第一章 资源调度框架YARN理论
1.1 YARN概述
分布式操作系统
hadoop 1.x
MapReduce
主从架构 主节点JobTracker 从节点TaskTracker
slot
hadoop 2.x
MapReduce编程API + YARN
主从架构 主节点ResourceManager 从节点NodeManager
Container
hadoop 3.x
Common
HDFS 纠删码
MapReduce
YARN
MapReduce编程API + YARN
YARN(Yet Another Resource Negotiator)
Yarn 是一个资源调度平台,负责为运算程序提供服务器运算资源,相当于一个分布式的操作系统平台,而 MapReduce 等运算程序则相当于运行于操作系统之上的应用程序。
有以下注意点:
1、yarn 并不清楚用户提交的程序的运行机制
2、yarn 只提供运算资源的调度(用户程序向 yarn 申请资源,yarn 就负责分配资源)
3、yarn 中的主管角色叫 ResourceManager
4、yarn 中提供运算资源的角色叫 NodeManager
5、yarn 与运行的用户程序解耦
6、MapReduce、Spark、Flink等运算框架都可以整合在 yarn 上运行
7、yarn 就成为一个通用的资源调度平台
1.2 YARN 的重要概念
1、ResourceManager
ResourceManager 是基于应用程序对集群资源的需求进行调度的 Yarn 集群主控节点,负责协调和管理整个集群的资源,响应用户提交的不同类型应用程序的解析,调度,监控等工作。ResourceManager 会为每一个 Application 启动一个 MRAppMaster, 并且 MRAppMaster 分散在各个 NodeManager 节点。
由两个组件构成:调度器(Scheduler)和应用程序管理器(ApplicationsManager,ASM)
2、NodeManager
NodeManager 是 YARN 集群当中真正资源的提供者,是真正执行应用程序的容器的提供者, 监控应用程序的资源使用情况,并通过心跳向集群资源调度器 ResourceManager 进行汇报。
3、Container
Container 是一个抽象出来的逻辑资源单位。它封装了一个节点上的 CPU,内存,磁盘,网络等信息,MapReduce 程序的所有 Task都是在一个容器里执行完成的,容器大小可以动态调整。
1.3 调度器
1.3.1 FIFO(先进先出调度器)
FIFO(First In First Out先进先出调度器):单队列的,根据提交作业的先后顺序,先来先服务
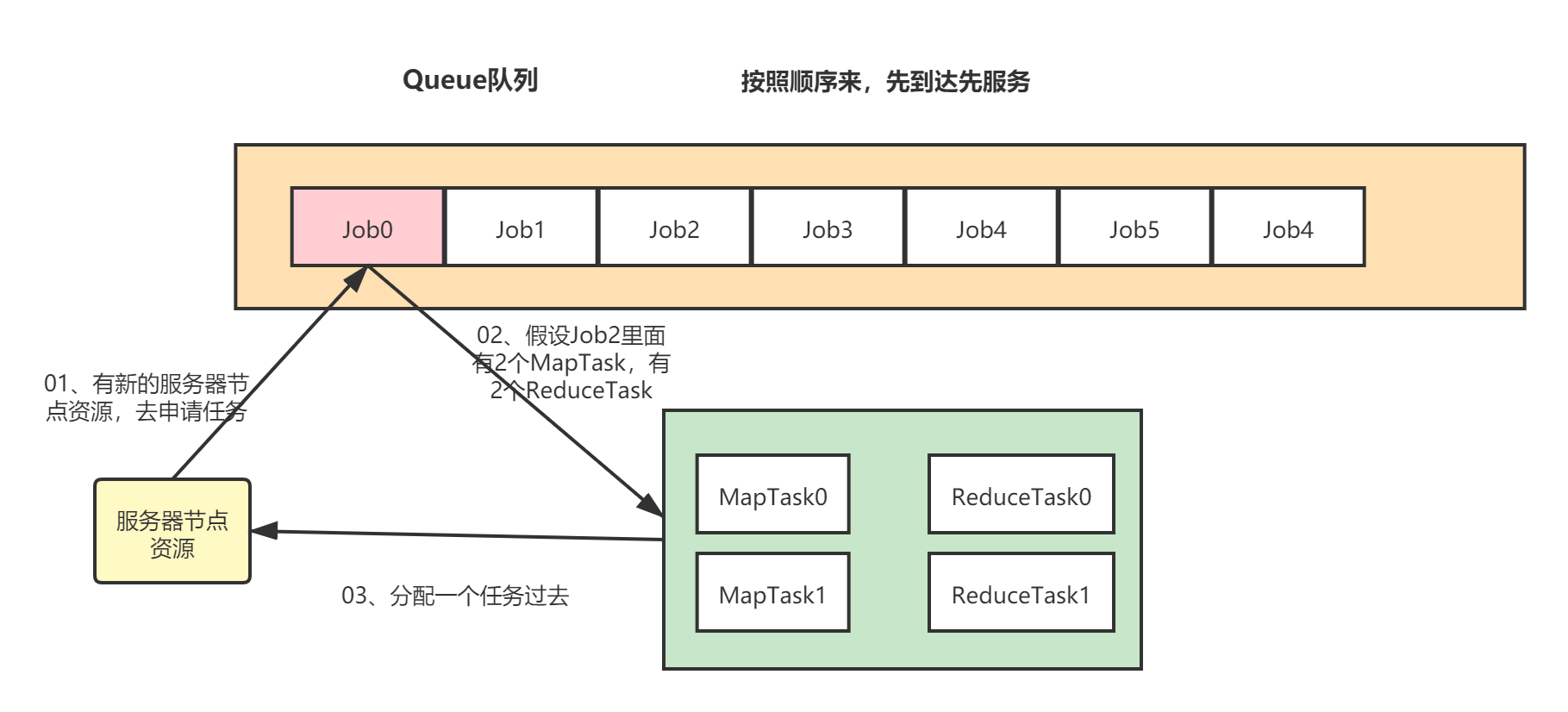
FIFO优缺点:
优点:简单方便
缺点:不支持多队列,生产环境使用较少
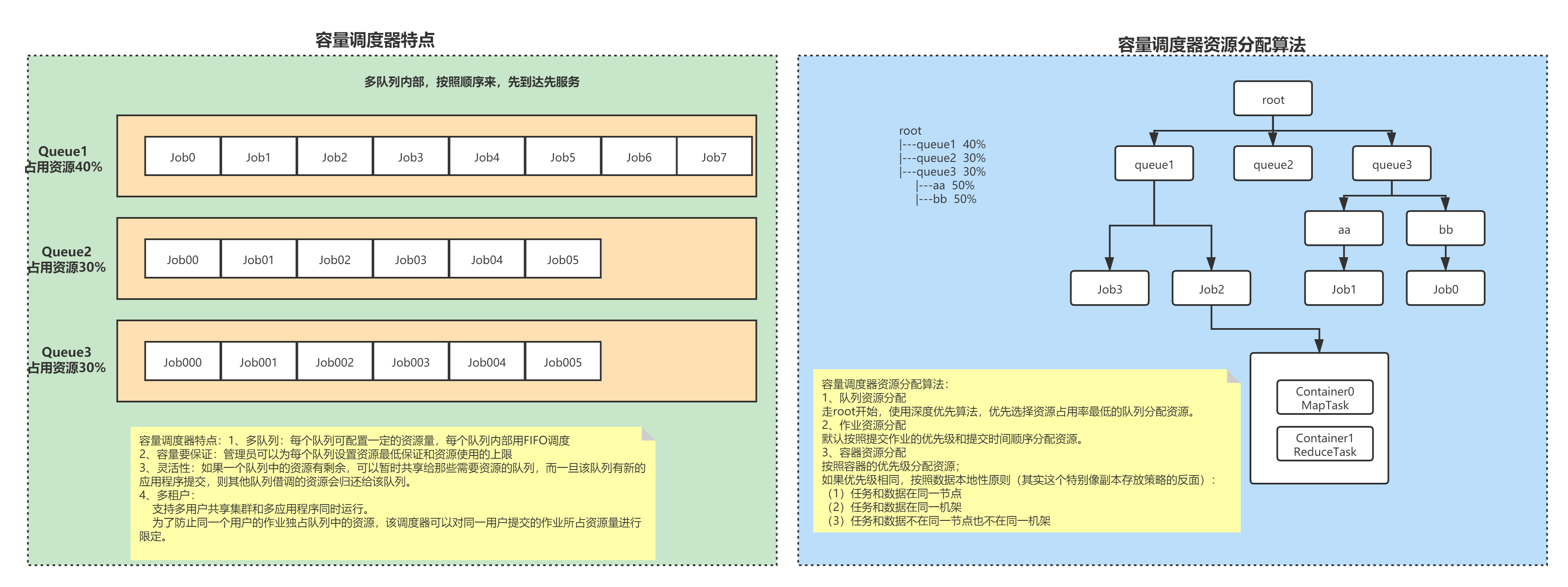
1.3.2 Capacity Scheduler (容量调度器)
