:
-
刷新的本质:把缓冲区的数据write到OS内部,清空缓冲区,end置为0
-
缓冲区是自己的FILE结构体内部维护的,属于父进程内部的数据区域
原因:
注意:如果没有重定向就是“行缓冲”,逐行刷新(遇到\n)
-
一般C库函数写入文件时是全缓冲的,而写入显示器是行缓冲
-
printf fwrite 库函数会自带缓冲区(之前的很多例子可以说明),当发生重定向到普通文件时,数据的缓冲方式由“行缓冲”变成了“全缓冲”
-
重定向的本质是全缓冲(里面必定调用了dup2系统接口),数据会暂存到缓冲区中,当执行到fork()时,创建子进程,子进程直接走到retrun
-
父子进程在退出时,数据会发生写时拷贝,所以当你父进程准备刷新的时候,子进程也就有了同样的一份数据,随即产生两份数据
-
write因为不存在缓冲区,所以不会进行写时拷贝,所以才打印了一次!
-
进程中某个数据发生改变,就会写时拷贝某个数据
🍣1.4、模拟实现C库函数
#include <stdio.h>
#include <unistd.h>
#include <stdlib.h>
#include <string.h>
#include <sys/stat.h>
#include <sys/types.h>
#include <fcntl.h>
#include <assert.h>
#define NUM 1024
// 刷新策略标记位
#define NONE_FLUSH 0x0 // 无缓冲
#define LINE_FLUSH 0x1 // 行缓冲
#define FULL_FLUSH 0x2 // 全缓冲
typedef struct _MyFILE{
int _fileno; // 文件描述符
char _buffer[NUM]; // 缓冲区
int _end; // 记录缓冲区尾部下标
int _flags; // fflush method
}MyFILE;
MyFILE *my_fopen(const char *filename, const char *method)
{
assert(filename);
assert(method);
int flags = O_RDONLY;
if(strcmp(method, "r") == 0)
{
flags = O_RDONLY;
}
else if(strcmp(method, "r+") == 0)
{
flags = O_RDWR;
}
else if(strcmp(method, "w") == 0)
{
flags = O_WRONLY | O_CREAT | O_TRUNC;
}
else if(strcmp(method, "w+") == 0)
{
flags = O_RDWR | O_CREAT | O_TRUNC;
}
else if(strcmp(method, "a") == 0)
{
flags = O_WRONLY | O_CREAT | O_APPEND;
}
else if(strcmp(method, "a+") == 0)
{
flags = O_RDWR | O_CREAT | O_APPEND;
}
int fileno = open(filename, flags, 0666);
if(fileno < 0)
{
return NULL;
}
MyFILE *fp = (MyFILE *)malloc(sizeof(MyFILE));
if(fp == NULL) return fp;
memset(fp, 0, sizeof(MyFILE));
fp->_fileno = fileno;
fp->_flags |= LINE_FLUSH;
fp->_end = 0;
return fp;
}
void my_fflush(MyFILE *fp)
{
assert(fp);
if(fp->_end > 0)
{
write(fp->_fileno, fp->_buffer, fp->_end);
fp->_end = 0;
syncfs(fp->_fileno);
}
}
void my_fwrite(MyFILE *fp, const char *start, int len)
{
assert(fp);
assert(start);
assert(len > 0);
// abcde123
// 写入到缓冲区里面
strncpy(fp->_buffer+fp->_end, start, len); //将数据写入到缓冲区了
fp->_end += len;
