以下内容是针对pgsql11来做的。请看好版本再去考虑是否往下看
准备两台服务器,地址如下:
| 主:192.168.0.1 | pgsql11 |
|---|---|
| 从:192.168.0.2 | pgsql11 |
一、主库配置
1、创建具有复制权限的用户replica 密码为000000
CREATE ROLE replica login replication encrypted password 'xxxxxx';
2、修改postgresql.conf
首先创建归档目录:mkdir -p /var/lib/pgsql/11/data/archive。我这边是放到了我数据存储的相关目录。注意:归档目录必须要对postgres用户授权。否则启动会报错。
把postgresql.conf有关信息改成以下内容
listen_addresses = '*' # what IP address(es) to listen on;
port = 5432 # (change requires restart)
max_connections = 1000 # (change requires restart)
shared_buffers = 128MB # min 128kB
dynamic_shared_memory_type = posix # the default is the first option
wal_level = replica # minimal, replica, or logical
archive_mode = on # enables archiving; off, on, or always
archive_command = 'cp %p /var/lib/pgsql/11/data/archive/%f'
# command to use to archive a logfile segment
wal_sender_timeout = 60s # in milliseconds; 0 disables
hot_standby = on # "on" allows queries during recovery
max_standby_streaming_delay = 30s # max delay before canceling queries
wal_receiver_status_interval = 10s # send replies at least this often
hot_standby_feedback = on # send info from standby to prevent
log_directory = 'log' # directory where log files are written
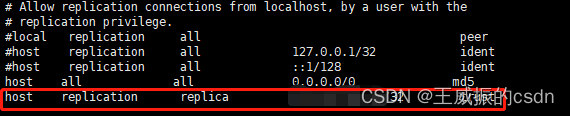
3、修改pg_hba.conf
把以下内容放到host最后一行。切记一定要放到最后,不然不进行复制工作。如图所示:
host replication replica 192.168.0.2/32 trust
4、重启主库
systemctl reload pgsql.service
这边顺带絮叨下,systemctl配置pgsql启动。
利用root权限进到目录 cd /etc/systemd/system
然后通过vi pgsql.service创建个新文件。把以下内容放到pgsql.service中。注意改下相关路径
[Unit]
Description=PostgreSQL database server
After=network.target
[Service]
Type=forking
User=postgres
Group=postgres
Environment=PGPORT=5432
Environment=PGDATA=/var/lib/pgsql/11/data/
OOMScoreAdjust=-1000
ExecStart=/usr/pgsql-11/bin/pg_ctl start -D ${PGDATA} -s -o "-p ${PGPORT}" -w -t 300
ExecStop=/usr/pgsql-11/bin/pg_ctl stop -D ${PGDATA} -s -m fast
ExecReload=/usr/pgsql-11/bin/pg_ctl reload -D ${PGDATA} -s
TimeoutSec=300
[Install]
WantedBy=multi-user.target
然后执行以下命令启用服务控制守护
systemctl daemon-reload
配置开机启动
systemctl enable pgsq.service
二、配置从库
1、验证下主库是否配置成功
[root@localhost data]# psql -h 192.168.0.1 -U postgres
psql (11.18)
Type "help" for help.
postgres=#
2、停止从库
systemctl stop pgsql.service
3、清空data数据存储
把data下的数据全清除。因为第四步要拉取主库的信息
rm -rf /var/lib/pgsql/11/data/*
4、从主库拉取数据
192.168.0.1:主库ip
pg_basebackup -h 192.168.0.1 -U replica -D /var/lib/pgsql/11/data/ -X stream -P
5、从库配置postgresql.conf
第四步拉取后的postgresql.conf文件,其实和主库中的postgresql.conf是一致的。检查下没问题就可以了
把postgresql.conf相关内容改成如下。注意归档文件的创建。
mkdir -p /var/lib/pgsql/11/data/archive/
listen_addresses = '*' # what IP address(es) to listen on;
port = 5432 # (change requires restart)
max_connections = 1000 # (change requires restart)
shared_buffers = 128MB # min 128kB
dynamic_shared_memory_type = posix # the default is the first option
wal_level = replica # minimal, replica, or logical
archive_mode = on # enables archiving; off, on, or always
archive_command = 'cp %p /var/lib/pgsql/11/data/archive/%f' # command to use to archive a logfile segment
wal_sender_timeout = 60s # in milliseconds; 0 disables
hot_standby = on # "on" allows queries during recovery
max_standby_streaming_delay = 30s # max delay before canceling queries
wal_receiver_status_interval = 10s # send replies at least this often
hot_standby_feedback = on # send info from standby to prevent
log_directory = 'log' # directory where log files are written
5、在data目录下修改或创建recovery.conf文件。如果不存在就自己创建
# 调整参数:
recovery_target_timeline = 'latest' #同步到最新数据
standby_mode = on #指明从库身份
trigger_file = 'failover.now'
primary_conninfo = 'host=192.168.0.1 port=5432 user=replica password=xxxxxx' #连接到主库信息
6、启动从库
systemctl start pgsql.service
然后再主库中执行
select client_addr,sync_state from pg_stat_replication;如果有从库节点信息。表示已经创建成功了。可以实验从主库插入一条数据,不出意外的话。从库会同步到此条数据。



![PGL图学习之图神经网络ERNIESage、UniMP进阶模型[系列八]](https://img-blog.csdnimg.cn/img_convert/1febb74318366fec6f5d05a8ce144b36.jpeg)