1.3.3 Fair Scheduler(公平调度器)
1、特点

2、缺额的概念
概念: 某一时刻一个作业应获资源和实际获取资源的差距叫缺额
公平调度器设计目标是:在时间尺度上,所有作业获得公平的资源。
调度器会优先为缺额大的作业分配资源
3、队列内部资源分配策略
1、FIFO策略
公平调度器每个队列资源分配策略可以选择FIFO,这样的话,公平调度器相当于容量调度器。
2、Fair策略
Fair 策略(默认)是一种基于公平算法实现的资源多路复用方式,默认情况下,每个队列内部采用该方式分配资源。这个时候用,如果一个队列中有两个程序运行,那么每个程序可得到1/2的资源。若是有三个应用程序同时运行,则每个应用程序可得到1/3的资源。
具体资源分配流程和容量调度器一致;
(1)选择队列
(2)选择作业
(3)选择容器
以上三步都是按照公平策略分配资源
3、DRF策略
DRF(Dominant Resource Fairness),前面说的资源,基本上都是单一标准,比如只考虑内存(这个其实就是Yarn默认的情况)。但是资源有很多种,例如内存,CPU,网络带宽,磁盘等等,这样我们很难通过单个标准来衡量两个应用应该分配的资源比例。
所以在YARN中,可以用DRF来决定多资源如何调度:
例如:集群一共有300 CPU和100T 内存,而应用1需要(3 CPU, 5TB),应用2需要(30 CPU,1TB)。则两个应用分别需要1(1%CPU, 5%内存)和2(10%CPU, 1%内存)的资源,这就意味着1是内存主导的, 2是CPU主导的,针对这种情况,可以选择DRF策略对不同应用进行不同资源(CPU和内存)的一个不同比例的限制。
4、来个例子吧
(1)队列资源分配
root
|---queue1 40%
|---queue2 30%
|---queue3 30%
|---Job000 7.5%
|---Job001 7.5%
|---Job002 7.5%
|---Job003 7.5%
假设总资源是100,有三个队列queue1、queue2、queue3,对资源的需求分别为:40、30、30
第一次计算:
100/3 = 33.333
queue1:分到33.333 --> 实际需要40 ——> 所以少了6.666
queue2:分到33.333 --> 实际需要30 ——> 所以多了3.333
queue3:分到33.333 --> 实际需要30 ——> 所以多了3.333
第二次计算:
拿多出来总数除以需要分配的队列的个数
(3.333+3.333)/ 1 = 6.666
queue1:分到33.333 + 6.666 --> 分到40
queue2:分到30
queue3:分到30
(2)队列内部Job作业资源分配
不加权的方式:
关注的是Job的个数进行分配。
示例:有一条队列总资源为20个,有4个job,对资源的需求分别为:
job1:2
job2:4
job3:6
job4:8
第一次计算:
20/4 = 5