if(fp->_flags & NONE_FLUSH)
{}
else if(fp->_flags & LINE_FLUSH)
{
if(fp->_end > 0 && fp->_buffer[fp->_end-1] == '\n')
{
//仅仅是写入到内核中
write(fp->_fileno, fp->_buffer, fp->_end);
fp->_end = 0;
syncfs(fp->_fileno);
}
}
else if(fp->_flags & FULL_FLUSH)
{
// 如果写入缓冲区的数据长度等于缓冲区的最大存储数量,则刷新缓冲区
if (len == NUM)
{
write(fp->_fileno, fp->_buffer, fp->_end);
fp->_end = 0;
syncfs(fp->_fileno)
}
}
}
void my_fclose(MyFILE *fp)
{
my_fflush(fp);
close(fp->_fileno);
free(fp);
}
int main()
{
MyFILE *fp = my_fopen("log.txt", "w");
if(fp == NULL)
{
printf("my_fopen error\n");
return 1;
}
//模拟进程退出
my_fclose(fp);
return 0;
}
🌸2、标准输出流与错误流的区别
🍤2.1、概念
-
我们都知道输出流和错误流对应的文件描述符是1和2
-
1和2对应的外设都是显示器,对其写入就是回显到显示器上
代码验证
#include <iostream>
#include <cstdio>
int main()
{
// stdout->1
printf("hello printf->stdout->1\n");
fprintf(stdout, "hello fprintf->stdout->1\n");
fputs("hello fputs->stdout->1\n", stdout);
std::cout << "hello cout->stdout->1" << std::endl;
std::cout << std::endl;
// stderr->2
fprintf(stderr, "hello fprintf->stderr->2\n");
fputs("hello fputs->stderr->2\n", stderr);
perror("hello perror");
std::cerr << "hello cerr->stderr->2" << std::endl;
return 0;
}
// 输出流和错误流向显示器写入的内容都回显到显示器中了!!!
[lyh_sky@localhost out_errno]$ ./test
hello printf->stdout->1
hello fprintf->stdout->1
hello fputs->stdout->1
hello cout->stdout->1
hello fprintf->stderr->2
hello fputs->stderr->2
hello perror: Success
hello cerr->stderr->2
我们对该代码进行输出重定向,看看有什么区别!!!
[lyh_sky@localhost out_errno]$ ls
makefile test Test.cc
[lyh_sky@localhost out_errno]$ ./test > log.txt
hello fprintf->stderr->2
hello fputs->stderr->2
hello perror: Success
hello cerr->stderr->2
[lyh_sky@localhost out_errno]$ cat log.txt
hello printf->stdout->1
hello fprintf->stdout->1
hello fputs->stdout->1
hello cout->stdout->1
- 我们发现只有向1号文件描述符写入的数据被重定向到了文件当中
但是错误流输出的数据被回显到显示器当中,为什么呢?
-
因为只进行了输出重定向,输出重定向是指把写入stdout的数据重定向到指向的文件中
-
而stderr是2号fd,它不会写入到stdout,所以会回显到显示器中!!!
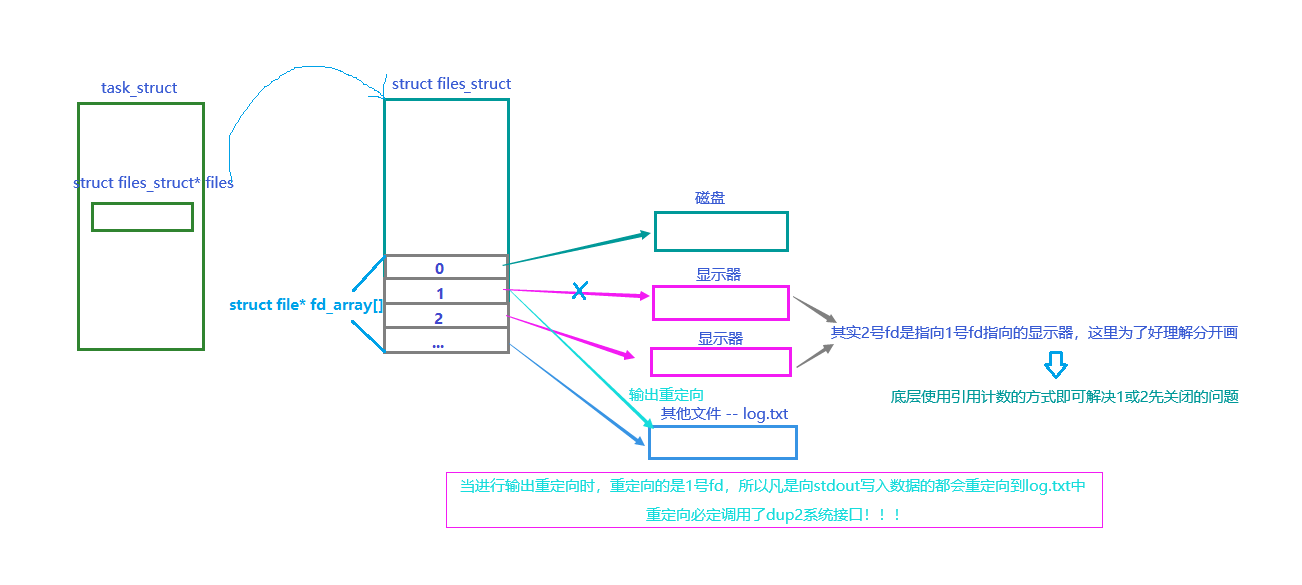
如何将错误流的数据重定向到文件中呢?