job1:分到5 --> 实际需要2 ——> 所以多了3
job2:分到5 --> 实际需要4 ——> 所以多了1
job3:分到5 --> 实际需要6 ——> 所以少了1
job4:分到5 --> 实际需要8 ——> 所以少了3
第二次计算:
拿多出来总数除以需要分配的job的个数
(3+1)/2 = 2
job1:分到2
job2:分到4
job3:分到5 --> 实际需要6 ——> 所以少了1 -->再分2个-->分到7 --> 实际需要6 ——> 所以多了1
job4:分到5 --> 实际需要8 ——> 所以少了3 -->再分2个-->分到7 --> 实际需要8 ——> 所以少了1
第三次计算:
拿多出来总数除以需要分配的job的个数
1 / 1 = 1
job1:分到2
job2:分到4
job3:分到6
job4:分到5 --> 实际需要8 ——> 所以少了3 -->再分2个-->分到7 --> 实际需要8 ——> 所以少了1 -->再分1个 --> 分到8 (这个就是实际需要的)
加权的方式:
关注的是Job的权重进行分配
示例:有一条队列总资源为20个,有4个job,对资源的需求分别为:
job1:2
job2:4
job3:6
job4:8
对应的权重是:
job1:2
job2:3
job3:2
job4:3
第一次计算:
20/(2+3+2+3) = 2
job1:分到4 --> 实际需要2 ——> 所以多了2
job2:分到6 --> 实际需要4 ——> 所以多了2
job3:分到4 --> 实际需要6 ——> 所以少了2
job4:分到6 --> 实际需要8 ——> 所以少了2
第二次计算:
拿多出来总数除以需要分配的job的个数
(2+2)/2 = 2
job1:分到2
job2:分到4
job3:分到4 --> 实际需要6 ——> 所以少了2 -->再分2个-->分到6(等于实际需要的)
job4:分到6 --> 实际需要8 ——> 所以少了2 -->再分2个-->分到8(等于实际需要的)
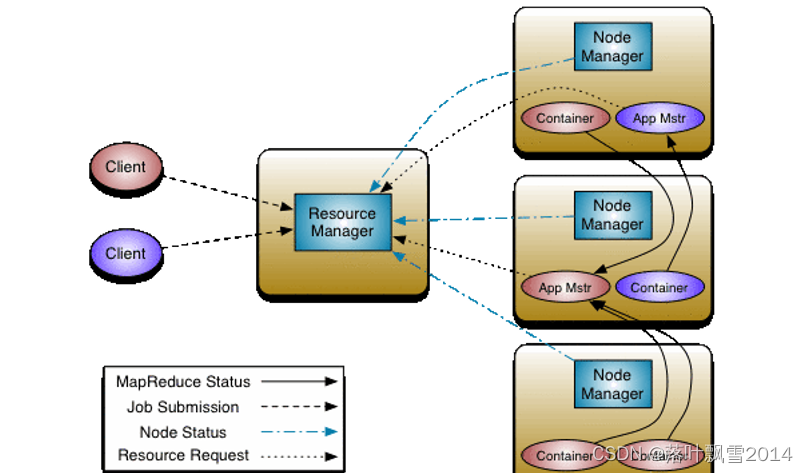
1.4 架构图
1.5 作业提交流程
1、用户向 YARN 中提交应用程序,其中包括 ApplicationMaster 程序,启动 ApplicationMaster 的命令,用户程序等
2、ResourceManager 为该程序分配第一个 Container,并与对应的 NodeManager 通讯,要求它在这个 Container 中启动应用程序 ApplicationMaster
3、ApplicationMaster 首先向 ResourceManager注册,这样用户可以直接通过 ResourceManager 查看应用程序的运行状态,然后将为各个任务申请资源,并监控它的运行状态,直到运行结束,重复 4 到 7 的步骤
4、ApplicationMaster 采用轮询的方式通过 RPC 协议向 ResourceManager 申请和领取资源
5、一旦 ApplicationMaster 申请到资源后,便与对应的 NodeManager 通讯,要求它启动任务
6、NodeManager 为任务设置好运行环境后,将任务启动命令写到一个脚本中,并通过运行该脚本启动任务
7、各个任务通过RPC 协议向 ApplicationMaster 汇报自己的状态和进度,以让 ApplicationMaster 随时掌握各个任务的运行状态。
8、应用程序运行完成后,AM 向 RM 注销并关闭自己。
画个图吧!!
第二章 资源调度框架YARN实践
2.1 先修改一下配置
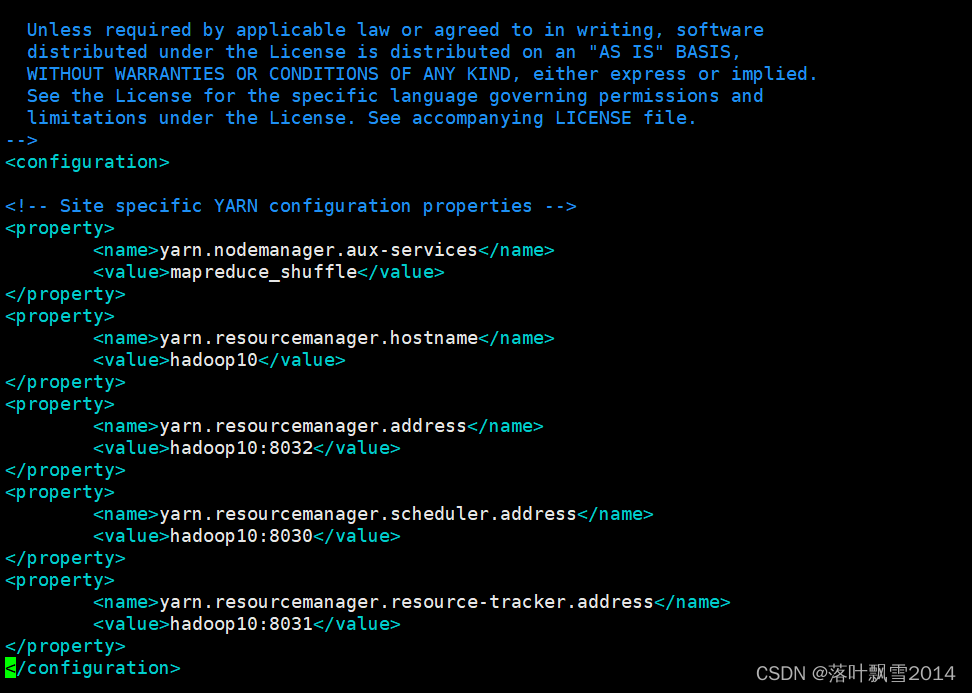
2.1.1 修改 yarn-site.xml
运行之前先给之前的hadoop配置中的yarn-site.xml里面添加如下内容,多个节点都要加。不加在8088页面中看不到Active Nodes的个数。
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop10</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>hadoop10:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>hadoop10:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>hadoop10:8031</value>
</property>
</configuration>
2.1.2 修改mapred-site.xml
下面的配置是 让MapReduce程序运行在Yarn之上 ,这个参数默认是local
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
然后在运行jar的时候,会出现问题,例如运行
[root@hadoop10 mapreduce]# hadoop jar hadoop-mapreduce-examples-3.2.2.jar pi 50 50
报错如下:
2021-09-22 19:36:51,215 INFO mapreduce.Job: map 0% reduce 0%
2021-09-22 19:36:51,229 INFO mapreduce.Job: Job job_1632310484251_0001 failed with state FAILED due to: Application application_1632310484251_0001 failed 2 times due to AM Container for appattempt_1632310484251_0001_000002 exited with exitCode: 1
Failing this attempt.Diagnostics: [2021-09-22 19:36:50.769]Exception from container-launch.