- 使用【./可执行程序 2> 文件名】,即可将错误流的数据重定向到指定文件中
[lyh_sky@localhost out_errno]$ ls
makefile test Test.cc
// 这里是将向stdout写入数据重定向到log.txt,向stderr写入数据重定向到errno.tx
[lyh_sky@localhost out_errno]$ ./test > log.txt 2> errno.txt
[lyh_sky@localhost out_errno]$ ls
errno.txt log.txt makefile test Test.c
[lyh_sky@localhost out_errno]$ cat log.txt
hello printf->stdout->1
hello fprintf->stdout->1
hello fputs->stdout->1
hello cout->stdout->1
[lyh_sky@localhost out_errno]$ cat errno.txt
hello fprintf->stderr->2
hello fputs->stderr->2
hello perror: Success
hello cerr->stderr->2
🍥2.3、perror
#include <stdio.h>
void perror(const char *s);
-
在标准错误输出上生成一条消息,描述在调用系统或库函数时遇到的最后一个错误
-
第一个参数如果s不为NULL并且*s不是空字节(“\0”),将打印参数字符串s,后跟冒号和空白
模拟实现perror
#include <string.h>
char *strerror(int errnum);
-
该函数用于获取指向错误消息字符串的指针
-
可以通过errno获取错误码,然后传递给它,就能获取最近一次的错误信息!!!
[lyh_sky@localhost out_errno]$ cat Test.cc
#include <iostream>
#include <cstdio>
#include <cstring>
#include <errno.h>
#include <sys/stat.h>
#include <sys/types.h>
#include <fcntl.h>
void my_perror(const char *info)
{
fprintf(stderr, "%s: %s\n", info, strerror(errno));
}
int main()
{
//fopen: C库函数
int fd = open("log.txt", O_RDONLY); //必定失败的 -- 当前进程工作路径下没有该文件
if(fd < 0)
{
//perror("open");
my_perror("my open");
return 1;
}
return 0;
}
[lyh_sky@localhost out_errno]$ ls
makefile test Test.cc
[lyh_sky@localhost out_errno]$ ./test
my open: No such file or directory
[lyh_sky@localhost out_errno]$ echo $?
1
-
当系统调用失败时,它通常返回-1,并将变量errno(全局变量)设置为一个描述错误的值(错误码)。(这些值可以在<errno.h>中找到!!!
-
语言中会有自己一套的错误码,我们也可以使用exit指定进程退出错误码,或者使用return …
-
如果调用失败的之后没有立即调用perror(),则errno的值也会被保存下来
-
函数perror()用于将此错误代码转换为一段字符串,回显到显示器
🍤2.2、标准错误流的意义
意义:
-
可以区分那些是日常程序的输出,哪些是错误
-
可以帮助我们以后写项目时,快速的差错,这就是“日志”!!!
-
我们现在写的程序虽然都用不着,但是还得了解一下