Container id: container_1632310484251_0001_02_000001
Exit code: 1
[2021-09-22 19:36:50.797]Container exited with a non-zero exit code 1. Error file: prelaunch.err.
Last 4096 bytes of prelaunch.err :
Last 4096 bytes of stderr :
Error: Could not find or load main class org.apache.hadoop.mapreduce.v2.app.MRAppMaster
Please check whether your etc/hadoop/mapred-site.xml contains the below configuration:
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=${full path of your hadoop distribution directory}</value>
</property>
<property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME=${full path of your hadoop distribution directory}</value>
</property>
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=${full path of your hadoop distribution directory}</value>
</property>
[2021-09-22 19:36:50.797]Container exited with a non-zero exit code 1. Error file: prelaunch.err.
Last 4096 bytes of prelaunch.err :
Last 4096 bytes of stderr :
Error: Could not find or load main class org.apache.hadoop.mapreduce.v2.app.MRAppMaster
Please check whether your etc/hadoop/mapred-site.xml contains the below configuration:
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=${full path of your hadoop distribution directory}</value>
</property>
<property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME=${full path of your hadoop distribution directory}</value>
</property>
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=${full path of your hadoop distribution directory}</value>
</property>
For more detailed output, check the application tracking page: http://hadoop10:8088/cluster/app/application_1632310484251_0001 Then click on links to logs of each attempt.
. Failing the application.
2021-09-22 19:36:51,247 INFO mapreduce.Job: Counters: 0
Job job_1632310484251_0001 failed!
解决方法很简单:在mapred-site.xml 增加以下配置
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
<property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
截图如下:
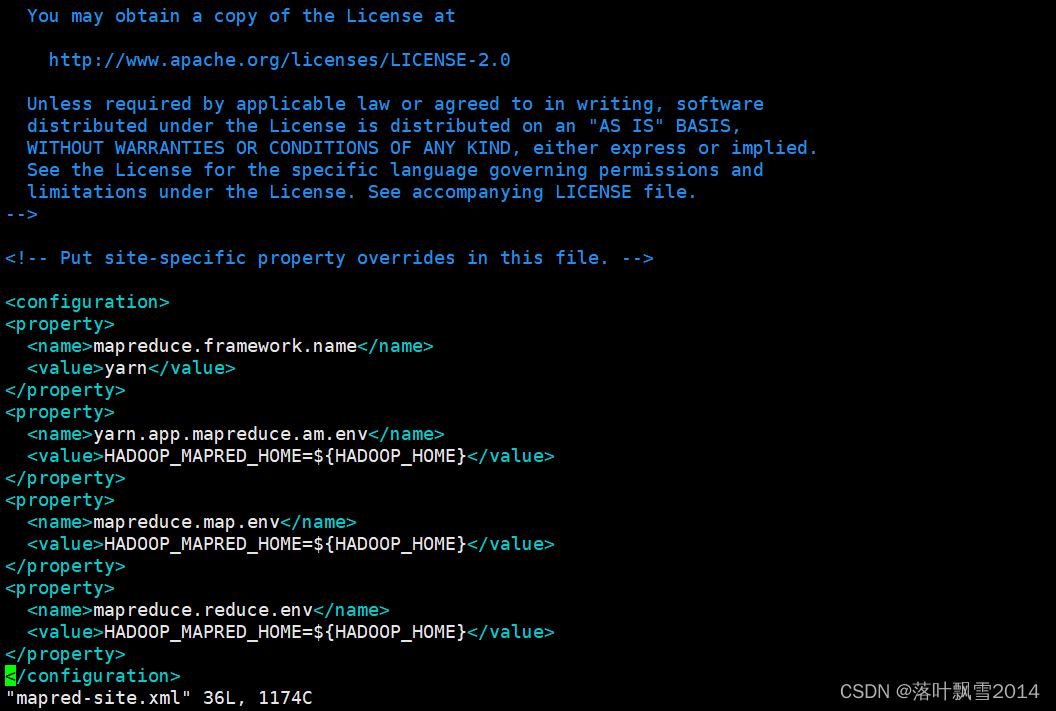
这样就解决了上面遇到的问题了。也可以改成绝对路径。
2.2 启动YARN和历史服务器
启动命令为:
start-yarn.sh
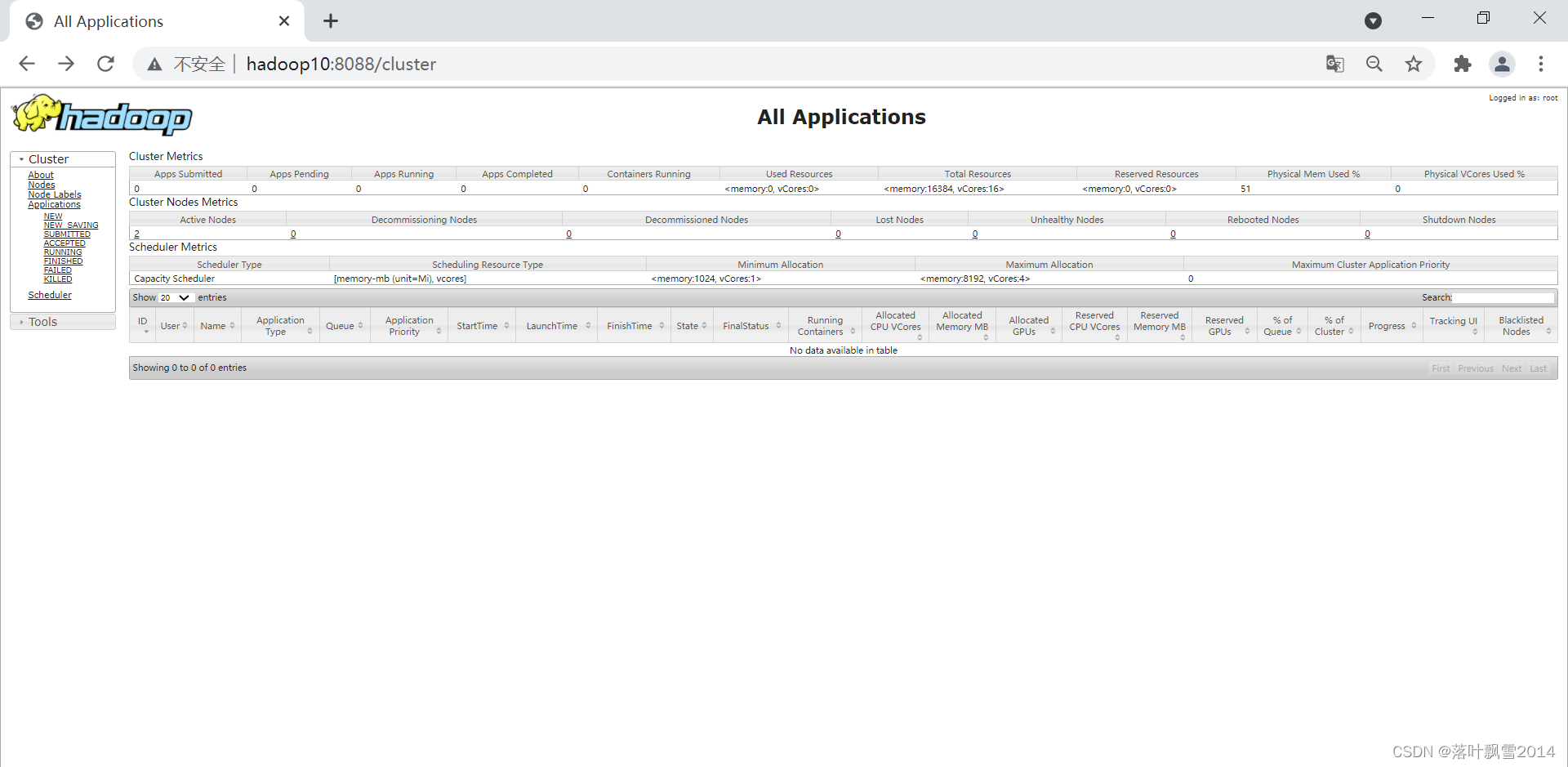
链接为:http://hadoop10:8088/cluster
正常启动之后页面如下:
启动历史服务器
启动命令:
[root@hadoop10 sbin]# pwd
/software/hadoop/sbin
[root@hadoop10 sbin]# mr-jobhistory-daemon.sh start historyserver
或者使用下面的新命令:
[root@hadoop10 hadoop]# mapred --daemon start historyserver
[root@hadoop10 hadoop]# jps
15458 JobHistoryServer
15082 ResourceManager
14589 NameNode
15550 Jps
[root@hadoop10 hadoop]#
[root@hadoop10 hadoop]# mapred --daemon stop historyserver
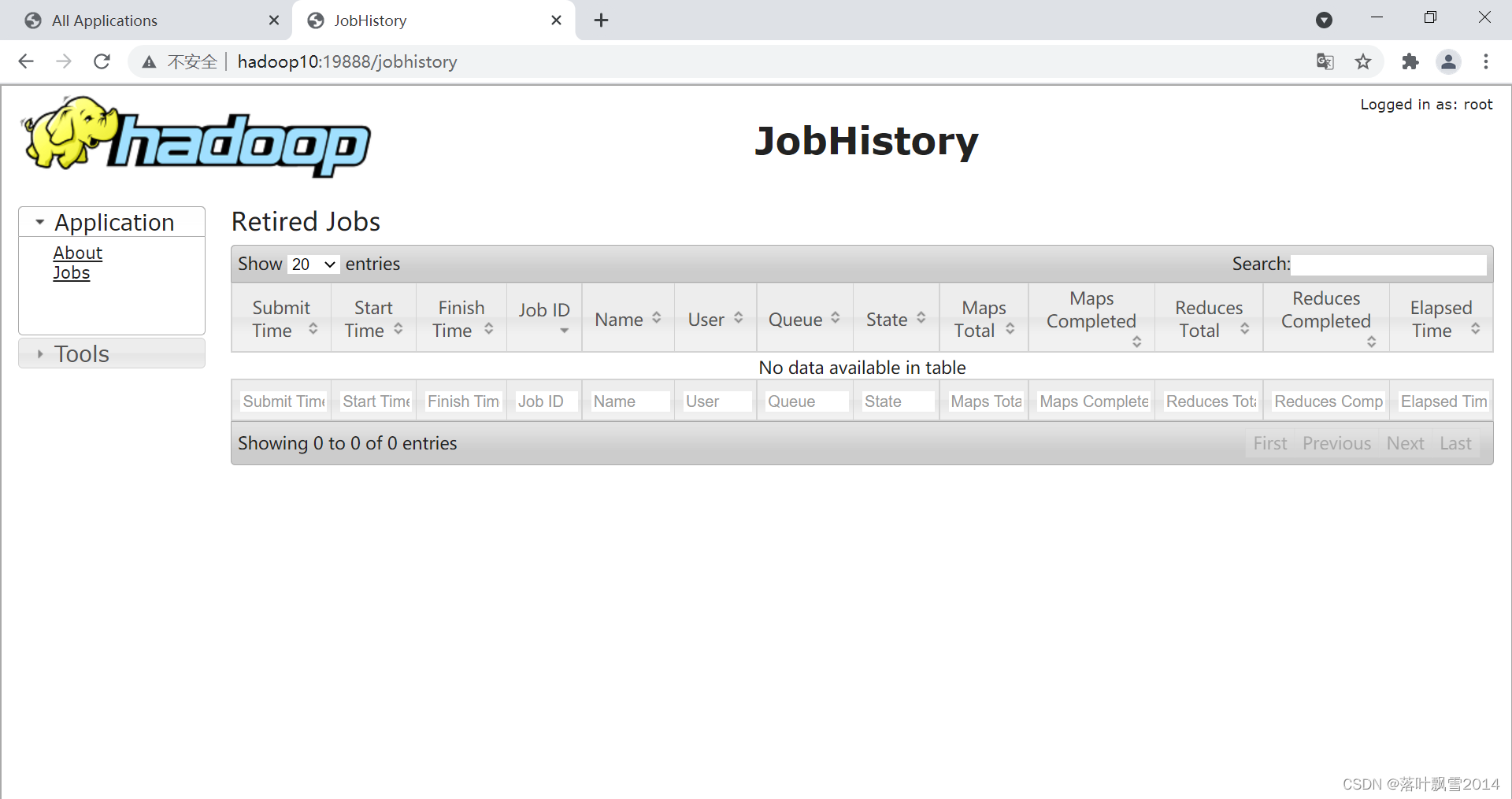
页面访问链接为:
http://hadoop10:19888/jobhistory
2.3 动手实践
2.3.1 查看任务
1、列出来所有的。
[root@hadoop10 hadoop]# yarn application -list
2021-09-22 20:02:15,689 INFO client.RMProxy: Connecting to ResourceManager at hadoop10/192.168.22.136:8032
Total number of applications (application-types: [], states: [SUBMITTED, ACCEPTED, RUNNING] and tags: []):0
Application-Id Application-Name Application-Type User Queue State Final-State Progress Tracking-URL
[root@hadoop10 hadoop]#
2、根据Application状态查询:yarn application -list -appStates (所有状态:ALL、NEW、NEW_SAVING、SUBMITTED、ACCEPTED、RUNNING、FINISHED、FAILED、KILLED)
[root@hadoop10 hadoop]# yarn application -list -appStates FINISHED
2021-09-22 20:14:36,133 INFO client.RMProxy: Connecting to ResourceManager at hadoop10/192.168.22.136:8032
Total number of applications (application-types: [], states: [FINISHED] and tags: []):1
Application-Id Application-Name Application-Type User Queue State Final-State Progress Tracking-URL
application_1632311749018_0001 QuasiMonteCarlo MAPREDUCE root default FINISHED SUCCEEDED 100% http://hadoop12:19888/jobhistory/job/job_1632311749018_0001
[root@hadoop10 hadoop]#

2.3.2 查看日志
1、查询Application应用日志
[root@hadoop10 hadoop]# yarn logs -applicationId job_1632311749018_0001
2、查看Container容器日志
[root@hadoop10 hadoop]# yarn logs -applicationId application_1632311749018_0001 -containerId container_1632311749018_0001_01_000001
2.3.3 查看attempt的任务
1、列出所有Application尝试的列表
yarn applicationattempt -list <ApplicationId>
[root@hadoop10 hadoop]# yarn applicationattempt -list application_1632311749018_0001
2021-09-22 20:21:34,413 INFO client.RMProxy: Connecting to ResourceManager at hadoop10/192.168.22.136:8032
Total number of application attempts :1
ApplicationAttempt-Id State AM-Container-Id Tracking-URL
appattempt_1632311749018_0001_000001 FINISHED container_1632311749018_0001_01_000001 http://hadoop10:8088/proxy/application_1632311749018_0001/
2、打印ApplicationAttemp状态
yarn applicationattempt -status <ApplicationAttemptId>
[root@hadoop10 hadoop]# yarn applicationattempt -status appattempt_1632311749018_0001_000001
2021-09-22 20:22:49,416 INFO client.RMProxy: Connecting to ResourceManager at hadoop10/192.168.22.136:8032
Application Attempt Report :
ApplicationAttempt-Id : appattempt_1632311749018_0001_000001
State : FINISHED
AMContainer : container_1632311749018_0001_01_000001
Tracking-URL : http://hadoop10:8088/proxy/application_1632311749018_0001/
RPC Port : 45512
AM Host : hadoop12
Diagnostics :
[root@hadoop10 hadoop]#
2.3.4 查看容器
1、列出所有Container
yarn container -list <ApplicationAttemptId>
[root@hadoop10 hadoop]# yarn container -list appattempt_1632311749018_0001_000001
2021-09-22 20:28:43,314 INFO client.RMProxy: Connecting to ResourceManager at hadoop10/192.168.22.136:8032
Total number of containers :0
Container-Id Start Time Finish Time State Host Node Http Address LOG-URL
2、打印Container状态
yarn container -status <ContainerId>
[root@hadoop10 hadoop]# yarn container -status container_1632311749018_0001_01_000001
2021-09-22 20:29:03,732 INFO client.RMProxy: Connecting to ResourceManager at hadoop10/192.168.22.136:8032
Container with id 'container_1632311749018_0001_01_000001' doesn't exist in RM or Timeline Server.
注意:只有任务在跑的过程中才能看到container的状态
2.3.5 队列相关
1、打印默认队列信息
[root@hadoop10 hadoop]# yarn rmadmin -refreshQueues
2021-09-22 20:30:56,914 INFO client.RMProxy: Connecting to ResourceManager at hadoop10/192.168.22.136:8033
[root@hadoop10 hadoop]# yarn queue -status default
2021-09-22 20:31:46,890 INFO client.RMProxy: Connecting to ResourceManager at hadoop10/192.168.22.136:8032
Queue Information :
Queue Name : default
State : RUNNING
Capacity : 100.00%
Current Capacity : .00%
Maximum Capacity : 100.00%
Default Node Label expression : <DEFAULT_PARTITION>
Accessible Node Labels : *
Preemption : disabled
Intra-queue Preemption : disabled
2、加载更新队列信息
[root@hadoop10 hadoop]# yarn rmadmin -refreshQueues
2021-09-22 20:32:15,068 INFO client.RMProxy: Connecting to ResourceManager at hadoop10/192.168.22.136:8033
2.3.6 查看节点状态
[root@hadoop10 hadoop]# yarn node -list -all
2021-09-22 20:33:19,077 INFO client.RMProxy: Connecting to ResourceManager at hadoop10/192.168.22.136:8032
Total Nodes:2
Node-Id Node-State Node-Http-Address Number-of-Running-Containers
hadoop11:41778 RUNNING hadoop11:8042 0
hadoop12:37299 RUNNING hadoop12:8042 0
[root@hadoop10 hadoop]#

声明:
文章中代码及相关语句为自己根据相应理解编写,文章中出现的相关图片为自己实践中的截图和相关技术对应的图片,若有相关异议,请联系删除。感谢。转载请注明出处,感谢。
By luoyepiaoxue2014
微博地址: http://weibo.com/luoyepiaoxue2014 点击打开链接